7、Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
简介
主页:https://imagen.research.google/
文本提示图片生成已经有很多工作了,如DALLE系列、stable diffusion
论文经过实验发现:
- 在纯文本语料库上预训练的通用大型语言模型(例如T5)在编码用于图像合成的文本方面惊人地有效
- 在Imagen中增加语言模型的大小比增加图像扩散模型的大小更能提高样本保真度和图像文本对齐

贡献点 - 仅在文本数据上训练的大型冻结语言模型对于文本到图像的生成是非常有效的文本编码器,并且缩放冻结文本编码器的大小比缩放图像扩散模型的大小更能显著提高样本质量。
- 提出动态阈值化,一种新的扩散采样技术,以利用高指导权重,生成比以前更逼真和更详细的图像
- 强调了几个重要的扩散架构设计选择,并提出了高效的U-Net,一种新的架构变体,更简单,收敛更快,内存效率更高
Imagen由一个将文本映射到一系列嵌入的文本编码器和一个将这些嵌入映射到分辨率不断增加的图像的条件扩散模型级联组成
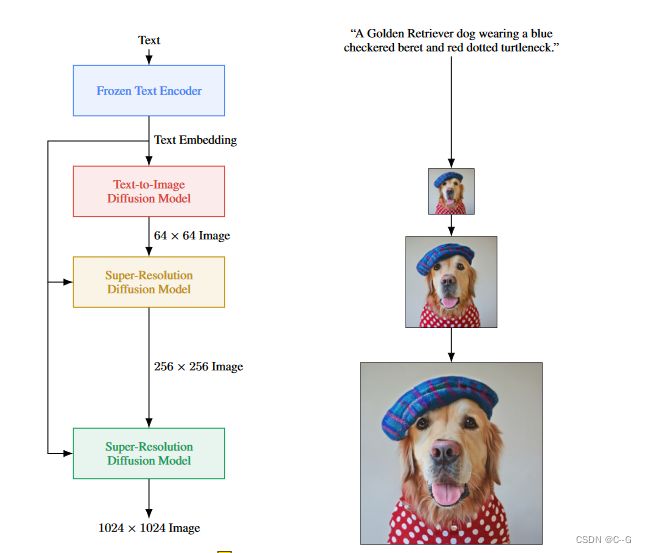
Imagen使用冻结的文本编码器将输入文本编码为文本嵌入。条件扩散模型将文本嵌入映射到64 × 64图像。Imagen进一步利用文本条件超分辨率扩散模型对图像进行上采样,首先是64 × 64→256 × 256,然后是256 × 256→1024 × 1024
Pretrained text encoders
冻结有几个优点,如嵌入的离线计算,导致在训练文本到图像模型期间的计算或内存占用可以忽略不计
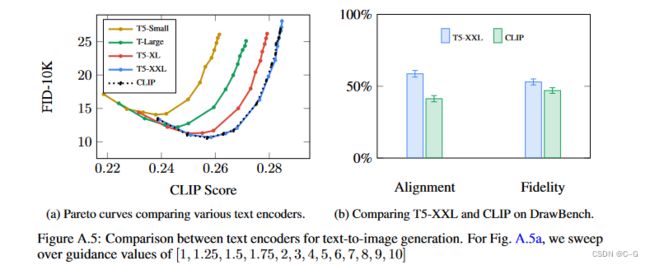
实验了目前常见的 BERT(base,large),T5(small,base,large,XL,XXL),CLIP(ViT-L/14)模型
BERT在一个较小的纯文本语料库(约20 GB, Wikipedia和BooksCorpus)上进行训练,具有掩码目标,并且具有相对较小的模型变体(高达340M参数)
T5在具有去噪目标的更大的C4纯文本语料库(约800 GB)上进行训练,并具有更大的模型变体(多达11B个参数),对于T5,使用编码器部分进行上下文嵌入
CLIP模型在具有图像-文本对比目标的图像-文本语料库上进行训练,对于CLIP,使用文本编码器的倒数第二层来获得上下文嵌入
diffusion model 固定为 64 × 64 64 \times 64 64×64,300M参数大小。
实验表明
- 缩放语言模型文本编码器的大小通常会导致更好的图像-文本对齐
- 大型冻结文本编码器对文本到图像模型有效
缩放语言模型文本编码器的大小通常会导致更好的图像-文本对齐
使用最大的文本编码器T5-XXL (4.6B参数)训练的Imagen产生了最好的结果

