Hudi 快速体验使用(含操作详细步骤及截图)
文章目录
- Hudi 快速体验使用
-
- 启动 spark-shel l添加 jar 包
- 模拟产生Trip乘车数据
- 插入数据
- 利用sqark SQL查询
- 参考资料:
Hudi 快速体验使用
本示例要完成下面的流程:

需要提前安装好hadoop、spark以及hudi及组件。
spark 安装教程:
https://blog.csdn.net/hshudoudou/article/details/125204028?spm=1001.2014.3001.5501
hudi 编译与安装教程:
https://blog.csdn.net/hshudoudou/article/details/123881739?spm=1001.2014.3001.5501
注意只Hudi管理数据,不存储数据,不分析数据。
启动 spark-shel l添加 jar 包
./spark-shell \
--master local[2] \
--jars /home/hty/hudi-jars/hudi-spark3-bundle_2.12-0.9.0.jar,\
/home/hty/hudi-jars/spark-avro_2.12-3.0.1.jar,/home/hty/hudi-jars/spark_unused-1.0.0.jar.jar \
--conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"

可以看到三个 jar 包都上传成功:

导包并设置存储目录:
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "hudi_trips_cow"
val basePath = "hdfs://hadoop102:8020/datas/hudi-warehouse/hudi_trips_cow"
val dataGen = new DataGenerator

模拟产生Trip乘车数据
val inserts = convertToStringList(dataGen.generateInserts(10))


3.将模拟数据List转换为DataFrame数据集
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
4.查看转换后DataFrame数据集的Schema信息
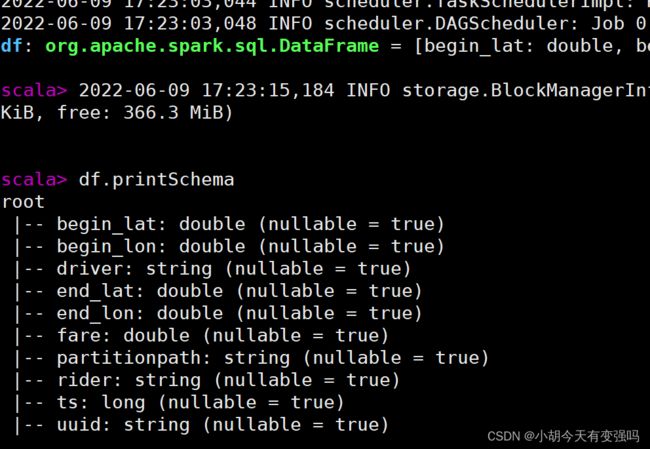
5.选择相关字段,查看模拟样本数据
df.select("rider", "begin_lat", "begin_lon", "driver", "fare", "uuid", "ts").show(10, truncate=false)

插入数据
将模拟产生Trip数据,保存到Hudi表中,由于Hudi诞生时基于Spark框架,所以SparkSQL支持Hudi数据源,直接通 过format指定数据源Source,设置相关属性保存数据即可。
df.write
.mode(Overwrite)
.format("hudi")
.options (getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD_OPT_KEY, "ts")
.option(RECORDKEY_FIELD_OPT_KEY, "uuid")
.option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath")
.option(TABLE_NAME, tableName)
.save(basePath)
getQuickstartWriteConfigs,设置写入/更新数据至Hudi时,Shuffle时分区数目
PRECOMBINE_FIELD_OPT_KEY,数据合并时,依据主键字段
RECORDKEY_FIELD_OPT_KEY,每条记录的唯一id,支持多个字段
PARTITIONPATH_FIELD_OPT_KEY,用于存放数据的分区字段
paste模式,粘贴完按ctrl + d 执行。

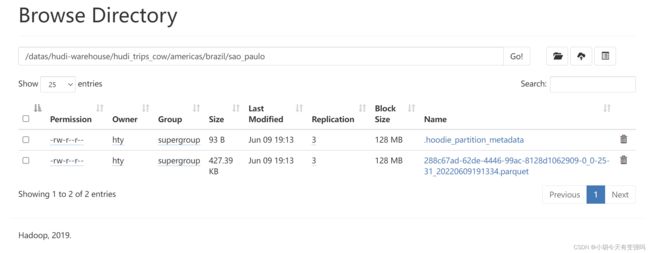
Hudi表数据存储在HDFS上,以PARQUET列式方式存储的
从Hudi表中读取数据,同样采用SparkSQL外部数据源加载数据方式,指定format数据源和相关参数options:
val tripSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
其中指定Hudi表数据存储路径即可,采用正则Regex匹配方式,由于保存Hudi表属于分区表,并且为三级分区(相 当于Hive中表指定三个分区字段),使用表达式://// 加载所有数据。
查看表结构:
tripSnapshotDF.printSchema()

比原先保存到Hudi表中数据多5个字段,这些字段属于Hudi管理数据时使用的相关字段。
将获取Hudi表数据DataFrame注册为临时视图,采用SQL方式依据业务查询分析数据:
tripSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
利用sqark SQL查询
spark.sql("select fare, begin_lat, begin_lon, ts from hudi_trips_snapshot where fare > 20.0").show()

查看新增添的几个字段:
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, _hoodie_file_name from hudi_trips_snapshot").show()
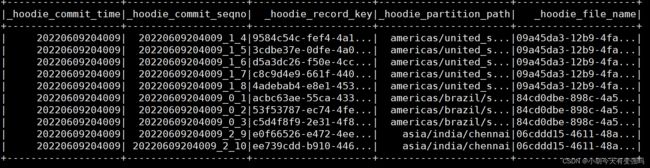
这几个新增添的字段就是 hudi 对表进行管理而增添的字段。
参考资料:
https://www.bilibili.com/video/BV1sb4y1n7hK?p=16&spm_id_from=pageDriver&vd_source=e21134e00867aeadc3c6b37bb38b9eee