【保姆级教程】hadoop 3.x 环境配置——入门篇
文章目录
- (一) Hadoop环境配置
-
- 1 配置服务器
-
- 1.1 虚拟机
- 1.2 云服务器
- 1.3 服务器基础配置总览
- 2 配置用户
- 3 配置JAVA
-
- 3.1 更换yum源
- 3.2 安装JDK
-
- 3.2.1 推荐:离线安装
- 3.2.2 不推荐:在线安装
- 4 配置SSH
- 5 更改hosts
- 6 搭建Hadoop集群
-
- 6.1 安装Hadoop
-
- 6.1.1 推荐:离线下载方法
- 6.1.2 暂不推荐:在线下载方法
- 6.2 搭建伪分布式环境
-
- 6.2.1 配置hadoop-env.sh
- 6.2.2 配置core-site.xml
- 6.2.3 配置hdfs-site.xml
- 6.2.4 配置mapred-site.xml
- 6.2.5 配置yarn-site.xml
- 6.2.6 格式化HDFS
- 6.2.7 开启HDFS
- 6.2.8 测试HDFS(可略)
- 6.2.9 关闭HDFS
- 6.2.10 开启yarn
- 6.2.11 关闭yarn
- 6.3 搭建完全分布式环境
-
- 6.3.1 修改主机名
- 6.3.2 修改hosts
- 6.3.3 修改workers(在master节点上修改)
-
- 推荐使用:跨主机SSH免密登录(RSA加密公钥)
- 暂不推荐:跨主机SSH免密登录(SCP直传公钥)
- 6.3.4 master节点配置
-
- 1)配置hadoop-env.sh
- 2)配置mapred-env.sh
- 3)配置yarn-env.sh
- 4)配置core-site.xml
- 5)配置hdfs-site.xml
- 6)配置mapred-site.xml:
- 7)配置yarn-site.xml
- 8)推送配置文件至slave主机
- 6.3.5 slave结点配置
- 6.3.6 格式化HDFS(在master节点上操作)
- 6.3.7 开启HDFS
- 6.3.8 测试HDFS(可略)
- 6.3.9 关闭HDFS
- 6.3.10 开启yarn
- 6.3.11 关闭yarn
- (二)常见问题及解决办法
-
- 1 问题整理
-
- 1)开启HDFS报错:localhost: ERROR: Cannot set priority of datanode
- 2)访问Hadoop web界面报错:It looks like you are making an HTTP request to a Hadoop IPC port. This is not the correct port for the web interface on this daemon.
- 3)启动完全分布式集群时报错:ERROR: Cannot set priority of nodemanager process 18647
- 4)解决了端口配置问题依然无法访问HDFS web界面
- 2 解决方法
-
- 1)删除data/name/tmp文件夹(针对结点进程无法启动的情况)
- 2)删除日志(针对因服务器异常关闭导致日志记录存在异常而无法启动集群的情况)
(一) Hadoop环境配置
author: CQU_dyd, latest update: 2021/7/14
文档说明:
- 已完成伪分布式集群搭建和完全分布式集群搭建的过程演示
- 待补充虚拟机配置流程(这次主要使用的是云服务器,所以没加这部分内容)
本文档为作者在大三下学期初次接触分布式计算时的记录文档,基本涵盖了作者在配置环境时踩过的所有坑,能力有限,若有疏漏还望大家批评指正。
1 配置服务器
可以选择虚拟机或云服务器,二者配置过程基本相同,当然,不管是虚拟机还是云服务器,系统都选用centOS 7版本。
1.1 虚拟机
配置过程略。
1.2 云服务器
本指导书主要使用华为弹性云服务器,配置过程和阿里云、腾讯云类似,根据个人需要选择基本配置(例如系统版本、磁盘大小、弹性公网ip,etc.)。
配置过程比较简单,此处略过。
1.3 服务器基础配置总览
-
系统:CentOS 7.6 64bit
-
java版本编号:1.8.0_261
-
hadoop版本编号:3.2.2
本文档所需的离线安装包获取链接(度盘链接,提取码:c34h):java+hadoop+spark离线安装包-百度云
2 配置用户
创建用户,并设置密码(如cqu123456.):
useradd -m hadoop -s /bin/bash # 注意,如果之前在/home/路径下有hadoop文件夹,一定要先移除再创建
passwd hadoop
给hadoop用户配置权限,打开配置文件:
visudo
之后在如图所示位置添加对应语句:

切换用户(接下来的所有操作都要在hadoop用户下进行):
su hadoop # 注意,不要使用root用户,以下全部切换到hadoop用户下操作
(虚拟机用户可不做)以防root用户被暴力破解,这里需要禁止root用户远程登录。
sudovim /etc/ssh/sshd_config # 打开配置文件
快捷键shift+g跳转到最后一行,找到 PermitRootLogin,将no改为yes:
PermitRootLogin no # 原本是yes
修改后保存退出,重启service sshd,会要求输入root的密码,根据提示输入即可:
systemctl restart sshd
如果需要切换回root用户则可以先登录hadoop用户再切换:
# 登录hadoop用户之后
su root
这时可以重启服务器,验证一下root用户是否被禁止登录。打开Xshell测试root连接,如果被拒绝访问则代表设置更改成功。
3 配置JAVA
3.1 更换yum源
安装JDK,安装之前可以更换一下yum源:
