这是一个示例网页,用于演示BeautifulSoup的基本用法。
| 姓名 | 年龄 |
|---|---|
| 张三 | 25 |
| 李四 | 30 |
接上篇《31、使用JsonPath解析淘票票网站地区接口数据》
上一篇我们介绍了如何使用JSONPath来解析淘票票网站的地区接口数据,本篇我们来学习BeautifulSoup的基本概念,以及bs4的基本使用。
BeautifulSoup是一个Python库(简称“bs4”),用于从HTML或XML文件中提取数据。它的设计目标是使解析复杂的文档变得简单、快速,并提供一种便捷的方式来浏览和搜索文档树。
BeautifulSoup可以处理不规则标记、修复糟糕的HTML和提供简单的遍历和搜索功能。使用BeautifulSoup,可以通过标签名称、属性值和文本内容等条件来搜索文档元素,并提取所需的数据。
通过BeautifulSoup,可以轻松地提取文档中的数据,例如标题、段落、链接、表格等。您还可以通过遍历树状结构,定位某个特定元素、获取其属性值以及修改文档内容。
(1)BeautifulSoup优点
简单易用,提供了简洁的API,使得从文档中提取数据变得容易。
支持多种解析器,包括标准库中的html.parser、lxml和xml等,具有较好的兼容性。可以处理不规则标记和修复糟糕的HTML,适用于实际应用中常见的网页解析任务。
(2)BeautifulSoup缺点
解析速度相对较慢,特别是在处理大型文档时可能会更明显。
功能相对较少,相比于专注于解析的库如lxml,功能选项较少。
(3)lxml优点
解析速度快,由于是C库的实现,处理大型文档效率高。
提供了丰富的功能选项,如XPath表达式、CSS选择器等,可以更精确地定位和提取数据。
(4)lxml缺点
相对于BeautifulSoup,使用起来稍微复杂一些,需要学习额外的功能和语法。
安装和配置可能需要一些额外的工作,尤其在某些平台和环境下。
综上所述,如果我们需要简单而易用的文档解析和数据提取,可以选择BeautifulSoup。如果您处理的是大量数据或复杂的文档结构,并且需要更高的解析速度和更多的功能选项,可以选择lxml。
使用BeautifulSoup需要先安装bs4库,然后导入相关模块。然后可以将HTML或XML文件传递给BeautifulSoup对象进行解析。解析后的文档将被转换成一个层次结构的树状对象,可以使用各种方法和属性来访问和操作这个树。示例代码:
注:首先要通过“pip install bs4”来安装bs4库。
# _*_ coding : utf-8 _*_
# @Time : 2023-08-20 17:48
# @Author : 光仔December
# @File : bs4基础联系
# @Project : Python_Projects
from bs4 import BeautifulSoup
# 要解析的HTML或XML文档
html_doc = """
示例网页
欢迎使用BeautifulSoup
这是一个示例网页,用于演示BeautifulSoup的基本用法。
- 列表项1
- 列表项2
- 列表项3
"""
# 创建BeautifulSoup对象,并制定解析器(此处使用默认的html.parser)
soup = BeautifulSoup(html_doc, 'html.parser')
# 访问和操作解析后的文档树
title = soup.title # 获取标题元素
h1 = soup.h1 # 获取第一个元素
description = soup.find(class_="description") # 根据class属性查找
元素
list_items = soup.find_all('li') # 查找所有
元素
# 打印获取到的内容
print("标题:", title.text)
print("第一个元素:", h1.text)
print("描述段落:", description.text)
print("列表项:")
for item in list_items:
print(item.text)
效果: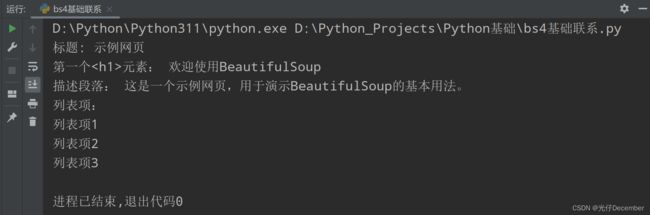
使用BeautifulSoup函数可以将HTML或XML内容转换为BeautifulSoup对象。
语法:soup = BeautifulSoup(html_doc, 'html.parser')
使用标签名称可以直接选择对应的元素。
语法:soup.tag_name(选择第一个匹配到的标签)或 soup.find('tag_name')(选择所有匹配到的标签)。
