第二十二章 原理篇:UP-DETR
最近一直在忙各种各样的面试,顺便重新刷了一遍西瓜书。
感觉自己快八股成精了,但是一到写代码的环节就拉跨,人真是麻了。
许愿搬家前可以拿到offer!
参考教程:
https://arxiv.org/pdf/2011.09094.pdf
https://zhuanlan.zhihu.com/p/398940573
https://github.com/dddzg/up-detr
https://bbs.huaweicloud.com/blogs/181241
Unsupervised Pre-training for Detection Transformers
- 背景
-
- 自监督学习
- UP-DETR
- 方法
-
- 预训练
-
- Encoder
- Decoder
- Multi-query Patches
- Patch feature reconstruction
- Attention mask
- Loss
- 微调
- 代码实现
-
- UP-DETR
-
- __init__()
- forward()
- backbone
- dataset
- loss
背景
自监督学习
首先要来了解一下自监督学习的概念。
自监督学习是属于无监督学习的一种,具体来说它使用的是无标签数据,并通过挖掘自身的特征作为监督信号,实现一个自己向自己学习的效果。其中也涉及到一些术语。
- pretext task:前置任务,又称为代理任务。是指为了达到某种任务目的而设置的间接任务,任务中的监督信号是基于数据本身生成的。
- pseudo label:伪标签,是指在pretext task中生成的数据标签。
- downstream task:下游任务。一般用pretext task做预训练,downstream task是指预训练好的模型的迁移任务,也就是我们常说的fine-tune。
Unsupervised pre-training models always follow two steps: pretraining on a large-scale dataset with the pretext task and finetuning the parameters on downstream tasks.
常用的pretext task可以分成四类。【这里可能写的不准,因为分类方法多种多样】
- Generation-based:基于生成的方法。比如说AE自编码机,它的输出对象就是输入本身,在重建输入的过程中学习对输入的表征。
- Context-based:基于上下文信息的方法。比如说我们之前提到的word2vec,它通过周围的词来预测中心词/通过中心词来预测周围词。
- Contrastive based:基于对比学习的方法。它是通过比较两个事物的相似性来进行编码的,通过人为构建正负样本并评估样本间距离,在实现自监督学习的效果。
- Cross model-based:基于多模态的数据的方法,比如说使用图像和它对应的文字标注作为输入,看这两个是否匹配。
总的来说,自监督学习就是使用数据本身构建一个约束,一个目标,在达成这个目标的过程中促使网络学习图像的表征。这个目标不能设计的太简单,不然就达不到目的,也不能设计的太难,否则训练就无法收敛。
UP-DETR
DETR目标检测模型使用transformer的encoder-decoder的结构,在目标检测任务上取得非常好的效果,它把目标检测当成一个集合预测的问题来做,不需要手动进行一些样本选择,也省去了复杂的后处理的过程。然而它也有一些transformer的缺点,比如说需要的训练数据数量多,再比如说训练很慢。在数据量不足的情况下,DETR表现得就有点不尽人意。
作者认为,在DETR总,所使用的backbone是已经经过了预训练的,并且能够从图片中提取出一个还不错的视觉表达,但是其中的transforer模块是还没有经过预训练的。因此作者们提出了一个对DETR中transformer进行预训练的方法,命名为random query patch detection。这是一个专门针对transformer模型的pretext task。
为什么常见的预训练方法不能应用到transformer上呢?作者给出了两个原因。
- 不同的架构。通常的前置任务都是设计来进行backbone的预训练,让backbone能够完成图像特征的提取。但是DETR不仅有backbone,还包括了一个transformer。
