Kubelet 各个端口作用 10250
| --port int32 Default: 10250 | |
The port for the kubelet to serve on. (DEPRECATED: This parameter should be set via the config file specified by the kubelet's --config flag. See https://kubernetes.io/docs/tasks/administer-cluster/kubelet-config-file/ for more information.) |
|
kubelet | Kubernetes https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/
https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/
kubelet架构分析 - Zachary's Cloudhttps://mazengxie.github.io/2019/01/08/kubelet-infrastructure.html
Archive - Zachary's Cloudhttps://mazengxie.github.io/archive.html?tag=kubelet
kubelet架构分析
kubelet是kubernetes集群中真正维护容器状态,具体“干活”的组件。每个节点上都运行一个 kubelet 服务进程,默认监听 10250 端口,接收并执行 master 发来的指令,管理 Pod 及 Pod 中的容器。

1.主要功能
节点管理
节点管理主要是节点自注册和节点状态更新:
- Kubelet 可以通过设置启动参数 –register-node 来确定是否向 API Server 注册自己;
- 如果 Kubelet 没有选择自注册模式,则需要用户自己配置 Node 资源信息,同时需要告知 Kubelet 集群上的 API Server 的位置;
- Kubelet 在启动时通过 API Server 注册节点信息,并定时向 API Server 发送节点新消息,API Server 在接收到新消息后,将信息写入 etcd
Self-registration of Nodes
When the kubelet flag --register-node is true (the default), the kubelet will attempt to register itself with the API server. This is the preferred pattern, used by most distros.
For self-registration, the kubelet is started with the following options:
-
--kubeconfig- Path to credentials to authenticate itself to the API server. -
--cloud-provider- How to talk to a cloud provider to read metadata about itself. -
--register-node- Automatically register with the API server. -
--register-with-taints- Register the node with the given list of taints (comma separated= : No-op if
register-nodeis false. -
--node-ip- IP address of the node. -
--node-labels- Labels to add when registering the node in the cluster (see label restrictions enforced by the NodeRestriction admission plugin). -
--node-status-update-frequency- Specifies how often kubelet posts node status to master.
pod管理
容器监控
健康检查
2.监听端口
kubelet 默认监听四个端口,分别为 10250 、10255、10248、4194。
tcp 0 0 127.0.0.1:10248 0.0.0.0:* LISTEN 3272/kubelet
tcp6 0 0 :::10255 :::* LISTEN 3272/kubelet
tcp6 0 0 :::4194 :::* LISTEN 3272/kubelet
tcp6 0 0 :::10250 :::* LISTEN 3272/kubelet
- 10250(kubelet API):kubelet server 与 apiserver 通信的端口,定期请求 apiserver 获取自己所应当处理的任务,通过该端口可以访问获取 node 资源以及状态。kubectl查看pod的日志和cmd命令,都是通过kubelet端口10250访问,如果本地没有开启10250端口的话:
查看日志
[devops@master cloudk8s]$ kubectl logs nginx-deployment-ddbc89dc5-7tkt5
Error from server: Get https://192.168.0.116:10250/containerLogs/default/nginx-deployment-ddbc89dc5-7tkt5/nginx: dial tcp 192.168.0.116:10250: getsockopt: connection refused
[root@master ~]# kubectl get pod -n monitor -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
grafana-5d794f46d5-5nk4t 1/1 Running 2 25h 10.233.90.118 node1
[root@master ~]# kubectl logs grafana-5d794f46d5-5nk4t -n monitor
t=2022-02-11T06:59:08+0000 lvl=info msg="Starting Grafana" logger=server version=7.1.0 commit=8101355285 branch=HEAD compiled=2020-07-16T11:04:17+0000
t=2022-02-11T06:59:08+0000 lvl=info msg="Config loaded from" logger=settings file=/usr/share/grafana/conf/defaults.ini
t=2022-02-11T06:59:08+0000 lvl=info msg="Config loaded from" logger=settings file=/etc/grafana/grafana.ini
...............................................
[root@node1 ~]# systemctl stop kubelet
[root@node1 ~]# systemctl status kubelet
?.kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/etc/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /etc/systemd/system/kubelet.service.d
?..10-kubeadm.conf
Active: inactive (dead) since Fri 2022-02-11 15:02:44 CST; 7s ago
Docs: http://kubernetes.io/docs/
Process: 511 ExecStart=/usr/local/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=0/SUCCESS)
Main PID: 511 (code=exited, status=0/SUCCESS)
Feb 11 15:02:32 node1 kubelet[511]: I0211 15:02:32.643574 511 topology_manager.go:221] [topologymanager] RemoveContainer - Container ID: 395478aba54...e31b5c3978
Feb 11 15:02:32 node1 kubelet[511]: E0211 15:02:32.645423 511 pod_workers.go:191] Error syncing pod 4646cd67-04f1-4e5d-ab5a-08b80f978ade ("hostnames-766c597cd...
[root@master ~]# kubectl logs grafana-5d794f46d5-5nk4t -n monitor
Error from server: Get "https://192.168.100.6:10250/containerLogs/monitor/grafana-5d794f46d5-5nk4t/grafana": dial tcp 192.168.100.6:10250: connect: connection refused 执行cmd命令
[devops@master cloudk8s]$ kubectl exec -it nginx-deployment-ddbc89dc5-7tkt5 /bin/sh
Error from server: error dialing backend: dial tcp 192.168.0.116:10250: getsockopt: connection refused
- 10248(健康检查端口): kubelet 是否正常工作, 通过 kubelet 的启动参数 –healthz-port 和 –healthz-bind-address 来指定监听的地址和端口。
[root@node1 ~]# curl http://127.0.0.1:10248/healthz
ok
[root@master ~]# vim /var/lib/kubelet/config.yaml
healthzPort: 10248
healthzBindAddress: 127.0.0.1
[root@master ~]# netstat -tpln | grep 10248
tcp 0 0 127.0.0.1:10248 0.0.0.0:* LISTEN 502/kubelet
- 4194(cAdvisor 监听):kublet 通过该端口可以获取到该节点的环境信息以及 node 上运行的容器状态等内容,访问 http://localhost:4194 可以看到 cAdvisor 的管理界面, 通过 kubelet 的启动参数 –cadvisor-port 可以指定 启动的端口。
[root@node1 ~]# curl http://127.0.0.1:4194/metrics
- 10255 (readonly API):提供了 pod 和 node 的信息,接口以只读形式暴露出去,访问该端口不需要认证和鉴权。 获取 pod 的接口,与 apiserver 的 http://127.0.0.1:8080/api/v1/pods?fieldSelector=spec.nodeName= 接口类似
特别需要注意的是 Kubernetes 1.11+ 版本以后,kubelet 就移除了 10255 端口, metrics 接口又回到了 10250 端口中
[root@node1 ~]# curl http://127.0.0.1:10255/pods
节点信息接口,提供磁盘、网络、CPU、内存等信息
[root@node1 ~]# curl http://127.0.0.1:10255/spec/Prometheus 服务发现 10250端口抓取指标监控kubelet
由于我们这里3个节点上面都运行了 node-exporter 程序,如果我们通过一个 Service 来将数据收集到一起用静态配置的方式配置到 Prometheus 去中,就只会显示一条数据,我们得自己在指标数据中去过滤每个节点的数据,那么有没有一种方式可以让 Prometheus 去自动发现我们节点的 node-exporter 程序,并且按节点进行分组呢?是有的,就是我们前面和大家提到过的服务发现。
在 Kubernetes 下,Promethues 通过与 Kubernetes API 集成,目前主要支持5中服务发现模式,分别是:Node、Service、Pod、Endpoints、Ingress。
我们通过 kubectl 命令可以很方便的获取到当前集群中的所有节点信息:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 165d v1.10.0
node02 Ready 85d v1.10.0
node03 Ready 145d v1.10.0
但是要让 Prometheus 也能够获取到当前集群中的所有节点信息的话,我们就需要利用 Node 的服务发现模式,同样的,在 prometheus.yml 文件中配置如下的 job 任务即可:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
通过指定kubernetes_sd_configs的模式为node,Prometheus 就会自动从 Kubernetes 中发现所有的 node 节点并作为当前 job 监控的目标实例,发现的节点/metrics接口是默认的 kubelet 的 HTTP 接口。
prometheus 的 ConfigMap 更新完成后,同样的我们执行 reload 操作,让配置生效:
$ kubectl delete -f prome-cm.yaml
configmap "prometheus-config" deleted
$ kubectl create -f prome-cm.yaml
configmap "prometheus-config" created
# 隔一会儿再执行下面的 reload 操作
$ kubectl get svc -n kube-ops
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus NodePort 10.102.74.90 9090:30358/TCP 5d
......
$ curl -X POST "http://10.102.74.90:9090/-/reload"
配置生效后,我们再去 prometheus 的 dashboard 中查看 Targets 是否能够正常抓取数据,访问任意节点IP:30358:

prometheus nodes target
我们可以看到上面的kubernetes-nodes这个 job 任务已经自动发现了我们3个 node 节点,但是在获取数据的时候失败了,出现了类似于下面的错误信息:
Get http://10.151.30.57:10250/metrics: net/http: HTTP/1.x transport connection broken: malformed HTTP response "\x15\x03\x01\x00\x02\x02"
这个是因为 prometheus 去发现 Node 模式的服务的时候,访问的端口默认是10250,而现在该端口下面已经没有了/metrics指标数据了,现在 kubelet 只读的数据接口统一通过10255端口进行暴露了,所以我们应该去替换掉这里的端口,但是我们是要替换成10255端口吗?不是的,因为我们是要去配置上面通过node-exporter抓取到的节点指标数据,而我们上面是不是指定了hostNetwork=true,所以在每个节点上就会绑定一个端口9100,所以我们应该将这里的10250替换成9100,但是应该怎样替换呢?
这里我们就需要使用到 Prometheus 提供的relabel_configs中的replace能力了,relabel 可以在 Prometheus 采集数据之前,通过Target 实例的 Metadata 信息,动态重新写入 Label 的值。除此之外,我们还能根据 Target 实例的 Metadata 信息选择是否采集或者忽略该 Target 实例。比如我们这里就可以去匹配__address__这个 Label 标签,然后替换掉其中的端口:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
这里就是一个正则表达式,去匹配__address__,然后将 host 部分保留下来,port 替换成了9100,现在我们重新更新配置文件,执行 reload 操作,然后再去看 Prometheus 的 Dashboard 的 Targets 路径下面 kubernetes-nodes 这个 job 任务是否正常了:

prometheus nodes target2
我们可以看到现在已经正常了,但是还有一个问题就是我们采集的指标数据 Label 标签就只有一个节点的 hostname,这对于我们在进行监控分组分类查询的时候带来了很多不方便的地方,要是我们能够将集群中 Node 节点的 Label 标签也能获取到就很好了。
这里我们可以通过labelmap这个属性来将 Kubernetes 的 Label 标签添加为 Prometheus 的指标标签:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
添加了一个 action 为labelmap,正则表达式是__meta_kubernetes_node_label_(.+)的配置,这里的意思就是表达式中匹配都的数据也添加到指标数据的 Label 标签中去。
对于 kubernetes_sd_configs 下面可用的标签如下: 可用元标签:
- __meta_kubernetes_node_name:节点对象的名称
- _meta_kubernetes_node_label:节点对象中的每个标签
- _meta_kubernetes_node_annotation:来自节点对象的每个注释
- _meta_kubernetes_node_address:每个节点地址类型的第一个地址(如果存在) *
关于 kubernets_sd_configs 更多信息可以查看官方文档:kubernetes_sd_config
另外由于 kubelet 也自带了一些监控指标数据,就上面我们提到的10255端口,所以我们这里也把 kubelet 的监控任务也一并配置上:
- job_name: 'kubernetes-nodes'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- job_name: 'kubernetes-kubelet'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:10255'
target_label: __address__
action: replace
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
特别需要注意的是 Kubernetes 1.11+ 版本以后,kubelet 就移除了 10255 端口, metrics 接口又回到了 10250 端口中,所以这里不需要替换端口,但是需要使用 https 的协议。所以如果你使用的是 Kubernetes 1.11+ 版本的化,需要讲上面的 kubernetes-kubelet 任务替换成下面的配置:
- job_name: 'kubernetes-kubelet'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
现在我们再去更新下配置文件,执行 reload 操作,让配置生效,然后访问 Prometheus 的 Dashboard 查看 Targets 路径:
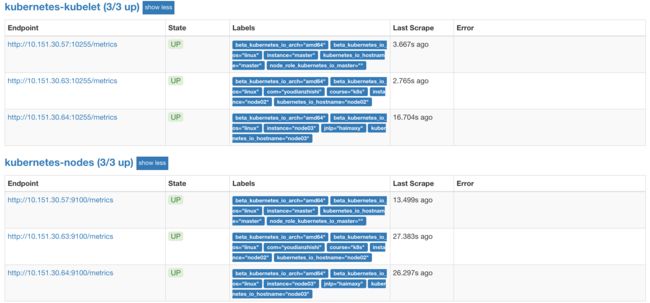
prometheus node targets

现在可以看到我们上面添加的kubernetes-kubelet和kubernetes-nodes这两个 job 任务都已经配置成功了,而且二者的 Labels 标签都和集群的 node 节点标签保持一致了。
现在我们就可以切换到 Graph 路径下面查看采集的一些指标数据了,比如查询 node_load1 指标:
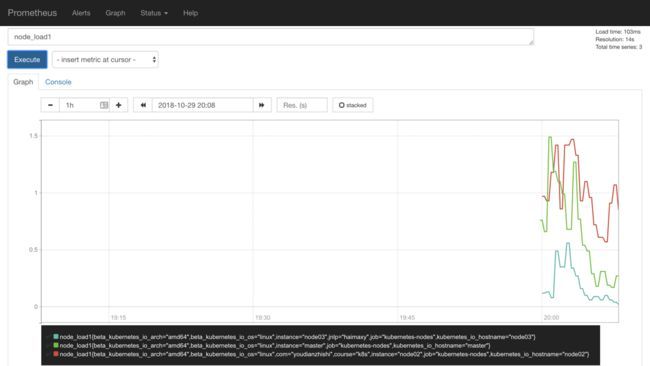
prometheus nodes graph1
我们可以看到将3个 node 节点对应的 node_load1 指标数据都查询出来了,同样的,我们还可以使用 PromQL 语句来进行更复杂的一些聚合查询操作,还可以根据我们的 Labels 标签对指标数据进行聚合,比如我们这里只查询 node03 节点的数据,可以使用表达式node_load1{instance="node03"}来进行查询:

prometheus nodes graph2
到这里我们就把 Kubernetes 集群节点的使用 Prometheus 监控起来了,下节课我们再来和大家学习怎样监控 Pod 或者 Service 之类的资源对象。