cd /etc/yum.repos.d/ # 切换到yum仓库
sudo mv CentOS-Base.repo CentOS-Base.repo.backup # 备份原repo文件
sudo wget -O /etc/yum.repos.d/CentOS-7.repo http://mirrors.aliyun.com/repo/Centos-7.repo # 下载阿里云的repo文件
sudo mv CentOS-7.repo CentOS-Base.repo # 设为默认repo文件(更改命名)
yum clean all
yum makecache
出现Metadata Cache Created即代表yum源更换成功。
这次主要用到的配置java环境的方法是离线安装(如自己已成功配置java可略过此部分内容)。
3.2 安装JDK
3.2.1 推荐:离线安装
使用WinSCP等远程连接软件把需要用的安装文件上传至云服务器,离线安装jdk-8u261-linux-x64.rpm文件。
cd /home/java # 进入java安装文件(rpm文件)所在目录
sudo yum install jdk-8u261-linux-x64.rpm # 回车后根据提示输入y继续
whereis java # 查找java软连接,默认链接是/usr/java/,记住这个地址,后面有用
检查java安装路径是否正确:
cd /usr/java/
ls # 查看/usr/java/下的内容
如果看到有jdk1.8.0_261-amd64这个文件夹,继续下一步。
配置环境变量:
vim ~/.bashrc # vim编辑配置文件
打开文件后在文件末尾添加如下变量(如果用的是我提供的安装包,则不用另外查找安装路径,直接复制这段到bashrc文件中):
export JAVA_HOME=/usr/java/jdk1.8.0_261-amd64
export JRE_HOME=/usr/java/jdk1.8.0_261-amd64/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
按下esc退出编辑,输入:wq!,使环境变量生效:
source ~/.bashrc
测试:
java -version
如果输出了正确的java版本(这里的版本号是1.8.0_261),至此,java配置过程已结束。
3.2.2 不推荐:在线安装
这种方法安装的java版本后缀为291,后经验证这个版本的java和hadoop-3.2.2不太兼容,但不影响使用,此处仅演示一下在线下载的方法。
sudo yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel # 在线安装
配置环境变量:
vim ~/.bashrc # vim编辑配置文件
打开文件后在文件最后添加如下变量(这里需要自己查找java的安装路径):
export JAVA_HOME={/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.292.b10-1.el7_9.x86_64}
export JRE_HOME={/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.292.b10-1.el7_9.x86_64/jre}
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
注意,{}处填入实际的java包路径(最终路径不包含括号),可通过如下语句查找:
rpm -ql java-1.8.0-openjdk-devel | grep '/bin/javac'
最后使环境变量生效:
source ~/.bashrc
测试:
java -version
4 配置SSH
因为集群、单节点模式都需要用到 ssh登陆,每次登陆ssh都要输入密码,非常麻烦 ,可以通过生成公钥来实现免密码登陆。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
一个简单的测试,如果可以不用输入密码则代表配置成功(第一次测试ssh会要求输入yes/no,输入yes即可):
ssh localhost
5 更改hosts
为了避免在修改配置文件的过程中频繁地使用主机ip,需要加入一个主机映射,用一个好记的名称代表主机的ip。
格式:ip [自己定义的映射名称]
打开hosts文件:
su hadoop # 保证当前操作的用户是自己创建的hadoop用户
sudo vim /etc/hosts
编辑hosts文件如下(以前的全部删除,改成下面这样。这里将当前主机ip映射为master,当然也可以自己定义,主要是为完成后续的集群配置做铺垫):
127.0.0.1 localhost
192.168.0.200 master # 必须使用当前主机的“内网”IP
6 搭建Hadoop集群
6.1 安装Hadoop
将上传到服务器的hadoop安装包(或者从命令行在线下载)解压,解压到/usr/local目录下:
6.1.1 推荐:离线下载方法
先使用WinSCP等远程软件将所需安装包上传至指定位置(这里是上传到了/home/hadoop路径下),然后解压:
cd /home/hadoop # 进入自己的hadoop压缩包所在路径
sudo tar -zxf hadoop-3.2.2.tar.gz -C /usr/local
修改文件夹名称:
cd /usr/local/ # 进入hadoop安装位置
sudo mv hadoop-3.2.2/ hadoop
配置环境变量:
vim ~/.bashrc
在文件中添加:
#在最后添加
export HADOOP_HOME={/usr/local/hadoop} # 填入实际的hadoop路径,记得把括号删掉
