python学习补充01
文章目录
- python 学习补充01
-
- 1、python 读取文件的方法
-
- 1.1、read()
- 1.2、readline()
- 1.3、readlines()
- 2、python 拆分字符串:split() 函数
- 3、python 去掉字符串空格
- 4、python 命令行传入参数
-
- 4.1、sys 模块
- 4.2、 getopt 模块
- 4.3、argparse 模块
- 5、python 条件
- 6、python 读写 csv 文件
-
- 6.1、python DictReader 读写 csv 文件
-
- 读取内容
- 写入内容
- 6.2、python csv 读写 csv 文件
- 7、txt 文件处理
-
- 7.1、写入浮点数到txt
- 7.2、从 txt 文件提取数据到numpy 数组
- 7.3、从 txt 文件读取数据到 list 中
- 8、将输出信息写入文件中
-
- 8.1方法1
- 8.2、方法2
- 9、reshape函数
- 10、统计 两个数组相同元素个数
- 11、shutil 模块
-
- 创建和解压缩文件
python 学习补充01
1、python 读取文件的方法
1.1、read()
作用:一次读取文件的所有内容,放在一个大字符串中,及存在内存中
file_object = open('test.txt') # 不要将open 放在 try 中,以防止打开失败,就不用关闭了
try:
file_context = file_object.read() # file_context 是一个 string ,读取完后,就失去了对test.txt 的文件引用
# file_context = open(file).read().splitlines() # file_context 是一个list,每行文本内容是list 中的一个元素
finally:
file_object.close()
# 还可以使用 with 、contextlib 打开文件,且自动关闭文件,以防止打开的文件对象未关闭而占用内存
优点:
- 方便、简单
- 一次性读出文件放在一个大字符串中,速度最快
缺点: - 文件过大的时候,占用内存会很慢
1.2、readline()
作用:逐行读取文本,结果是一个 list
with open(file) as f:
line = f.readlins()
while line:
print(line)
line = f.readline()
优点:
- 占用内存小,逐行读取
缺点: - 由于是逐行读取,速度慢
1.3、readlines()
作用:一次读取文本的所有内容,结果是一个 list
with open(file) as f:
for line in f.readlines():
print(line)
说明:这种方法读取的文本内容,每行文本结尾都会带有一个 “\n" 换行符(可以用 line.rstrip(‘\n’) 去掉换行符 )
优点:
- 一次读取文本内容,速度快
缺点: - 随着文本增大,占用内存会增多
2、python 拆分字符串:split() 函数
os.path.split() : 按照路径将文件名和路径分割开
split() : 拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
# 函数说明
string.split(str="",num=string.count(str))[n]
# 参数说明:
## str: 分隔符,默认 空格,但不能为空("")。
## num: 表示分割次数。若存在num,则仅分割成 num+1 个字符串,并且每一个子字符串可以赋值给新的变量
## [n]:表示选取第 n 个分片
# 注意:当使用空格作为分隔符时,对于中间为空的项会自动忽略
os.path.split("path")
# 参数说明:
## path:指一个文件的全路径作为参数
## 若给出的是一个目录和文件名,则输出路径和文件名
## 若给出的是一个目录名,则输出路径和空文件名
示例
import re
text = "3.14:15"
print(re.split('[.:]',text)
3、python 去掉字符串空格
str.strip() :去除字符串开头或结尾的空格
str.lstrip():去除字符串开头的空格
str.rstrip():去除字符串结尾的空格
str.replace(" ", “”) :去除全部空格
“”.join(str.split()) :去除全部空格
4、python 命令行传入参数
参考:python 获取命令行参数
4.1、sys 模块
import sys
opt1 = sys.argv[0] # argv[0] 表示文件本身路径,即执行脚本的名字,不做命令行参数
opt2 = sys.argv[1]
4.2、 getopt 模块
函数说明
options,args = getopt.getopt(args,shortopts,longopts=[])
# 参数(即右边括号中传入的参数)说明
## args: 一般是 sys.argv[1:]。过滤掉 sys.argv[0],它是执行脚本的名字,不算做命令行参数
## shortopts:短格式分析串。如"hp:i:" ,h 后面没有冒号,表示后面不带参数;p 和 i 后面带有冒号,表示后面带有参数
## longopts:长格式分析串列表。如["help","ip=","port="],help 后面没有等号,表示不带参数;ip 和 port 后面有等号,表示带参数
# 返回值
## options:是以元组为元素的列表,每个元组的形式为:(选项串,附加参数),如:("-i","192.168.0.1")
## args:列表,其中的元素是哪些不含'-' 或 '--' 的参数
示例
import getopt
import sys
def main(argv):
try:
options,args = getopt.getopt(argv,"hp:i:",["help","ip=","port="])
except getopt.GetoptError:
sys.exit()
for option,value in options:
if option in ("-h","--help"):
print("help")
if option in ("-i","--ip"):
print("ip is:{0}".format(value))
if option in ("-p","--port"):
print("port is:{0}".format(value))
print("error args:{0}".format(args))
if __name__ == '__main__':
main(sys.argv[1:])
############### run ############
$ $python3 test.py -i 192.168.0.1 -p 80 123 a
##### result
ip is:192.168.0.1
port is : 80
error args:['123','a']
4.3、argparse 模块
作用:用于解析命令行选项和参数的标准模块
使用步骤:
1、import argparse # 导入模块
2、parser= argparse.ArgumentParser() # 创建解析对象
3、parser.add_argument() # 向该对象中添加使用到的命令行选项和参数
4、parser.parser_args() # 解析命令行
示例
import argparse
def main(args):
print("--address {0}".format(args.code_address)) #args.address会报错,因为指定了dest的值
print("--flag {0}".format(args.flag)) #如果命令行中该参数输入的值不在choices列表中,则报错
print("--port {0}".format(args.port)) #prot的类型为int类型,如果命令行中没有输入该选项则报错
print("-l {0}".format(args.log)) #如果命令行中输入该参数,则该值为True。因为为短格式"-l"指定了别名"--log",所以程序中用args.log来访问
if __name__ == '__main__':
parser = argparse.ArgumentParser(usage="it's usage tip.", description="help info.")
