【Linux】2. Linux实操命令
Linux实操命令
- 2. Linux实操
-
- 2.1 远程登陆Linux系统
- 2.2 Vi和Vim编辑器
- 2.3 开机、重启和用户登陆注销
- 2.4 用户管理
- 2.5 指定运行级别指令
- 2.6 重置root密码
- 2.7 帮助指令
- 2.8 文件目录类指令
- 2.9 时间日期类指令
- 2.10 搜索查找类指令
- 2.11 压缩和解压类指令
- 2.12 组管理
- 2.13 权限管理
- 2.14 定时任务调度-crond
- 2.15 定时任务调度-at
- 2.16 Linux磁盘分区、挂载
- 2.17 网络配置
- 2.18 进程管理
- 2.19 服务管理
- 2.20 动态监控进程
- 2.21 监控网络状态
- 2.23 rpm管理
- 2.24 yum
2. Linux实操
2.1 远程登陆Linux系统
- 为什么要远程登陆Linux系统?
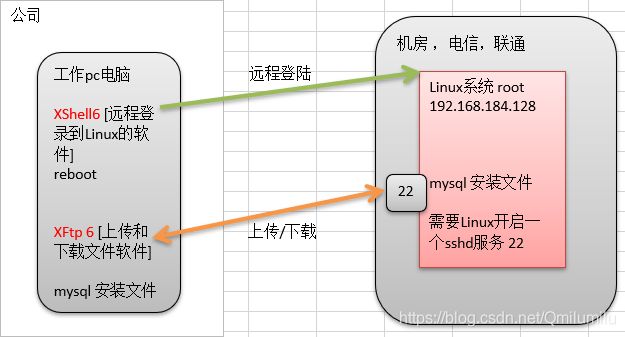
- Linux服务器是开发小组共享的
- 正式上线的项目是运行在公网的
- 因此需要远程登陆到centos进行项目管理或开发
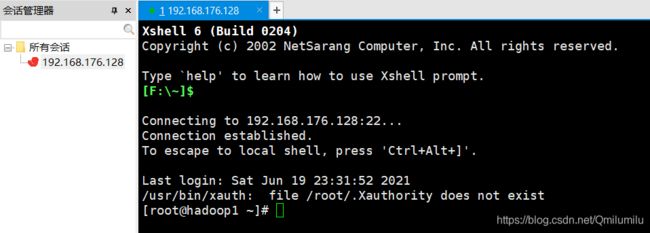
- 远程登录Linux-Xshell 6
- Xshell 是目前最好的远程登录到Linux操作的软件,流畅的速度并且完美解决了中文乱码的问题, 是目前程序员首选的软件
- Xshell [1] 是一个强大的安全终端模拟软件,它支持SSH1, SSH2, 以及MicrosoftWindows 平台的TELNET 协议
- Xshell可以在Windows界面下用来访问远端不同系统下的服务器,从而比较好的达到远程控制终端的目的
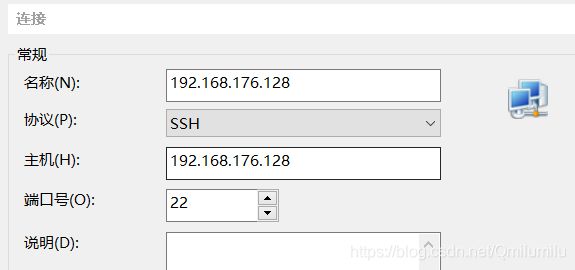
- 安装Xshell 6
- 新建连接:
- 首先获得虚拟Linux系统的IP地址
- 输入
ifconfig命令(出现了自己会变得情况,改成了192.168.176.129,不知道为啥) 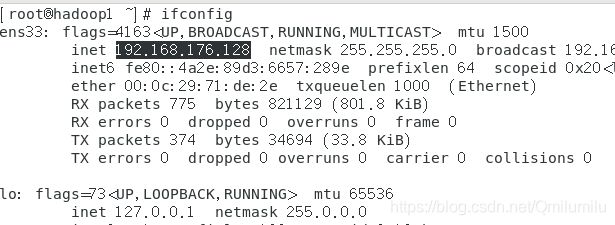
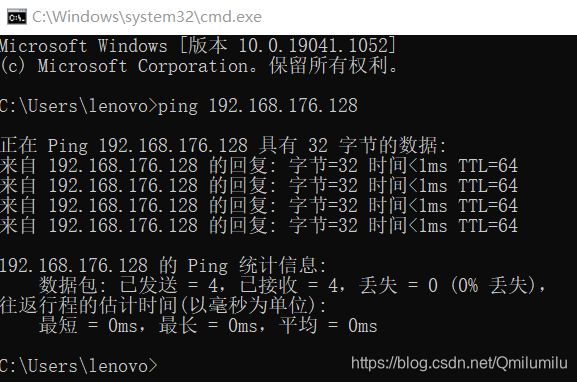
- 输入
- 在Windows DOS下ping这个IP
- Xshell 6下新建连接
- 双击左侧连接即可远程登陆到Linux系统的root用户了
- 首先获得虚拟Linux系统的IP地址
- 远程上传和下载文件 Xftp6
- 是一个基于 windows 平台的功能强大的SFTP、 FTP 文件传输软件。使用了Xftp 以后, windows 用户能安全地在 UNIX/Linux 和 Windows PC 之间传输文件
- Xftp5安装配置和使用
- 新建连接配置
- 使用界面
- 新建连接配置
- Xftp解决中文乱码问题:在选项里设置编码UTF-8
2.2 Vi和Vim编辑器
- 所有的 Linux 系统都会内建 vi 文本编辑器
- Vim 具有程序编辑的能力,可以看做是Vi的增强版本,可以主动的以字体颜色辨别语法的正确性,方便程序设计。代码补完、编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用
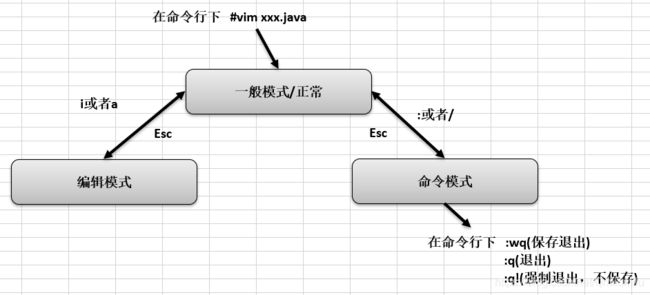
- vi和vim常用的三种模式
- 正常模式:以 vim 打开一个档案就直接进入一般模式了(这是默认的模式)。在这个模式中, 可以使用『上下左右』 按键来移动光标,可以使用『删除字符』 或『删除整行』 来处理档案内容,也可以使用『复制、贴上』 来处理你的文件数据
- 插入模式:按下i, I, o, O, a, A, r, R等任何一个字母之后才会进入编辑模式, 一般来说按i即可
- 命令行模式:在这个模式当中, 可以提供你相关指令,完成读取、存盘、替换、离开 vim 显示行号等的动作则是在此模式中达成的
- 示例:
- 使用vim打开并创建一个文件

- 键入 i 进入插入模式

- esc退出插入模式,键入 wq 写入并退出
- 使用vim打开并创建一个文件
- vi和vim的各个模式之间的互相转换:
- vi和vim的快捷键
- 拷贝当前行
yy, 拷贝当前行向下的5行5yy,并粘贴(输入p) - 删除当前行
dd, 删除当前行向下的5行5dd - 在文件中查找某个单词 [命令行下
/关键字, 回车查找 , 输入n就是查找下一个 ] - 设置文件的行号,取消文件的行号.[命令行下
:set nu和:set nonu] - 编辑 /etc/profile文件,在一般模式下,使用快捷键到底文档的最末行[
G]和最首行[gg] - 编辑 /etc/profile 文件,在一般模式下,将光标移动到 20行
目标行数 + shift + g - 在一个文件中输入 “hello” ,然后在一般模式下,撤销这个动作
u - 更多的看整理的文档
- 拷贝当前行
2.3 开机、重启和用户登陆注销
- 关机&重启命令
- 介绍:
- shutdown
shutdown -h now:表示立即关机(-h:halt关机)shutdown -h 1:表示1分钟后关机shutdown -r now:立即重启
halt:关机reboot:重启sync:把内存的数据同步到磁盘[tom@hadoop1 ~]$ sync
- shutdown
- 注意:
当关机或重启时,都应该先执行一下sync指令,把内存的数据写入磁盘,以防数据丢失
- 介绍:
- 用户登录和注销
- 介绍:
- 登录时尽量少使用root账户,因为有最大权限,避免操作失误;可以先使用普通用户登陆,在使用
su - root命令来切换成管理员身份[tom@hadoop1 ~]$ su - root 密码: 上一次登录:二 6月 22 16:56:42 CST 2021pts/0 [root@hadoop1 ~]# - 在提示符下输入
logout即可注销用户[root@hadoop1 ~]# logout [tom@hadoop1 ~]$
- 登录时尽量少使用root账户,因为有最大权限,避免操作失误;可以先使用普通用户登陆,在使用
- 注意:
logout指令在图像运行级别无效,在运行级别3下有效[root@hadoop1 home]# logout //之前从tom登陆到root,logout会退回到tom [tom@hadoop1 ~]$ logout Connection closing...Socket close. Connection closed by foreign host.
- 介绍:
2.4 用户管理
-
Linux系统是一个多用户多任务的操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统
-
用户管理操作:
-
添加用户:
useradd 用户名-
当创建用户tom成功后,会自动地创建和用户同名的家目录在home/tom
[root@hadoop1 ~]# cd /home [root@hadoop1 home]# ls tom [root@hadoop1 home]# useradd cool [root@hadoop1 home]# ls cool tom [root@hadoop1 home]# -
也可以通过 useradd -d 指定目录 新的用户名,给新创建的用户指定家目录
[root@hadoop1 home]# useradd -d /home/test jack [root@hadoop1 home]# ls cool test tom
-
-
指定/修改用户密码:
passwd 用户名[root@hadoop1 home]# passwd cool 更改用户 cool 的密码 。 新的 密码: 无效的密码: 密码少于 8 个字符 重新输入新的 密码: passwd:所有的身份验证令牌已经成功更新 [cool@hadoop1 ~]$ pwd //pwd显示当前在哪个用户 /home/cool -
删除用户:
userdel 用户名[cool@hadoop1 ~]$ userdel cool //不能自己删除自己 -bash: /usr/sbin/userdel: 权限不够 [root@hadoop1 ~]# userdel cool //刚刚登陆过,可能正在运行 userdel: user cool is currently used by process 10403-
userdel 用户名:删除用户,但是要保留家目录(一般情况下建议保留用户家目录)[root@hadoop1 ~]# userdel cool [root@hadoop1 ~]# cd /home [root@hadoop1 home]# ls cool test tom -
userdel -r cool:删除用户以及用户主目录(注意使用)[root@hadoop1 home]# userdel -r jack [root@hadoop1 home]# ls cool tom
-
-
查询用户信息:
id 用户名[root@hadoop1 home]# id root uid=0(root) gid=0(root) 组=0(root) [root@hadoop1 home]# id cool id: cool: no such user [root@hadoop1 home]# id tom uid=1000(tom) gid=1000(tom) 组=1000(tom) -
切换用户:
su -用户名-
从权限高的用户切换到权限低的用户,不需要输入密码,反之需要
[root@hadoop1 home]# su - tom 上一次登录:二 6月 22 16:56:06 CST 2021从 192.168.176.1pts/0 [tom@hadoop1 ~]$ su - root 密码: 上一次登录:二 6月 22 17:18:31 CST 2021从 192.168.176.1pts/0 [root@hadoop1 ~]# -
当需要返回到原来用户时,使用exit指令
[root@hadoop1 ~]# exit 登出 [tom@hadoop1 ~]$
-
-
查看当前用户/登陆用户:
who am i(第一次登陆时使用的用户)[tom@hadoop1 ~]$ who an i root pts/0 2021-06-22 17:18 (192.168.176.1)//登陆时间 [root@hadoop1 ~]# who am i root pts/0 2021-06-22 17:18 (192.168.176.1) [root@hadoop1 ~]# -
用户组:类似于角色,系统可以对有共性的多个用户进行统一的管理