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin # 可与原先的PATH进行整合
按下esc退出编辑,输入:wq!,使环境变量生效:
source ~/.bashrc
修改文件权限(即让hadoop用户操作hadoop):
cd /usr/local/ # 切换到解压目录下
sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限
测试,如果配置正确则会输出正确的版本号:
cd /usr/local/hadoop # 切换到hadoop目录下
./bin/hadoop version # 输出hadoop版本号
如果能输出正确的版本号(这里是3.2.2),至此,hadoop的安装过程结束,如需在线下载其他版本可看“在线下载方法”一节。
6.1.2 暂不推荐:在线下载方法
在线获取hadoop-3.2.2安装包:
sudo wget -O hadoop-3.2.2.tar.gz https://mirrors.cnnic.cn/apache/hadoop/common/hadoop-3.2.2/hadoop-3.2.2.tar.gz --no-check-certificate
修改文件夹名称:
cd /usr/local/ # 进入hadoop安装位置
sudo mv hadoop-3.2.2/ hadoop
配置环境变量:
vim ~/.bashrc
在文件中添加:
#在最后添加
export HADOOP_HOME={/usr/local/hadoop} # 填入实际的hadoop路径,记得把括号删掉
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin # 可与原先的PATH进行整合
按下esc退出编辑,输入:wq!,使环境变量生效:
source ~/.bashrc
修改文件权限(即让hadoop用户操作hadoop):
cd /usr/local/ # 切换到解压目录下
sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限
测试,如果配置正确则会输出正确的版本号:
cd /usr/local/hadoop # 切换到hadoop目录下
./bin/hadoop version # 输出hadoop版本号
6.2 搭建伪分布式环境
6.2.1 配置hadoop-env.sh
在hadoop安装目录下vim打开hadoop-env.sh:
cd etc/hadoop/
vim hadoop-env.sh
在文件中加入如下内容:
export JAVA_HOME=/usr/java/jdk1.8.0_261-amd64 # 这里必须和bashrc中的设置保持一致
export HADOOP_HOME=/usr/local/hadoop # hadoop安装位置
# 定义HDFS和yarn在hadoop用户上运行
export HDFS_NAMENODE_USER=hadoop
export HDFS_DATANODE_USER=hadoop
export HDFS_SECONDARYNAMENODE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoop
# 定义hadoop的log路径和lib路径(若无此路径则要另外创建)
export HADOOP_PID_DIR=/usr/local/hadoop/var/lib/hadoop
export HADOOP_LOG_DIR=/usr/local/hadoop/var/log/hadoop
保存后,创建集群所需的lib和log目录:
su hadoop # 确保当前操作是在hadoop用户下
mkdir -p /usr/local/hadoop/var/lib/hadoop
mkdir -p /usr/local/hadoop/var/log/hadoop
给子目录的读写操作授权(如果hadoop用户在/usr/local/hadoop/var/log/hadoop路径下不加sudo进行创建文件/删除文件操作没有报错,则可以跳过这一步):
sudo chmod -R 777 /usr/local/hadoop/var/lib/hadoop
sudo chmod -R 777 /usr/local/hadoop/var/log/hadoop
6.2.2 配置core-site.xml
用vim打开core-site.xml:
cd etc/hadoop/
vim core-site.xml
打开后添加以下代码:其中master是主机映射名称(名称映射可以在/etc/hosts中修改),注意,如果使用的是云服务器,务必检查安全组是否放通了相应的端口,最好是放通8000-65535范围内的全部端口,方便后续操作。
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>file:/usr/local/hadoop/tmpvalue>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
configuration>
6.2.3 配置hdfs-site.xml
用vim打开配置文件:
cd etc/hadoop/
vim hdfs-site.xml
打开后添加:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/hadoop/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/hadoop/datavalue>
property>
configuration>
检查相关目录(tmp、name、data)是否存在:
ls /usr/local/hadoop/
如果没有则手动创建相关目录:
su hadoop # 确保当前用户是hadoop
mkdir -p /usr/local/hadoop/tmp
mkdir -p /usr/local/hadoop/name
mkdir -p /usr/local/hadoop/data
给子目录的读写操作授权(如果文件夹可以正常读写则跳过这步):
sudo chmod -R 777 /usr/local/hadoop/tmp
sudo chmod -R 777 /usr/local/hadoop/name
sudo chmod -R 777 /usr/local/hadoop/data
6.2.4 配置mapred-site.xml
打开文件操作略。
在文件中加入:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.application.classpathname>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*value>
property>
configuration>
6.2.5 配置yarn-site.xml
打开文件操作略。
在文件中加入:
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>2048value>
property>
configuration>
6.2.6 格式化HDFS
在hadoop安装目录下运行,一个集群只需要格式化一次(限首次启动hadoop集群时使用,如果是因为结点进程挂掉而重新格式化,必须把之前的缓存目录/日志目录全部清除才行,详细操作流程见“常见问题及解决办法”一节):
cd /usr/local/hadoop
bin/hdfs namenode -format
接下来会输出很多信息,看到Storage directory /usr/local/hadoop/name has been successfully formatted.就代表格式化HDFS成功。
6.2.7 开启HDFS
一次性启动HDFS和yarn:
sbin/start-all.sh
也可以选择开启部分服务(仅开启HDFS),即:sbin/stop-dfs.sh,对应的关闭指令为:sbin/stop-dfs.sh。
如果是sbin/start-all.sh,则启动集群后会出现5个新的进程,加上jps一共6个进程被完全开启且无报错,则代表伪分布式集群启动成功:
jps # 查看进程
成功开启HDFS和yarn后的全部进程如下图所示:

打开浏览器输入网址(格式:主机ip:端口号,默认端口为9870)访问HDFS:例如,124.70.48.162:9870
能打开这个页面就代表HDFS的web功能可以正常使用:
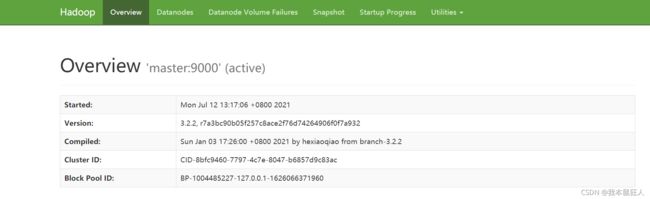
6.2.8 测试HDFS(可略)
在HDFS系统上创建相关目录:
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/root
bin/hdfs dfs -mkdir /input
上传测试文件至HDFS系统指定目录(这里的目录是input):
bin/hdfs dfs -put etc/hadoop/*.xml /input
将配置文件上传至input文件夹中(这里上传的是MapReduce的jar包,参数jar指定当前执行文件的类型),并指定输出文件为output(注意output文件夹必须还未被创建,若已被创建则会报错):
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep /input /output 'dfs[a-z.]+'
bin/hdfs dfs -cat /output/*
复制到本地查看:
bin/hdfs dfs -get /output output
cat output/*
6.2.9 关闭HDFS
一次性关闭HDFS和yarn:
sbin/stop-all.sh
6.2.10 开启yarn
sbin/start-yarn.sh
6.2.11 关闭yarn
sbin/stop-yarn.sh
至此,伪分布式系统配置过程已全部展示完毕。
6.3 搭建完全分布式环境
配置完全分布式的过程和伪分布式基本一致,这里只重点说明一下有区别的地方,建议在查看本节之前就已经过完伪分布式的配置流程。
如果想跳过一些不必要的伪分布式配置步骤,请保证至少过完“更改hosts”这节之前的内容,并且完成了hadoop的安装。
6.3.1 修改主机名
分别登录三台主机,更改主机名(这步操作的作用是便于区分不同主机,也可以不改):
su hadoop # 保证当前用户为hadoop用户
sudo vim /etc/hostname # 打开hostname配置文件
然后删除原文件中的主机名称,改成自己需要的主机名称(例如,对于master主机,将名称修改为“master”;对于slave01主机,将名称修改为“slave01”),修改完之后输入:wq!,保存退出。
最后重启主机,使重命名操作生效:
sudo reboot
重启之后,当前操作用户又变成了root,切换到hadoop用户继续后面的操作:
su hadoop
6.3.2 修改hosts
本次主要配置了3台云服务器(可根据需要配置多台),其中master结点一台,slave结点两台。
不同主机的公网ip和内网ip如下(以我在华为云上创建的主机为例):
| 主机名称 | 公网ip | 内网ip |
|---|---|---|
| master | 124.70.48.162 | 192.168.0.200 |
| slave01 | 114.116.251.49 | 192.168.0.80 |