虽然扩大扩散模型U-Net的大小可以提高样本质量,但发现扩大文本编码器的大小比U-Net的大小更有影响


Diffusion models and classifier-free guidance
扩散模型通过迭代去噪过程将高斯噪声转换为学习到的数据分布的样本,公式如下
![]()
( x , c ) (x,c) (x,c)为数据条件对, t ∼ μ ( [ 0 , 1 ] ) , ϵ ∼ N ( 0 , I ) t \sim \mu([0,1]),\epsilon \sim N(0,I) t∼μ([0,1]),ϵ∼N(0,I),此外 α t , σ t , ω t \alpha_t,\sigma_t,\omega_t αt,σt,ωt是影响样品质量的 t 的函数
Classifier guidance
在采样过程中使用预训练模型 p ( c ∣ z t ) p(c|z_t) p(c∣zt) 的梯度来降低条件扩散模型多样性的同时提高样本质量的技术
Classifier free guidance
是一种替代技术,它通过在训练过程中随机丢弃 c(例如,以10%的概率),来联合训练一个针对条件和无条件目标的单一扩散模型,从而避免这种预训练模型
使用调整后的 x-prediction 进行采样
![]()
ϵ θ ( z t , c ) , ϵ θ ( z t ) \epsilon_\theta(z_t,c),\epsilon_\theta(z_t) ϵθ(zt,c),ϵθ(zt)是条件和无条件的 ϵ \epsilon ϵ-predictions,其中 ϵ θ : = ( z t − α t x ^ θ ) / σ t \epsilon_\theta:=(z_t - \alpha_t \hat{x}_\theta)/\sigma_t ϵθ:=(zt−αtx^θ)/σt, w w w 是指导权重
w w w = 1 表示禁用 Classifier free guidance, w w w > 1,强化了指导的效果。
Imagen严重依赖于无分类器指导来进行有效的文本约束
Large guidance weight samplers
增加无分类器引导权重改善了图像-文本对齐,但损害了图像保真度,产生高饱和和不自然的图像,这是由于高引导权重引起的训练-测试不匹配
在每次采样 t,x-prediction x ^ 0 t \hat{x}^t_0 x^0t 与 训练数据 x 的边界要在 [1-,1],但是高指导权重会导致 x-prediction 超过这些边界,这称为训练-测试不匹配,同时由于扩散模型在整个采样过程中迭代地应用于它自己的输出,采样过程产生不自然的图像,有时甚至发散
为此引入了 静态阈值 和 动态阈值
静态阈值
elementwise将x预测裁剪到[- 1,1]称为静态阈值化,对具有大指导权重的采样至关重要,并防止空白图像的生成,随着指导权重的进一步增加,静态阈值仍然会导致过度饱和和细节较少的图像
动态阈值
