大数据笔试真题集锦---第五章:Hive面试题
第五章目录

第五章 Hive
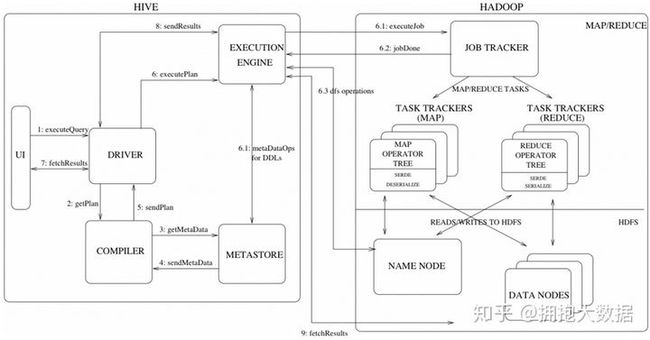
5.1 Hive 运行原理(源码级)
- 用户提交查询等任务给Driver。
- Antlr解析器将SQL转化为抽象语法树AST Tree
- 遍历AST Tree,抽出基本的查询单元QueryBlock
- 遍历QueryBlock,翻译为执行操作树OperatorTree
- 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量
- 遍历OperatorTree,翻译为MapReduce任务
- 物理层优化器进行MapReduce任务的变换,生成最终的执行计划
- 执行计划,返回结果
5.2 Hive转化join为MR的原理
5.2.1 reduce端join
map端读取两个表,为两个表的数据分别打上标签tag,发送数据
reduce端根据分区分组规则拿到的数据时key相同的数据,再根据标签tag进行相同key的不同value的join操作,完成实际的连接。
5.2.2 map端join
将小表复制多份存放在每个map task的内存中,然后只扫描大表,对大表中key在小表中存在时,进行一个join拼接操作。
将小表复制的对象方法为DistributedCache.addCacheFile,要使用时再使用相应的提取文件目录的方法,并用标准IO获取到数据。
5.2.3 semi join
先将参与join的表1的key复制到一个新的表3中,然后把新表复制多份到各个map task中,最后将不在新表3的表2的数据过滤掉,再进行reduce。
5.3 Hive 建表
5.3.1 传统方式建表
#TEMPORARY:临时的 EXTERNAL:外部的
create [TEMPORARY,EXTERNAL] table [if not exist] [db_name.]name(
col_name data_type
...
)
#指定分区字段和类型(字段不在建表语句中)
[PARTITIONED BY (col_name data_type,...)]
#指定分桶字段和数量(字段存在建表语句中)
[
CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)]
INTO num_buckets BUCKETS
]
#指定解析格式
[ROW FORMAT row_format]
#二选一使用hive自带的或自定义OutPutFormat时引入包
STORED AS file_format |
STORED BY *'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]*
#外部表创建时必须指定
[LOCATION hdfs_path]
#指定表的其它属性,这里可以设置压缩格式
[TBLPROPERTIES (property_name=property_value, ...)]row_format
#DELIMITED 与 SERDE 方式二选一指定使用 hive自带的解析方式或自定义解析
DELIMITED
[FIELDS TERMINATED BY char [ESCAPED BY char]]
[COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char]
[LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]数据类型
TINYINT | SMALLINT | INT | BIGINT | BOOLEAN | FLOAT | DOUBLE | DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later) | STRING | BINARY -- (Note: Available in Hive 0.8.0 and later) | TIMESTAMP -- (Note: Available in Hive 0.8.0 and later) | DECIMAL -- (Note: Available in Hive 0.11.0 and later) | DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later) | DATE -- (Note: Available in Hive 0.12.0 and later) | VARCHAR -- (Note: Available in Hive 0.12.0 and later) | CHAR -- (Note: Available in Hive 0.13.0 and later)
ARRAY < data_type >