-
添加组:
groupadd 组名[root@hadoop1 ~]# groupadd wudang -
删除组:
groupdel 组名[root@hadoop1 ~]# groupdel wudang -
增加用户时直接为其指定一个组:
useradd -g 组名 用户名[root@hadoop1 ~]# useradd -g wudang jack [root@hadoop1 ~]# id jack uid=1001(jack) gid=1001(wudang) 组=1001(wudang)如果没有指定,会默认的创建一个与用户同名的组,将该用户放入
[root@hadoop1 ~]# id tom uid=1000(tom) gid=1000(tom) 组=1000(tom) -
修改用户的组:
usermod -g 组名 用户名[root@hadoop1 ~]# groupadd shaolin [root@hadoop1 ~]# usermod -g shaolin jack [root@hadoop1 ~]# id jack uid=1001(jack) gid=1002(shaolin) 组=1002(shaolin)
-
-
-
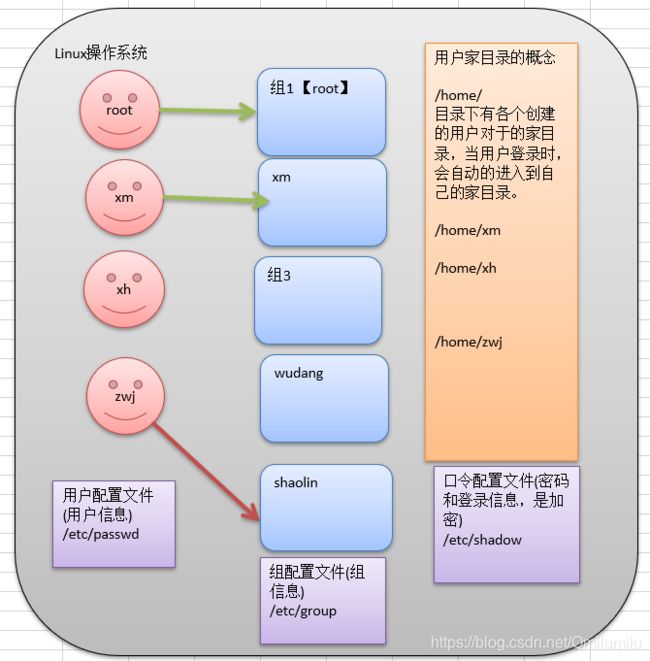
用户和组相关文件:
-
/etc/passwd 文件
-
用户(user)的配置文件,记录用户的各种信息
-
每行的含义: 用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录Shell
[root@hadoop1 home]# vim /etc/passwd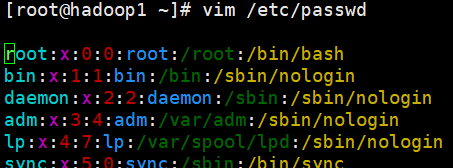
-
-
/etc/shadow 文件
-
口令的配置文件
-
每行的含义: 登录名:加密口令:最后一次修改时间:最小时间间隔:最大时间间隔:警
告时间:不活动时间:失效时间:标志[root@hadoop1 home]# vim /etc/shadow

-
-
/etc/group 文件
-
组(group)的配置文件,记录Linux包含的组的信息
-
每行含义: 组名:口令:组标识号:组内用户列表
[root@hadoop1 home]# vim /etc/group //这里Tom未指明组,则默认创建的同名的组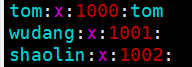
-
-
-
2.5 指定运行级别指令
-
运行级别说明:
- 0 :关机
- 1 :单用户【找回丢失密码】
- 2:多用户状态没有网络服务(无用)
- 3:多用户状态有网络服务(用得最多)
- 4:系统未使用保留给用户
- 5:图形界面(一般默认)
- 6:系统重启
-
切换级别的指令:
[root@hadoop1 ~]# init 3 [root@hadoop1 ~]# init 5 -
常用运行级别是3和5 ,如果要修改默认的运行级别,可改文件设置
-
在centOS7之前,修改/ect/inittab文件中的配置,centOS7后进行了简化:
multi-user.target:analogous to runlevel 3graphical.target:analogous to runlevel 5 -
使用命令查看当前默认运行级别:
[root@hadoop1 home]# systemctl get-default graphical.target -
使用命令设置运行级别:
[root@hadoop1 home]# systemctl set-default multi-user.target Removed symlink /etc/systemd/system/default.target. Created symlink from /etc/systemd/system/default.target to /usr/lib/systemd/system/multi-user.target. [root@hadoop1 home]# systemctl get-default multi-user.target此时再重启会自动进入多用户级别:3
-
2.6 重置root密码
- 首先,启动系统,进入开机界面,在界面中按“
e”进入编辑界面 - 进入编辑界面,使用键盘上的上下键把光标往下移动,找到以““Linux16”开头内容所在的行数”,在行的最后面输入:
init=/bin/sh - 输入完成后,直接按快捷键:Ctrl+x 进入单用户模式
- 在光标闪烁的位置中输入:
mount -o remount,rw /(注意:各个单词间有空格),完成后按键盘的回车键(Enter) - 在新的一行最后面输入:
passwd, 完成后按键盘的回车键(Enter)。输入密码,然后再次确认密码即可(提示:密码长度最好8位以上,但不是必须的),密码修改成功后,会显示passwd…的样式,说明密码修改成功 - 接着,在鼠标闪烁的位置中(最后一行中)输入:
touch /.autorelabel(注意:touch与 /后面有一个空格),完成后按键盘的回车键(Enter) - 继续在光标闪烁的位置中,输入:
exec /sbin/init(注意:exec与 /后面有一个空格),完成后按键盘的回车键(Enter),等待系统自动修改密码(提示:这个过程时间可能有点长,耐心等待),完成后,系统会自动重启,新的密码生效
2.7 帮助指令
当对某个指令不熟悉时,可以使用Linux提供的帮助指令来了解这个指令的使用方法
-
man:获得帮助信息
语法:
man [命令或配置文件][root@hadoop1 ~]# man ls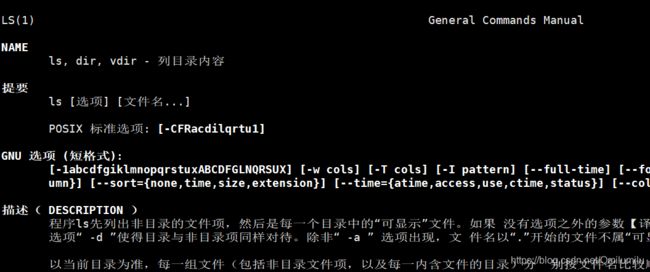
- Linux下,隐藏文件是以 . 开头的
- 命令的选项可以组合使用,如:ls -al → \to → ls -al /root
-
help指令:或的shell内置命令的帮助信息
语法:
help 命令[root@hadoop1 ~]# help cd

2.8 文件目录类指令
-
pwd 指令(print working directory)
- 基本语法:
pwd - 功能描述:显示当前工作目录的绝对路径
- 基本语法:
-
ls指令(list)
- 基本语法:
ls [选项] [目录或是文件] - 常用选项
- -a :显示当前目录所有的文件和目录,包括隐藏的
- -l :以列表的方式显示信息
- 基本语法:
-
cd指令(change directory)
-
基本语法:
cd [参数] -
功能描述:切换到指定目录
-
常用参数:
-
cd ~或cd :回到自己的家目录 -
cd ..回到当前目录的上一级目[root@hadoop1 tom]# who am i root pts/0 2021-06-25 19:17 (192.168.176.1) [root@hadoop1 tom]# cd~ bash: cd~: 未找到命令...//有空格 [root@hadoop1 tom]# cd ~ [root@hadoop1 ~]# [root@hadoop1 ~]# cd /home [root@hadoop1 home]# cd tom [root@hadoop1 tom]# cd .. [root@hadoop1 home]#也可以直接使用路径切换目录
//使用绝对路径 [root@hadoop1 ~]# cd /home/tom [root@hadoop1 tom]# cd /root [root@hadoop1 ~]# //使用相对路径 [root@hadoop1 ~]# cd /home/tom [root@hadoop1 tom]# cd ../../root [root@hadoop1 ~]#
-
-
-
mkdir指令(make directories)
-
基本语法:
mkdir [选项] 要创建的目录 -
功能描述:用于创建目录
[root@hadoop1 ~]# mkdir /home/dog [root@hadoop1 ~]# cd /home [root@hadoop1 home]# ls cool dog jack tom -
常用选项:
-p 创建多级目录
[root@hadoop1 home]# mkdir /home/animal/cat mkdir: 无法创建目录"/home/animal/cat": 没有那个文件或目录 //mkdir无法创建多级目录 [root@hadoop1 home]# mkdir -p /home/animal/cat [root@hadoop1 home]# ls animal cool dog jack tom [root@hadoop1 home]# cd animal [root@hadoop1 animal]# ls cat
-
-
rmdir指令
-
基本语法:
rmdir [选项] 要删除的空目录 -
功能描述:删除空目录
[root@hadoop1 ~]# cd /home [root@hadoop1 home]# rmdir /home/dog [root@hadoop1 home]# ls animal cool jack tom [root@hadoop1 home]# rmdir animal rmdir: 删除 "animal" 失败: 目录非空//注意:只能删除非空目录 -
rm -rf 要删除的非空目录删除非空目录[root@hadoop1 home]# rm -rf animal [root@hadoop1 home]# ls cool jack tom
-
-
touch指令
- 基本语法:
touch 文件名 - 功能描述:创建空文件
- 基本语法:
-
cp指令
-
基本语法:
cp [选项] source dest -
功能描述:拷贝文件到指定目录
//将 /home/aaa.txt 拷贝到 /home/bbb 目录下 [root@hadoop1 ~]# cd /home [root@hadoop1 home]# touch aaa.txt [root@hadoop1 home]# ls aaa.txt cool jack tom [root@hadoop1 home]# mkdir bbb [root@hadoop1 home]# ls aaa.txt bbb cool jack tom [root@hadoop1 home]# cp aaa.txt bbb [root@hadoop1 home]# cd bbb [root@hadoop1 bbb]# ls aaa.txt -
常用选项 -r :递归复制整个文件夹
//递归复制 /home/bbb整个文件夹到/pot下 [root@hadoop1 home]# cp -r /home/bbb /opt [root@hadoop1 home]# cd .. [root@hadoop1 /]# cd /opt [root@hadoop1 opt]# ls bbb rh VMwareTools-10.3.10-13959562.tar.gz vmware-tools-distrib [root@hadoop1 opt]# cd bbb [root@hadoop1 bbb]# ls aaa.txt -
如果复制到的目标文件夹内有同名的文件,如果默认执行覆盖文件操作怎么办
[root@hadoop1 home]# vim aaa.txt [root@hadoop1 home]# cp aaa.txt bbb cp:是否覆盖"bbb/aaa.txt"? y//每次都要确认覆盖操作 [root@hadoop1 home]# \cp aaa.txt bbb//默认覆盖
-
-
rm指令
- 基本语法:
rm [选项] 要删除的文件或目录 - 功能描述:移除文件或者目录
- 常用选项:
- -r :递归删除整个文件夹
- -f : 强制删除不提示
- 基本语法:
-
mv指令
基本语法、功能描述:
-
mv oldNameFile newNameFile(功能描述:重命名) -
mv /temp/movefile /targetFolder(功能描述:移动文件) = 剪切//移动整个目录 [root@hadoop1 home]# ls aaa.txt bbb ccc.txt cool jack tom [root@hadoop1 home]# rm -rf bbb [root@hadoop1 home]# ls aaa.txt ccc.txt cool jack tom [root@hadoop1 home]# cd /opt [root@hadoop1 opt]# mv bbb /home [root@hadoop1 opt]# ls rh VMwareTools-10.3.10-13959562.tar.gz vmware-tools-distrib [root@hadoop1 opt]# cd /home [root@hadoop1 home]# ls aaa.txt bbb ccc.txt cool jack tom
-
-
cat指令(concatenate)
-
基本语法:
cat [选项] 要查看的文件 -
功能描述:查看文件内容
-
常用选项:-n 显示行号
[root@hadoop1 home]# cat -n aaa.txt 1 hello -
cat 只能浏览文件,而不能修改文件,为了浏览方便,一般会带上管道命令
| 其他指令
-
-
more指令
-
基本语法:
more 要查看的文件 -
功能描述:是一个基于VI编辑器的文本过滤器,它以全屏幕的方式按页显示文本文件的内容
-
内置的若干快捷键:
操作 功能说明 空白键 (space) 代表向下翻一页; Enter 代表向下翻『一行』 ; q 代表立刻离开 more ,不再显示该文件内容。 Ctrl+F 向下滚动一屏 Ctrl+B 返回上一屏 = 输出当前行的行号 :f 输出文件名和当前行的行号
-
-
less指令
-
基本语法:
less 要查看的文件 -
功能描述:用来分屏查看文件内容,它的功能与more指令类似,但是比more指令更加强大,支持各种显示终端。 less指令在显示文件内容时,并不是一次将整个文件加载之后才显示,而是根据显示需要加载内容, 对于显示大型文件具有较高的效率
-
内置的若干快捷键:
操作 功能说明 空白键 向下翻动一页; [pagedown] 向下翻动一页 [pageup] 向上翻动一页; /字串 向下搜寻『字串』 的功能; n:向下查找; N:向上查找; ?字串 向上搜寻『字串』 的功能; n:向上查找; N:向下查找; q 离开 less 这个程序;
-
-
echo指令
-
基本语法:
echo [选项] [输出内容] -
功能描述:输出内容到控制台
//使用echo 指令输出环境变量 [root@hadoop1 home]# echo $HOSTNAME hadoop1 //使用echo 指令输出 hello,world! [root@hadoop1 home]# echo "hello world" hello world
-
-
head指令
-
基本语法、功能描述:
-
head 文件(功能描述:查看文件头10行内容)
-
head -n 5 文件(功能描述:查看文件头5行内容, 5可以是任意行数)
[root@hadoop1 home]# head -n 5 /etc/profile # /etc/profile # System wide environment and startup programs, for login setup # Functions and aliases go in /etc/bashrc
-
-
-
tail指令
基本语法、功能描述:
-
tail 文件(功能描述:查看文件头10行内容) -
tail -n 5 文件(功能描述:查看文件头5行内容, 5可以是任意行数) -
tail -f 文件(功能描述:实时追踪该文档的所有更新)[root@hadoop1 home]# tail -f aaa.txt hello tail: aaa.txt:文件已截断 hello,world
-
-
> 指令 和 >> 指令
-
基本语法、功能描述:
ls -l >文件(功能描述:列表的内容写入文件a.txt中(覆盖写))ls -al >>文件(功能描述:列表的内容追加到文件aa.txt的末尾)cat 文件1 > 文件2(功能描述:将文件1的内容覆盖到文件2)echo "内容">> 文件
-
应用案例:
//将 /home 目录下的文件列表 写入到 /home/info.txt 中 [root@hadoop1 home]# ls -l /home > /home/homeinfo.txt [root@hadoop1 home]# ls aaa.txt bbb ccc.txt cool homeinfo.txt jack tom [root@hadoop1 home]# cat homeinfo.txt 总用量 20 -rw-r--r--. 1 root root 12 6月 25 22:13 aaa.txt drwxr-xr-x. 2 root root 4096 6月 25 20:07 bbb -rw-r--r--. 1 root root 0 6月 25 20:06 ccc.txt drwx------. 5 jack wudang 4096 6月 22 17:17 cool -rw-r--r--. 1 root root 0 6月 25 22:20 homeinfo.txt drwx------. 3 jack shaolin 4096 6月 22 17:54 jack drwx------. 15 tom tom 4096 6月 25 19:19 tom //1.使用 > 覆盖 [root@hadoop1 home]# ls -l /home > /home/homeinfo.txt [root@hadoop1 home]# cat homeinfo.txt 总用量 20 -rw-r--r--. 1 root root 12 6月 25 22:13 aaa.txt drwxr-xr-x. 2 root root 4096 6月 25 20:07 bbb -rw-r--r--. 1 root root 0 6月 25 20:06 ccc.txt drwx------. 5 jack wudang 4096 6月 22 17:17 cool -rw-r--r--. 1 root root 0 6月 25 22:20 homeinfo.txt drwx------. 3 jack shaolin 4096 6月 22 17:54 jack drwx------. 15 tom tom 4096 6月 25 19:19 tom //2.使用 >> 追加 [root@hadoop1 home]# ls -l /home >> /home/homeinfo.txt [root@hadoop1 home]# cat homeinfo.txt 总用量 20 -rw-r--r--. 1 root root 12 6月 25 22:13 aaa.txt drwxr-xr-x. 2 root root 4096 6月 25 20:07 bbb -rw-r--r--. 1 root root 0 6月 25 20:06 ccc.txt drwx------. 5 jack wudang 4096 6月 22 17:17 cool -rw-r--r--. 1 root root 0 6月 25 22:20 homeinfo.txt drwx------. 3 jack shaolin 4096 6月 22 17:54 jack drwx------. 15 tom tom 4096 6月 25 19:19 tom 总用量 24 -rw-r--r--. 1 root root 12 6月 25 22:13 aaa.txt drwxr-xr-x. 2 root root 4096 6月 25 20:07 bbb -rw-r--r--. 1 root root 0 6月 25 20:06 ccc.txt drwx------. 5 jack wudang 4096 6月 22 17:17 cool -rw-r--r--. 1 root root 396 6月 25 22:20 homeinfo.txt drwx------. 3 jack shaolin 4096 6月 22 17:54 jack drwx------. 15 tom tom 4096 6月 25 19:19 tom//将当前日历信息 追加到 /home/mycal 文件中 [root@hadoop1 home]# cal >> /home/mycal.txt [root@hadoop1 home]# cat mycal.txt 六月 2021 日 一 二 三 四 五 六 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 [root@hadoop1 home]# cal >> /home/mycal.txt [root@hadoop1 home]# cat mycal.txt 六月 2021 日 一 二 三 四 五 六 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 六月 2021 日 一 二 三 四 五 六 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
-
-
ln 指令
-
基本语法、功能描述:
ln -s [原文件或目录] [软链接名](功能描述:给原文件创建一个软链接)=快捷方式 -
应用实例 :
//在/home 目录下创建一个软连接 linkToRoot,连接到 /root 目录 [root@hadoop1 home]# ln -s /root/ /home/myroot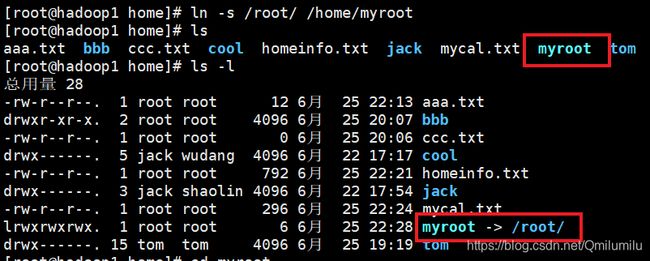
//访问myroot就是root目录 [root@hadoop1 home]# cd myroot [root@hadoop1 myroot]# ls anaconda-ks.cfg hello.java initial-setup-ks.cfg 公共 模板 视频 图片 文档 下载 音乐 桌面//删除软链接 [root@hadoop1 myroot]# rm /home/myroot rm:是否删除符号链接 "/home/myroot"?y
-
-
history指令
-
基本语法、功能描述:
history(功能描述:查看已经执行过历史命令)