在每次采样中,将 s 设置为 x ^ 0 t \hat{x}^t_0 x^0t 中的某个百分位像素绝对值,如果 s > 1,那么将 x ^ 0 t \hat{x}^t_0 x^0t 阈值设置为范围 [- s, s],然后除以 s
动态阈值化将饱和像素(那些接近-1和1的像素)向内推进,从而主动防止像素在每个步骤中饱和
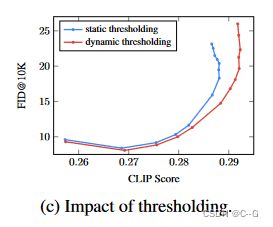
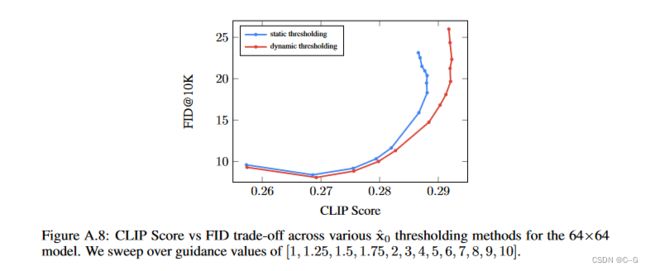
动态阈值可以显著提高照片的真实感,以及更好的图像-文本对齐,特别是在使用非常大的指导权重时
与静态或无阈值相比,动态阈值分割的样本具有明显更好的真实感和与文本的对齐性,特别是在存在大型无分类器引导权重的情况下
无分类器指导是生成图像-文本对齐样本的关键因素
虽然以前的工作通常使用相对较小的引导权重,但Imagen为所有三种扩散模型使用相对较大的引导权重
在较宽的指导权重范围内,动态阈值分割技术可获得明显更好的CLIP评分,并且与静态阈值分割技术相比,FID评分相当或更好
aug_level = 0给出了所有指导权重值的最佳FID分数,随着指导权重的增加,FID会显著提高,达到约7−10,虽然使用较大的aug_level值生成的FID略差,但它允许更多样化的片段分数范围,这表明超分辨率模型生成的图像更多样化。
对于最佳样本,通常在[0.1,0.3]中使用aug_level
Robust cascaded diffusion models
Imagen利用64×64模型和两个文本条件超分辨率扩散模型将64×64生成的图像上采样为256 × 256图像,然后为1024 × 1024图像
具有噪声调节增强的级联扩散模型,在逐步生成高保真图像方面非常有效,通过噪声水平调节,使超分辨率模型感知噪声添加量,显著提高了样本质量,有助于提高超分辨率模型处理低分辨率模型产生的伪影的鲁棒性
Imagen对这两个超分辨率模型都使用了噪声调节增强。这是生成高保真图像的关键。
给定条件低分辨率图像和增强水平( aug_level)(例如,高斯噪声或模糊的强度),用增强(对应于aug_level)破坏低分辨率图像,并在aug_level上条件扩散模型
训练阶段,aug_level是随机选择的,测试阶段,通过遍历不同参数,找到最好的样本质量
论文选择使用高斯噪声作为一种增强形式,并应用类似于扩散模型中使用的前向过程的保方差高斯噪声增强,增强水平由 aug_level∈[0,1]指定
- 用噪声调节增强训练超分辨率模型可以获得更好的CLIP和FID分数
- 噪声调节增强能对超分辨率模型进行更强的文本调节,从而在更高的指导权重下提高CLIP和FID分数
没有噪声增强的训练通常会导致较差的CLIP和FID分数,这表明噪声调节增强对于获得类似于之前工作[29]的最佳样本质量至关重要
与使用条件增强训练的模型相比,未经噪声增强训练的模型在不同指导权重下的CLIP和FID分数变化要小得多
因为强噪声增强训练大大降低了低分辨率图像调节信号,鼓励模型更高程度地依赖条件文本