| slave02 | 119.3.221.111 | 192.168.0.55 |
因为要实现跨主机相互访问,如果每次使用ip来访问不同主机会很麻烦,所以这里对不同主机的hosts文件进行了修改(主要涉及的操作是:加入其他主机的公网ip,并修改当前主机的名称映射)。
注意,对于云服务器,当前主机访问自身使用的是内网ip,访问其他主机使用的是公网ip;而对于虚拟机,没有内网ip和公网ip之分,填写当前虚拟机的ip即可。
打开hosts配置文件(不同主机hosts所在路径相同):
su hadoop # 保证当前操作用户为hadoop
sudo vim /etc/hosts
接下来就是修改hosts中的内容(三台主机均需要修改):
-
master主机
在master主机的hosts文件中,加入master主机的内网ip和映射名称,并添加两个slave主机的公网ip和对应的映射名称,修改后的hosts文件内容示例如下(修改时请将注释内容删除):
127.0.0.1 localhost 192.168.0.200 master master # master必须用内网IP 114.116.251.49 slave01 slave01 # slave01用外网IP 119.3.221.111 slave02 slave02 # slave02用外网IP -
slave主机(两个slave主机操作相同,这里只展示slave01的相关操作)
在slave主机的hosts文件中,加入slave主机(当前主机)的内网ip和映射名称,并添加master主机的公网ip和映射名称,修改后的hosts文件内容示例如下(修改时请将注释内容删除):
127.0.0.1 localhost 192.168.0.80 slave01 slave01 # slave01用内网IP 124.70.48.162 master master # master必须用外网IP
当前主机修改完后,保存退出。
6.3.3 修改workers(在master节点上修改)
这一步是指定所有工作结点,配置文件在hadoop安装目录下的etc/hadoop目录中:
cd /usr/local/hadoop # 进入hadoop的安装目录
vim etc/hadoop/workers # 打开workers的配置文件
打开文件后删除原有内容,将如下内容复制进去:
master
slave01
slave02
推荐使用:跨主机SSH免密登录(RSA加密公钥)
这一步将在主节点上操作。虽然我目前还不太明白RSA加密的原理,但考虑到安全性问题,还是建议使用这个方法配置免密登录。
编辑免密列表:
cd ~/.ssh/
#编辑免密列表
vi node-list.txt
在打开的文件中输入如下内容:
master
slave01
slave02
将RSA公钥指纹加入到known_hosts文件中:
ssh-keyscan -t rsa -f node-list.txt > ~/.ssh/known_hosts
将免密配置推送至子节点,即将master主机上的 ~/.ssh 配置文件复制到子节点上(推送时需要输入slave主机的hadoop密码):
scp -r ~/.ssh hadoop@slave01:~
scp -r ~/.ssh hadoop@slave02:~
测试免密登录slave01(slave02同理):
ssh slave01
如果不需要使用密码即可远程登录slave主机,则代表SSH免密登录设置成功(输入exit返回master主机)。
暂不推荐:跨主机SSH免密登录(SCP直传公钥)
这段内容参考了大三上学期原大数据助教提供的实验指导书,如果已通过RSA加密方法配置了免密登录可以跳过此节。
先验证当前主机是否可以本地免密登录:
ssh localhost
如果不需要输入密码则继续下一步,否则请回到之前的 “配置SSH” 章节重新配置ssh。
为了让master可以免密登录slave01和slave02,需要将master主机的密钥传给两个slave主机( id_rsa.pub文件)。
在master上通过scp传递公钥:
scp ~/.ssh/id_rsa.pub hadoop@slave01:/home/hadoop/
在slave01上加入验证(slave02同理):
ls /home/hadoop/ # 查看master传送过来的 id_rsa.pub文件
# 将master公钥加入免验证:
cat /home/hadoop/id_rsa.pub >> ~/.ssh/authorized_keys rm /home/hadoop/id_rsa.pub
测试:
-
在master主机上:
ssh slave01如果可以不需要输入密码就能登录slave主机就表示配置成功。
-
验证成功后切换回master:
ssh master # 从slave主机登录master要输入master主机的hadoop用户密码
6.3.4 master节点配置
如果已构建并测试过伪分布模式的机器,先将 Hadoop 所有进程全部停止,清理掉所有伪分布模式下的缓存及日志内容。
终止进程命令(注意要在hadoop运行目录下,如/usr/local/hadoop):
sbin/stop-all.sh
清理掉所有伪分布模式下的缓存及日志内容(只是清除内容,原目录保留):
su hadoop # 确保当前用户在hadoop用户下
rm -rf /usr/local/hadoop/tmp/*
rm -rf /usr/local/hadoop/name/*
rm -rf /usr/local/hadoop/data/*
rm -rf /usr/local/hadoop/var/lib/hadoop/*
rm -rf /usr/local/hadoop/var/log/hadoop/*
1)配置hadoop-env.sh