-
显示最近使用过的10个指令
[root@hadoop1 home]# history 5 208 cd .. 209 cd /home 210 ll 211 history 212 history 5 -
执行指定历史编号为210的指令
[root@hadoop1 home]# !210 ll 总用量 28 -rw-r--r--. 1 root root 12 6月 25 22:13 aaa.txt drwxr-xr-x. 2 root root 4096 6月 25 20:07 bbb -rw-r--r--. 1 root root 0 6月 25 20:06 ccc.txt drwx------. 5 jack wudang 4096 6月 22 17:17 cool
-
2.9 时间日期类指令
-
date指令-显示当前日期
-
基本语法、功能描述:
date(功能描述:显示当前时间)date +%Y(功能描述:显示当前年份)date +%m(功能描述:显示当前月份)date +%d(功能描述:显示当前是哪一天)date "+%Y-%m-%d %H:%M:%S"(功能描述:显示年月日时分秒)
-
应用实例:
-
案例1:显示当前时间信息
[root@hadoop1 home]# date 2021年 06月 25日 星期五 23:06:37 CST -
案例2:显示当前时间年月日
[root@hadoop1 home]# date "+%Y-%m-%d" 2021-06-25 -
案例3:显示当前时间年月日时分秒
[root@hadoop1 home]# date "+%Y-%m-%d %H:%M:%S" 2021-06-25 23:08:13
-
-
-
date指令-设置日期
-
基本语法:
date -s字符串时间 -
应用实例:设置当前时间
[root@hadoop1 home]# date -s "2021-06-25 23:08:13" 2021年 06月 25日 星期五 23:08:13 CST [root@hadoop1 home]# date 2021年 06月 25日 星期五 23:08:23 CST
-
-
cal指令
-
基本语法:
cal [选项] -
功能描述:不加选项,显示本月日历
-
应用实例:

-
2.10 搜索查找类指令
-
find指令
-
基本语法:
find [搜索范围] [选项] -
功能描述:将从指定目录向下递归地遍历其各个子目录,将满足条件的文件或者目录显示在终端
-
选项说明:
选项 功能 -name<查询方式> 按照指定的文件名查找模式查找文件 -user<用户名> 查找属于指定用户名所有文件 -size<文件大小> 按照指定的文件大小查找文件(+n 大于 -n小于 n 等于) -
案例应用:
-
案例一:根据名称查找/home 目录下的hello.txt文件
[root@hadoop1 LiveOS]# find /home -name aaa.txt /home/aaa.txt /home/bbb/aaa.txt -
案例二:按拥有者:查找/opt目录下,用户名称为 nobody的文件
[root@hadoop1 LiveOS]# find /opt -user root -
案例3: 查找整个linux系统下大于200m的文件(+n 大于 -n小于 n等于)
[root@hadoop1 home]# find / -size +200M /proc/kcore find: ‘/proc/12894/task/12894/fd/5’: 没有那个文件或目录 find: ‘/proc/12894/task/12894/fdinfo/5’: 没有那个文件或目录 find: ‘/proc/12894/fd/6’: 没有那个文件或目录 find: ‘/proc/12894/fdinfo/6’: 没有那个文件或目录 /run/media/root/CentOS 7 x86_64/LiveOS/squashfs.img [root@hadoop1 root]# cd /run/media/root/CentOS\ 7\ x86_64/LiveOS/ [root@hadoop1 LiveOS]# ls -l 总用量 442741 -rw-r--r--. 1 root root 453365760 11月 26 2018 squashfs.img -r--r--r--. 1 root root 224 11月 26 2018 TRANS.TBL //453365760不适合阅读,加-lh,这里h是humam,更人性化 [root@hadoop1 LiveOS]# ls -lh 总用量 433M -rw-r--r--. 1 root root 433M 11月 26 2018 squashfs.img -r--r--r--. 1 root root 224 11月 26 2018 TRANS.TBL
-
-
-
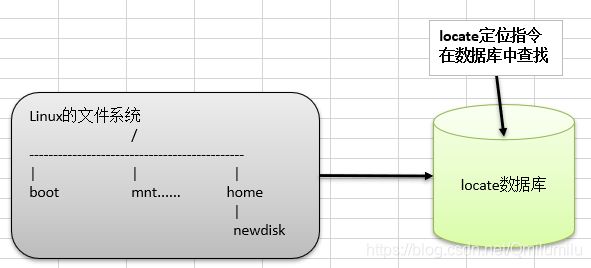
locate指令
-
基本语法:
locate 搜索文件 -
功能描述:可以快速定位文件路径。 locate指令利用事先建立的系统中所有文件名称及路径
的locate数据库实现快速定位给定的文件。 Locate指令无需遍历整个文件系统,查询速度较快。为了保证查询结果的准确度,管理员必须定期更新locate时刻 -
特别说明:由于locate指令基于数据库进行查询,所以第一次运行前,必须使用updatedb指令创建locate数据库
-
应用案例:
//使用locate 指令快速定位 hello.txt 文件所在目录 [root@hadoop1 LiveOS]# updatedb [root@hadoop1 LiveOS]# locate aaa.txt /home/aaa.txt /home/bbb/aaa.txt
-
-
which指令
-
基本语法:
which 指令名 -
功能描述:查看某个指令在那个目录下
[root@hadoop1 LiveOS]# which ls alias ls='ls --color=auto' /usr/bin/ls
-
-
grep指令和 管道符号 |
-
基本语法:
grep [选项] 查找内容 源文件 -
功能描述:过滤查找 , 管道符, “|”,表示将前一个命令的处理结果输出传递给后面的命令处理

