Flink Table Store 独立孵化启动 , Apache Paimon 诞生
全网最全大数据面试提升手册!
2023年3月12日,Flink Table Store 项目顺利通过投票,正式进入 Apache 软件基金会 (ASF) 的孵化器,改名为 Apache Paimon (incubating)。
随着 Apache Flink 技术社区的不断成熟和发展,越来越多企业开始利用 Flink 进行流式数据处理,从而提升数据时效性价值,获取业务实时化效果。与此同时,在大数据领域数据湖架构也日益成为新的技术趋势,越来越多企业开始采用 Lakehouse 架构,基于DataLake 构建新一代 Data Warehouse。因此,Flink 社区希望能够将 Flink 的 Streaming 实时计算能力和 Lakehouse 新架构优势进一步结合,推出新一代的 Streaming Lakehouse 技术,促进数据在数据湖上真正实时流动起来,并为用户提供实时离线一体化的开发体验。
但目前业界主流数据湖存储格式项目都是面向 Batch 场景设计的,在数据更新处理时效性上无法满足 Streaming Lakehouse 的需求,因此 Flink 社区在一年多前内部孵化了 Flink Table Store (简称 FTS )子项目,一个真正面向 Streaming 以及 Realtime的数据湖存储项目, 截止目前已经发布了 3 个版本,并得到了大量用户的积极反馈和多家公司的积极贡献。为了让 Flink Table Store 能够有更大的发展空间和生态体系, Flink PMC 经过讨论决定将其捐赠 ASF 进行独立孵化。
截止目前,包括 阿里云,字节跳动、Confluent、同程旅行、Bilibili 等多家公司参与到 Apache Paimon 的贡献,未来希望能够有更多对新一代流式数据湖存储感兴趣的开发者加入 Paimon 社区,一起打造新一代的流式湖仓新架构。
01
什么是 Apache Paimon
Apache Paimon (incubating) 是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。Paimon 采用开放的数据格式和技术理念,可以与 Apache Flink / Spark / Trino 等诸多业界主流计算引擎进行对接,共同推进 Streaming Lakehouse 架构的普及和发展。

开放的数据格式
Paimon 以湖存储的方式基于分布式文件系统管理元数据,并采用开放的 ORC、Parquet、Avro 文件格式,支持各大主流计算引擎,包括 Flink、Spark、Hive、Trino、Presto。未来会对接更多引擎,包括 Doris 和 Starrocks。
大规模实时更新
得益于 LSM 数据结构的追加写能力,Paimon 在大规模的更新数据输入的场景中提供了出色的性能。
Paimon 创新的结合了 湖存储 + LSM + 列式格式 (ORC, Parquet),为湖存储带来大规模实时更新能力,Paimon 的 LSM 的文件组织结构如下:

高性能更新:LSM 的 Minor Compaction,保障写入的性能和稳定性
高性能合并:LSM 的有序合并效率非常高
高性能查询:LSM 的基本有序性,保障查询可以基于主键做文件的 Skipping
在最新的版本中,Paimon 集成了 Flink CDC,通过 Flink DataStream 提供了两个核心能力:
实时同步 Mysql 单表到 Paimon 表,并且实时将上游 Mysql 表结构(Schema)的变更同步到下游的 Paimon 表中。
实时同步 Mysql 整库级别的表结构和数据到 Paimon 中,同时支持表结构变更的同步,并且在同步过程中复用资源,只用少量资源,就可以同步大量的表。
通过与 Flink CDC 的整合,Paimon 可以让业务数据简单高效的流入数据湖中。
数据表局部更新
在数据仓库的业务场景下,经常会用到宽表数据模型,宽表模型通常是指将业务主体相关的指标、维表、属性关联在一起的模型表,也可以泛指将多个事实表和多个维度表相关联到一起形成的宽表。
Paimon 的 Partial-Update 合并引擎可以根据相同的主键实时合并多条流,形成 Paimon 的一张大宽表,依靠 LSM 的延迟 Compaction 机制,以较低的成本完成合并。合并后的表可以提供批读和流读:
批读:在批读时,读时合并仍然可以完成 Projection Pushdown,提供高性能的查询。
流读:下游可以看到完整的、合并后的数据,而不是部分列。

流批一体数据读写
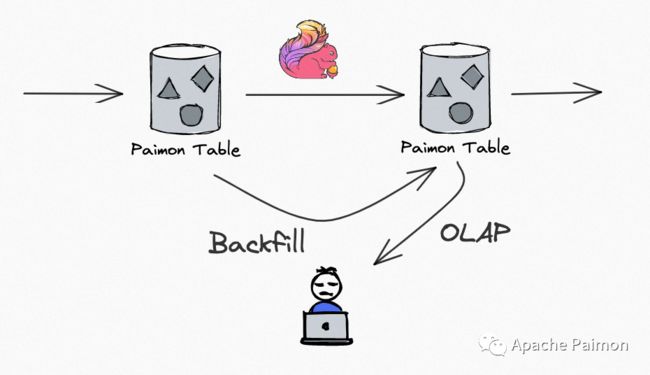
Paimon 作为一个流批一体的数据湖存储,提供流写流读、批写批读,使用 Paimon 来构建 Streaming Pipeline,并且数据沉淀到存储中。
在 Flink Streaming 作业实时更新的同时,可以 OLAP 查询各个 Paimon 表的历史和实时数据,并且也可以通过 Batch SQL,对之前的分区 Backfill,批读批写。
不管输入如何更新,或者业务要求如何合并 (比如 Partial-Update),使用 Paimon 的 Changelog 生成功能,总是能够在流读时获取完全正确的变更日志。
当面对主键表时,为什么你需要完整的 Changelog :
你的输入并不是完整的 changelog,比如丢失了 UPDATE_BEFORE (-U),比如同个主键有多条 INSERT 数据,这就会导致下游的流读聚合有问题,同个主键的多条数据应该被认为是更新,而不是重复计算。
当你的表是 Partial Update ,下游需要看到完整的、合并后的数据,才可以正确的流处理。
你可以使用 Lookup 来实时生成 Changelog:
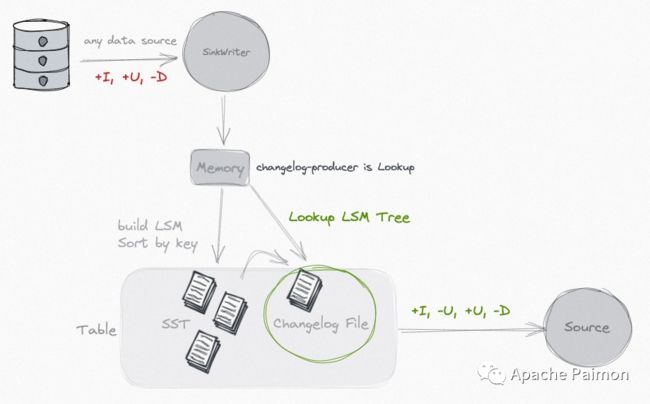
如果你觉得成本过大,你也可以解耦 Commit 和 Changelog 生成,通过 Full-Compaction 和对应较大的时延,以非常低的成本生成 Changelog。
02
版本发布
Flink Table Store 已经发布了三个版本,我们计划在4月份发布 Paimon 0.4 版本,请您保持对 Paimon 的关注。
Paimon 将长期投入实时性、生态和数仓完整性的研发上,构建更好的 Streaming LakeHouse。
如果您有其他需求,请联系我们。
03
致谢
感谢 Apache Flink 的伙伴们,有你们的支持,才有 Apache Paimon 的诞生
感谢项目孵化 Champion 李钰老师,也感谢其他 Mentors: 秦江杰, Robert Metzger, Stephan Ewen
感谢来自阿里巴巴,字节跳动、Confluent、同程旅行、Bilibili 的各位开发者
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!


2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
互联网最坏的时代可能真的来了
我在B站读大学,大数据专业
我们在学习Flink的时候,到底在学习什么?
193篇文章暴揍Flink,这个合集你需要关注一下
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
我们在学习Spark的时候,到底在学习什么?
在所有Spark模块中,我愿称SparkSQL为最强!
硬刚Hive | 4万字基础调优面试小总结
数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解析
【面试&个人成长】2021年过半,社招和校招的经验之谈
大数据方向另一个十年开启 |《硬刚系列》第一版完结
我写过的关于成长/面试/职场进阶的文章
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」