在master的hadoop安装目录下vim打开hadoop-env.sh:
cd /usr/local/hadoop
vim etc/hadoop/hadoop-env.sh
在文件中加入如下内容(如果之前做过伪分布式,其中的内容几乎不用修改):
export JAVA_HOME=/usr/java/jdk1.8.0_261-amd64 # 这里必须和bashrc中的设置保持一致
# 定义HDFS和yarn在hadoop用户上运行
export HDFS_NAMENODE_USER=hadoop
export HDFS_DATANODE_USER=hadoop
export HDFS_SECONDARYNAMENODE_USER=hadoop
export YARN_RESOURCEMANAGER_USER=hadoop
export YARN_NODEMANAGER_USER=hadoop
# 定义hadoop的log路径和lib路径(若无此路径则要另外创建)
export HADOOP_PID_DIR=/usr/local/hadoop/var/lib/hadoop
export HADOOP_LOG_DIR=/usr/local/hadoop/var/log/hadoop
#HBase 集成配置
#export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/soft/hbase-2.3.4/lib/*
2)配置mapred-env.sh
打开文件:
vim /usr/local/hadoop/etc/hadoop/mapred-env.sh
打开后在文件开头添加:
export JAVA_HOME=/usr/java/jdk1.8.0_261-amd64
3)配置yarn-env.sh
打开文件:
vim /usr/local/hadoop/etc/hadoop/yarn-env.sh
打开后在文件开头添加:
export JAVA_HOME=/usr/java/jdk1.8.0_261-amd64
4)配置core-site.xml
打开文件:
vim /usr/local/hadoop/etc/hadoop/core-site.xml
打开后在文件中添加(如果之前做过伪分布式,其中的内容几乎不用修改):
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>file:/usr/local/hadoop/tmpvalue>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
configuration>
5)配置hdfs-site.xml
打开文件:
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
完全分布式的HDFS配置文件和伪分布式的HDFS配置文件略有区别,主要涉及的内容是修改dfs结点数量、指定SecondaryNameNode所在主机、指定SecondaryNameNode工作目录,打开后在文件中添加:
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/hadoop/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/hadoop/datavalue>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>slave01:9868value>
property>
<property>
<name>dfs.namenode.checkpoint.dirname>
<value>file:/usr/local/hadoop/namesecondaryvalue>
property>
configuration>
检查目录(tmp、name、data、namesecondary)是否存在,如果没有则手动创建:
ls /usr/local/hadoop/
创建相关缓存目录:
su hadoop # 确保当前用户是hadoop用户
mkdir -p /usr/local/hadoop/tmp
mkdir -p /usr/local/hadoop/name
mkdir -p /usr/local/hadoop/data
mkdir -p /usr/local/hadoop/namesecondary
如果之前启动过集群,记得清除相关文件:清理掉所有伪分布模式下的缓存及日志内容(只是清除内容,原目录保留)。
su hadoop # 确保当前用户在hadoop用户下
rm -rf /usr/local/hadoop/tmp/*
rm -rf /usr/local/hadoop/name/*
rm -rf /usr/local/hadoop/data/*
rm -rf /usr/local/hadoop/var/lib/hadoop/*
rm -rf /usr/local/hadoop/var/log/hadoop/*
6)配置mapred-site.xml:
打开文件:
vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
打开后在文件中添加(如果之前做过伪分布式,其中的内容几乎不用修改):
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.application.classpathname> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*value>
property>
configuration>
7)配置yarn-site.xml
打开文件:
vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