MAP < primitive_type, data_type >
STRUCT < col_name : data_type [COMMENT col_comment], ...>
5.3.2 CTAS查询建表
CREATE [TEMPORARY,EXTERNAL] TABLE if not existname
[ROW FORMAT row_format]
[STORED AS file_format]
AS
select_statement
缺点:所有数据类型默认最大范围
5.3.3 Like建表
CREATE TABLE t1 LIKE t2
5.4 存储格式和压缩格式
一般选择ORC+bzip/gzip作为数据源的存储,选择则ORC+Snappy作为中间数据的存储
分区表单文件不大可以采用gzip压缩,桶表需要用bzip或lzo支持分片的方式压缩
设置压缩
建表时指定"stored as orc tblproperties ("orc.compress"="gzip")"
设置 set hive.exec.compress.intermediate=true 开启中间数据压缩,然后设置 mapred.map.output.compression.codec 指定中间数据的压缩方式
设置 set hive.exec.compress.output=true 开启输出文件压缩,然后设置 mapred.output.compression.codec 指定输出文件的压缩方式。
5.5 内部表和外部表
hive外部表是使用external关键字并指定一个hdfs目录创建的表。
hive内部表在创建时会在对应hive目录下创建相应的文件夹,外部表则以指定文件夹为数据源创建表。
hive内部表在删除时会将整个文件夹一并删除,外部表则只会删除元数据。
5.6 分区表和分桶表
5.6.1 分区表
将数据按照分区字段拆分存储的表,在hdfs中以文件夹的形式分别存放不同分区的数据,可以避免全表查询,提高查询效率。
5.6.2 动态分区
hive通过设置hive.exec.dynamici.partition=true开启动态分区。
可以在插入数据时根据表中某字段值决定分区,当分区字段完全由变量决定时称为动态分区,若有常量限制则称为混合分区,若完全由常量决定分区时称为静态分区。
5.6.3 分桶表
根据分桶字段hash值分组拆分数据的表,在hdfs中表现为将单个的数据文件拆分为多个文件。
5.6.4 总结
分区字段的每个值都对应一个文件夹和一个分区文件,而分桶字段则是多个值对应一个桶文件。
如果同时使用分区和分桶,则会先按照分区划分文件,再对每个文件按照分桶进行拆分。
5.7 行转列和列转行
行转列(split + explode + laterview)列转行 ( concat_ws + collect_list/set )
5.8 Hive时间函数
from_unixtime(bigint,string) => string 将10位的unix时间戳转为指定格式(默认为yyyy-MM-dd HH:mm:ss)
unix_timestamp(string date,string regex)=> bigint 将指定格式的日期字符串转为10位时间戳
to_date(string date) => string 把标准格式的日期字符串转为yyyy-MM-dd
month(string date) => int 把标准格式的日期字符串转为MM
weekofyear(string date) => int 返回当前周数
quarter(string date) => int 返回当前季度,仅限1.3以上版本,下面trunc限1.2以上版本
trunc(string date,string regex) => string 返回指定日期的起点时间,如trunc('2017-08-10','MM')返回当月第一天,'YYYY'返回当年第一天
current_date() => string 返回yyyy-MM-dd
date_add(string date,int) => string
date_sub(string date,int) => string
datediff(string date,string date) => string 日期比较函数,仅支持标准日期格式或标准格式
更多函数: https://www.cnblogs.com/MOBIN/p/5618747.html
时间戳
不支持13位的毫秒,可以用cast(ct/1000 as bigint)进行转换。
截断机制
标准格式:yyyy-MM-dd HH:mm:ss
不同的函数内部有各自的regex,基于标准格式截断。
如:month()函数内部regex为'yyyy-MM',识别时截取字符串的前7位比较,符合格式就识别成功,与后续字符串无关,包括内容!
