Notion API + Python实现阅读、影视数据可视化图表
目录
实现效果
1️⃣准备阶段
Notion API
1、创建API
2、API连接数据库
3、获取数据库ID
Python第三方库
2️⃣ 方法实现
一、Python连接Notion
导入库
二、数据处理
三、数据可视化
import numpy as np
import requests,json
import matplotlib.pyplot as plt
import pyecharts.options as opts
from pyecharts.charts import Pie
class Notion_Data:
def __init__(self):
print("欢迎来到Notion数据可视化分析!")
# 获取用户数据库ID及Token密钥
# 数据处理
def Notion_Data_deal(self, Database_ID: str, Token_KEY: str):
base_url = "https://api.notion.com/v1/databases/"
"""
接口匹配
"""
headers = {
"Authorization": "Bearer " + Token_KEY,
"accept": "application/json",
"Notion-Version": "2022-06-28" # Notion版本号
}
query = {"filter": {"property": "出版社", "checkbox":{"equals":True}}}
# 获取Notion页面下的详细信息 https://developers.notion.com/reference/post-database-query
response = requests.post(base_url + Database_ID + "/query", headers=headers, data=query)
jst = json.loads(response.text)
return jst
def Json_Data_deal(self, Database_ID: str, Token_KEY: str, Type: str): # 类型仅限为:书籍、影片
dict = self.Notion_Data_deal(Database_ID, Token_KEY)
"""获取到数据列"""
data_len = len(dict['results'])
# 统计类型数量,进行后续图形比例
# 书籍以出版社为划分,影片以类别划分
if Type == "影片":
"""获取到数据列"""
dic = {}
dtc = {}
for i in range(data_len):
name = dict['results'][i]['properties']['片名']['title'][0]['plain_text']
select = dict['results'][i]['properties']['类别']['multi_select']
classify = []
for j in range(len(select)):
classify.append(dict['results'][i]['properties']['类别']['multi_select'][j]['name'])
dic[name] = classify # 类别
ls = list(dic.items()) # 获取数据数量
for i in range(len(ls)):
for j in range(len(ls[i][1])):
if ls[i][1][j] in "奇幻":
ls[i][1][j] = "科幻"
if ls[i][1][j] in "惊悚" or ls[i][1][j] in "悬疑":
ls[i][1][j] = "恐怖"
if ls[i][1][j] in "故事" or ls[i][1][j] in "扫黑" or ls[i][1][j] in "生活":
ls[i][1][j] = "剧情"
if ls[i][1][j] in "运动":
ls[i][1][j] = "冒险"
dtc[ls[i][1][j]] = dtc.get(ls[i][1][j], 0) + 1
lt = list(dtc.items())
print("有效数据:" + str(len(dic)))
return lt
if Type == "书籍":
dic = {}
for i in range(data_len):
try:
name = (dict['results'][i]['properties']['出版社']['select']['name'])
dic[name] = dic.get(name, 0) + 1
except Exception:
pass
continue
ls = list(dic.items())
return ls
def Notion_Visualization(self, Database_ID: str, Token_KEY: str, Type: str): # 交互式可视化图表
data = self.Json_Data_deal(Database_ID, Token_KEY, Type)
lenght = len(data)
sum = 0
count_num, name = [], []
for i in range(lenght):
sum += int(data[i][1])
name.append(data[i][0])
for j in range(lenght):
a = round(int(data[j][1]) / sum * 100, 2) # 保留为两位小数
count_num.append(a)
np.set_printoptions(precision=2)
data_pair_temp = [list(data) for data in zip(name, count_num)]
p = (
Pie() # 实例化
.add(
series_name=Type, # 系列名称
data_pair=data_pair_temp, # 馈入数据
radius="65%", # 饼图半径比例
center=["50%", "50%"], # 饼图中心坐标
label_opts=opts.LabelOpts(is_show=False, position="center"), # 标签位置
)
.set_global_opts(legend_opts=opts.LegendOpts(is_show=True)) # 不显示图示
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")) # 标签颜色
.render(Type + ".html") # 渲染文件及其名称
# .render_notebook()
)
print("文件已保存在当前程序目录!")
"""
# 静态可视化图表
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 显示中文标签,处理中文乱码问题
plt.rcParams['axes.unicode_minus'] = False # 坐标轴负号的处理
plt.pie(x=count_num, labels=name, autopct='%.2f%%')
plt.legend(loc='center')
plt.savefig("./Image/Vedio.png")
plt.show()
# print(name, count_num)
"""
if __name__ == '__main__':
text = Notion_Data()
Database_ID = str(input("请输入数据库ID:\n"))
Token_KEY = str(input("请输入Token密钥:\n"))
Type = str(input("请输入类型(仅限书籍、影片):\n"))
text.Notion_Visualization(Database_ID, Token_KEY, Type)
# print(text.Json_Data_deal(Database_ID, Token_KEY, Type))全部代码
导言
本代码是为创建Notion数据库(Database)可视化图标,若使用Notion页面为页面(page),该教材不符合你所使用。
通俗来讲,Notion数据库是表格。但是Notion在创建之初就会将其定义为是数据库 or 页面,那么如何判断我的Notion是数据库还是包?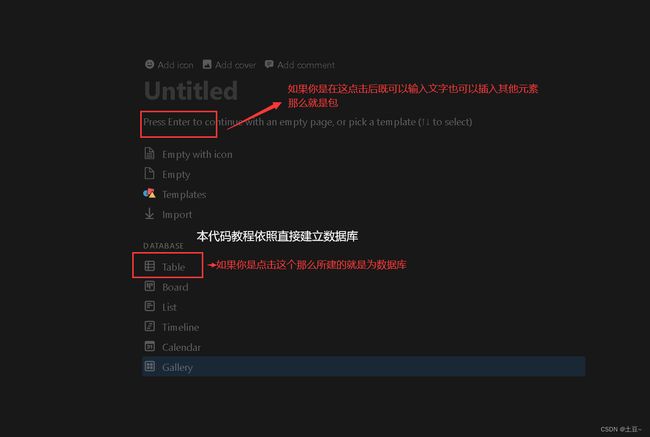
实现效果
1️⃣准备阶段
Notion API
将你的工作界面加入连接。
1、创建API
Notion API官网
点击链接,开始创建属于你的Notion API

