windows下hadoop的部署和使用
本教程在windows10环境下安装配置hadoop+hbase+spark。
一、下载压缩包:
1、JavaJDK,1.8以上。
2、Hadoop2.8.3,下载地址:http://archive.apache.org/dist/hadoop/core/
Hadoop2.8.3windows环境下的第三方包:winutils,
https://github.com/steveloughran/winutils,如果报nativeio异常,可以将此包解压至hadoop的bin目录下。
3、Spark2.2.0,下载地址:http://archive.apache.org/dist/spark/spark-2.2.0/
4、选择spark-2.2.0-bin-hadoop2.7点击下载。
二、安装配置
1、安装jdk并配置环境变量。
2、解压缩hadoop,配置环境变量。
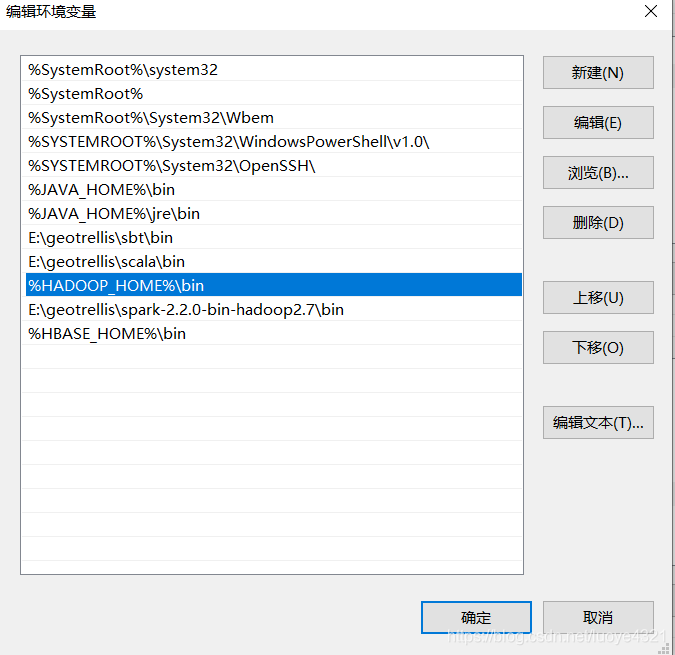
右键单击我的电脑 –>属性 –>高级环境变量配置 –>高级选项卡 –>环境变量 –> 单击新建HADOOP_HOME,如下图 
3、修改hadoop配置文件
1)修改core-site.xml配置文件,位置在hadoop目录下etc/hadoop/core-site.xml,添加如下配置:
2)修改hdfs-site.xml配置文件,位置在hadoop目录下etc/hadoop/hdfs-site.xml,添加如下配置:
注意value里的目录,我这里使用全路径配置。
根据上面的配置,在hadoop目录下创建namenode、datanode节点存储目录。如下:
3)重命名mapred-site.xml.template为mapred-site.xml,位置同上添加配置:
4)配置yarn-site.xml,位置同上
至此,hadoop配置完成,hdfs负责分布式存储,mapreduce负责分布式计算,yarn负责资源调度,基本的(伪)分布式环境初步建立。
三、测试使用
1、格式化namenode的hdfs目录
cmd命令下输入执行:hdfs namenode –format
2、启动hadoop,定位到sbin目录,如下输入

3、启动所有hadoop服务,输入start-all
这时候会弹出4个窗口,输入jps查看进程情况,如下:

输入:http://localhost:8088/ 查看hadoop的启动情况
4、测试和使用
1)创建hdfs的目录,如下:
Hadoop fs –mkdir /user
Hadoop fs –mkdir /user/input
2)上传文件
Hadoop fs –put e:/test.txt /user/input
Txt文本内容如下,输入:
Hadoop fs –cat /user/input/test.txt

3)词频计算
hadoop jar E:/geotrellis/hadoop-2.8.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar wordcount /user/input/ /user/output
4)查看运行结果,如下:
