只有理解 Token 和内存,才能更好掌握 ChatGPT !
Token计数在塑造大语言模型的记忆和对话历史方面发挥着重要作用。将其视为与能够记住聊天最后几分钟的朋友进行对话,使用Token计数来维护上下文并确保对话顺利进行。然而,这种有限的内存会对用户交互产生影响,例如需要重复关键信息来维护上下文。
ChatGPT 等大型语言模型 (LLM) 已经改变了 AI 格局,了解其复杂性对于充分发挥其潜力至关重要。这篇短文将重点讨论大语言模型中的Token限制和记忆。本文旨在让诸位了解Token限制的重要性、LLM 中的内存概念,以及如何在这些限制内通过交互式界面和 API 以编程方式有效管理对话。
让我们首先讨论一个场景,其中用户与 LLM 交互并体验“Token限制和记忆”对对话的影响。

提示:“一个戴着眼镜、棕色头发、穿着休闲毛衣的年轻人,坐在温馨的房间里,在时尚的笔记本电脑上与 AI 语言模型进行交互,周围漂浮着包含Token的语音气泡。渲染风格现代且引人入胜。” 由 Russ Kohn 和 GPT4 提示。由 MidJourney 渲染。
一、了解Token和Token限制
1.Token和Token计数
Token是大语言模型文本的构建块,长度范围从一个字符到一个单词。例如,短语“ChatGPT 太棒了!” 由 6 个 token 组成:[“Chat”、“G”、“PT”、“is”、“amazing”、“!”]。这是一个更复杂的例子:“人工智能很有趣(也很有挑战性)!” 由 7 个标记组成:[“AI”、“is”、“fun”、“(”、“and”、“challenge”、“)!”]。
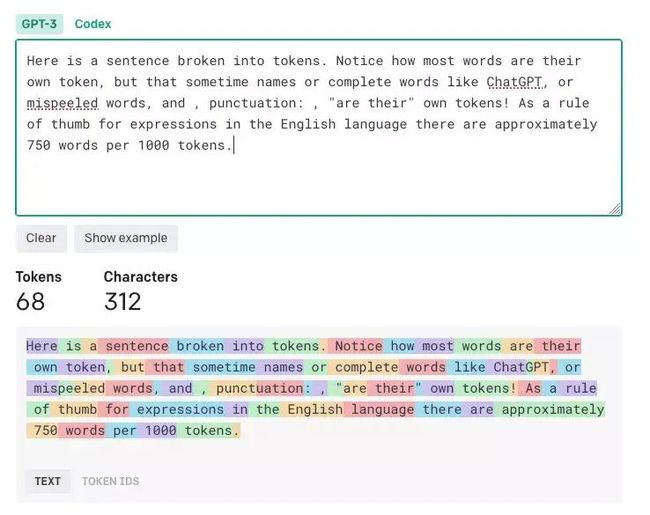
OpenAI tokenizer 实用程序的屏幕截图,展示了Token计数的工作原理。
注意:上图中使用的工具来自 OpenAI,可从https://platform.openai.com/tokenizer 获取。
2.Token限制
模型实现中的Token限制限制了单次交互中处理的Token数量,以确保高效的性能。例如,ChatGPT 3 有 4096 个Token限制,GPT4 (8K) 有 8000 个Token限制,GPT4 (32K) 有 32000 个Token限制。
二、记忆和对话历史
Token计数在塑造大语言模型的记忆和对话历史方面发挥着重要作用。将其视为与能够记住聊天最后几分钟的朋友进行对话,使用Token计数来维护上下文并确保对话顺利进行。然而,这种有限的内存会对用户交互产生影响,例如需要重复关键信息来维护上下文。
1.背景很重要
上下文窗口从当前提示开始,并返回历史记录,直到超出Token计数。就大语言模型而言,之前的一切都从未发生过。当对话长度超过Token限制时,上下文窗口会发生变化,可能会丢失对话早期的关键内容。为了克服这一限制,用户可以采用不同的技术,例如定期重复重要信息或使用更高级的策略。