Neural network architecture
base model
64 × 64 64 \times64 64×64 文本映射图像扩散模型的 U-Net 来自于 Improved denoising diffusion probabilistic models。
实验发现,在注意力层和池化层中对文本嵌入的层规范化有助于极大地提高性能。
Super-resolution models
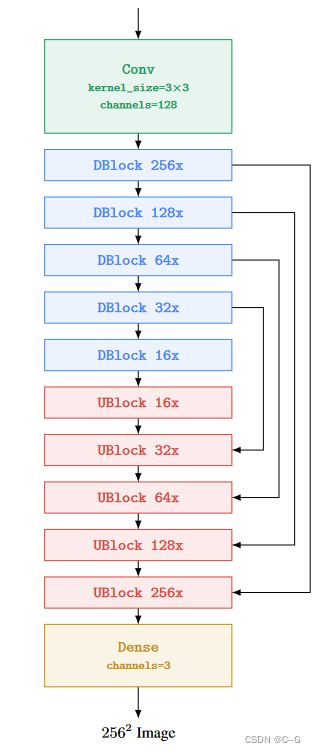
在两个超分辨率模型中都使用了文本交叉注意力,将图像从上采样到 64 × 64 → 256 × 256 64 \times 64 \rightarrow 256 \times256 64×64→256×256,称为 variant Efficient U-Net,该模型与base model相比,更简单,收敛更快,内存效率更高
- 为低分辨率添加更多的残差块,将模型参数从高分辨率块转移到低分辨率块,较低分辨率的块通常具有更多的通道,这使能够通过更多的模型参数来增加模型容量,而不会产生惊人的内存和计算成本
- 较低分辨率下使用8个剩余块,将跳跃连接按1/√2的比例伸缩可以显著提高收敛速度
- 在典型的U-Net下采样块中,下采样操作发生在卷积之后,而在上采样块中,上采样操作发生在卷积之前,这里倒置下采样和上采样块的这种顺序,以显著提高U-Net的正向传递速度,并且没有发现性能下降
将U-Net模型的300M参数扩展到2B参数时,随着模型容量的增加,获得了更好的权衡曲线
相比于扩展U-Net模型大小,扩展冻结的文本编码器模型大小可以更有效地提高模型质量
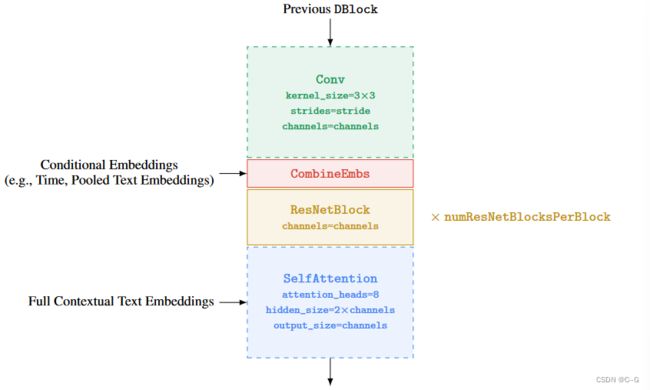
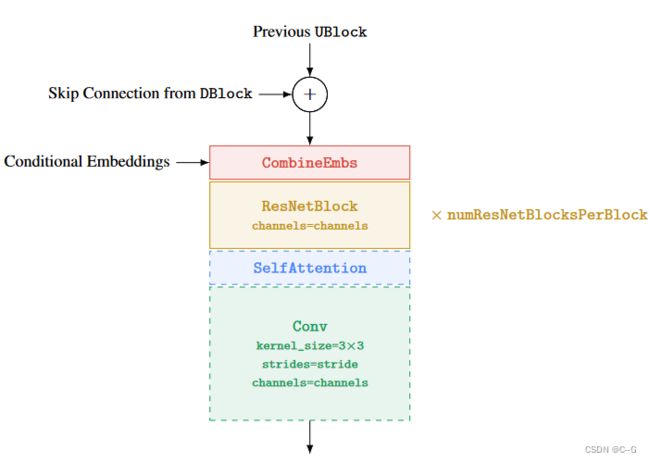
DBlock和UBlock都使用ResNetBlock
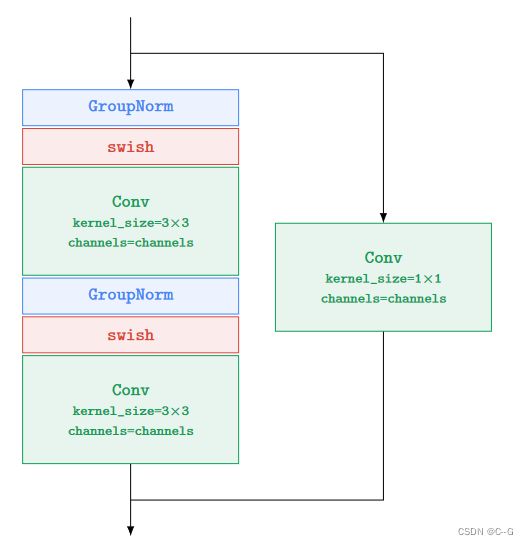
DBlock的虚线块是可选的,例如,不是每个DBlock都需要下采样或需要self-attention。
UBlock的虚线块是可选的,例如,并不是每个UBlock都需要上采样或需要self-attention。
Efficient U-Net architecture for 642 → 2562
Evaluating Text-to-Image Models
FID和CLIP评分都有局限性,例如FID与感知质量不完全一致,而CLIP在计算时无效,论文使用人工评价来评估图像质量和标题相似性,以真实参考标题-图像对为基线
- 为了探索图像质量,评价者被要求使用问题在模型生成和参考图像之间进行选择:“哪个图像更逼真(看起来更真实)?”我们报告了评分者选择模型生成而不是参考图像的时间百分比(偏好率)。
