row_number() over(partition by xx order by xx desc)
一、目的
主要用于根据某个字段对数据分组去重
二、demo
1. 有数据表 duplicate_test 如下
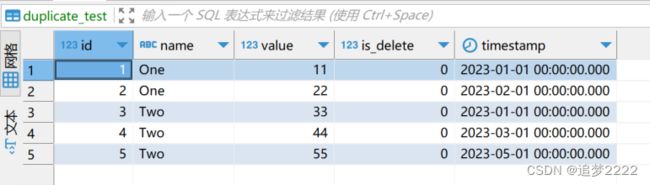
2. 使用 name 作为 key 对数据分组,并增加一列标识序号 idx(根据 时间戳倒序标记序号)
select
name,
row_number() over(partition by name order by timestamp desc) as idx,
value,
timestamp
from duplicate_test
where is_delete = 0运行结果如下

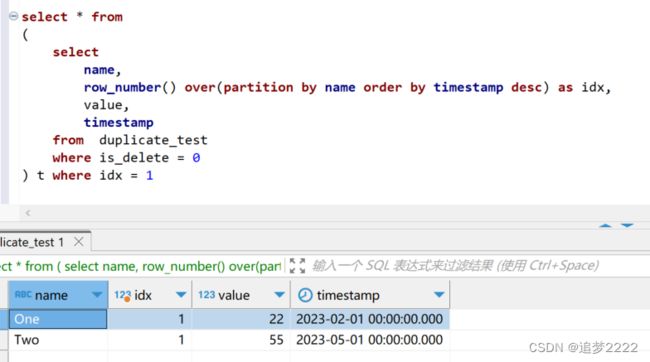
3. 根据 name 作为 key,取每个分组里的第一条数据,从而实现 去重
select * from
(
select
name,
row_number() over(partition by name order by timestamp desc) as idx,
value,
timestamp
from duplicate_test
where is_delete = 0
) t where idx = 1运行结果如下:
三、解释
以上sql 中只有一句核心代码:
row_number() over(partition by name order by timestamp desc) as idx
新增一列序号列 row_number(),根据 name 分组,每个分组里根据 timestamp 倒序排序,序号从 1 开始,起个别名 idx
四、sql 测试源码,数据库是 postgresql
-- 建表
create table duplicate_test (
id bigserial NOT NULL,
name varchar(50) NULL,
value int2 NULL,
is_delete int2 NOT NULL DEFAULT 0,
timestamp timestamp(6) NULL
);
-- 插入数据
insert into duplicate_test
(name, value, is_delete, timestamp)
VALUES('One', 11, 0, '2023-01-01 00:00:00');
insert into duplicate_test
(name, value, is_delete, timestamp)
VALUES('One', 22, 0, '2023-02-01 00:00:00');
insert into duplicate_test
(name, value, is_delete, timestamp)
VALUES('Two', 33, 0, '2023-01-01 00:00:00');
insert into duplicate_test
(name, value, is_delete, timestamp)
VALUES('Two', 44, 0, '2023-03-01 00:00:00');
insert into duplicate_test
(name, value, is_delete, timestamp)
VALUES('Two', 55, 0, '2023-05-01 00:00:00');
-- 分组排序
select
name,
row_number() over(partition by name order by timestamp desc) as idx,
value,
timestamp
from duplicate_test
where is_delete = 0
-- 取每个组里的 时间戳最新的数据
select name, value from
(
select
name,
row_number() over(partition by name order by timestamp desc) as idx,
value,
timestamp
from duplicate_test
where is_delete = 0
) t where idx = 1
五、参考链接
Hive(十一)--数据去重及row_number()_hive row_number_zxfBdd的博客-CSDN博客
sql - 使用 ROW_NUMBER 和 PARTITION BY 获取第一行和最后一行 - SegmentFault 思否