- 不同的特征倾向。DETR中的transformer关注于空间定位的学习。而目前常用的前置任务都关注于特征的判别,而不是空间定位。
因此,这篇论文的核心目的就是为DETR中的transformer构建一个用于预训练的空间定位任务:从给定图像中随机crop多个patch,并预训练transformer对这些patch进行定位。这个想法比较简单,但是实际操作中还是出现了一些问题,这些问题也被作者成功解决了。
作者总结了两个重要的问题:
- Multi-task learning:目标检测本身是一个组合型的任务,既包括了分类也包括了定位。而这两个任务图像的关注其实是不同的,分类任务更关注图像的纹理材质等,而检测任务更关注图像的边界。为防止patch detection的任务破坏已经学习的分类特征,作者引入了frozen pre-training backbone的方法和patch feature reconstruction来维持transformer的特征判别能力。
- Multi-query localization:多框定位问题。不同的queries关注不同的位置和框的大小。‘’对object query进行了显式的分组,以此适配多框的定位。使得预训练的任务和下游的目标检测 更加的贴合。‘’ 【原论文的这一部分写的有点模糊,所以先引用一下作者的解释。】
方法
UP-DETR包括了预训练和微调两个步骤,首先在大规模数据上进行无监督预训练,然后在标记好的数据上进行微调。
预训练
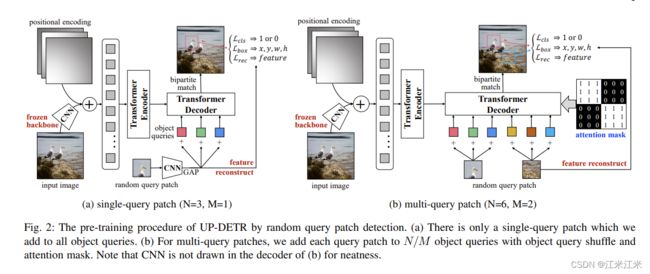
先来看一下论文中给出的预训练原理图。分成了single-query patch和multi-query patch两种。两者的encoder部分没有什么区别,都是原始图像经过CNN获得特征后加上一个position encoding然后送入到transformer的encoder中去。区别主要体现在decoder的部分。
左半边是single-query的例子。其中N是object query的数量,M是裁剪出来的patch的数量。这个patch同样送入预训练好的backbone中得到一个特征,后面再接上一个global average pooling进行降维。降维得到的query,会和object query叠加在一起,作为decoder的输入。
右半边是multi-query patch的例子,对于N个object query和M个patch,需要把每个patch加到 N ÷ M N\div M N÷M个queries中去。相比于单patch, multi patch还增加了一个额外的注意力mask。
此外,除了分类和定位的loss外,预训练过程中还增加了一个新的loss,也就是reconstruction loss。
Encoder
给定一个输入图像,backbone提取它的视觉表达,得到一个大小为 C × H × W C\times H\times W C×H×W的输出。每个图象被当作一个长度为 H × W H\times W H×W的token。然后加上一个position encoding就可以送到多层encoder中去了。
Decoder
在预训练阶段,随即从输入图像中裁剪patch作为query,并记录对应的坐标和宽高作为ground truth。因此预训练的过程可以作为一个非监督的实现。对于随即裁剪的query patch,CNN的backbone会得到它的特征,这个特征和object queries组合在一起,再传入decoder。decoder被训练来预测这个patch在输入图像中对应的位置。
Multi-query Patches
每个图片在通常不止一个物体,而是多个。为了保证预训练和微调过程的一致性,UP-DETR也需要构建一个多multi-query patch的检测。假设这里有M个patch和N个object queries,作者把N个object queries分成M组,每个patch query会被分到 N ÷ M N\div M N÷M个object queries中去。
Patch feature reconstruction
预训练任务主要关注的是定位而不是分类,在预训练中虽然也有二分类的分类头,但是这个分类和图像的类别没有任何关系。所以作者提出了一个patch feature reconstruction的loss,在定位的预训练中尽可能的保留分类特征。
Attention mask