第二层直接访问,如soup.a.name或soup.a.attrs。
使用标签名称和属性来选择元素。
语法:soup.find('tag_name', attrs={'attr_name': 'attr_value'})
使用CSS选择器语法来选择元素。
语法:soup.select('css_selector')(返回所有匹配到的元素列表)
使用.contents属性可以获取当前节点的所有子节点。
使用.parent属性可以访问当前节点的父节点。
使用.next_sibling和.previous_sibling属性可以访问当前节点的下一个兄弟节点和上一个兄弟节点。
使用.text属性可以获取元素的文本内容。
使用.get('attribute_name')方法可以获取元素的特定属性值。
使用.find()方法可以按条件查找第一个匹配的元素。
使用.find_all()方法可以查找所有匹配的元素。
可以通过标签名称、属性值、文本内容等条件进行搜索。
使用.replace_with(new_tag)方法可以替换当前节点为指定的新节点。
使用.append(new_tag)方法可以在当前节点末尾添加一个新节点。
使用.extract()方法可以将当前节点从文档树中移除。
以上是bs4的一些常用语法和操作,可以根据具体需求使用对应的方法和属性来解析、遍历和搜索HTML或XML文档树,并获取所需的数据。下面的示例代码演示了使用bs4常用的语法和操作来解析、遍历、搜索和修改包含更复杂HTML结构的文档树。通过逐个示例,大家可以了解如何使用不同的方法和属性来实现所需的功能:
# _*_ coding : utf-8 _*_
# @Time : 2023-08-20 18:06
# @Author : 光仔December
# @File : bs4基本语法练习
# @Project : Python_Projects
from bs4 import BeautifulSoup
# HTML文档
html_doc = """
示例网页
欢迎使用BeautifulSoup
"""
# 创建BeautifulSoup对象
soup = BeautifulSoup(html_doc, 'html.parser')
# 标签选择器示例
title = soup.title
print("标题:", title.text)
h1 = soup.h1
print("第一个元素:", h1.text)
# 直接访问标签示例
a_tag = soup.a
print("a标签名称:", a_tag.name)
print("a标签属性:", a_tag.attrs)
# 属性选择器示例
description = soup.find('p', class_="description")
print("描述段落:", description.text)
# 搜索文档树示例
first_link = soup.find('a')
print("第一个链接地址:", first_link['href'])
# CSS选择器示例
links = soup.select('ul li a')
print("链接:")
for link in links:
print(link.text)
# 遍历文档树示例
table = soup.table
rows = table.find_all('tr')
print("表格内容:")
for row in rows:
cells = row.find_all('td')
for cell in cells:
print(cell.text)
print()
# 修改文档树示例
replacement_tag = soup.new_tag('b')
replacement_tag.string = "新的加粗文本"
# 将p中间的字符串替换为新的加粗文本
description.string.replace_with(replacement_tag)
# 打印修改后的内容
print("更换后的描述段落:", soup.div.p)
效果: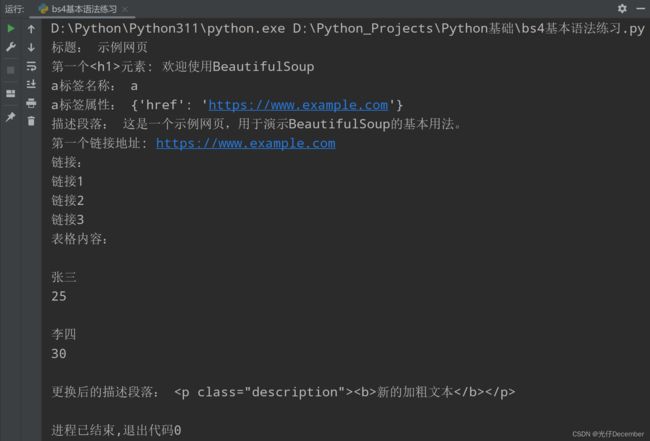
至此,有关使用BeautifulSoup的基本介绍及语法示例就全部学习完毕,下一篇我们来使用BeautifulSoup来抓取星巴克的数据。
参考:尚硅谷Python爬虫教程小白零基础速通教学视频
转载请注明出处:https://guangzai.blog.csdn.net/article/details/132394556