推断依据
month('2017-09-08 14:15') 可以识别月份为09 month('2017-09-08 1415') 也可以识别 month('2017-0908 14:15') 无法识别,返回结果为null month('2017') 无法识别,结果为null data_add('2017-09-10 23:20:30',3) 截断格式'yyyy-MM-dd',返回结果为'2017-09-13',丢失了时间精度。
5.9 Hive 排名函数
row_number 不并列不跳过: 1 2 3 4dense_rank 并列不跳过: 1 1 2 3rank 并列跳过: 1 1 3 4
5.10 Hive 分析函数:Ntile
效果:排序并分桶
ntile(3) over(partition by A order by B)
=> {1,2,3}->1,{4,5,6}->2,{7,8,9}->3可用于取前50%数据统计、取中间三分之一统计等需求。
5.11 Hive 拉链表更新
- 更新过期时间:update TABLE SET FIELD = ? where FIELD2 IN (select ... 相当于where子查询)
- 将旧数据的过期时间更新为当前时间,然后插入新数据并设置新数据的过期时间为一个最大值。
5.12 Hive 排序
5.12.1 order by
需要加载所有数据到reduce中排序,排序方法可能是冒泡、快排、归并,无论如何都要加载所有数据
5.12.2 order by limit
创建一个大小为limit的缓存数组,采用插入法进行排序,把每行数与数组内的数比较,大的话就插入,每插入一个数都有一个数被挤出去,保证每次比较的次数都只有limit次
因此严格模式允许order by limit,虽然比较的数多,但是每次比较的资源消耗很少。
5.12.3 sort by
局部排序,最终生成的每个文件都有序但不能保证全局有序
5.12.4 sort by limit
相当于sort by + order by limit,先局部排序取TopN,然后读入多个TopN结果再全局排序取TopN。
5.13 Hive 调优
减少distinct:使用distinct容易造成数据倾斜问题,使用group by的子查询代替它。
map任务数量优化:
实际业务中往往存在大量的分区表,每个分区表都实际存储一定量的文件,其中必然有些分区的数据量很少。正常读取时往往有多少个文件就创建多少个map,此时可以通过设置一些参数,让sql语句在执行前先合并表文件。 -参数: mapred.min.split.size.per.node = {设置一个节点中分片至少的大小}byte mapred.min.split.size.per.rack= {设置一个交换机中分片至少的大小}byte mapred.max.split.size = {设置分片的最大大小}byte hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat 设置hive先合并文件再执行 -效果: 假设我全部设置为100000000(相当于100M),经过配置后,hive会首先合并文件,切分成各种100M,最后再把剩下来的各个节点上的散碎数据合并到一起再生成几个分片。 还有一种情况,当一个map任务中处理数据量很大时(大小很小,但是条数很多),可以采用分桶法,先用一个查询语句把该表数据查出来分桶写入,再使用这个分桶表。相当于增加map任务数量,增加并行度。
并行度优化: 1.手动设置reduce数量 mapred.reduce.tasks 2.避免全局的聚合函数,使用聚合函数尽量要分组 3.避免全局的order by,有时候全局排序很难避免,但可以根据topN需求,再各个分区中只留下N个值,再进行全局排序。 4.避免笛卡尔积 5.设置mapTask分片大小
小文件问题: 1.避免产生小文件:少用动态分区、根据需求使用reduce 2.使用Sequencefile作为表存储格式,不要用textfile,在一定程度上可以减少小文件 3.使用hadoop archive命令把小文件进行归档 4.重建表,建表时减少reduce数量 5.参数设置: hive.merge.mapfiles = true 设置map端输出合并 hive.merge.mapredfiles = true 设置reduce输出合并 hive.merge.size.per.task = 25610001000 设置合并文件的大小 hive.merge.smallfiles.avgsize=16000000 设置当平均大小小于该值时合并
存储格式 1.使用ORCfile存储,可以显著提高join操作的查询速度 2.使用压缩格式存储,可以显著降低网络IO和存储大小
使用map端join
使用tez作为默认引擎
使用向量化查询:一次执行1024行数据的操作 hive.vectorized.execution.enabled = true; hive.vectorized.execution.reduce.enabled = true;
设置本地模式、并行模式(自动并行非依赖阶段)、严格模式
开启JVM重用
可以考虑开启推测执行(慎重)
总结
减少distinct
设置读取时合并小文件和合理拆分大文件
优化并行度
设置存储格式和压缩格式
设置输出时合并小文件
设置map端JOIN
更换引擎
设置本地模式、并行模式、严格模式
开启JVM重用
开启推测执行
5.14 Hive和Hbase区别
hive是高延迟、结构化和面向分析的逻辑存储组件
hbase则是低延迟、非结构化和面向编程的物理存储组件
hive支持sql语句,通常全表扫描,不推荐删除和更新
hbase不支持sql语句,通常随机读写,增删改查速度很快。
hive是行式结构,hbase则是列式存储。
5.15 其他
5.15.1 用过哪些开窗函数