所有的patch都是随机裁剪得到的,因此他们彼此之间是独立的,也就说是第一个patch得到的box和第二个是没啥关系的。为了满足patch query的独立性,使用一个attention mask来控制object patch之间的交互。
从这个图中来说,这个attention mask的作用是简单的表示了两个object query是否来自同一个组,是否对应的是同一个patch query。

这个attention mask在计算中会被加到decoder的自注意力中去 s o f t m a x ( Q K T / ( d k ) + X ) V softmax(QK^T/\sqrt(d_k)+X)V softmax(QKT/(dk)+X)V。
X的计算方式,具体来说,如果来此同一个组,则为0,否则为-float(‘inf’)
Loss
预测的结果 y i ^ = ( c i ^ , b i ^ , p i ^ ) \hat{y_i} = (\hat{c_i},\hat{b_i},\hat{p_i}) yi^=(ci^,bi^,pi^)包括三个元素,其中 c i ^ \hat{c_i} ci^便是patch匹配的二分类。 b i ^ \hat{b_i} bi^是一个定义了目标位置和宽高的向量{x,y,w,h}, p i ^ \hat{p_i} pi^是特征重建的结果。
L ( y , y ^ ) = ∑ i = 1 N [ λ c i L c l s ( c i , c i ^ ) + 1 c i = 1 L b o x ( b i , b i ^ ) + 1 c i = 1 L r e c ( p i , p i ^ ) ] L(y,\hat{y}) = \sum_{i=1}^N[\lambda_{{c_i}}L_{cls}(c_i,\hat{c_i}) + 1_{c_i = 1}L_{box}(b_i,\hat{b_i} ) + 1_{c_i=1}L_{rec}(p_i,\hat{p_i})] L(y,y^)=i=1∑N[λciLcls(ci,ci^)+1ci=1Lbox(bi,bi^)+1ci=1Lrec(pi,pi^)]
微调
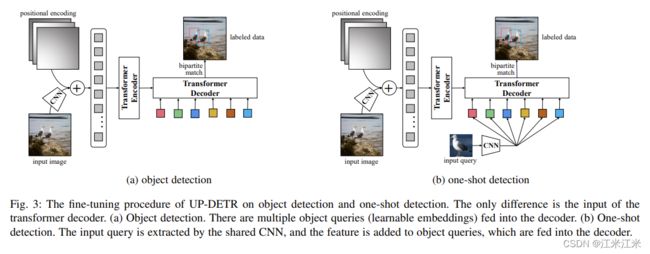
看一下论文中给出的微调的原理图。论文中提到UP-DETR可以很简单地在目标检测任务和one-shot任务上进行微调。
左半边是object detection,就是正常的DETR的训练过程,使用CNN获得特征后送入encoder,decoder的输入是多个object query。
右半边是one-shot detection的例子。使用CNN提取目标物体的特征,然后把它加到object queries上,送入decoder中,最终预测出来的就是图像中对应目标的位置。
代码实现
代码部分主要参考源码:https://github.com/dddzg/up-detr。
在微调部分,因为使用的是和DETR一样的模型和一样的步骤,所以这一部分是没有什么区别的。我们主要看一下预训练的UP-DETR部分是怎么完成的。
首先来回顾一下UP-DETR的预训练步骤。
- 使用backbone提取图像特征:这里用的是最深层的featuremap。
- 创建position embedding。这个embedding主要在encoder相关的部分使用。
- transformer encoder结构,主要用于进行一个全局特征的提取。
- 从输入图像中获取patch,使用backbone提取特征并处理
- 创建object query。这个也可以看作一个position embedding,主要在decoder相关的部分使用。object query要和patch query组合在一起,作为decoder的输入。
- 预测结果,并进行loss的计算。
- patch query存在一个reconstruction的过程。
- 如果是多patch query的情况,还有一个额外的attention mask。
UP-DETR
先来看一下和DETR相比,UP-DETR增加了哪些部分。
- patch query的获取。
- patch query的reconstruction
- multi patch query的attention mask
- 可能涉及到了自监督标签的生成的部分。
init()
class UPDETR(DETR):
""" This is the UPDETR module for pre-training.
UPDETR inherits from DETR with same backbone,transformer,object queries and etc."""
def __init__(self, backbone, transformer, num_classes, num_queries, aux_loss=False,
feature_recon=True, query_shuffle=False, mask_ratio=0.1, num_patches=10):
UPDETR这个类,直接继承了DETR这个类。因为它的修改的部分没有涉及到模型本身,所以模型直接使用DETR就可以。它的传入参数包括:
- backbone:你打算使用的backbone
- transformer:构造好的transformer
- num_classes:数据集中物体种类的数量。
- num_queries:object queries的数量,也就代表了每张图中能预测的物体的最大数量。
- aux_loss:是否要使用aux_loss。
和DETR是一样的。
super().__init__(backbone, transformer, num_classes, num_queries, aux_loss)
这些传入参数主要是用来实例化我们的DETR。
具体来看一下UP-DETR的初始化做了什么。
hidden_dim = transformer.d_model
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # pooling used for the query patch feature
# align the patch feature dim to query patch dim.
self.patch2query = nn.Linear(backbone.num_channels, hidden_dim)
self.num_patches = num_patches
self.mask_ratio = mask_ratio
self.feature_recon = feature_recon
if self.feature_recon:
# align the transformer feature to the CNN feature, which is used for the feature reconstruction
self.feature_align = MLP(hidden_dim, hidden_dim, backbone.num_channels, 2)
self.query_shuffle = query_shuffle
assert num_queries % num_patches == 0 # for simplicity
query_per_patch = num_queries // num_patches
# the attention mask is fixed during the pre-training
self.attention_mask = torch.ones(self.num_queries, self.num_queries) * float('-inf')
for i in range(query_per_patch):
self.attention_mask[i * query_per_patch:(i + 1) * query_per_patch,
i * query_per_patch:(i + 1) * query_per_patch] = 0
可以看到我们之前提到的patch query的生成,attention mask的生成和reconstruction layer都是在这里初始化的。我们分开来看。
-
patch query
self.patch2query = nn.Linear(backbone.num_channels, hidden_dim) # self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.patch2query是用于处理backbone输出的feature map。
-
attention mask
query_per_patch = num_queries // num_patches self.attention_mask = torch.ones(self.num_queries, self.num_queries) * float('-inf') for i in range(query_per_patch): self.attention_mask[i * query_per_patch:(i + 1) * query_per_patch, i * query_per_patch:(i + 1) * query_per_patch] = 0假设有n个queries,m个patch,那么一共会分成n/m组。attention mask描述的是object queries之间的关系,所以它的大小是n*n,初始值是-float(‘inf’),对于来自同一个组的object query,它们的值被改为0。
-
reconstruction layer
self.feature_recon = feature_recon if self.feature_recon: # align the transformer feature to the CNN feature, which is used for the feature reconstruction self.feature_align = MLP(hidden_dim, hidden_dim, backbone.num_channels, 2)在使用patch query的时候,cnn的backbone的输出特征维度为num_channels,被降维成hidden_dim,使用MLP将其复原后原来的维度,用于比较。
forward()
然后来看一下UP-DETR的forward()部分做了什么。
def forward(self, samples: NestedTensor, patches: torch.Tensor):
它的输入除了代表图像的samples外,还有一个代表剪切出来的图像的patches。
samples consists of:
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
patches is a torch Tensor, of shape [batch_size x num_patches x 3 x SH x SW]
The size of patches are small than samples
也就是说我们输入的图像大小是[batch_size, 3, H, W],我们输入的patch的大小是[batch_size, num_patch, 3, SH, SW]。
我们一步一步来看看forward过程。
-
首先encoder的输入部分相对于DETR来说是没有什么改变的。输入一组图像,并获得它们经过backbone后提取到的feature。还有针对featuremap得到的position encoding。
batch_num_patches = patches.shape[1] if isinstance(samples, (list, torch.Tensor)): samples = nested_tensor_from_tensor_list(samples) features, pos = self.backbone(samples) src, mask = features[-1].decompose() assert mask is not None -
进行对patch的处理,使用backbone获得patch的特征,并转成patch query。同样是使用backbone最后一层的输出,然后使用一个avgpool池化后得到大小为[batch_size * nun_patches, C, 1,1]的输出,并且flatten。
bs = patches.size(0) # 初始patch的大小为[b,n,c, sh, sw] patches = patches.flatten(0, 1) # flatten后大小为[b*n,c,sh,sw] patch_feature = self.backbone(patches) # 得到特征 patch_feature_gt = self.avgpool(patch_feature[-1]).flatten(1)flatten后的patch_feature大小为[batch_sizenum_patches, C],使用线性层进行降维,变成[batch_sizenum_patches, hidden_dim],也就是和object query维度一样的embedding。再变回[batch_size, num_patches, hidden_dim]。因为每个object queries都要分配一个patch,所以要按照组进行repeat。
patch_feature = self.patch2query(patch_feature_gt) \ .view(bs, batch_num_patches, -1) \ .repeat_interleave(self.num_queries // self.num_patches, dim=1) \ .permute(1, 0, 2) \ .contiguous()如果需要shuffle的话,还要增加一步。
idx = torch.randperm(self.num_queries) if self.query_shuffle else torch.arange(self.num_queries) -
构建输入,传入transformer。
transformer的encoder的输入,和DETR中没有区别。仍然是self.input_proj(src),而原本的object query使用的是self.query_embed,在这里要和我们的patch_feature组合在一起使用。并且在decoder的计算中,还要使用attention mask来处理不同object query的关系。mask_query_patch = (torch.rand(self.num_queries, bs, 1, device=patches.device) > self.mask_ratio).float() # mask some query patch and add query embedding patch_feature = patch_feature * mask_query_patch \ + self.query_embed.weight[idx, :].unsqueeze(1).repeat(1, bs, 1) hs = self.transformer( self.input_proj(src), mask, patch_feature, pos[-1], self.attention_mask.to(patch_feature.device))[0] -
输出部分。对于分类和回归,仍是和之前一样的处理。然后加上重建的部分。
outputs_class = self.class_embed(hs) outputs_coord = self.bbox_embed(hs).sigmoid() outputs_feature = self.feature_align(hs)
backbone
backbone的代码部分有一点细微的调整。在UP-DETR的forward中其实已经体现出来了。
features, pos = self.backbone(samples)
patch_feature = self.backbone(patches)
在这里samples是一个NestedTensor,backbone对它的输出结果是feature和pos;patches是一个tensor,backbone对它的输出结果只有feature。
这个更改主要是在joiner的forward中。
def forward(self, tensor_list):
"""supports both NestedTensor and torch.Tensor
"""
if isinstance(tensor_list, NestedTensor):
xs = self[0](tensor_list)
out: List[NestedTensor] = []
pos = []
for name, x in xs.items():
out.append(x)
# position encoding
pos.append(self[1](x).to(x.tensors.dtype))
return out, pos
else:
return list(self[0](tensor_list).values())
dataset
在数据处理上,主要增加的部分是对于每一个图像,要从中裁剪出一些patch,并返回patch和它对应的位置。
def get_random_patch_from_img(img, min_pixel=8):
"""
:param img: original image
:param min_pixel: min pixels of the query patch
:return: query_patch,x,y,w,h
"""
w, h = img.size
min_w, max_w = min_pixel, w - min_pixel
min_h, max_h = min_pixel, h - min_pixel
sw, sh = np.random.randint(min_w, max_w + 1), np.random.randint(min_h, max_h + 1)
x, y = np.random.randint(w - sw) if sw != w else 0, np.random.randint(h - sh) if sh != h else 0
patch = img.crop((x, y, x + sw, y + sh))
return patch, x, y, sw, sh
loss
原有的loss主要是class_loss和bbox_loss,预训练阶段增加了一个新的reconstruction loss。
def loss_feature(self, outputs, targets, indices, num_boxes):
"""Compute the mse loss between normalized features.
"""
target_feature = outputs['gt_feature']
idx = self._get_src_permutation_idx(indices)
batch_size = len(indices)
target_feature = target_feature.view(batch_size, target_feature.shape[0] // batch_size, -1)
src_feature = outputs['pred_feature'][idx]
target_feature = torch.cat([t[i] for t, (_, i) in zip(target_feature, indices)], dim=0)
# l2 normalize the feature
src_feature = nn.functional.normalize(src_feature, dim=1)
target_feature = nn.functional.normalize(target_feature, dim=1)
loss_feature = F.mse_loss(src_feature, target_feature, reduction='none')
losses = {'loss_feature': loss_feature.sum() / num_boxes}
return losses