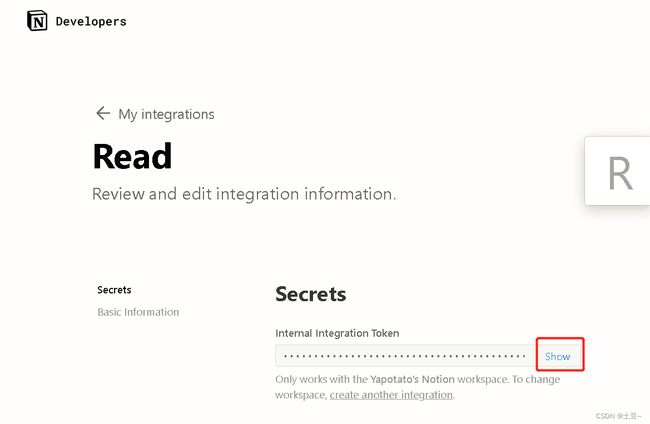
创建后会出现:Secrets
点击右方的Show,获取这一串密钥,在Python代码中需要
-
详情
2、API连接数据库
点击右上角三点后,再点击,Add connections,加入你所创建的API
3、获取数据库ID
...
|--- 这一段就是你的数据库 ID ---|
由于设备不同,所得到的效果也不一样,这里提供图片:
Python第三方库
- Matplotlib==3.5.3
- numpy==1.21.4
- requests==2.28.1
- 安装方法
-
第一种


安装好后会出现一串绿色英文,证明安装成功,只需返回等待即可。
-
第二种
进入Ctrl + r快捷键,输入cmd进入


-
2️⃣ 方法实现
一、Python连接Notion
导入库
import numpy as np
import requests,json
import matplotlib.pyplot as plt
import pyecharts.options as opts
from pyecharts.charts import Pie
class Notion_Data: # 后面的所有代码都在这个类中写
def __init__(self):
print("欢迎来到Notion数据可视化分析!")
# 获取用户数据库ID及Token密钥
# 数据处理
def Notion_Data_deal(self, Database_ID: str, Token_KEY: str):
base_url = "
response = requests.post(base_url + Database_ID + "/query", headers=headers, data=query)
jst = json.loads(response.text)
return jst
""" 以下代码为测试用例,可任意修改 """
if __name__ == '__main__':
text = Notion_Data()
Database_ID = str(input("请输入数据库ID:\\n"))
Token_KEY = str(input("请输入Token密钥:\\n"))
print(text.Notion_Data_deal(Database_ID, Token_KEY))
此时获取到的内容为JSON格式,以下:
-
输出效果
每个人的数据不一样,只要没有显示错误代码即可。