sum(col) over() : 分组对col累计求和,over() 中的语法如下
count(col) over() : 分组对col累计,over() 中的语法如下
min(col) over() : 分组对col求最小
max(col) over() : 分组求col的最大值
avg(col) over() : 分组求col列的平均值first_value(col) over() : 某分区排序后的第一个col值
last_value(col) over() : 某分区排序后的最后一个col值
lag(col,n,DEFAULT) : 统计往前n行的col值,n可选,默认为1,DEFAULT当往上第n行为NULL时候,
取默认值,如不指定,则为NULL
lead(col,n,DEFAULT) : 统计往后n行的col值,n可选,默认为1,DEFAULT当往下第n行为NULL时候,
取默认值,如不指定,则为NULL
ntile(n) : 用于将分组数据按照顺序切分成n片,返回当前切片值。注意:n必须为int类型。
排名函数:
row_number() over() : 排名函数,不会重复,适合于生成主键或者不并列排名
rank() over() : 排名函数,有并列名次,名次不连续。如:1,1,3
dense_rank() over() : 排名函数,有并列名次,名次连续。如:1,1,2
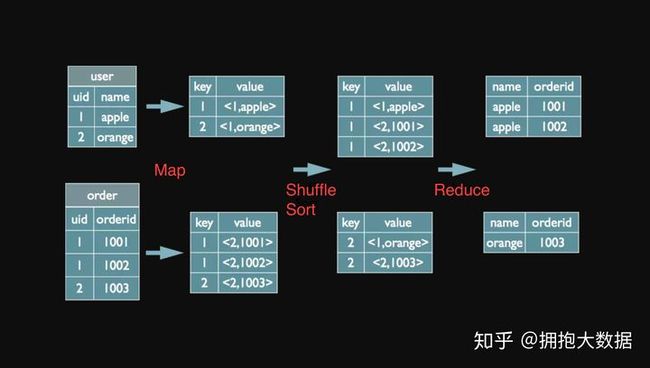
5.15.2 hive中两个表join转换成mr程序,怎么转换的,原理是什么
在map的输出value中为不同表的数据打上tag标记,在reduce阶段根据tag判断数据来源。MapReduce的过程如下
5.15.3 sort by 和order by的区别
order by会对输入做全局排序,因此只有一个Reducer(多个Reducer无法保证全局有序),然而只有一个Reducer,会导致当输入规模较大时,消耗较长的计算时间。这样很可能会超过单个节点的磁盘和内存存储能力导致任务失败。
sort by的数据只能保证在同一个reduce中的数据可以按指定字段排序。使用sort by你可以指定执行的reduce个数(通过set mapred.reduce.tasks=n来指定),对输出的数据再执行归并排序5.15.4 交易表结构为user_id(用户ID),order_id(订单ID),pay_time(付款时间),order_amount(金额)
1. 写sql查询过去一个月付款用户量(提示:用户量需去重)最高的三天分别是哪几天?
2. 写sql查询昨天每个用户最后付款的订单ID及金额
select
date_format(pay_time,'%Y-%m-%d') days ,
count(distinct user_id)
from table
where pay_time>=date_sub(now(),interval 1 month) #过去一个月
group by date_format(pay_time,'%Y-%m-%d')
order by count(distinct user_id) desc
limit 3
思路:求最高的三天,肯定是先排序,后limit. 先求出每天的付款用户量,既然每天,那肯定要按天分组了;按照题目要求过滤条件有:1.过去一个月 2.付款用户(即要排除未付款的用户),另外求用户量需要去重,题目中也有提示,因为存在同一个用户每天有多笔消费记录的情况;返回排在前三的付款用户量及对应的时间(天)
select
a.user_id, a.order_amount
from
(select
user_id, order_amount,
row_number() over(partition by user_id order by pay_time desc) as rank
from table
where date_format(pay_time,"%Y-%m-%d")=date_sub(curdate(),interval 1 day) #昨天
) as
awhere rank=1
5.15.5 用户登录日志表为user_id,log_id,session_id,visit_time
用sql查询近30天每天平均登录用户数量
select
avg(numUser) as averageUsers
from (
select
date_format(visit_time,'%Y-%m-%d') as visit_date,
count(distinct user_id) as numUser
from table
where
datediff(curdate(),visit_date)<=30
group by visit_date
);
5.15.6 Hive的动态分区和静态分区?
静态分区 SP(static partition)
1、静态分区是在编译期间指定的指定分区名
2、支持load和insert两种插入方式
2.1load方式
1)会将分区字段的值全部修改为指定的内容
2)一般是确定该分区内容是一致的时候才会使用
2.2insert方式
1)必须先将数据放在一个没有设置分区的普通表中
2)该方式可以在一个分区内存储一个范围的内容
3)从普通表中选出的字段不能包含分区字段
3、适用于分区数少,分区名可以明确的数据
动态分区 DP(dynamic partition)
1、根据分区字段的实际值,动态进行分区
2、是在sql执行的时候进行分区
3、需要先将动态分区设置打开(set hive.exec.dynamic.partition.mode=nonstrict )
4、只能用insert方式
5、通过普通表选出的字段包含分区字段,分区字段放置在最后,多个分区字段按照分区顺序放置
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断。