打开后在文件中添加(如果之前做过伪分布式,其中的内容几乎不用修改):
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.env-whitelistname>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOMEvalue>
property>
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>2048value>
property>
configuration>
8)推送配置文件至slave主机
前面已经配置了master与两台slave主机的免密登录,并且修改了相关配置文件,可直接将hadoop的配置文件推到两台slave主机对应的位置上(这样就省去了重复配置的操作):
# 以下操作在master主机上
cd /usr/local/hadoop # 进入hadoop安装目录
# 将master主机的整个hadoop配置文件夹推送到指定位置
scp -r etc/hadoop hadoop@slave01:/usr/local/hadoop/etc/
scp -r etc/hadoop hadoop@slave02:/usr/local/hadoop/etc/
验证一下配置文件是否成功从master主机推送到slave主机:
# 进入slave01主机(slave02)同理
cd /usr/local/hadoop # 进入hadoop安装目录
cat etc/hadoop/workers
如果在命令行成功输出原master主机上配置的workers文件的内容,则说明推送成功(如果不放心可以vim打开其他配置文件再确认一下)。
6.3.5 slave结点配置
由于主要的配置文件已通过master推送到指定位置,这里仅需要创建集群所需的目录。
检查目录(tmp、name、data、namesecondary)是否存在,如果没有则手动创建:
ls /usr/local/hadoop/
创建相关缓存目录:
su hadoop # 确保当前用户是hadoop用户
mkdir -p /usr/local/hadoop/tmp
mkdir -p /usr/local/hadoop/name
mkdir -p /usr/local/hadoop/data
mkdir -p /usr/local/hadoop/namesecondary
mkdir -p /usr/local/hadoop/var/lib/hadoop
mkdir -p /usr/local/hadoop/var/log/hadoop
如果之前在slave主机上启动过伪分布式集群,记得清除相关文件:清理掉所有伪分布模式下的缓存及日志内容(只是清除内容,原目录保留)。
su hadoop # 确保当前用户在hadoop用户下
rm -rf /usr/local/hadoop/tmp/*
rm -rf /usr/local/hadoop/name/*
rm -rf /usr/local/hadoop/data/*
rm -rf /usr/local/hadoop/var/lib/hadoop/*
rm -rf /usr/local/hadoop/var/log/hadoop/*
6.3.6 格式化HDFS(在master节点上操作)
回到master主机,在hadoop安装目录下运行,只需要格式化一次(限首次启动hadoop集群时使用,如果是因为结点进程挂掉而重新格式化,必须把之前的缓存目录/日志目录全部清除才行,详细操作流程见“常见问题及解决办法”一节):
cd /usr/local/hadoop
bin/hdfs namenode -format
接下来会输出很多信息,看到Storage directory /usr/local/hadoop/name has been successfully formatted.就代表格式化HDFS成功。
6.3.7 开启HDFS
一次性启动HDFS和yarn:
sbin/start-all.sh
也可以选择开启部分服务(仅开启HDFS),即:sbin/stop-dfs.sh,对应的关闭指令为:sbin/stop-dfs.sh。
如果是sbin/start-all.sh,则启动集群后会在master上出现4个新的进程、slave01上出现3个新进程、slave02上出现2个新进程。如果所有结点上的进程被完全开启且无报错,则代表完全分布式集群启动成功:
jps # 查看进程
查看开启HDFS和yarn后的全部进程,如果成功开启集群则会看到如下进程:
- master结点上的进程,包含jps、NodeManager、NameNode、ResourceMananger、DataNode:

- slave01结点上的进程,包含jps、SecondaryNamenode、DataNode、NodeManager:

- slave02结点上的进程,包含jps、DataNode、NodeManager:

打开浏览器输入网址(格式:master主机ip:端口号,默认端口为9870)访问HDFS:例如,124.70.48.162:9870
能打开这个页面就代表HDFS的web功能可以正常使用:
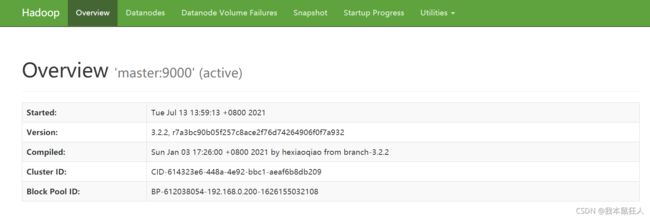
还可以查看集群信息:
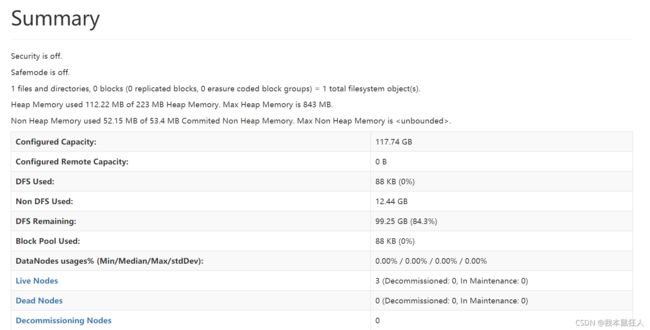
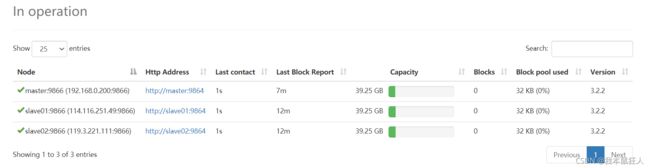
6.3.8 测试HDFS(可略)
在HDFS系统上创建相关目录:
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/root
bin/hdfs dfs -mkdir /input