parser.add_argument("--address", default=80, help="the port number.", dest="code_address")
parser.add_argument("--flag", choices=['.txt', '.jpg', '.xml', '.png'], default=".txt", help="the file type")
parser.add_argument("--port", type=int, required=True, help="the port number.")
parser.add_argument("-l", "--log", default=False, action="store_true", help="active log info.")
args = parser.parse_args()
main(args)
5、python 条件
与:and
或:or
6、python 读写 csv 文件
读写内容:
| id | class |
|---|---|
| 0 | 5 |
| 1 | 4 |
| 2 | 13 |
6.1、python DictReader 读写 csv 文件
读取内容
import csv
with open('name.csv') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
# 循环打印数据的id 和 class 值
print(row['id'],row['class'])
# 打印结果:
0 5
1 4
2 13
写入内容
import csv
with open('name.csv','w') as csvfile:
writer = csv.DictWriter(csvfile,fieldnames=['id','class'])
# 写入列标题,即 DictWriter 构造方法的 fieldnames 参数
writer.writeheader()
for data in datas:
weiter.writerow({'id':data[0],'class':data[1]})
6.2、python csv 读写 csv 文件
import csv
with open('name.csv','w') as csvfile:
writer = csv.writer(csvfile)
f = open('files.txt','r')
lines = f.readlines()
for line in lines:
line = line.split()
writer.writerow(line)
f.close()
7、txt 文件处理
7.1、写入浮点数到txt
with open('file_path/filename.txt','a') as file:
write_str = '%f %f\n'%(float_data1,float_data2)
file.write(write_str)
7.2、从 txt 文件提取数据到numpy 数组
a = numpy.loadtxt('file.txt')
b = reshape(a,(3,2,4)) # reshape到想要的形状
7.3、从 txt 文件读取数据到 list 中
with open('file.txt','r') as f:
datas = f.readlines() # 逐行读取数据
for line in datas:
data = line.split() # 将单个数据分隔开保存好
num_data = map(float,data) # 转化为浮点数
8、将输出信息写入文件中
8.1方法1
mylog = open('mylog.log',mode='a',encoding='utf-8')
for i in range(10):
print('Mylog file',file=mylog)
muylog.close
8.2、方法2
import sys
sys.stdout = open('mylog.log',mode = 'w',encoding='utf-8')
for i in range(10):
print('Mylog file')
9、reshape函数
可用于numpy 的 array 和 ndarray,pandas 的 dataframe 和 series(series 需要先用 series.value 将对象转化成 ndarray 结构)
reshape(-1,1) # 重组成 任意行,一列
10、统计 两个数组相同元素个数
array1 = [1,2,3,4,5]
array2 = [1,3,3,5,5]
# 两个数组维度相同时
len(set(array1) & set(array2)) # 统计两个数组相同元素个数,维度相同
print(set(array1) & set(array2)) # 输出两个数组相同元素
# 两个数组维度不同时
print([x for x in array1 if x in array2])
11、shutil 模块
参考:[https://blog.csdn.net/weixin_41261833/article/details/108050152](Python模块——shutil 模块详解)
os 模块是 python 标准库中的一个重要模块,里面提供了对目录和文件的一般常用操作。
shutil 库作为 os 模块的补充,提供了复制、移动、删除、压缩、解压等操作。(注意:shutil 模块对压缩包的处理是调用 ZipFile 和 TarFile 两个模块进行的)
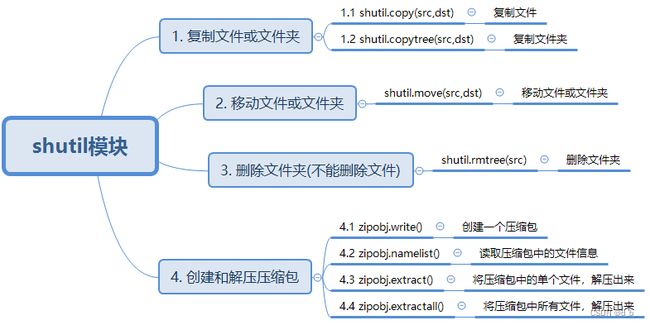
创建和解压缩文件
zipobj.write() : 创建一个压缩包
zipobj.namelist() : 读取压缩包中的文件信息
zipobj.extract() : 将压缩包中的单个文件,解压出来
zipobj.extractall(): 将压缩包中的所有文件解压出来
# shutil 模块对于压缩包的处理,是调用 ZipFile 和 TarFile 两个模块进行的,需要导入
# 这里所说的压缩包,是指 ".zip" 格式的压缩包
示例
import zipfile
import os
file_list = os.listdir(os.getcwd())
# 1、文件打包
with zipfile.ZipFile(r"myZip.zip", "w") as zipobj:
for file in file_list:
zipobj.write(file)
# 2、读取压缩包中的文件
with zipfile.ZipFile("myZip.zip","r") as zipobj:
print(zipobj.namelist())
# 3、解压 压缩包 中的单个文件
dst = r"/home/usr/my_file"
with zipfile.ZipFile("myZip.zip", "r") as zipobj:
zipobj.extract("file1", dst)
# 4、将压缩包中的所有文件,解压出来
dst = r"/home/usr/my_file"
with zipfile.ZipFile("myZip.zip", "r") as zipobj:
zipobj.extractall(dst)