-
常用选项:
选项 功能 -n 显示匹配行及行号。 -i 忽略字母大小写 -
应用实例:
//请在 hello.txt 文件中,查找 "yes" 所在行,并且显示行号 //写法1: [root@hadoop1 home]# cat /home/a.txt | grep "yes" yes yes yes [root@hadoop1 home]# cat /home/a.txt | grep -n "yes" 2:yes 4:yes 5:yes //写法2: [root@hadoop1 home]# grep -n "yes" /home/a.txt 2:yes 4:yes 5:yes
-
2.11 压缩和解压类指令
-
gzip/gunzip 指令
-
基本语法、功能描述:
gzip 文件(功能描述:压缩文件,只能将文件压缩为.gz文件*)gunzip 文件.gz(功能描述:解压缩文件命令)
-
应用实例:
//压缩 [root@hadoop1 home]# gzip a.txt [root@hadoop1 home]# ls aaa.txt a.txt.gz bbb ccc.txt cool homeinfo.txt jack mycal.txt tom //解压 [root@hadoop1 home]# gunzip a.txt.gz [root@hadoop1 home]# ls aaa.txt a.txt bbb ccc.txt cool homeinfo.txt jack mycal.txt tom
-
-
zip/unzip 指令
-
基本语法、功能描述:
zip [选项] XXX.zip 将要压缩的内容(功能描述:压缩文件和目录的命令)unzip [选项] XXX.zip(功能描述:解压缩文件)
-
zip常用选项
-r:递归压缩,即压缩目录
-
unzip的常用选项
-d<目录> : 指定解压后文件的存放目录
-
应用实例:
//将 /home下的 所有文件进行压缩成 mypackage.zip [root@hadoop1 home]# zip -r myhome.zip /home [root@hadoop1 home]# ls aaa.txt a.txt bbb ccc.txt cool homeinfo.txt jack mycal.txt myhome.zip tom //将 mypackge.zip 解压到 /opt/tmp 目录下 [root@hadoop1 home]# mkdir /opt/tmp [root@hadoop1 home]# unzip -d /opt/tmp /home/myhome.zip [root@hadoop1 home]# cd /opt/tmp/ [root@hadoop1 tmp]# ls home
-
-
tar 指令
-
基本语法、功能描述:
tar [选项] XXX.tar.gz 打包的内容(功能描述:打包目录,压缩后的文件格式.tar.gz) -
选项说明:
选项 功能 -c 产生.tar打包文件 -v 显示详细信息 -f 指定压缩后的文件名 -z 打包同时压缩 -x 解包.tar文件 -
应用实例:
//压缩多个文件,将 /home/a.txt 和 /home/aaa.txt 压缩成 mya.tar.gz [root@hadoop1 home]# tar -zcvf mya.tar.gz /home/a.txt /home/aaa.txt tar: 从成员名中删除开头的“/” /home/a.txt /home/aaa.txt [root@hadoop1 home]# ls aaa.txt a.txt bbb ccc.txt cool homeinfo.txt jack mya.tar.gz mycal.txt myhome.zip tom //将 mya.tar.gz 解压到/opt/tmp [root@hadoop1 tmp]# tar -zxvf /home/mya.tar.gz -C /opt/tmp
-
2.12 组管理
-
Linux组基本介绍
-
在linux中每个用户必须属于一个组,不能独立于组外
-
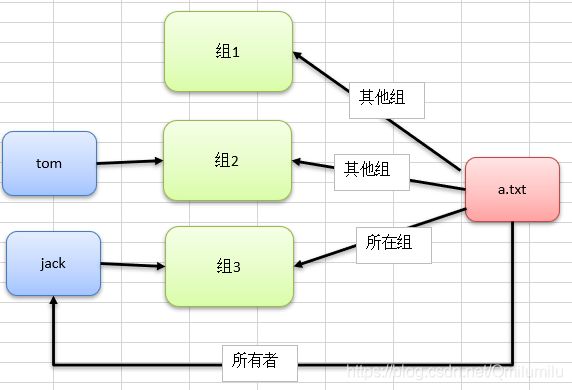
在linux中每个文件有所有者、所在组、其它组的概念
-
所有者:一般为文件的创建者,谁创建了该文件, 就自然的成为该文件的所有者
-
所在组:默认为所有者所在的组,对该文件有一定的权限
-
其他组:除了所在组的其他的组,对该文件有一定的权限
-
-
-
文件/目录 所有者
-
查看文件的所有者:
ls -ahl[root@hadoop1 home]# ls -ahl 总用量 900K drwxr-xr-x. 6 root root 4.0K 6月 26 00:27 . dr-xr-xr-x. 18 root root 4.0K 6月 25 20:02 .. -rw-r--r--. 1 root root 12 6月 25 22:13 aaa.txt -rw-r--r--. 1 root root 27 6月 26 00:09 a.txt drwxr-xr-x. 2 root root 4.0K 6月 25 20:07 bbb -rw-r--r--. 1 root root 0 6月 25 20:06 ccc.txt drwx------. 5 jack wudang 4.0K 6月 22 17:17 cool -rw-r--r--. 1 root root 792 6月 25 22:21 homeinfo.txt drwx------. 3 jack shaolin 4.0K 6月 22 17:54 jack -
修改文件所有者:
chown 用户名 文件名[root@hadoop1 home]# touch c.txt [root@hadoop1 home]# ll -rw-r--r--. 1 root root 0 6月 26 15:33 c.txt [root@hadoop1 home]# chown tom c.txt [root@hadoop1 home]# ll -rw-r--r--. 1 tom root 0 6月 26 15:33 c.txt
-
-
组的创建
-
基本语法:
groupadd 组名 -
应用实例:
[root@hadoop1 home]# groupadd monster [root@hadoop1 home]# useradd -g monster fox [root@hadoop1 home]# id fox uid=1002(fox) gid=1003(monster) 组=1003(monster)
-
-
文件/目录 所在组
当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组
-
查看文件/目录所在组
ls –ahl[fox@hadoop1 ~]$ pwd /home/fox [fox@hadoop1 ~]$ touch ok.txt [fox@hadoop1 ~]$ ll 总用量 0 -rw-r--r--. 1 fox monster 0 6月 28 23:22 ok.txt //ok.txt文件所有者是fox,所在的组就是fox所在的monster //或使用ls –ahl查看 [fox@hadoop1 ~]$ ls -ahl 总用量 36K drwx------. 5 fox monster 4.0K 6月 28 23:22 . drwxr-xr-x. 7 root root 4.0K 6月 28 23:18 .. -rw-r--r--. 1 fox monster 0 6月 28 23:22 ok.txt -
修改文件所在的组
chgrp 组名 文件名[root@hadoop1 ~]# cd /home [root@hadoop1 home]# ll 总用量 896 -rw-r--r--. 1 root root 0 6月 25 20:06 ccc.txt [root@hadoop1 home]# chgrp monster ccc.txt [root@hadoop1 home]# ll 总用量 896 -rw-r--r--. 1 root monster 0 6月 25 20:06 ccc.txt
-
-
其它组
除文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组
-
改变用户所在组
在添加用户时,可以指定将该用户添加到哪个组中,同样的用root的管理权限可以改变某个用户所在的组
-
基本语法:
-
usermod –g组名 用户名 -
usermod –d目录名 用户名 改变该用户登陆的初始目录(特别说明:用户需要有进入到新目录的权限)
-
-
应用实例:
[root@hadoop1 home]# id jack uid=1001(jack) gid=1002(shaolin) 组=1002(shaolin) //此时jack在shaolin组,现在要改到tom组 //先查查有没有tom组 [root@hadoop1 home]# cat /etc/group | grep tom tom:x:1000:tom [root@hadoop1 home]# usermod -g tom jack [root@hadoop1 home]# ll 总用量 896 drwx------. 3 jack tom 4096 6月 22 17:54 jack
-
2.13 权限管理
ls -l 中显示的内容如下:
-rw-r--r--. 1 root root 27 6月 26 00:09 a.txt
-
基本介绍:0-9位说明
- 第0位确定文件类型(d, - , l , c , b)
- d:目录,相当于Windows的文件夹
- l:链接,相当于Windows的快捷方式
- c:字符设备文件,鼠标,键盘
- b:块设备,比如硬盘
- 第1-3位确定所有者(该文件的所有者)拥有该文件的权限。 —User
- 第4-6位确定所属组(同用户组的)拥有该文件的权限, —Group
- 第7-9位确定其他用户拥有该文件的权限 —Other
- 第0位确定文件类型(d, - , l , c , b)
-
rwx权限详解
-
rwx作用到文件
-
r:代表可读(read):可以读取,查看
-
w:代表可写(write):可以修改
注意:不代表可以删除该文件删除一个文件的前提条件是对该文件所在的目录有写权限,才能删除该文件
-
x:代表可执行(execute):可以被执行
-
-
rwx作用到目录
- r:代表可读(read):可以读取, ls查看目录内容
- w:代表可写(write):可以修改,目录内创建+删除+重命名目录
- x:代表可执行(execute):可以进入该目录
-
-
举例:
- -rwxrw-r-- 1 root root 1213 Feb 2 09:39 abc.txt
- 解释:
- 第一组rwx : 文件拥有者的权限是读、写和执行
- 第二组rw- : 与文件拥有者同一组的用户的权限是读、写但不能执行
- 第三组r-- : 不与文件拥有者同组的其他用户的权限是读不能写和执行
- 1:文件:硬链接数,目录:子目录数
- root:用户
- root:组
- 1213:文件大小
- Feb 2 09:39:最后修改时间
- abc.txt:文件名
- 可用数字表示为:r=4,w=2,x=1 因此rwx=4+2+1=7
-
修改权限-chmod
- 通过chmod指令,可以修改文件或者目录的权限

-
第一种方式: + 、 -、 = 变更权限
-
u:所有者, g:所有组, o:其他人, a:所有人(u、 g、 o的总和)
-
基本语法:
chmod u=rwx,g=rx,o=x 文件目录名chmod o+w 文件目录名chmod a-x 文件目录名
-
应用案例:
//给abc文件 的所有者读写执行的权限,给所在组读执行权限,给其它组读执行权限 [root@hadoop1 home]# chmod u=rwx,g=rx,o=rx a.txt [root@hadoop1 home]# ll -rwxr-xr-x. 1 root root 27 6月 26 00:09 a.txt //给abc文件的所有者除去执行的权限,增加组写的权限 [root@hadoop1 home]# chmod u-x,g+w a.txt [root@hadoop1 home]# ll -rw-rwxr-x. 1 root root 27 6月 26 00:09 a.txt //给abc文件的所有用户添加读的权限 [root@hadoop1 home]# chmod a+r a.txt [root@hadoop1 home]# ll -rw-rwxr-x. 1 root root 27 6月 26 00:09 a.txt
-
-
第二种方式:通过数字变更权限
-
r=4 w=2 x=1 rwx=4+2+1=7
-
chmod u=rwx,g=rx,o=x 文件目录名=chmod 751 文件目录名 -
应用实例:
[root@hadoop1 home]# chmod 755 a.txt [root@hadoop1 home]# ll -rwxr-xr-x. 1 root root 27 6月 26 00:09 a.txt
-
-
修改文件/目录所有者-chown
chown 新所有者 文件名/目录改变文件的所有者chown 新所有者:新所有组 文件名/目录改变用户的所有者和所有组chown -R 新所有者 目录将目录中的所有文件都改成新所有者
-
修改文件/目录所在组-chgrp
chgrp 新所有者 文件名/目录改变文件的所有组
2.14 定时任务调度-crond
-
crond 任务调度概述
-
任务调度:是指系统在某个时间执行的特定的命令或程序
-
任务调度分类:
- 系统工作:有些重要的工作必须周而复始地执行。如病毒扫描等
- 个别用户工作:个别用户可能希望执行某些程序,比如对mysql数据库的备份