请注意,如果大语言模型不了解句子的开头部分,其反应可能会有所不同。
2.聊天体验:提示、完成和Token限制
参与大语言模型涉及提示(用户输入)和完成(模型生成的响应)的动态交换。例如,当你问“法国的首都是哪里?” (提示),大语言模型回答“法国的首都是巴黎”。(完成)。为了在Token限制内优化聊天体验,平衡提示和完成至关重要。如果对话接近Token限制,您可能需要缩短或截断文本以保持上下文并确保与大语言模型的无缝交互。
3.超过Token限制和潜在的解决方案
超过Token限制可能会导致不完整或无意义的响应,因为大语言模型会失去重要的背景。想象一下询问埃菲尔铁塔并收到有关比萨斜塔的回复,因为上下文窗口发生了变化。要处理Token限制问题,您可以截断、省略或重新措辞文本以适应限制。一个好的策略是在达到限制之前通过创建摘要来结束当前的对话,然后用该摘要开始下一次对话。另一种策略是写很长的提示,让你尝试一次性对话:向人工智能提供你所知道的一切,并让它做出一个响应。如果您使用第三方提示管理器,它还可以帮助您管理对话、跟踪Token限制和管理成本。
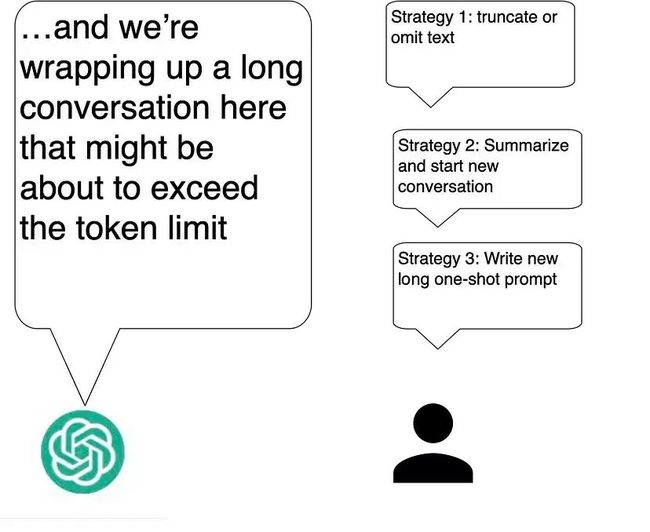
该图说明了处理大语言模型中Token限制问题的策略,包括截断文本、总结对话和编写长的一次性提示。
三、实际应用:管理内容创建中的Token限制
应用本文中讨论的策略,我亲身体验了在大语言模型中管理Token限制和上下文的好处。在撰写本文时,我遇到了前面讨论的Token限制问题。对于感兴趣的人,我使用了带有 OpenAI API 的自定义 FileMaker Pro 解决方案,利用了可供 ChatGPT-Plus 订阅者使用的 GPT-3.5-turbo (ChatGPT) 和 GPT-4 (8k) 模型。我首先精心设计提示来创建故事处理和大纲,然后进行修改。由于对话超出了 GPT-3.5-turbo 的Token限制,我切换到 GPT-4 并总结了开始新对话的目标。使用提示管理器帮助我按项目组织提示并高效工作,而无需依赖 OpenAI 网站。这种方法还有助于分离“元”提示,例如标题和 SEO 优化,来自那些帮助写作过程的人。在整个过程中,我仔细审查和编辑了生成的内容,以确保质量和连贯性。这个实际示例演示了使用摘要、切换模型和使用提示管理器来管理Token限制的有效性。通过理解和应用这些策略,用户可以在各种应用(例如内容创建和分析)中充分发挥 ChatGPT 等大语言模型的全部潜力。
四、结论
了解大型语言模型中的Token限制和记忆对于在各种应用程序(例如内容创建、聊天机器人和虚拟助手)中有效利用其功能至关重要。
通过掌握Token、Token计数、对话历史记录和上下文管理的概念,您可以优化与 ChatGPT 等 LLM 的交互。希望本文中讨论的实用策略(包括管理Token限制和利用提示管理器)能够让你自信地畅游人工智能世界。有了这些知识,可以 大大提高探索人工智能未来所带来的兴奋度,并释放大语言模型在技术、商业和生产力应用方面的更多潜力。