-
错误代码


降低Matplotlib库的版本为:3.5.3
二、数据处理
def Json_Data_deal(self, Database_ID: str, Token_KEY: str, Type: str): # Type为获取你要处理的数据库为数据还是影片
dict = self.Notion_Data_deal(Database_ID, Token_KEY) # 调用前一个函数
"""获取到数据列"""
data_len = len(dict['results']) # 统计类型数量,进行后续图形比例
# 书籍以出版社为划分,影片以类别划分。
if Type == "影片":
"""获取到数据列"""
dic = {} # 字典存放数据
for i in range(data_len): # 循环将数据调用出来
select = dict['results'][i]['properties']['类别']['multi_select']
for j in range(len(select)):
try: # 捕捉异常数据并跳过
if select[j]['name'] == None: # 如何该行影片类型为空,则跳过
continue
else:
if select[j]['name'] == "奇幻":
select[j]['name'] = "科幻"
if select[j]['name'] == "惊悚" or select[j]['name'] == "悬疑":
select[j]['name'] = "恐怖"
if select[j]['name'] == "故事" or select[j]['name'] == "扫黑" or select[j]['name'] == "生活":
select[j]['name'] = "剧情"
if select[j]['name'] == "运动":
select[j]['name'] = "冒险"
dic[select[j]['name']] = dic.get(select[j]['name'], 0) + 1
except Exception:
pass # 不处理异常
continue # 跳过
print("有效数据:" + str(len(dic)))
return dic
if Type == "书籍":
dic = {}
for i in range(data_len):
try: # 捕捉异常数据并跳过
name = (dict['results'][i]['properties']['出版社']['select']['name'])
dic[name] = dic.get(name, 0) + 1 # 统计每本数据出版社类型数量,为可视化数据使用
except Exception:
pass # 不处理异常
continue # 跳过
ls = list(dic.items())
return ls
""" 以下代码为测试用例,可任意修改 """
if __name__ == '__main__':
text = Notion_Data()
Database_ID = str(input("请输入数据库ID:\\n"))
Token_KEY = str(input("请输入Token密钥:\\n"))
Type = str(input("请输入数据库类型(书籍/影片):\\n"))
# print(text.Notion_Data_deal(Database_ID, Token_KEY))
print(text.Json_Data_deal(Database_ID, Token_KEY, Type))
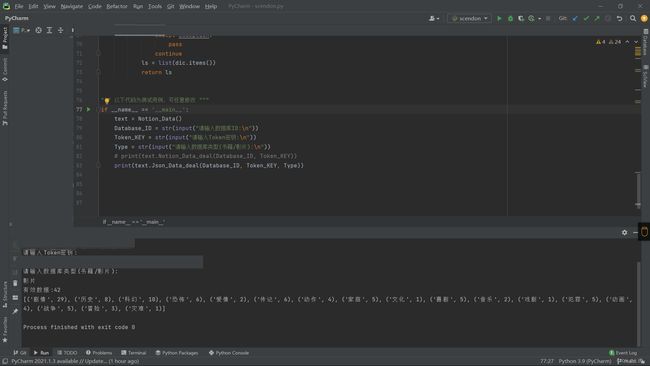
-
输出效果
每个人的数据不一样,只要没有显示错误代码即可。
三、数据可视化
def Notion_Visualization(self, Database_ID: str, Token_KEY: str, Type: str): # 交互式可视化图表
data = self.Json_Data_deal(Database_ID, Token_KEY, Type)
lenght = len(data)
sum = 0
count_num, name = [], []
for i in range(lenght):
sum += int(data[i][1])
name.append(data[i][0])
for j in range(lenght):
a = round(int(data[j][1]) / sum * 100, 2) # 保留为两位小数
count_num.append(a)
np.set_printoptions(precision=2)
data_pair_temp = [list(data) for data in zip(name, count_num)]
p = (
Pie() # 实例化
.add(
series_name=Type, # 系列名称
data_pair=data_pair_temp, # 馈入数据
radius="65%", # 饼图半径比例
center=["50%", "50%"], # 饼图中心坐标
label_opts=opts.LabelOpts(is_show=False, position="center"), # 标签位置
)
.set_global_opts(legend_opts=opts.LegendOpts(is_show=True)) # 不显示图示
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")) # 标签颜色
.render(Type + ".html") # 渲染文件及其名称
# .render_notebook()
)
print("文件已保存在当前程序目录!")
""" 以下代码为测试用例,可任意修改 """
if __name__ == '__main__':
text = Notion_Data()
Database_ID = str(input("请输入数据库ID:\\n"))
Token_KEY = str(input("请输入Token密钥:\\n"))
Type = str(input("请输入类型(仅限书籍、影片):\\n"))
text.Notion_Visualization(Database_ID, Token_KEY, Type) # 可视化图标
# print(text.Json_Data_deal(Database_ID, Token_KEY, Type)) # JSON数据处理
-
输出效果
 将HTML打开即可看到
将HTML打开即可看到