-
-
基本语法 :
crontab [选项] -
常用选项:
选项 功能描述 -e 编辑crontab定时任务 -l 查询crontab任务 -r 删除当前用户所有的crontab任务 service crond restart 重启任务调度 -
应用实例:
[root@hadoop1 home]# ls aaa.txt a.txt bbb ccc.txt cool c.txt fox homeinfo.txt jack mya.tar.gz mycal.txt myhome.zip tom [root@hadoop1 home]# crontab -e //输入*/1 * * * * ls -l /etc/ > /home/crontabtest.txt //每一分钟,将etc中的内容,重定向到文件crontabtest.txt中 no crontab for root - using an empty one crontab: installing new crontab [root@hadoop1 home]# ll -rw-r--r--. 1 root root 0 6月 29 16:20 crontabtest.txt [root@hadoop1 home]# rm crontabtest.txt //删除文件后 rm:是否删除普通空文件 "crontabtest.txt"?y 您在 /var/spool/mail/root 中有邮件 [root@hadoop1 home]# ll //一分钟后再次生成 -rw-r--r--. 1 root root 0 6月 29 16:21 crontabtest.txt -
*/1 * * * * ls -l /etc/ > /home/crontabtest.txt:细节参数说明-
5个占位符的说明
项目 含义 范围 第一个“*” 一小时当中的第几分钟 0-59 第二个“*” 一天当中的第几小时 0-23 第三个“*” 一个月当中的第几天 1-31 第四个“*” 一年当中的第几月 1-12 第五个“*” 一周当中的星期几 0-7(0和7都代表星期日) -
特殊符号的说明
特殊符号 含义 * 代表任何时间。 比如第一个“*”就代表一小时中每分钟都执行一 次的意思。 , 代表不连续的时间。 比如“0 8,12,16 * * * 命令”, 就代表在每天 的8点0分, 12点0分, 16点0分都执行一次命令 - 代表连续的时间范围。 比如“0 5 * * 1-6命令”, 代表在周一到周 六的凌晨5点0分执行命令 */n 代表每隔多久执行一次。 比如“*/10 * * * * 命令”, 代表每隔 10分钟就执行一遍命令 -
特定时间执行任务案例
时间 含义 45 22 * * * 命令 在22点45分执行命令 0 17 * * 1 命令 每周一的17点0分执行命令 0 5 1,15 * * 命令 每月1号和15号的凌晨5点0分执行命令 40 4 * * 1-5 命令 每周一到周五的凌晨4点40分执行命令 */10 4 * * * 命令 每天的凌晨4:00开始到4:50, 每隔10分钟执行一次命令 0 0 1,15 * 1 命令 每月1号和15号, 每周1的0点0分都会执行命令。 注意:星期几和几号最好不要同时出现, 因为他们定义的都是天。 非常容易让管理员混乱
//案例:每天凌晨2:00 将mysql数据库 testdb ,备份到文件中 1. crontab -e 2. 0 2 * * * mysqldump -u root -proot testdb > /home/db.bak
-
-
使用脚本应用案例:
每隔1分钟, 将当前日期和日历都追加到 /home/mycal 文件中
-
编写脚本
[root@hadoop1 home]# vim myshell.sh //date >> /home/mycal //cal >> /home/mycal 您在 /var/spool/mail/root 中有新邮件 [root@hadoop1 home]# ll -rw-r--r--. 1 root root 39 7月 2 09:03 myshell.sh -
给root用户赋予执行脚本文件的权限
[root@hadoop1 home]# chmod u+x myshell.sh [root@hadoop1 home]# ll -rwxr--r--. 1 root root 39 7月 2 09:03 myshell.sh -
执行脚本
[root@hadoop1 home]# ./myshell.sh [root@hadoop1 home]# ll -rw-r--r--. 1 root root 200 7月 2 09:05 mycal -rwxr--r--. 1 root root 39 7月 2 09:03 myshell.sh [root@hadoop1 home]# cat mycal 2021年 07月 02日 星期五 09:05:54 CST 七月 2021 日 一 二 三 四 五 六 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 -
使用crond定时执行脚本
[root@hadoop1 home]# crontab -l //查看当前crond任务 */1 * * * * le -l /etc/ > /home/crontabtest.txt [root@hadoop1 home]# crontab -e //编辑新的crond任务 crontab: installing new crontab 您在 /var/spool/mail/root 中有新邮件 [root@hadoop1 home]# crontab -l */1 * * * * le -l /etc/ > /home/crontabtest.txt */1 * * * * /home/myshell.sh [root@hadoop1 home]# cat mycal 2021年 07月 02日 星期五 09:05:54 CST 七月 2021 日 一 二 三 四 五 六 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 [root@hadoop1 home]# cat mycal //时间过了一分钟,文件内容有更新 2021年 07月 02日 星期五 09:05:54 CST 七月 2021 日 一 二 三 四 五 六 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 2021年 07月 02日 星期五 09:16:02 CST 七月 2021 日 一 二 三 四 五 六 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
-
2.15 定时任务调度-at
-
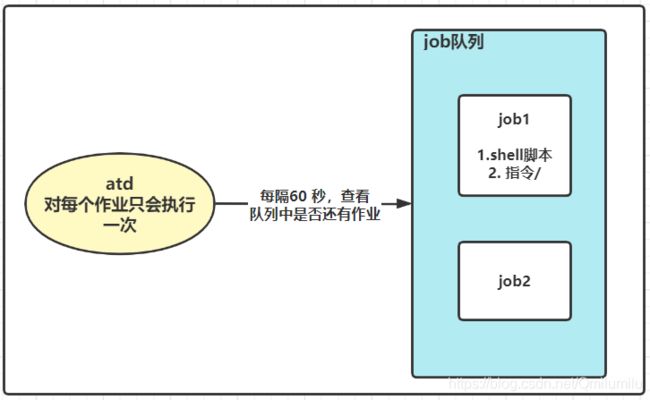
概述:
-
at命令是一次性定时计划任务,at的守护进程atd会以后台模式运行,检查作业队列
-
默认情况下,60秒检查一次作业队列(有作业是,会检查作业运行时间,如果时间与当前时间不匹配,则运行此作业)
-
at命令是一次性的,执行完就不再执行了
-
在使用at命令前,一定要保证atd进程的启动,可以使用指令来查看
ps -ef | grep atd[root@hadoop1 home]# ps -ef | grep atd root 7775 1 0 08:53 ? 00:00:00 /usr/sbin/atd -f root 11324 9658 0 10:05 pts/0 00:00:00 grep --color=auto atd
-
-
原理图:
-
基本语法:
at [选项] [时间]Ctrl + D 结束at命令的输入 -
选项
选项 含义 -m 当指定的任务被完成后,将给用户发送邮件 -I atq的别名 -d atm的别名 -v 显示任务将被执行的时间 -c 打印任务内容到标准输出 -V 显示版本信息 -q <队列> 使用指定队列 -
时间的定义:
- 接受在当天的hh:mm(小时:分钟)式的时间指定,加入该时间已经过去,那么就放到第二天执行
- 使用midnight(深夜),noon(中午),teatime(下午,一般是下午4点)等比较模糊的词语来指定时间
- 采用12小时计时制,即在时间后面加AM、PM,如12pm
- 指定命令执行的具体时间:如 04:00 2021-03-1
- 使用相对计时法:如now + 5 minutes(hours、days、weeks)
- 使用today、tomorrow
-
应用案例:
[root@hadoop1 ~]# at 5pm + 2 days at> /bin/ls /home<EOT> //输入两次ctrl+d 退出编辑 job 3 at Sun Jul 4 17:00:00 2021 [root@hadoop1 ~]# atq //atq查看当前还未执行的job 3 Sun Jul 4 17:00:00 2021 a root [root@hadoop1 ~]# at 5pm tomorrow //明天下午5点执行 at> date > /root/date100.log<EOT> job 6 at Sat Jul 3 17:00:00 2021 [root@hadoop1 ~]# atq 6 Sat Jul 3 17:00:00 2021 a root 3 Sun Jul 4 17:00:00 2021 a root [root@hadoop1 ~]# atrm 3 //atrm 编号 :删除指定作业 您在 /var/spool/mail/root 中有新邮件 [root@hadoop1 ~]# atq 6 Sat Jul 3 17:00:00 2021 a root
2.16 Linux磁盘分区、挂载
-
Linux分区
-
原理介绍:
- Linux来说无论有几个分区,分给哪一目录使用,它归根结底就只有一个根目录,一个独立且唯一的文件结构 , Linux中每个分区都是用来组成整个文件系统的一部分
- Linux采用了一种叫“载入”的处理方法,它的整个文件系统中包含了一整套的文件和目录,且将一个分区和一个目录联系起来。这时要载入的一个分区将使它的存储空间在一个目录下获得
-
原理图:
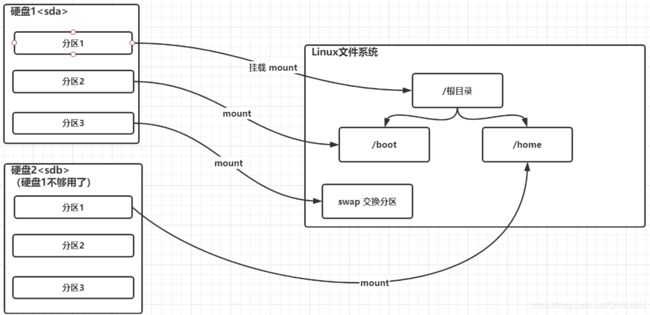
-
硬盘说明:
- Linux硬盘分IDE硬盘和SCSI硬盘,目前基本上是SCSI硬盘
- 对于IDE硬盘,驱动器标识符为“
hdx~”,其中“hd”表明分区所在设备的类型,这里是指
IDE硬盘了。“x”为盘号(a为基本盘, b为基本从属盘, c为辅助主盘, d为辅助从属
盘) ,“~”代表分区,前四个分区用数字1到4表示,它们是主分区或扩展分区,从5开始就是逻辑分区。例, hda3表示为第一个IDE硬盘上的第三个主分区或扩展分区,hdb2表示为第二个IDE硬盘上的第二个主分区或扩展分区 - 对于SCSI硬盘,则标识为“
sdx~”, SCSI硬盘是用“sd”来表示分区所在设备的类型的,其余则和IDE硬盘的表示方法一样
-
查看所有设备挂载情况
-
lsblk[root@hadoop1 ~]# lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTsda 8:0 0 20G 0 disk ├─sda1 8:1 0 1G 0 part /boot├─sda2 8:2 0 2G 0 part [SWAP]└─sda3 8:3 0 17G 0 part /sr0 11:0 1 1024M 0 rom -
lsblk -f[root@hadoop1 ~]# lsblk -f //FSTYPE LABEL:文件系统基本类型 //UUID:每个分区40位的唯一标识符 //MOUNTPOINT:挂载点 NAME FSTYPE LABEL UUID MOUNTPOINTsda //分区情况 ├─sda1 ext4 2b4b1a15-338f-4f48-9f1b-f452554cd50b /boot├─sda2 swap 7a814b32-ba6d-4ece-8bd4-22616bb801f1 [SWAP]└─sda3 ext4 bd3d6bdf-9bbf-4610-bda0-4dea8e07c746 /sr0
-
-
-
挂载的经典案例
-
说明:下面我们以增加一块硬盘为例来熟悉下磁盘的相关指令和深入理解磁盘分区、挂
载、卸载的概念 -
如何增加一块硬盘?
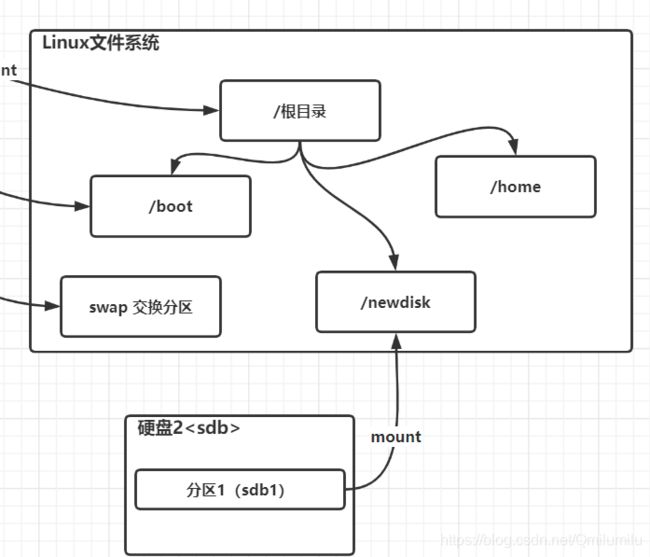
-
虚拟机添加硬盘
虚拟机设置 → \to →添加 → \to →硬盘 → \to →设置1GB → \to →使用SCSI硬盘
[root@hadoop1 home]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 20G 0 disk ├─sda1 8:1 0 1G 0 part /boot ├─sda2 8:2 0 2G 0 part [SWAP] └─sda3 8:3 0 17G 0 part / sdb 8:16 0 1G 0 disk //新的硬盘已经添加 sr0 11:0 1 1024M 0 rom -
分区
-
分区命令:
fdisk /dev/sdb——所有的设备都在dev文件夹下 -
分区:
[root@hadoop1 home]# fdisk /dev/sdb 欢迎使用 fdisk (util-linux 2.23.2)。 更改将停留在内存中,直到您决定将更改写入磁盘。 使用写入命令前请三思。 Device does not contain a recognized partition table 使用磁盘标识符 0x3f7d1ba5 创建新的 DOS 磁盘标签。 命令(输入 m 获取帮助):m 命令操作 a toggle a bootable flag b edit bsd disklabel c toggle the dos compatibility flag d delete a partition g create a new empty GPT partition table G create an IRIX (SGI) partition table l list known partition types m print this menu n add a new partition o create a new empty DOS partition table p print the partition table q quit without saving changes s create a new empty Sun disklabel t change a partition's system id u change display/entry units v verify the partition table w write table to disk and exit x extra functionality (experts only) 命令(输入 m 获取帮助):n //new一个分区 Partition type: p primary (0 primary, 0 extended, 4 free) e extended Select (default p): p //主分区 分区号 (1-4,默认 1):1 //只分一个分区 起始 扇区 (2048-2097151,默认为 2048): 将使用默认值 2048 Last 扇区, +扇区 or +size{K,M,G} (2048-2097151,默认为 2097151): 将使用默认值 2097151 分区 1 已设置为 Linux 类型,大小设为 1023 MiB 命令(输入 m 获取帮助):w //写入修改并退出 The partition table has been altered! Calling ioctl() to re-read partition table. 正在同步磁盘。 您在 /var/spool/mail/root 中有新邮件 [root@hadoop1 home]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 20G 0 disk ├─sda1 8:1 0 1G 0 part /boot ├─sda2 8:2 0 2G 0 part [SWAP] └─sda3 8:3 0 17G 0 part / sdb 8:16 0 1G 0 disk └─sdb1 8:17 0 1023M 0 part //此时分区已经修改 sr0 11:0 1 1024M 0 rom
-
-
格式化:指定基本类型
-
分区命令:
mkfs -t ext4 /dev/sdb1 -
格式化:
[root@hadoop1 home]# mkfs -t ext4 /dev/sdb1 mke2fs 1.42.9 (28-Dec-2013) 文件系统标签= OS type: Linux 块大小=4096 (log=2) 分块大小=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 65536 inodes, 261888 blocks 13094 blocks (5.00%) reserved for the super user 第一个数据块=0 Maximum filesystem blocks=268435456 8 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376 Allocating group tables: 完成 正在写入inode表: 完成 Creating journal (4096 blocks): 完成 Writing superblocks and filesystem accounting information: 完成 您在 /var/spool/mail/root 中有新邮件 [root@hadoop1 home]# lsblk -f NAME FSTYPE LABEL UUID MOUNTPOINT sda ├─sda1 ext4 2b4b1a15-338f-4f48-9f1b-f452554cd50b /boot ├─sda2 swap 7a814b32-ba6d-4ece-8bd4-22616bb801f1 [SWAP] └─sda3 ext4 bd3d6bdf-9bbf-4610-bda0-4dea8e07c746 / sdb └─sdb1 ext4 16cb3e86-1eeb-4098-8dbd-93062a045f81 //格式化完成
-
-
挂载
-
先创建一个/newdisk目录
-
挂载:
mount /dev/sdb1 /newdisk/[root@hadoop1 /]# mkdir newdisk [root@hadoop1 /]# mount /dev/sdb1 /newdisk/ [root@hadoop1 /]# lsblk -f NAME FSTYPE LABEL UUID MOUNTPOINT sda ├─sda1 ext4 2b4b1a15-338f-4f48-9f1b-f452554cd50b /boot ├─sda2 swap 7a814b32-ba6d-4ece-8bd4-22616bb801f1 [SWAP] └─sda3 ext4 bd3d6bdf-9bbf-4610-bda0-4dea8e07c746 / sdb └─sdb1 ext4 16cb3e86-1eeb-4098-8dbd-93062a045f81 /newdisk //此时已经有了挂载点了 sr0
-
-
卸载设备:
-
umount /dev/sdb1设备名称//先退回根目录 [root@hadoop1 /]# umount /dev/sdb1 [root@hadoop1 /]# lsblk -f NAME FSTYPE LABEL UUID MOUNTPOINT sda ├─sda1 ext4 2b4b1a15-338f-4f48-9f1b-f452554cd50b /boot ├─sda2 swap 7a814b32-ba6d-4ece-8bd4-22616bb801f1 [SWAP] └─sda3 ext4 bd3d6bdf-9bbf-4610-bda0-4dea8e07c746 / sdb └─sdb1 ext4 16cb3e86-1eeb-4098-8dbd-93062a045f81 //此时挂载点已经没有了 sr0 -
umount /newdisk挂载目录
-
-
注意:用命令行挂载重启后会失效
-
永久挂载:通过修改/etc/fstab实现挂载
//vim /etc/fstab
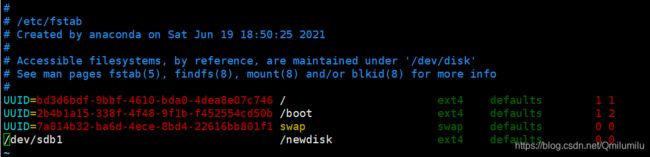
-
添加完成后 执行mount –a 即刻生效
-
再重启后,挂载点依然生效
-
-
-
-
磁盘情况查询
-
查询系统整体磁盘使用情况
-
基本语法:
df -h -
应用实例:
[root@hadoop1 ~]# df -h 文件系统 容量 已用 可用 已用% 挂载点 /dev/sda3 17G 5.5G 11G 35% / devtmpfs 975M 0 975M 0% /dev tmpfs 991M 0 991M 0% /dev/shm tmpfs 991M 11M 981M 2% /run tmpfs 991M 0 991M 0% /sys/fs/cgroup /dev/sdb1 991M 2.6M 922M 1% /newdisk /dev/sda1 976M 134M 776M 15% /boot .host:/ 316G 24G 293G 8% /mnt/hgfs //共享文件夹 tmpfs 199M 8.0K 199M 1% /run/user/42 tmpfs 199M 0 199M 0% /run/user/0
-
-
查询指定目录的磁盘占用情况
-
基本语法:
du -h /目录 -
选项:
- -s 指定目录占用大小汇总
- -h 带计量单位
- -a 含文件
- –max-depth=1 子目录深度
- -c 列出明细的同时,增加汇总值
-
应用案例:
[root@hadoop1 opt]# du -hac --max-depth=1 /opt 4.0K /opt/rh 5.4M /opt/tmp 163M /opt/vmware-tools-distrib 54M /opt/VMwareTools-10.3.10-13959562.tar.gz 222M /opt 222M 总用量
-
-
-
磁盘情况-工作实用指令
-
统计/home文件夹下文件的个数
[root@hadoop1 opt]# ls -l /opt 总用量 55124 drwxr-xr-x. 2 root root 4096 10月 31 2018 rh drwxr-xr-x. 3 root root 4096 6月 26 00:23 tmp -rw-r--r--. 1 root root 56431201 6月 13 2019 VMwareTools-10.3.10-13959562.tar.gz drwxr-xr-x. 9 root root 4096 6月 13 2019 vmware-tools-distrib 您在 /var/spool/mail/root 中有新邮件 [root@hadoop1 opt]# ls -l /opt | grep "^-" //"^-":过滤出以-开头的,即文件 -rw-r--r--. 1 root root 56431201 6月 13 2019 VMwareTools-10.3.10-13959562.tar.gz [root@hadoop1 opt]# ls -l /opt | grep "^-" | wc -l //wc:统计个数 1 -
统计/home文件夹下目录的个数
[root@hadoop1 opt]# ls -l /opt | grep "^d" | wc -l 3 -
统计/home文件夹下文件的个数,包括子文件夹里的
[root@hadoop1 /]# ls -lR /home | grep "^-" | wc -l //R:代表递归 13 -
统计文件夹下目录的个数,包括子文件夹里的
[root@hadoop1 /]# ls -lR /home | grep "^d" | wc -l 13 -
以树状显示目录结构
[root@hadoop1 /]# tree /home //未安装tree bash: tree: 未找到命令... 您在 /var/spool/mail/root 中有新邮件 [root@hadoop1 /]# yum install tree //安装 [root@hadoop1 /]# tree /home /home ├── aaa.txt ├── a.txt ├── bbb │ └── aaa.txt ├── ccc.txt ├── cool ├── crontabtest.txt ├── c.txt ├── fox │ └── ok.txt ├── homeinfo.txt ├── jack ├── mya.tar.gz ├── mycal ├── myhome.zip ├── myshell.sh └── tom ├── a.txt ├── \345\205\254\345\205\261 ├── \346\250\241\346\235\277 ├── \350\247\206\351\242\221 ├── \345\233\276\347\211\207 ├── \346\226\207\346\241\243 ├── \344\270\213\350\275\275 ├── \351\237\263\344\271\220 └── \346\241\214\351\235\242 13 directories, 13 files
-
2.17 网络配置
-
Linux网络配置原理图
NAT网络配置:

-
查看网络IP和网关
-
查看虚拟网络编辑器、修改ip地址、查看网关
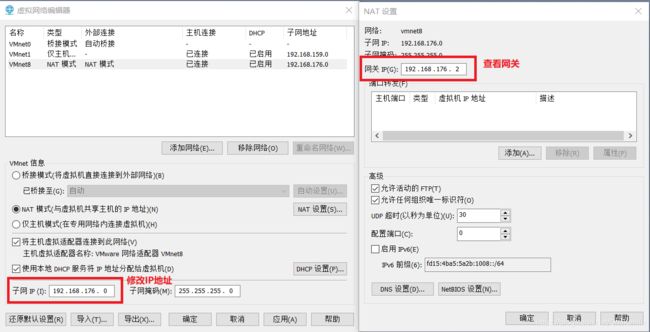
-
查看windows环境的中VMnet8网络配置 (
ipconfig指令)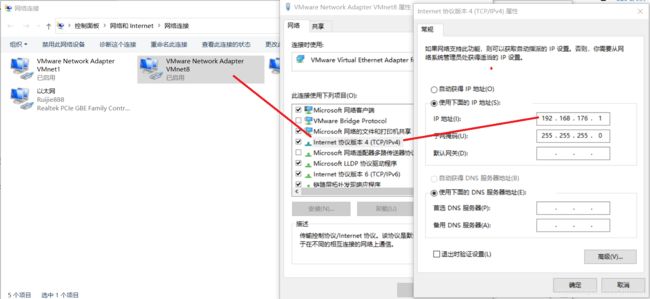
-
查看Linux环境的中网络配置 (
ifconfig指令)
-
-
ping 测试主机之间网络连通性
-
基本语法:
ping 目的主机(功能描述:测试当前服务器是否可以连接目的主机) -
应用实例:
//测试当前服务器是否可以连接百度 [root@hadoop1 ~]# ping baidu.com PING baidu.com (220.181.38.148) 56(84) bytes of data. 64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=1 ttl=128 time=34.6 ms 64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=2 ttl=128 time=34.3 ms
-
-
linux网络环境配置
-
第一种方法(自动获取):
-
登陆后,通过界面的来设置自动获取ip
-
注意:linux启动后会自动获取IP,缺点是每次自动获取的ip地址可能不一样
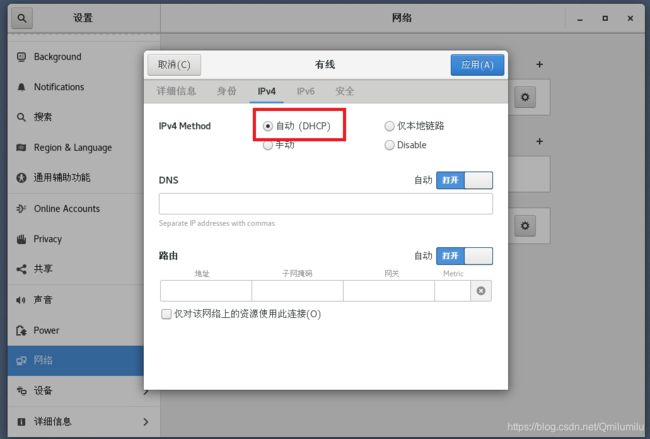
-
-
⭐第二种方法==(指定固定的ip)服务器一定是要固定IP==
-
直接修改配置文件来指定IP,并可以连接到外网(程序员推荐)
-
编辑 vi /etc/sysconfig/network-scripts/ifcfg-ens33
(这里的eth33就是指本机的网络设备-网卡)

-
将ip地址配置的静态的, ip地址为192.168.184.130(自定义)
-
ens33文件原内容:
TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="dhcp" #此时为动态配置 DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" UUID="58116b51-1bee-4c20-a204-9ceff1463a6c" DEVICE="ens33" ONBOOT="yes" -
修改后的内容:
TYPE="Ethernet" PROXY_METHOD="none" BROWSER_ONLY="no" BOOTPROTO="static" #修改为静态配置 DEFROUTE="yes" IPV4_FAILURE_FATAL="no" IPV6INIT="yes" IPV6_AUTOCONF="yes" IPV6_DEFROUTE="yes" IPV6_FAILURE_FATAL="no" IPV6_ADDR_GEN_MODE="stable-privacy" NAME="ens33" UUID="58116b51-1bee-4c20-a204-9ceff1463a6c" DEVICE="ens33" ONBOOT="yes" #IP地址 IPADDR=192.168.200.130 #网关 GATEWAY=192.168.200.2 #域名解析器 DNS1=192.168.200.2 -
同时在虚拟机的虚拟网络编辑中将网关修改

-
重启网络服务或者重启系统生效
- service network restart
- reboot
-
此时查看Windows vmnet8及Linux网络,都已经修改
[root@hadoop1 ~]# ifconfig ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.200.130 netmask 255.255.255.0 broadcast 192.168.200.255 inet6 fe80::4a2e:89d3:6657:289e prefixlen 64 scopeid 0x20<link> ether 00:0c:29:71:de:2e txqueuelen 1000 (Ethernet) RX packets 662 bytes 808149 (789.2 KiB)
-
-
-
-
设置主机名和Hosts映射
-
设置主机名:
- 为了方便记忆,可以给Linux系统设置主机名,也可以根据需要修改主机名
- 指令
hostname:查看主机名 - 修改文件在
/etc/hostname指定 - 修改后重启生效
-
设置host映射
-
目的:使用主机名来ping主机
-
配置映射关系的文件所在位置:
-
Windows:“C:\Windows\System32\drivers\etc\hosts”(修改此处即域名劫持)
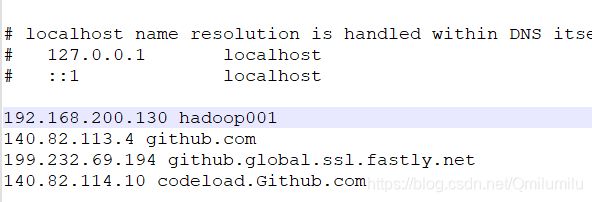
此时在命令行中已经可以使用主机名ping通了