- 为了探究对齐,人类评价者会看到一张图像和一个提示,并被问到“标题是否准确描述了上述图像?”他们必须回答“是”、“多少”或“不是”。这些回答的得分分别为100、50和0。这些评分是对模型样本和参考图像独立获得的,两者都有报道。
DrawBench
虽然COCO是一个有价值的基准,但越来越明显的是,它的提示范围有限,不能轻易提供对模型之间差异的见解
Human raters prefer T5-XXL over CLIP on DrawBench
人类评价者在所有11个类别中都更喜欢T5-XXL,而不是CLIP
论文提出DrawBench,一套全面和具有挑战性的提示,支持文本到图像模型的评估和比较
DrawBench包含11类提示,测试模型的不同功能,如忠实地渲染不同颜色、对象数量、空间关系、场景中的文本和对象之间不寻常的交互的能力
类别还包括复杂的提示,包括长而复杂的文本描述、罕见的单词和拼写错误的提
使用DrawBench直接比较不同的模型。为此,人类评价者有两组图像,一组来自模型A,一组来自模型B,每组有8个样本。人工评价者被要求在样本保真度和图像-文本对齐方面比较模型A和模型B。他们有三种选择:喜欢A型车;冷漠的;或者更喜欢B型。

实验细节
64 × 64 64 \times 64 64×64 文本到图像合成模型训练了 2B参数模型
64 × 64 → 256 × 256 , 256 × 256 → 1024 × 1024 64\times 64 \rightarrow 256\times256,256\times256 \rightarrow 1024 \times 1024 64×64→256×256,256×256→1024×1024 分别为600M 参数 和 400M 参数
对于所有模型,batch size大小为 2048,迭代了2.5M次
采用256个 TPU-v4 训练 64 × 64 64 \times 64 64×64 模型,128个 TPU-v4 训练超分辨率模型
论文不认为过度拟合是一个问题,相信进一步的训练可能会提高整体表现
base model 采用Adafactor优化器,其性能类似,但内存占用小得多
超分辨率网络 采用 Adam优化器,Adafactor在初始消融过程中会影响模型质量
对于无分类器指导,以10%的概率将三个模型的文本嵌入归零,从而无条件地进行联合训练。
在内部数据集的组合上进行训练,其中图像-文本对≈460M,以及公开可用的Laion数据集,其中图像-文本对≈400M


Limitations and Societal Impact
严重依赖大型的、大多数未经整理的、从网络上抓取的数据集
依赖于在未经策划的网络规模数据上训练的文本编码器,因此继承了大型语言模型的社会偏见和限制
所有的生成模型,包括Imagen,都可能会遇到数据分布模式丢失的危险,这可能会进一步加剧数据集偏差的社会后果。
Imagen在生成描述人物的图像时存在严重的局限性
Imagen编码了几种社会偏见和刻板印象,包括生成浅肤色人群图像的总体偏见,以及描绘不同职业的图像倾向于与西方性别刻板印象保持一致