chatglm2外挂知识库问答的简单实现
一、背景
大语言模型应用未来一定是开发热点,现在一个比较成功的应用是外挂知识库。相比chatgpt这个知识库比较庞大,效果比较好的接口。外挂知识库+大模型的方式可以在不损失太多效果的条件下获得数据安全。
二、原理
现在比较流行的一个方案是langchain+chatglm,这已经算是一个成品了,也可以考虑自己上手捏一下泥巴,langchain学习成本有点高,可以直接利用prompt来完成问问题会简单很多。具体方案我参考了这个文章:大模型外挂(向量)知识库 - 知乎 (zhihu.com) 基本的思路简化成这张图
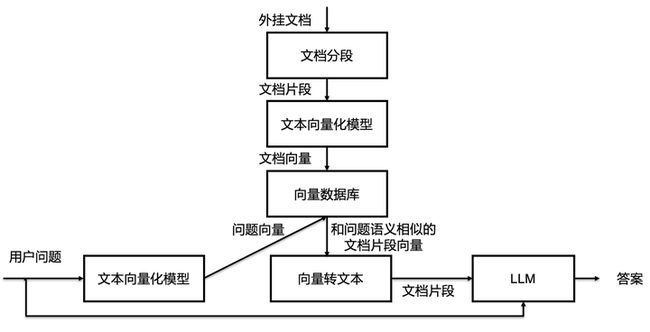
简单的说就是根据用户问题,从知识库获取与“问题”相关的“文档片段”, 让大模型根据文档片段来回答“问题”。其实这种根据指定内容回答问题的模型也是挺成熟的,至少huggingface上就有很多,只不过那些模型是根据BERT模型+QA数据集微调好的。我们相信chatglm这类大模型理解问题和总结内容的能力一定更强。
这里就涉及到一个如何获取“问题”相关的“文档片段”的过程了,其实可以直接用文本检索方式,但传统的全文检索由于是词的匹配,因此对纯粹的问句效果可能不好。因此现在主流的方式是用向量匹配,就是把“问题”和知识库的文本都转成向量,再用向量的近似搜索获取更为相关的结果。
应用这种方式会很容易想到一个问题,也是上面知乎文章中提到的对称语义检索。即一定会把与“问题”接近的语句作为第一返回,它只是文字表述和问题一样,但并不是问题的答案。例如

也许这不是个问题,因为谁会在知识库里留下大量问句呢?或者你可以通过预处理把问题和大量正文绑定起来就不会匹配出“问题”了。所以使用向量的效果到底比纯粹的全文检索是否更好我也不清楚,毕竟检索效果还和预处理时候文本片段的切割、向量转换、向量最近邻查询效果 有关系。
三、实现
这里我直接使用了text2vec + chromadb简单实现。text2vec负责对文本转为向量, chromadb负责进行向量检索。
text2vec地址在shibing624/text2vec-base-chinese · Hugging Face ,预训练模型不算大
chromadb是一个新出的向量数据库,很多功能不完善,只是为了快速地体验一下向量存储检索功能, Getting Started | Chroma (trychroma.com)
本来功能是想做成一个独立于大模型服务的服务:

但是还是有点麻烦,最后还是选择直接在chatglm原生的客户端里直接加向量存储和检索的功能。就是直接在内存里完成,也就是下图绿色的部分就行了。
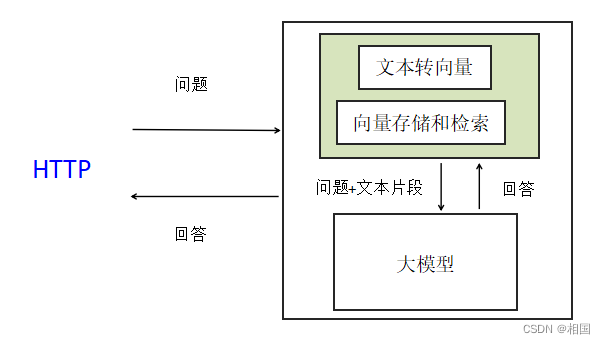
代码就增加三处。1. 知识库读取、转换、存chromadb;2. 问题转换、检索chromadb、获得文本片段;3. prompt改成“问题+文本片段”
#.....
import glob
import chromadb
from text2vec import SentenceModel
#.....
@st.cache_resource
def get_vectordb():
model = SentenceModel('shibing624/text2vec-base-chinese')
client = chromadb.Client()
texts = []
for filename in glob.glob(f"texts/*.txt"):
with open(filename, encoding='utf-8') as f:
texts.append(f.read())
embeddings = model.encode(texts).tolist()
collection = client.get_or_create_collection("testname")
ids = [f'id{x+1}' for x in range(len(texts))]
collection.add(ids=ids, embeddings=embeddings, documents=texts)
return collection, model
def query_related(text:str, model:SentenceModel, coll):
embedding = model.encode(text).tolist()
result = coll.query( query_embeddings=embedding, n_results=1)['documents']
return result[0][0]
#.....
collection, t2v = get_vectordb()
#...改大max_length
max_length = st.sidebar.slider(
'max_length', 0, 32768, 32768, step=1
)
#.....
if button:
input_placeholder.markdown(prompt_text)
related_text = query_related(prompt_text, t2v, collection)
prompt_text = f"'''\n{related_text}\n''' \n请从上文提取信息并回答:“{prompt_text}”"
代码难度不大,一开始读取text2vec时候就把本地texts目录里的文本读取出来并转为向量。这里我是每一篇文本转一个向量,查询到最近似的也只保留首个文档。 可能按段落分割更好,如果是按段落,那么查询到多个文本片段可以按需要拼接起来。
我把代码开源在gitee上:llm_simple-kb-plugin: chatglm2外挂知识库的简单实现, 这是直接在web_demo2.py上修改的 (gitee.com)
四、结果
问个问题:“向量数据库是什么?” ,原版chatglm2的回答:

很显然是这些年与数据库信息相关内容的总结。
这是增加了相关文章以后的效果:

感觉chatglm2-6B的总结能力还是有点弱,我的文章列了12个向量数据库,这里并没有提取完,虽然它只会给10条,但是前3个不知道哪里推导出来的。
五、总结
实验出来效果比想象中还是要差,我猜测原因主要有两个,一是大模型参数不够,涌现不出来。二是涉及对信息加工的中间过程,越多参与的中间步骤造成的精度损失会成倍放大。目前看起来大模型应用要实现工业化要求,可能还是比想象中要难,这只是一个外挂知识库让大模型做总结的功能而已,但是未来想象空间还是很大的,我也相信如我开篇所说:大语言模型应用未来一定会是开发热点。