揭秘内存暴涨:解决大模型分布式训练OOM纪实
在现代深度学习开发中,我们通常依赖其他模块,像搭积木一样构建复杂的软件系统,这个过程往往快速且有效。然而,如何在遇到问题时迅速定位和解决问题,由于系统的复杂性和耦合性,一直困扰着深度学习系统设计和维护者。
作为爱奇艺后端技术团队的一员,我们详细记录了一次解决深度学习训练内存相关问题的过程,希望为正努力解决棘手问题的同行提供一些启示。
01
背景
过去的一个季度中,我们一直在A100集群观察到随机的cpu内存oom现象。随着大模型训练的引入,oom更加的令人难以忍受,使得我们下定决心要解决这个问题。
回望来路,一时间觉得豁然开朗。事实上我们也曾经很接近问题的真相,不过当时缺乏足够的想象力而错过。
02
过程
在最开始的阶段,我们对历史log进行了归纳分析。发现了若干规律,对最后的解决有很好的指导意义:
这个是A100集群中遇到的新问题,其他集群没遇到过
问题和pytorch的ddp分布式训练有关;使用pytorch的其他训练模式没有遇到
这个oom问题相当随机,有的3个小时遇到,有的1个多星期才遇到
内存在oom的时候以暴涨形式发生,基本上1分半内完成从10%到90%的涨幅,如下图所示:
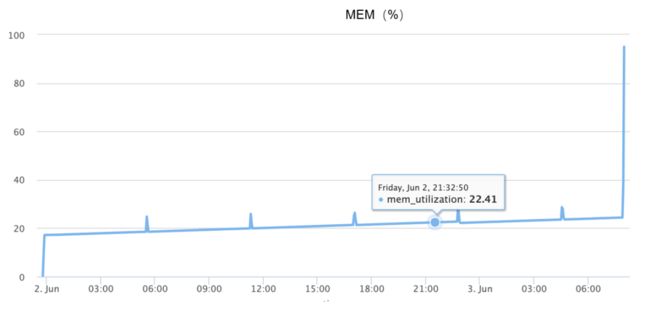
虽然有以上信息,但是由于问题基本不能可靠复现,开始阶段完全是靠发散的想象;猜了很多可能的原因,比如:
会不会是代码问题,因为object没有回收,导致持续的内存泄露?
会不会是底层的内存分配器问题,类似因为glibc的PTMALLOC分配器的碎片过多,所以在某个时刻,突发的内存请求导致了持续的内存分配?
会不会是硬件的问题?
会不会是软件特定版本的 bug?
下面我们对前两个假设进行具体的介绍。
是代码的问题吗?
为了研判是否是代码的问题,我们在出现过问题的场景上加入调试代码,并周期性的进行调用。如下代码会打印出目前python gc模块所不能回收的所有object。
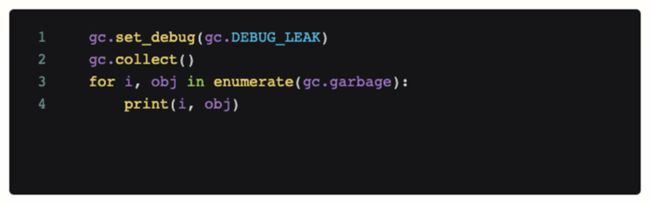 但追加了该代码之后,得到的log研判,oom的时候并没有占用大量内存的unreachable object存在,且持续的gc也不能缓解oom本身。所以至此我们的第一个猜想破产,问题不是代码(内存泄漏)引起的。
但追加了该代码之后,得到的log研判,oom的时候并没有占用大量内存的unreachable object存在,且持续的gc也不能缓解oom本身。所以至此我们的第一个猜想破产,问题不是代码(内存泄漏)引起的。
是内存分配器引起的吗?
在这个阶段,我们引入了jemalloc内存分配器,它的优势和glibc默认的PTMALLOC相比,在于可以提供更有效率的内存分配,以及对于内存分配本身调试更好的支持,由此可以实现:
会不会是默认内存分配器的问题
更好的调试和分析手段
为了不修改torch本身的代码,以及在python中直接查看jemalloc目前的状态,我们使用了ctypes来将jemalloc的接口直接在python中进行暴露:

这样我们把这段代码放到一个函数内,就可以周期性的获知目前jemalloc接收来自于上层的请求【allocated】,以及它向系统请求的实际物理内存的大小【mapped】。
经过实际的复现过程中,最终发现allocated和mapped这两个数值在发生OOM时非常接近。所以我们对于内存碎片的假说也因此破产。
究竟是什么问题引起的?
在山穷水尽疑无路的时候,再一次对已有OOM的log进行了梳理,发现有一个之前没有被重点分析的方向:即我们有若干次多台机器在相近的时间(相邻1-2分钟)发生OOM。
那么有什么合理的解释来说明这种神奇的同步性?普通的bug应该不会引起如此的同调性反复发生。所以他们之间可能存在某种必然关联。
那么这种关联性来源于何处?对于这个问题的探索,分析的视角移向分布式训练上的网络通信上。
最开始对于通信的怀疑还是针对出现OOM的机器,怀疑它们之间因为某种原因产生了通信,进而导致彼此出现问题,所以在日常训练中,加入了tcpdump,对网络流量进行监控。
终于在加入tcpdump之后一次OOM中,抓到了最值得怀疑的一次通信。即在发生问题若干分钟之前,OOM的机器接收到了安全扫描流量。
03
最终定位
在抓到安全团队扫描这个怀疑对象之后,我们协同安全团队一起进行分析,最终发现,能够根据扫描稳定复现OOM问题,所以触发原因已经八九不离十了。但是,到了这里,我们只是能够复现以及变更安全扫描策略规避OOM问题,还需要进一步对代码进行分析并最终定位。
经过对代码分析以及定位,最终确定问题点在于pytorch的DDP分布式训练协议,相关代码如下:
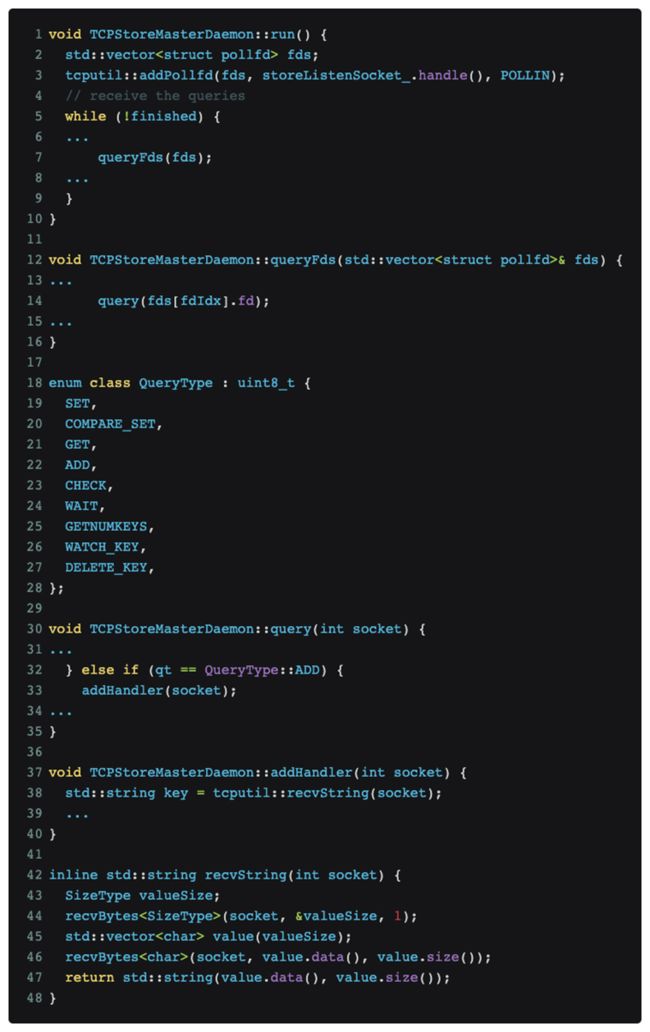
如上图所示,pytorch分布式训练在master端口持续监听消息。

Nmap扫描【nmap -sS -sV】正好触发到了QueryType::ADD这个消息类型,也就是上图tcpdump所示data部分的绿框数字【03】,进而导致pytorch尝试使用recvString这个函数预分配一段buffer,来接受它认为的后续消息。但这个buffer长度是使用【03】后面的一个uint64_t[little-endian]类型来进行解析的,也就是红框数字【e0060b0000】,即962174058496字节,这个数值被理解为将要接收1T数据,pytorch向内存分配器请求了相应内存之后,内存分配器向内核进一步请求相应的物理页。而由于我们的gpu训练集群没有配置巨页表,因此Linux只能按照4K粒度来逐渐在缺页中断中来满足内存分配器的1T内存请求,也就是大概需要1分钟左右来分配所有内存,和前面观察到的OOM大概发生在1分钟左右的快速内存增长对应。
04
解决方案
知道前因后果之后,解决方案也变得自然而然:
1. 短期:变更安全扫描策略规避
2. 长期:和社区沟通加强 pytorch DDP 协议的健壮性【1】
05
总结
在完成对于OOM问题的调查过程回溯之后,我们发现在这个过程中,我们实际上对于内存相关的工具和调试方法已经做了一轮有效的测试。
在这个过程中,我们发现有一些通用的点可以为后续的研发所借鉴:
Jemalloc对于内存问题能够起到很有效的定量分析,能够捕捉到对于python+C这种混合编程系统中底层内存的相关问题。
Memray。我们在调试过程中给予它很高的期望,但最终发现memray能够发挥最好的领域还是处在纯python侧,对于pytorch DDP这种混合编程系统力有不逮。
有的时候还是需要从更大的维度来思考问题。比方如果不把和外部无关服务通信过程拉进来考虑,就不会发现真正的根本原因。
【1】https://github.com/pytorch/pytorch/issues/106294

也许你还想看
Spring Cloud Gateway下的GC停顿排查之旅
爱奇艺海外运营系统的设计和实践
爱奇艺数据湖实战