-
Linux:/etc/hosts
[root@hadoop001 ~]# vim /etc/hosts [root@hadoop001 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.200.1 DESKTOP-55E400K [root@hadoop001 ~]# ping DESKTOP-55E400K //关闭防火墙后,可以ping通 PING DESKTOP-55E400K (192.168.200.1) 56(84) bytes of data. 64 bytes from DESKTOP-55E400K (192.168.200.1): icmp_seq=30 ttl=64 time=0.619 ms 64 bytes from DESKTOP-55E400K (192.168.200.1): icmp_seq=31 ttl=64 time=0.562 ms 64 bytes from DESKTOP-55E400K (192.168.200.1): icmp_seq=32 ttl=64 time=0.439 ms 64 bytes from DESKTOP-55E400K (192.168.200.1): icmp_seq=33 ttl=64 time=0.551 ms 64 bytes from DESKTOP-55E400K (192.168.200.1): icmp_seq=34 ttl=64 time=0.497 ms 64 bytes from DESKTOP-55E400K (192.168.200.1): icmp_seq=35 ttl=64 time=0.390 ms 64 bytes from DESKTOP-55E400K (192.168.200.1): icmp_seq=36 ttl=64 time=1.18 ms
-
-
-
主机名解析过程分析
-
Hosts:一个文本文件,用来记录**IP和Hostname(主机名)**之间的映射
-
DNS:Domain Name System域名系统,是互联网上作为域名和IP地址相互映射的分布式文件数据库
-
应用实例:
-
先查看浏览器缓存中,有没有该域名的IP解析地址
-
若没有,检查DNS解析器缓存中,有没有该域名的IP解析地址
- 一般来说,当电脑第一次成功访问一个网站后,在一定时间段内,浏览器或者操作系统会缓存它的IP地址(DNS解析记录)
- 如在cmd窗口输入指令:
ipconfig /displaydns//DNS域名解析缓存ipconfig /flushdns//手动清理DNS解析缓存
-
若没有,检查系统中hosts文件中,有没有该域名的IP解析地址
-
若没有,则到域名服务器DNS进行解析
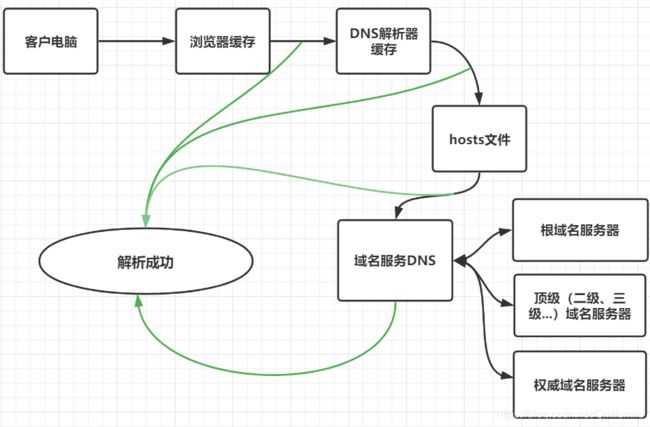
-
-
-
2.18 进程管理
-
基本介绍:
- 在LINUX中,每个执行的程序(代码)都称为一个进程(动态概念)
- 每一个进程都分配一个ID号
- 每一个进程,都会对应一个父进程,而这个父进程可以复制多个子进程。例如www服务器
- 每个进程都可能以两种方式存在的:前台与后台
- 前台进程:就是用户目前的屏幕上可以进行操作的
- 后台进程:则是实际在操作,但由于屏幕上无法看到的进程,通常使用后台方式执行
- 一般系统的服务都是以后台进程的方式存在,而且都会常驻在系统中。直到关机才才结束
-
显示系统执行的进程
-
基本介绍:
ps命令是用来查看目前系统中,有哪些正在执行,以及它们执行的状况。可以不加任何参数
-
常用选项:
选项 描述 -a 显示当前终端的所有进程 -u 以用户的格式显示进程信息 -x 显示后台进程运行的参数 -
显示的信息选项:
-
System V展示风格
-
USER:用户名称
-
PID:进程号
-
%CPU:进程占用CPU的百分比
-
%MEM:进程占用物理内存的百分比
-
VSZ:进程占用的虚拟内存大小(单位: KB)
-
RSS:进程占用的物理内存大小(单位: KB)
-
TT:终端名称,缩写
-
STAT:进程状态,其中S-睡眠, s-表示该进程是会话的先导进程, N-表示进程拥有比普通优先级更低的优先级, R-正在运行, D-短期等待, Z-僵死进程, T-被跟踪或者被停止等等
-
STARTED:进程的启动时间
-
TIME: CPU时间,即进程使用CPU的总时间
-
COMMAND:启动进程所用的命令和参数,如果过长会被截断显示
-
-
实例一:查看当前系统有没有目标进程
-
语法:
ps –aux|grep xxx -
应用实例:
[root@hadoop001 ~]# ps -aux | grep "sshd" root 7753 0.0 0.2 112756 4320 ? Ss 16:31 0:00 /usr/sbin/sshd -D root 8622 0.0 0.2 160848 5608 ? Ss 16:35 0:00 sshd: root@pts/0 root 12067 0.0 0.2 156636 5484 ? Ss 18:04 0:00 sshd: root@pts/1 root 12796 0.0 0.0 112728 988 pts/1 S+ 18:24 0:00 grep --color=auto sshd
-
-
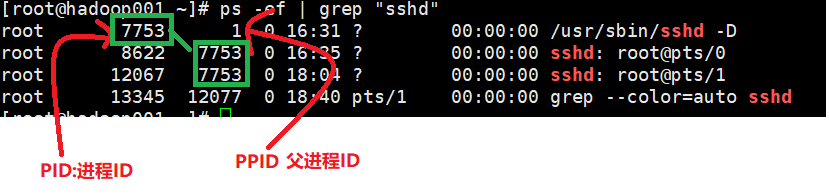
实例二:以全格式显示当前所有的进程,查看进程的父进程
-
语法:
ps –ef|grep xxx -
-e 显示所有进程 、-f 全格式
-
应用实例:
-
-
-
终止进程kill和killall
-
介绍:
若是某个进程执行一半需要停止时,或是已消了很大的系统资源时,此时可以考虑停止该进程。使用kill命令来完成此项任务
-
基本语法:
kill [选项] 进程号(功能描述:通过进程号杀死进程)killall 进程名称(功能描述:通过进程名称杀死进程,也支持通配符,这在系统因负载过大而变得很慢时很有用)
-
常用选项:
-9:表示强迫进程立即停止 -
最佳实践:
-
案例1:踢掉某个非法登录用户

kill 16704 -
案例2: 终止远程登录服务sshd, 在适当时候再次重启sshd服务
[root@hadoop001 ~]# ps -aux | grep sshdroot 7753 0.0 0.2 112756 4356 ? Ss 17:18 0:00 /usr/sbin/sshd -Droot 8622 0.0 0.2 160848 5608 ? Ss 17:22 0:00 sshd: root@pts/0root 12067 0.0 0.2 156636 5484 ? Ss 18:51 0:00 sshd: root@pts/1root 16945 1.0 0.2 156636 5492 ? Ss 20:50 0:00 sshd: root@pts/2root 17005 0.0 0.0 112728 988 pts/2 S+ 20:51 0:00 grep --color=auto sshd [root@hadoop001 ~]# kill 7753 //停掉远程登录服务[root@hadoop001 ~]# ps -aux | grep sshdroot 8622 0.0 0.2 160848 5608 ? Ss 17:22 0:00 sshd: root@pts/0root 12067 0.0 0.2 156636 5484 ? Ss 18:51 0:00 sshd: root@pts/1root 16945 0.2 0.2 156636 5492 ? Ss 20:50 0:00 sshd: root@pts/2root 17147 0.0 0.0 112728 984 pts/2 S+ 20:52 0:00 grep --color=auto sshd//此时其他用户已经登不上来了Connecting to 192.168.200.130:22...Could not connect to '192.168.200.130' (port 22): Connection failed.Type `help' to learn how to use Xshell prompt.[F:\~]$重启服务:
[root@hadoop001 ~]# /bin/systemctl start sshd.service //重启服务[root@hadoop001 ~]# ps -aux | grep sshdroot 8622 0.0 0.2 160848 5608 ? Ss 17:22 0:00 sshd: root@pts/0root 12067 0.0 0.2 156636 5484 ? Ss 18:51 0:00 sshd: root@pts/1root 16945 0.1 0.2 156636 5492 ? Ss 20:50 0:00 sshd: root@pts/2root 17196 0.4 0.2 112756 4316 ? Ss 20:54 0:00 /usr/sbin/sshd -Droot 17198 0.0 0.0 112728 988 pts/2 S+ 20:54 0:00 grep --color=auto sshd -
案例3: 终止多个gedit 编辑器
killall gedit -
案例4:强制杀掉一个终端
kill -9 bash对应的进程号
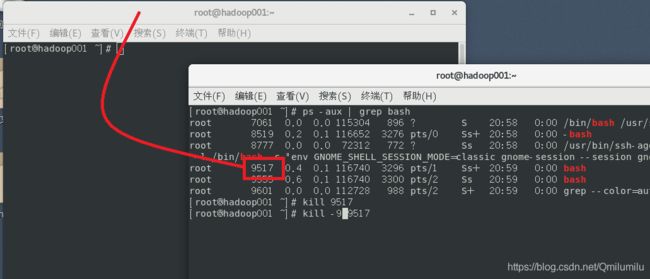
-
-
-
查看进程树pstree
-
基本语法:
pstree [选项],可以更加直观的来看进程信息[root@hadoop001 ~]# pstreesystemd─┬─ModemManager───2*[{ModemManager}] ├─NetworkManager───2*[{NetworkManager}] ├─VGAuthService ├─2*[abrt-watch-log] ├─abrtd ├─accounts-daemon───2*[{accounts-daemon}] ├─alsactl ├─at-spi-bus-laun─┬─dbus-daemon───{dbus-daemon} │ └─3*[{at-spi-bus-laun}] ├─at-spi2-registr───2*[{at-spi2-registr}] ├─atd ├─auditd─┬─audispd─┬─sedispatch... -
常用选项:
- -p :显示进程的PID
- -u :显示进程的所属用户
-
应用实例:
-
案例1:请你树状的形式显示进程的pid
[root@hadoop001 ~]# pstree -p systemd(1)─┬─ModemManager(6931)─┬─{ModemManager}(6978) │ └─{ModemManager}(7001) ├─NetworkManager(7186)─┬─{NetworkManager}(7285) │ └─{NetworkManager}(7298) ├─VGAuthService(7006) ├─abrt-watch-log(7009) ├─abrt-watch-log(7013) ├─abrtd(7008) ├─accounts-daemon(6927)─┬─{accounts-daemon}(6973) -
案例2: 请你树状的形式进程的用户id
[root@hadoop001 ~]# pstree -u systemd─┬─ModemManager───2*[{ModemManager}] ├─NetworkManager───2*[{NetworkManager}] ├─VGAuthService ├─2*[abrt-watch-log] ├─abrtd ├─accounts-daemon───2*[{accounts-daemon}] ├─alsactl ├─at-spi-bus-laun─┬─dbus-daemon───{dbus-daemon}
-
-
2.19 服务管理
-
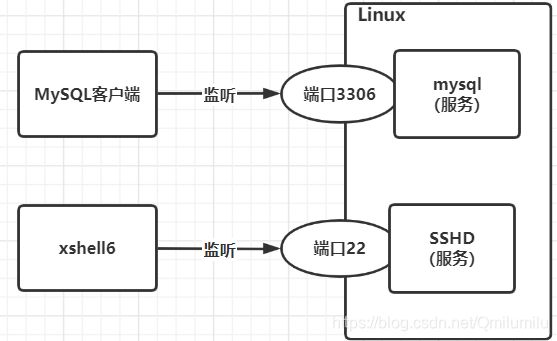
介绍:
服务(service) 本质就是进程,但是是运行在后台的,通常都会监听某个端口,等待其它程序的请求,比如(mysql , sshd 防火墙等),因此我们又称为守护进程,是Linux中非常重要的知识点
-
原理图:
后台程序=守护进程=服务
-
service管理指令:
-
service 服务名 [start | stop | restart | reload | status] -
在CentOS7.0后 不再使用service,而是 systemctl
-
CentOS7.0后service管理服务指令有:
-
应用案例:
[root@hadoop001 ~]# service network stop Stopping network (via systemctl): [ 确定 ] [root@hadoop001 ~]# service network start Starting network (via systemctl): [ 确定 ]
-
-
查看服务名:
-
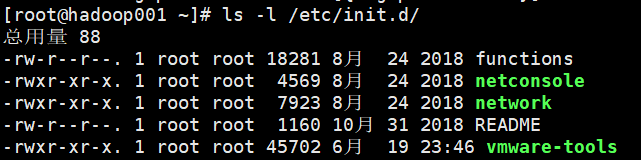
方式1: /etc/init.d/服务名称
-
方式2:使用
setup→ \to →系统服务 就可以看到-
前面带有
*的服务,会随着Linux系统的启动而自启 -
移动光标敲空格,可取消*自启
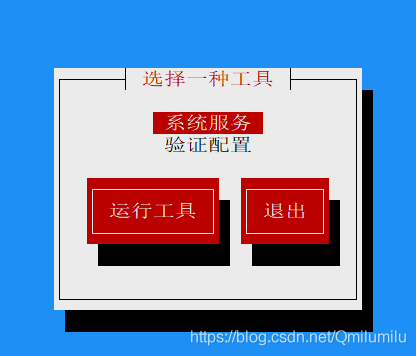
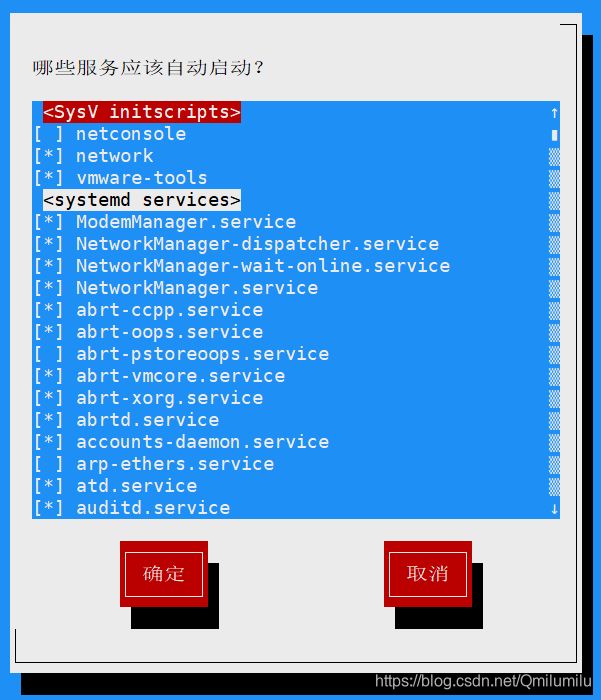
-
-
-
服务的运行级别(runlevel):
-
Linux系统有7种运行级别(runlevel): 常用的是级别3和5
• 运行级别0: 系统停机状态,系统默认运行级别不能设为0,否则不能正常启动
• 运行级别1: 单用户工作状态, root权限,用于系统维护,禁止远程登陆
• 运行级别2: 多用户状态(没有NFS),不支持网络
• 运行级别3: 完全的多用户状态(有NFS),无界面,登陆后进入控制台命令行模式
• 运行级别4: 系统未使用,保留
• 运行级别5: X11控制台,登陆后进入图形GUI模式
• 运行级别6: 系统正常关闭并重启,默认运行级别不能设为6,否则不能正常启动 -
Linux开机流程:
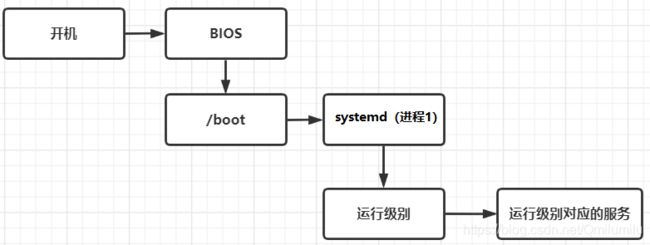
-
-
chkconfig指令
- 介绍:
- 通过chkconfig 命令可以给每个服务的各个运行级别设置自启动/关闭
- chkconfig指令管理的服务在/etc/init.d查看
- 注意:Centos7.0后,很多服务使用systemctl管理
- 基本语法:
- 查看服务:
chkconfig --list | grep xxx - 查看指定的服务:
chkconfig 服务名 --list - 将某个服务,在指定级别打开或关闭:
chkconfig --level 5 服务名 on/off
- 查看服务:
- 介绍:
-
systemctl管理指令(临时效果)
-
基本语法:
systemctl [start | stop | restart | reload | status] 服务名 -
systemctl指令管理服务在/usr/lib/systemd/system 查看
[root@hadoop001 ~]# systemctl status firewalld ● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled) Active: active (running) since 六 2021-07-03 08:38:51 CST; 6min ago Docs: man:firewalld(1) Main PID: 7137 (firewalld) Tasks: 2 CGroup: /system.slice/firewalld.service └─7137 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid 7月 03 08:38:49 hadoop001 systemd[1]: Starting firewalld - dynamic firewall daemon... 7月 03 08:38:51 hadoop001 systemd[1]: Started firewalld - dynamic firewall daemon.
-
-
systemctl设置服务的自启动状态(永久效果)
-
基本语法:
systemctl list-unit-files [| grep 服务名](查看服务开机启动状态)systemctl enable 服务名(设置服务开机自启)systemctl disable 服务名(关闭服务开机自启)systemctl is-enabled 服务名(查询某个服务是否是自启动的)
-
应用案例:
[root@hadoop001 ~]# systemctl list-unit-files | grep firewalld firewalld.service enabled [root@hadoop001 ~]# systemctl is-enabled firewalld enabled [root@hadoop001 ~]# systemctl is-enabled sshd enabled
-
-
防火墙
-
关闭和启用防火墙,会立即生效,但这种方式只是临时生效,当重启系统后,还是会回归以前的服务设置
-
若想让某个服务永久失效,或永久启用,则要设置开机自启systemctl enable|disable 服务名
-
防火墙原理图:
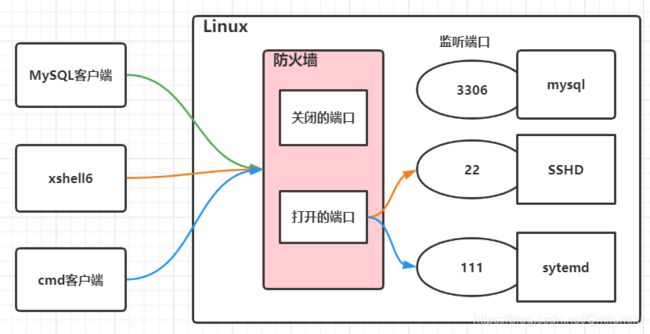
-
测试防火墙的作用:
- 使用netstat指令,查看当前网络状态,看到systemd的端口号为111

