HTTP 框架修炼之道 | 青训营
Powered by:NEFU AB-IN
文章目录
- HTTP 框架修炼之道 | 青训营
-
- 走进 HTTP 协议
- HTTP 框架的设计与实现
-
- 应用层
- 中间件层
- 路由设计
- 协议层
- 传输层(网络层)
-
- 1. BIO(Blocking I/O):
- 2. NIO(Non-blocking I/O):
- 区别:
- 性能修炼之道与企业实践
-
- 针对网络库的优化
- 针对协议的优化
HTTP 框架修炼之道 | 青训营
-
走进 HTTP 协议
-
HTTP 框架的设计与实现
-
性能修炼之道与企业实践
走进 HTTP 协议
前后端通过http通信,负责对http请求解析,根据路由选择对应逻辑
超文本通常包括文本、图像、音频、视频等多种媒体类型,这些内容通过链接与其他相关信息相互连接。最著名的超文本系统之一是万维网(World Wide Web,简称Web)
协议要素

content-length 描述body有多少字节
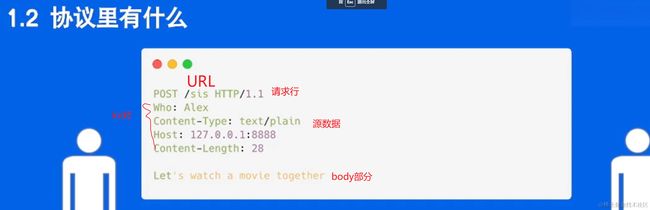
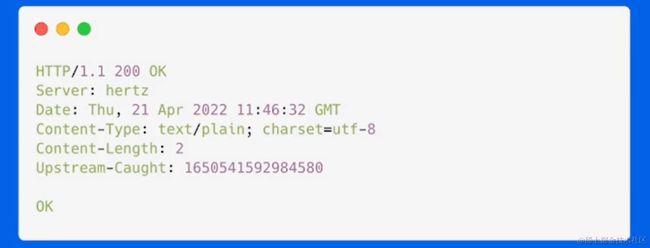
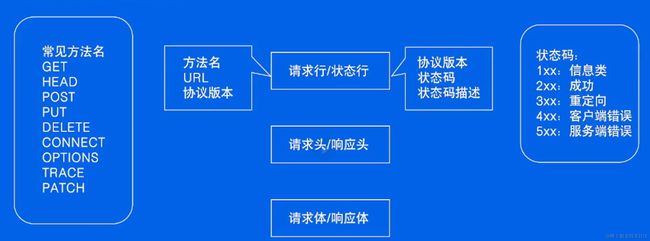
HTTP(Hypertext Transfer Protocol)是一种用于在Web上传输数据的应用层协议。HTTP请求通常由客户端(例如浏览器)发送给服务器,然后服务器响应请求并返回数据给客户端。以下是HTTP协议完整的请求流程以及请求中包含的内容:
-
建立TCP连接:在发送HTTP请求之前,客户端首先需要与服务器建立一个TCP连接。这通常涉及到域名解析(将域名解析为IP地址)和与服务器的三次握手握手过程以建立连接。
-
客户端发送HTTP请求:一旦建立了TCP连接,客户端会发送HTTP请求到服务器。HTTP请求通常包括以下部分:
-
请求行:包含HTTP方法(例如GET、POST、PUT等)、请求的URL(Uniform Resource Locator)以及HTTP协议版本(例如HTTP/1.1)。
-
请求头:包含关于请求的元信息,如Host(主机名)、User-Agent(用户代理,通常是浏览器的标识)、Accept(可接受的响应内容类型)、Cookies等。
-
空行:一个空行用来分隔请求头和请求体。
-
请求体:对于某些HTTP方法(如POST),请求体可以包含客户端发送给服务器的数据,例如表单数据或JSON。后面跟换行符
-
-
服务器处理请求:一旦服务器接收到HTTP请求,它会解析请求并采取相应的操作。这可能涉及到查询数据库、执行应用程序逻辑等。
-
服务器发送HTTP响应:服务器会生成HTTP响应并将其发送回客户端。HTTP响应通常包括以下部分:
-
状态行:包含HTTP协议版本、响应状态代码和状态消息。例如,HTTP/1.1 200 OK表示请求成功。
-
响应头:包含有关响应的元信息,如Server(服务器信息)、Content-Type(响应内容类型)、Content-Length(响应内容长度)等。
-
空行:与请求一样,一个空行分隔响应头和响应体。
-
响应体:包含服务器返回给客户端的实际数据,如HTML页面、JSON数据等。
-
-
关闭连接:一旦服务器发送完响应,服务器和客户端可以选择关闭TCP连接(HTTP/1.0通常会关闭,而HTTP/1.1默认保持连接以便复用)。
HTTP协议是无状态的,这意味着每个请求都是独立的,服务器不会在请求之间保留任何状态信息。如果需要跟踪用户状态,通常会使用Cookie等机制。
总之,HTTP协议的请求流程涉及建立连接、发送请求、处理请求、发送响应以及关闭连接。协议的具体细节和头部字段可能会根据HTTP版本和服务器配置而有所不同。HTTP/1.1和HTTP/2是较新的版本,它们引入了一些性能优化和新的功能。
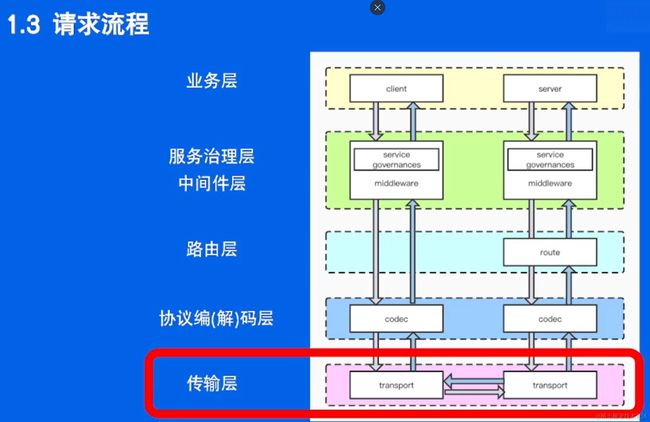
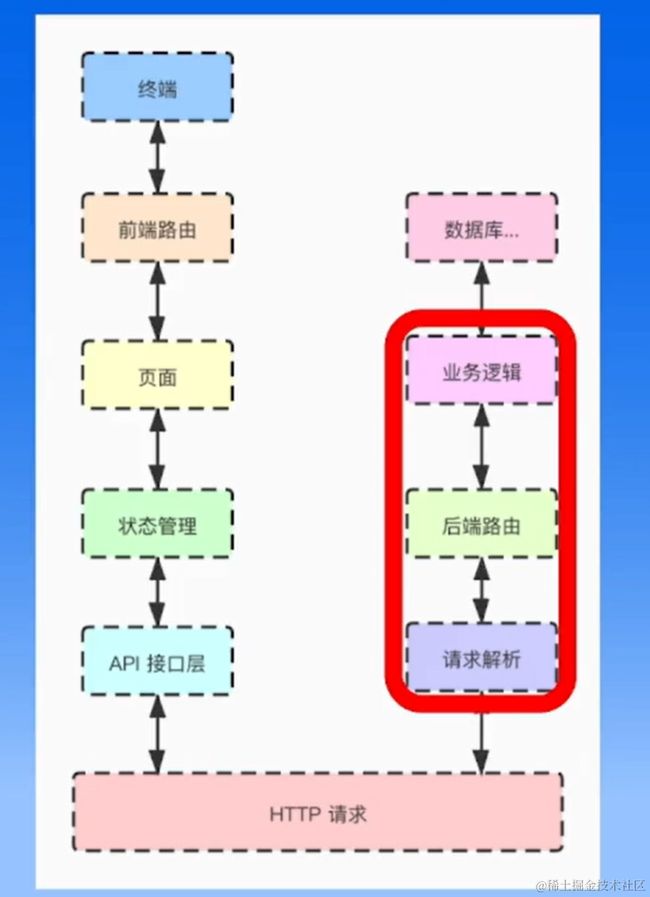
HTTP 框架的设计与实现
http框架聚焦于第四层之上——应用层
分层设计,使得可以使用下一层的接口,专注于本层开发即可

http框架设计,也应分层设计
- 分为五层,层与层解耦
- 应用层 跟用户直接打交道的一层 对请求抽象 提供丰富API
- 中间件层 对用户有预处理和后处理的逻辑
- 路由层 寻址
- 协议层 http1.1
- 网络层
- common 放一些公共逻辑
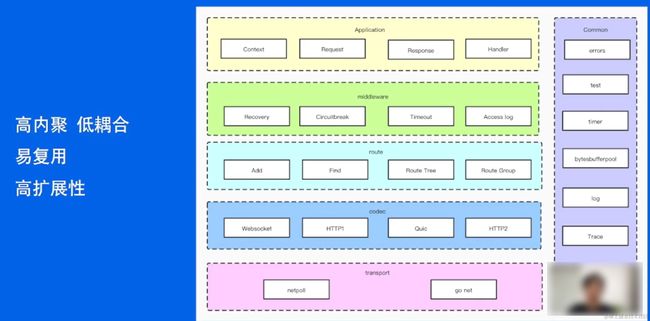
应用层
提供合理API
ctx 通常代表一个上下文对象(用于在特定的执行环境中传递和共享数据、状态和方法),包含了与当前HTTP请求和响应相关的信息和方法。这种上下文对象通常由Web框架或服务器提供,以简化HTTP请求和响应的处理。
- 可理解性:获取body,如ctx.GetBody()
- 简单性:如ctx.Request.Header.Peek()
- 冗余性:
- getbody 和 body 不用一起存在
- 不能某个接口是两个接口拼起来
- 兼容性
- 可测性
- 可见性
不要试图在文档中说明,很多用户不看文档
中间件层

在Go语言中以及许多HTTP框架中,“handler”(处理程序)通常是一个用于处理HTTP请求的函数、方法或对象。处理程序负责接收HTTP请求、执行相应的操作,然后生成HTTP响应。处理程序通常用于路由请求和处理请求的逻辑。以下是一些关于处理程序的常见情况:
-
HTTP请求处理程序:
-
在Go的标准库中,HTTP请求处理程序是一个函数,通常有两个参数:
http.ResponseWriter和*http.Request。http.ResponseWriter用于构建HTTP响应,*http.Request包含了HTTP请求的信息(例如URL、HTTP方法、请求头等)。 -
例如,以下是一个简单的HTTP请求处理程序示例,它回应一个 “Hello, World!” 消息:
import ( "fmt" "net/http" ) func helloHandler(w http.ResponseWriter, r *http.Request) { fmt.Fprintln(w, "Hello, World!") } func main() { http.HandleFunc("/hello", helloHandler) http.ListenAndServe(":8080", nil) }
-
-
HTTP框架中的处理程序:
-
许多HTTP框架(如Gin、Echo、Chi等)提供了自定义处理程序的概念,通常支持更灵活的路由和中间件配置。在这些框架中,处理程序可以是函数、结构体的方法,或者是实现了特定接口的类型。
-
例如,在Gin框架中,您可以定义路由和处理程序如下:
import ( "github.com/gin-gonic/gin" ) func main() { r := gin.Default() r.GET("/hello", func(c *gin.Context) { c.String(http.StatusOK, "Hello, World!") }) r.Run(":8080") }
-
-
中间件:
-
处理程序也可以是中间件函数,它们用于在实际请求处理程序之前或之后执行一些操作,如身份验证、日志记录、路由控制等。中间件函数通常接受一个处理请求的函数,并返回一个新的处理请求的函数。
-
以下是一个简单的日志记录中间件的示例:
func loggingMiddleware(next http.Handler) http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) { log.Println("Request received:", r.Method, r.URL.Path) next.ServeHTTP(w, r) }) }
-
总之,无论是在Go标准库还是在HTTP框架中,处理程序通常是用于处理HTTP请求的函数、方法或对象。这些处理程序负责执行与请求相关的操作,并生成HTTP响应。处理程序可以用于定义路由、中间件,以及应用程序的核心逻辑,它们是构建Web应用程序的重要组件。不同的框架可能有不同的实现和用法,但基本概念是相似的。
经过 日志-> Metrics 的预处理,再执行业务逻辑,再出去经过后处理
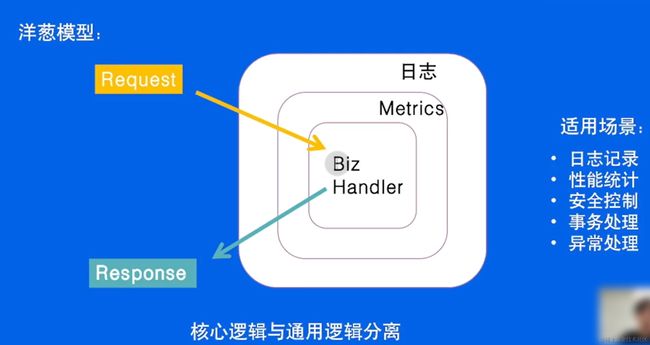

解释上图的流程:
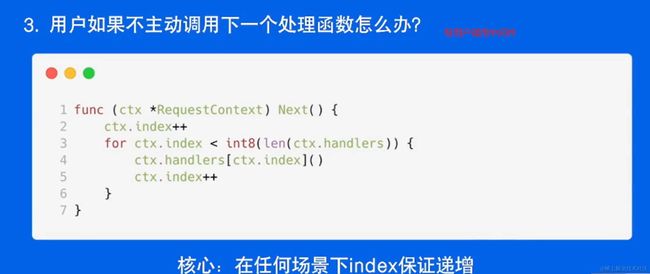
在某些Go语言的Web框架和中间件中,ctx.Next(c) 是用来调用下一个中间件或处理程序的方法。这种语法通常用于中间件函数中,以控制中间件链的执行流程。
具体来说,ctx 通常是一个上下文对象,Next(c) 是该上下文对象的方法。这个方法的作用是将请求传递给下一个中间件或处理程序,并继续执行下一个处理步骤。在处理HTTP请求时,中间件通常按照它们在链中的顺序依次执行,然后再将请求传递给实际的请求处理程序。
以下是一个使用ctx.Next(c) 的示例,假设您使用的是Gin框架的中间件:
import (
"github.com/gin-gonic/gin"
)
func customMiddleware(c *gin.Context) {
// 执行一些前置操作
fmt.Println("Middleware: Before Request")
// 调用下一个中间件或处理程序
c.Next()
// 执行一些后置操作
fmt.Println("Middleware: After Request")
}
func main() {
r := gin.Default()
// 使用自定义中间件
r.Use(customMiddleware)
// 定义路由处理程序
r.GET("/hello", func(c *gin.Context) {
// 处理HTTP请求
c.String(http.StatusOK, "Hello, World!")
})
r.Run(":8080")
}
在上述示例中,customMiddleware 是一个自定义中间件。在中间件中,它首先执行一些前置操作,然后调用 c.Next() 来将请求传递给下一个中间件或处理程序。在本例中,下一个处理程序是定义的路由处理程序,它会处理实际的HTTP请求。然后,中间件再执行一些后置操作。
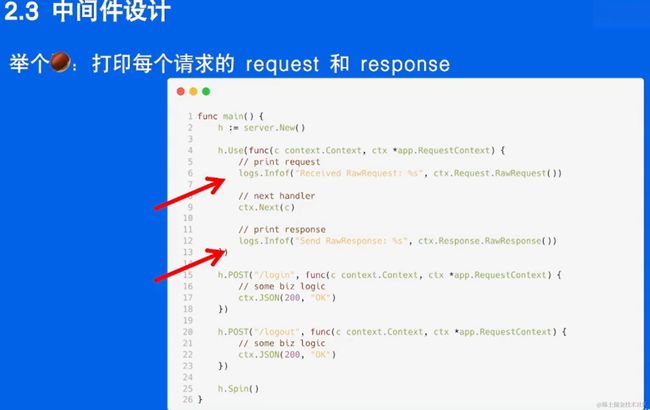
以下是对代码的解释:
-
ctx.JSON(200, "ok"):- 这行代码通常用于处理HTTP请求并生成HTTP响应。
ctx可能是一个上下文对象,用于表示HTTP请求和响应的上下文。JSON是一个方法,用于生成HTTP响应,并将数据以JSON格式返回给客户端。200是HTTP响应的状态码,表示成功。"ok"是要返回给客户端的JSON数据。在这种情况下,它是一个简单的字符串,表示一切正常。
-
h := server.New():- 这行代码创建了一个名为
h的新的服务器实例。 server可能是一个自定义的服务器对象或框架中的服务器对象。New()是一个构造函数或工厂方法,用于创建服务器实例。
- 这行代码创建了一个名为
-
h.Spin():- 这行代码启动了服务器,使其开始监听传入的HTTP请求。
Spin()可能是服务器对象中的一个方法,用于启动服务器并开始接受和处理HTTP请求。

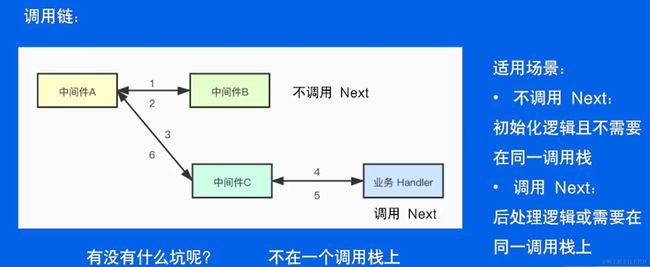
路由设计
框架路由的主要作用是将传入的URL映射到相应的处理函数(也称为处理程序或控制器)。当客户端发送一个HTTP请求时,这个请求通常包括一个URL(Uniform Resource Locator),URL表示了客户端想要访问的资源或执行的操作。
框架的路由系统的任务就是根据请求的URL来确定应该执行哪个处理函数来处理该请求。这个匹配过程通常基于一组路由规则,这些规则将特定的URL模式与特定的处理函数关联起来。当请求的URL与某个路由规则匹配时,框架就会调用相应的处理函数来处理请求。
例如,假设有一个简单的路由规则:
- 当URL是 “/user” 时,执行名为 “handleUser” 的处理函数。
- 当URL是 “/product” 时,执行名为 “handleProduct” 的处理函数。
如果客户端发送了一个HTTP请求,URL是 “/user”,框架的路由系统将会匹配这个请求到 “handleUser” 处理函数,然后执行与之关联的代码,以完成相应的操作。
总之,框架路由的目的是将URL映射到适当的处理函数,以便根据请求的内容执行相应的操作。这种机制使得Web应用程序能够根据不同的URL来呈现不同的页面或提供不同的服务。

静态路由
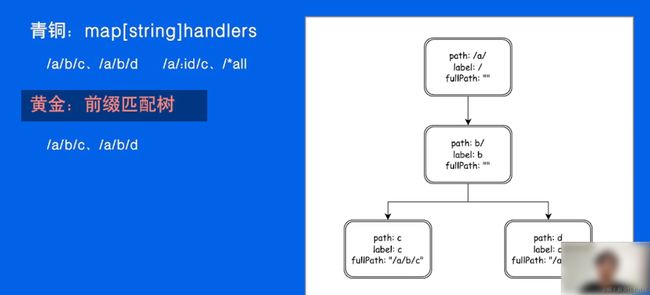
参数路由
提出公共的:或者 /
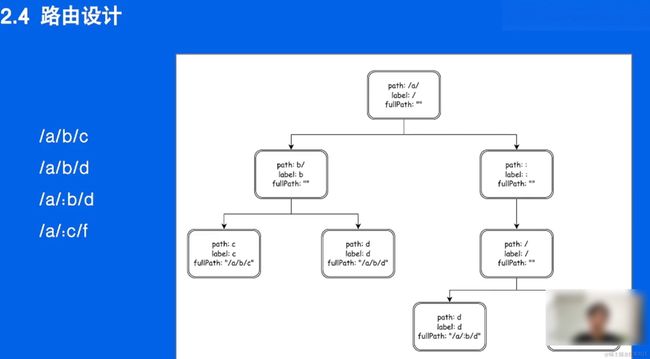



协议层
完成对接口的拓展就能完成对协议的拓展
- 不要把context写到struct,需要显示的通过函数的第一个参数传过来,需要context进行上下文传递
- 需要传链接
- 返回值,抛给上层error

传输层(网络层)
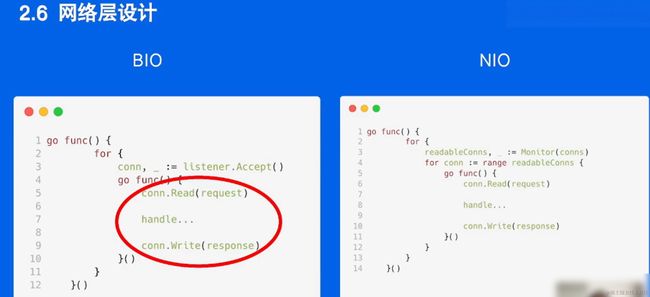
NIO(Non-blocking I/O)和BIO(Blocking I/O)是两种不同的I/O模型,它们描述了计算机系统中处理输入和输出的方式。以下是它们的具体含义以及它们之间的区别:
1. BIO(Blocking I/O):
BIO是一种阻塞式I/O模型。在BIO中,当应用程序执行I/O操作时,它会阻塞(暂停)直到I/O操作完成。这意味着在进行I/O操作期间,应用程序不能执行其他任务,它必须等待数据准备好或者操作完成。
示例:
假设您编写一个简单的文件复制程序,使用BIO模型,代码可能如下:
package main
import (
"io"
"os"
)
func main() {
sourceFile, err := os.Open("input.txt")
if err != nil {
panic(err)
}
defer sourceFile.Close()
destFile, err := os.Create("output.txt")
if err != nil {
panic(err)
}
defer destFile.Close()
buffer := make([]byte, 1024)
for {
bytesRead, err := sourceFile.Read(buffer)
if err == io.EOF {
break
}
if err != nil {
panic(err)
}
destFile.Write(buffer[:bytesRead])
}
}
在上面的代码中,inputStream.read(buffer) 和 outputStream.write(buffer, 0, bytesRead) 都是阻塞调用,它们会等待数据读取或写入完成。
2. NIO(Non-blocking I/O):
NIO是一种非阻塞式I/O模型。在NIO中,应用程序可以发起I/O操作,但不会等待操作完成。相反,它会继续执行其他任务,然后稍后检查操作的状态。这意味着一个线程可以管理多个I/O操作,提高了系统的并发性能。
示例:
使用Java NIO编写的文件复制程序可以如下所示:
FileChannel sourceChannel = new FileInputStream("input.txt").getChannel();
FileChannel destChannel = new FileOutputStream("output.txt").getChannel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
while (sourceChannel.read(buffer) != -1) {
buffer.flip();
destChannel.write(buffer);
buffer.clear();
}
sourceChannel.close();
destChannel.close();
在上面的代码中,sourceChannel.read(buffer) 和 destChannel.write(buffer) 是非阻塞调用,它们不会等待数据读取或写入完成,而是继续执行后续代码。
区别:
-
阻塞 vs. 非阻塞:
- BIO是阻塞式I/O,意味着当执行I/O操作时,线程会被阻塞,直到操作完成。
- NIO是非阻塞式I/O,线程不会被阻塞,可以继续执行其他任务。
-
并发性:
- BIO通常需要为每个客户端连接创建一个新的线程,因此对于大量客户端的情况,线程开销会很大。
- NIO允许一个线程管理多个I/O操作,因此可以更高效地处理大量并发连接。
-
编程复杂性:
- BIO编程通常比较简单,因为它使用阻塞调用,代码顺序执行。
- NIO编程较复杂,因为需要处理异步I/O操作和状态管理。
-
适用场景:
- BIO适用于连接数较少但I/O操作较重的情况,如文件I/O或数据库连接。
- NIO适用于需要处理大量并发连接,例如网络服务器或聊天应用程序。
总之,BIO和NIO是两种不同的I/O模型,它们在处理I/O操作时的工作方式不同。选择哪种模型通常取决于应用程序的需求和性能要求。
性能修炼之道与企业实践

针对网络库的优化
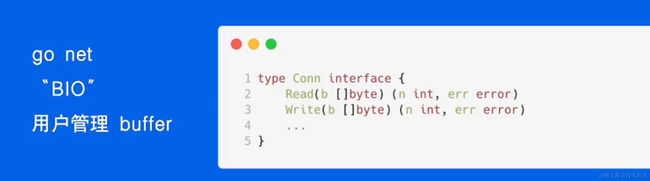
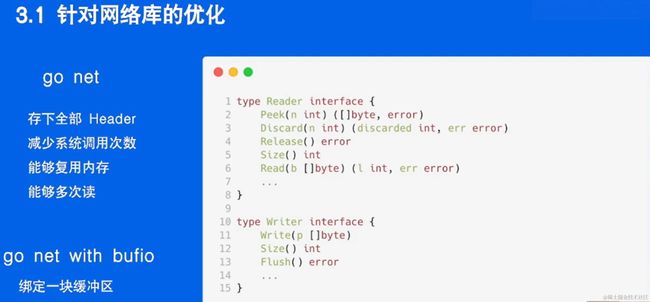
go net
流式友好 小包性能高
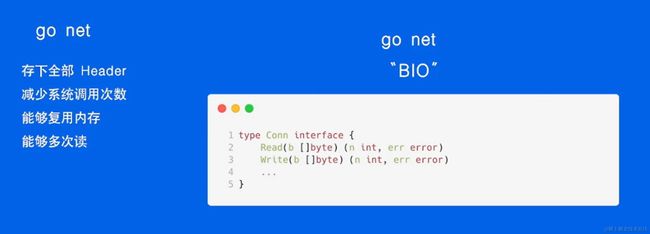
问题:需要用户在后台管理buffer 需要的开销比较大
解决:为每一个链接绑定一块buffer(4K左右)
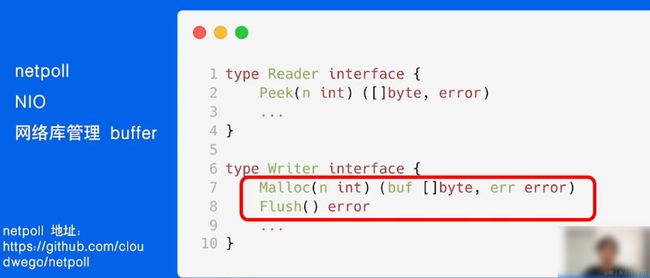
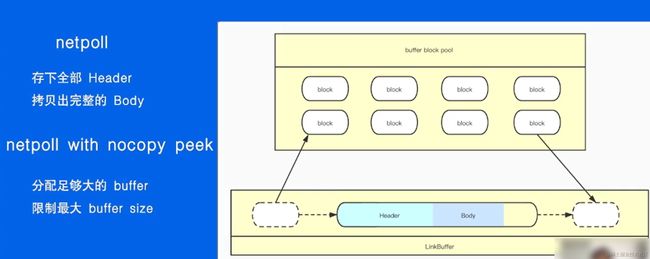
netpoll
中大包性能高 时延低
针对协议的优化
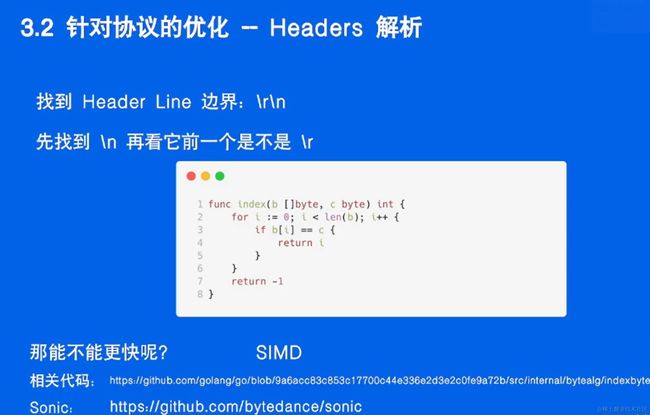
在HTTP协议中,“\r\n” 表示回车(Carriage Return)和换行(Line Feed),它们在HTTP报文中用于分隔报头(Header)字段。HTTP报头字段通常使用"\r\n"来表示字段之间的分隔,而字段的名称和值之间也使用"\r\n"来分隔。
例如,下面是一个HTTP请求的示例,其中使用了"\r\n"来分隔报头字段:
GET /index.html HTTP/1.1\r\n
Host: www.example.com\r\n
User-Agent: Mozilla/5.0\r\n
Accept: text/html\r\n
\r\n
在这个示例中,每个报头字段的名称和值之间都用"\r\n"分隔,而每个报头的末尾使用两个连续的"\r\n"来表示报头结束。这是HTTP协议中的硬线标准,表示了HTTP请求的正确格式。
总之,“hard line” 或 “hardline” 在计算机通信领域通常指的是一种严格要求的标准或规则,而在HTTP协议中,“\r\n” 用于表示回车和换行,是HTTP请求和响应中报头字段的分隔符。
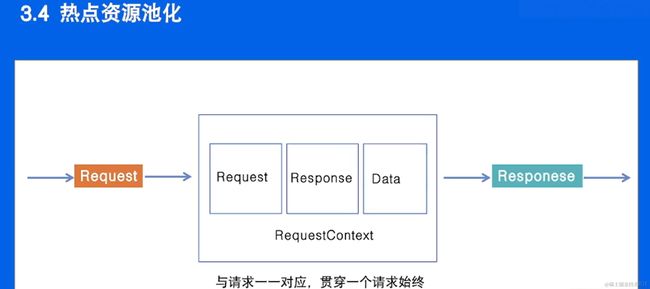
“request context” 池化技术指的是将请求上下文对象(通常称为 request context)放入池中以进行有效的重用的技术。这个概念通常用于高并发的服务器应用程序,特别是Web服务器,以减少对象的创建和垃圾回收(GC)的开销。
在Web服务器中,每个客户端请求通常都需要一个请求上下文对象,该对象用于存储与该请求相关的信息,例如请求头、请求参数、用户身份验证信息等等。在高并发情况下,频繁地创建和销毁这些请求上下文对象可能会导致性能问题,因为对象的创建和销毁都会涉及到内存分配和垃圾回收。
池化技术的核心思想是,当一个请求上下文对象不再需要时,它不会被立即销毁,而是放回到一个对象池(或请求上下文池)中,以备将来重用。这样做有几个好处:
-
减少对象创建和销毁开销:通过重用对象,减少了频繁的内存分配和垃圾回收,提高了性能。
-
降低内存占用:对象池控制了请求上下文对象的数量,防止了内存泄漏或内存溢出。
-
更稳定的响应时间:通过减少GC的发生频率,可以更稳定地维持低延迟和一致的响应时间。
使用池化技术时,通常会在服务器启动时创建一定数量的请求上下文对象,并将它们放入池中。然后,当请求到达时,可以从池中获取一个请求上下文对象,并在请求处理完成后将其返回池中,以供下一个请求使用。
这种技术需要小心管理对象的生命周期,以确保对象在适当的时候被释放回池中,以避免资源泄漏。常见的编程语言和框架通常提供了池化技术的实现