上传测试文件(core-site.xml)至HDFS系统指定目录(这里的目录是input):
bin/hdfs dfs -put etc/hadoop/core-site.xml /input
将配置文件上传至input文件夹中(这里上传的是MapReduce的jar包,参数jar指定当前执行文件的类型),并指定输出文件为output(注意output文件夹必须还未被创建,若已被创建则会报错),做一个简单的词频统计:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount /input/core-site.xml /output
bin/hdfs dfs -ls /output
bin/hdfs dfs -cat /output/*
复制到本地查看:
bin/hdfs dfs -get /output output
cat output/*
6.3.9 关闭HDFS
一次性关闭HDFS和yarn:
sbin/stop-all.sh
6.3.10 开启yarn
sbin/start-yarn.sh
6.3.11 关闭yarn
sbin/stop-yarn.sh
至此,完全分布式系统配置过程已全部展示完毕。
(二)常见问题及解决办法
1 问题整理
1)开启HDFS报错:localhost: ERROR: Cannot set priority of datanode
查看日志:
cd /usr/local/hadoop/var/log/hadoop # 进入日志目录,这个定义在hadoop-env.sh中
vim /usr/local/hadoop/var/log/hadoop/hadoop-hadoop-datanode-master.log # 因为是datanode出错,所以查看datanode的日志
快捷键shift+g跳转到文档末尾,发现有这样的报错:chmod: changing permissions of ‘/usr/local/hadoop/data’: Operation not permitted
一开始怀疑是文件夹授权不对,chmod更改了授权依然无效,才发现文档的创建用户是root(非当前hadoop用户),linux不允许跨用户操作目录。
删除掉原先的文件夹,再用hadoop用户新建文件夹就可以启动集群了。
2)访问Hadoop web界面报错:It looks like you are making an HTTP request to a Hadoop IPC port. This is not the correct port for the web interface on this daemon.
在启动hadoop集群后,打开浏览器上输入http://124.70.48.162:9000/(端口号前面的主机ip请换成自己的主机ip),出现无法访问的情况,经查发现是单节点的hadoop的问题,正确的访问地址为http://124.70.48.162:8088/cluster
常用界面访问地址:
-
管理界面:http://124.70.48.162:8088
-
NameNode界面:http://124.70.48.162:9870
-
HDFS NameNode界面:http://localhost:8042
3)启动完全分布式集群时报错:ERROR: Cannot set priority of nodemanager process 18647
检查了一下master结点的错误日志,发现是我的路径没写对。
原缓存文件路径:file:///usr/local/hadoop/tmp
后来把hdfs-site.xml和core-site.xml配置文件中对应路径前面的“file://"去掉即可正常启动集群(加上前缀的话,在虚拟机上是可以正常启动的,不明白云服务器为何不认这种写法)。
4)解决了端口配置问题依然无法访问HDFS web界面
多半是因为防火墙没关(虚拟机用户遇到这种状况比较常见)。
查看防火墙是否活跃:
systemctl status firewalld
如果状态为active就需要关闭防火墙,关闭指令:
systemctl stop firewalld
如果防火墙已关,依旧无法访问,检查访问端口是否配置正确(默认端口9870),如果使用的是云服务器则要检查安全组中是否放通此端口。
如果问题依旧没有解决,输入jps指令检查datanode进程是否正常运行,如果缺失datanode,检查datanode日志,找出错误原因(日志文件或数据文件路径错误、配置路径错误,etc.),处理后重新格式化HDFS,再启动集群即可解决。
2 解决方法
总之,绝大部分环境配置相关的异常都跟集群没有正常开启/关闭有关,养成好习惯,每次开启集群之后都要在关机之前及时关闭集群。
1)删除data/name/tmp文件夹(针对结点进程无法启动的情况)
删除并重建相关文件夹:
su hadoop # 确保当前用户是hadoop
cd /usr/local/hadoop/ # 进入hadoop安装目录
rm -rf data
mkdir data
rm -rf name
mkdir name
rm -rf tmp
mkdir tmp
重新格式化:
bin/hdfs namenode -format
启动HDFS:
sbin/start-dfs.sh
2)删除日志(针对因服务器异常关闭导致日志记录存在异常而无法启动集群的情况)
删除并重建相关文件夹:
su hadoop # 确保当前用户是hadoop
cd /usr/local/hadoop/var
rm -rf log
mkdir log
mkdir log/hadoop
sudo chmod -R 777 /usr/local/hadoop/var/log/hadoop # 重新给子目录授权
启动HDFS:
sbin/start-dfs.sh