-
在cmd中ping 192.168.200.130 111,并不能ping通
-
此时在Linux中关闭防火墙,便可以在cmd中ping通了
-
-
防火墙打开或者关闭指定的端口
-
真正的生产环境,往往需要将防火墙打开,但是外部请求数据包就不能跟服务器监听端口通讯,此时就需要打开指定的端口
-
firewall指令(❗ firewall-cmd中间没空格啊,真的晕眩)
- 打开端口:
firewall-cmd --permanent --add-port=端口号/协议号 - 关闭端口:
firewall-cmd --permanent --remove-port=端口号/协议号 - 重写载入才能生效:
firewall-cmd --reload - 查询端口是否开放:
firewall-cmd --query-port=端口号/协议号
- 打开端口:
-
应用案例:
[root@hadoop001 ~]# firewall-cmd --permanent --add-port=111/tcp success [root@hadoop001 ~]# firewall-cmd --reload success [root@hadoop001 ~]# firewall-cmd --query-port=111/tcp yes //关闭111端口 [root@hadoop001 ~]# firewall-cmd --permanent --remove-port=111/tcp success [root@hadoop001 ~]# firewall-cmd --query-port=111/tcp yes //不reload不会生效 [root@hadoop001 ~]# firewall-cmd --reload success [root@hadoop001 ~]# firewall-cmd --query-port=111/tcp no //已关闭
-
2.20 动态监控进程
-
介绍:
- top与ps命令很相似。它们都用来显示正在执行的进程
- Top与ps最大的不同之处,在于top会动态更新进程的运行情况
-
基本语法:
top [选项] -
常用选项:
选项 功能 -d 秒数 指定top指令每隔几秒更新,默认是3秒 -i 使top不显示任何闲置或僵死(zombie)的进程 -p 通过指定监控进程ID来仅仅监控某个进程的状态 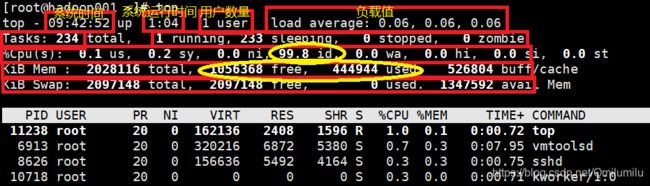
-
交互操作的说明:
操作 功能 P 以CPU使用率排序(默认) M 以内存使用率排序 N 以PID排序 q 退出top -
监控指定的用户进程:
- 输入top
- 输入u,再输入指定进程的用户名
-
终止指定的进程:
- 输入top
- 输入k,再输入指定进程的PID
2.21 监控网络状态
-
基本语法:
netstat [选项] -
选项说明
-
-an 按一定顺序排列输出
-
-p 显示哪个进程在调用
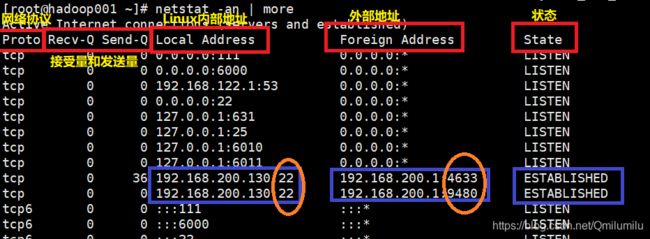
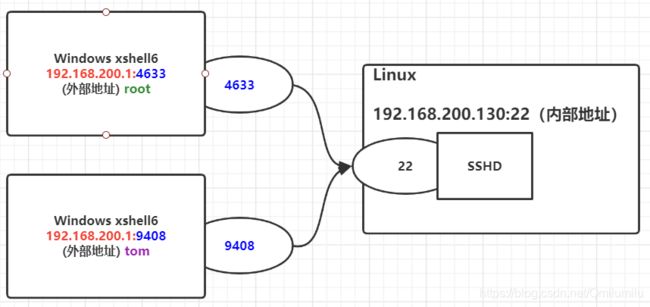
==注意:==如果此时tom用户logout,但9408端口的链接并不会立马断开,而是进入TIME_WAIT状态(TCP协议的机制,担心网络延时原因,故会超时等待一分钟)
-
-
应用案例
//请查看服务名为 sshd 的服务的信息 [root@hadoop001 ~]# netstat -anp | sshd
2.23 rpm管理
-
介绍:
- 一种用于互联网下载包的打包及安装工具,它包含在某些Linux分发版中
- 它生成具有**.RPM**扩展名的文件
- RPM是RedHat Package Manager(RedHat软件包管理工具)的缩写,类似windows setup.exe,这一文件格式名称虽然打上了RedHat的标志,但理念是通用的
- Linux的分发版本都有采用(suse,redhat, centos 等等),可以算是公认的行业标准了
-
rpm包的简单查询指令
-
基本语法:
查询已安装的rpm列表:
rpm –qa | grep xx -
应用案例:
[root@hadoop001 ~]# rpm -qa | grep firefox firefox-60.2.2-1.el7.centos.x86_64 //名称:firefox //版本号: 60.2.2-1 //适用操作系统: l7.centos.x86_64 //表示centos6.x的64位系统 //如果是i686、 i386表示32位系统, noarch表示通用
-
-
rpm包的其它查询指令
rpm -qa:查询所安装的所有rpm软件包rpm -qa | more:分页显示rpm -qa | grep xxx:过滤查找rpm -q 软件包名:查询软件包是否安装rpm -qi 软件包名:查询软件包信息rpm -ql 软件包名:查询安装到哪里了,包含哪些文件rpm -qf 文件全路径名:查询某个文件在之前安装时所属的软件
-
卸载rpm包
- 基本语法:
rpm -e RPM包的名称 - 细节讨论:
- 如果其它软件包依赖于您要卸载的软件包,卸载时则会产生错误信息
如: rpm -e foo
removing these packages would break dependencies:foo is needed by bar-1.0-1 - 如果我们就是要删除 foo这个rpm 包,可以增加参数
--nodeps,就可以强制删除,但是一般不推荐这样做, 因为依赖于该软件包的程序可能无法运行
如: rpm -e --nodeps foo
- 如果其它软件包依赖于您要卸载的软件包,卸载时则会产生错误信息
- 基本语法:
-
安装rpm包
- 基本语法:
rpm -ivh RPM包全路径名称 - 参数说明:
-i:install 安装-v:verbose 提示-h:hash 进度条
- 基本语法:
2.24 yum
-
介绍:
- Yum 是一个Shell前端软件包管理器
- 基于RPM包管理,能够从指定的服务器自动下载RPM包并且安装
- 可以自动处理依赖性关系, 并且一次安装所有依赖的软件包
-
yum原理图:
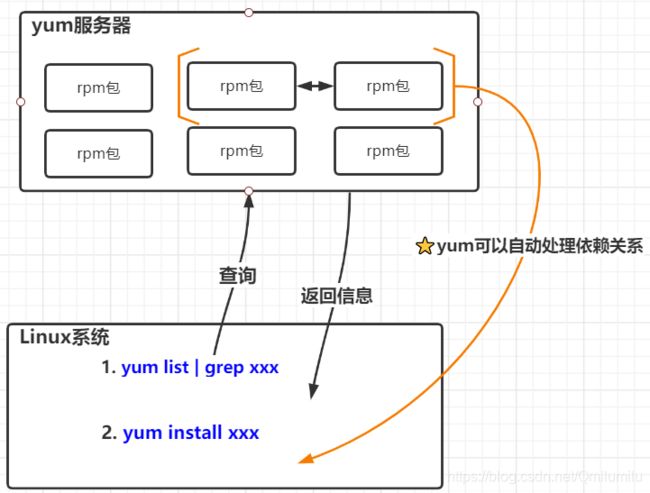
-
yum的基本指令:
- 查询yum服务器是否有需要安装的软件:
yum list|grep xxx - 安装指定的yum包:
yum install xxx
- 查询yum服务器是否有需要安装的软件: