数据仓库总结
1.为什么要做数仓建模
数据仓库建模的目标是通过建模的方法更好的组织、存储数据,以便在性能、成本、效率和数据质量之间找到最佳平衡点。
当有了适合业务和基础数据存储环境的模型(良好的数据模型),那么大数据就能获得以下好处:
当有了适合业务和基础数据存储环境的模型(良好的数据模型)
访问性能:能够快速查询所需的数据,减少数据I/O。
数据成本:减少不必要的数据冗余,实现计算结果数据复用,降低大数据系统中的存储成本和计算成本。
使用效率:改善用户应用体验,提高使用数据的效率。
数据质量:改善数据统计口径的不一致性,减少数据计算错误的可能性,提供高质量的、一致的数据访问平台
建模方式有哪些
er建模
在信息系统中,将事务抽象为“实体”(Entity)、“属性”(Property)、“关系”(Relationship)来表示数据关联和事物描述,这种对数据的抽象建模通常被称为ER实体关系模型。
ER模型是数据库设计的理论基础,当前几乎所有的OLTP系统设计都采用ER模型建模的方式
遵从三范式
1NF:原子性。 字段属性不可再分
2NF:唯一性 。一个表只说明一个事物;
3NF:每列都与主键有直接关系,不存在传递依赖。
维度建模
关系模型虽然冗余少,但是在大规模数据,跨表分析统计查询过程中,会造成多表关联,这会大大降低执行效率。所以一般都会采用维度模型建模,把相关各种表整理成两种:事实表和维度表两种。
在维度建模的基础上又可分为三种模型:星型模型、雪花模型、星座模型。
维度建模是从分析决策的需求出发构建模型,为分析需求服务,因此它重点关注用户如何更快速的完成需求分析,同事具有较好的大规模复杂查询的相应能力。其典型的代表是星型模型,以及在一些特殊场景下使用的雪花模型。
维度建模设计分为以下步骤:
- 选择需要进行分析决策的业务过程
- 定义粒度
- 识别维度
- 确认事实
星型模型
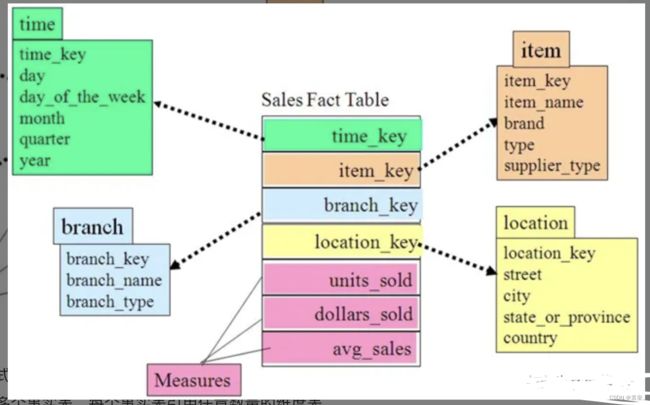
星型模式是维度模型中最简单的形式,也是数据仓库以及数据集市开发中使用最广泛的形式。星型模式由事实表和维度表组成,一个星型模式中可以有一个或多个事实表,每个事实表引用任意数量的维度表。
星型模型与雪花模型的区别主要在于维度的层级,标准的星型模型维度只有一层,而雪花模型可能会涉及多层。
雪花模型
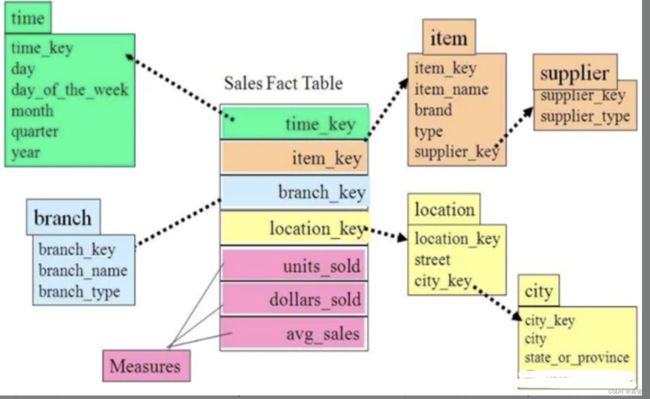
雪花模式是一种多维模型中表的逻辑布局,与星型模式相同,雪花模式也是由事实表和维度表所组成。所谓的“雪花化”就是将星型模型中的维度表进行规范化处理。当所有的维度表完成规范化后,就形成了以事实表为中心的雪花型结构,即雪花模式。、
星座模型
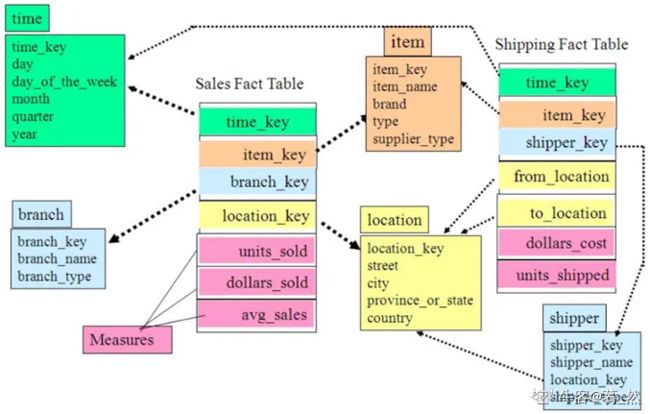
数据仓库由多个主题构成,包含多个事实表,而维表是公共的,可以共享(例如两张事实表共用一些维度表时,就叫做星型模型),这种模式可以看做星型模式的汇集,因而称作星系模式或者事实星座模式。
数据仓库和数据库的区别
数据库和数据仓库都是存储数据的地方,关键是存储数据的区别。数据仓库准确而言是一个逻辑的概念,依托RDBMS作为数据仓库平台。数据库存储的是原始数据,没经过任何加工;而数据仓库是为了满足数据分析需要设计的,对源数据进行了ETL(Extract,Transform,Load)过程,数据抽取工作分抽取、清洗、转换、装载。
数据仓库中的数据主要是为了给企业做决策时分析使用,涉及的主要是对数据的查询,一般情况下不会对数据进行修改,如果数据仓库中的历史数据超过存储期限
为什么要数仓分层
我们先来看下数据仓库为什么要分层,也就是分层的优势。
1)把复杂问题简单化
将复杂的问题分解成多层来完成,每一次只处理简单的任务,方便定位问题。
2)减少重复开发
规范数据分层,通过的中间层数据,能够减少极大的重复计算,增加一次计算结果的复用性。
3)隔离原始数据
不论是数据的异常还是数据敏感度,使真实数据与统计数据解耦开。
各个分层的作用
第一层:
ODS——原始数据层:存放原始数据
第二层:
DWD——数据明细层:对ODS层数据进行清洗、维度退化、脱敏等。
第三层:
DWS——数据汇总层: 对DWD层数据进行一个轻度的汇总。
第四层:
ADS——数据应用层:为各种统计报表提供数据
该层是基于DW层的数据,整合汇总成主题域的服务数据,用于提供后续的业务查询等。
第五层:
DIM——维表层:基于维度建模理念思想,建立整个企业的一致性维度。
维表层主要包含两部分数据:
高基数维度数据:一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维表。数据量可能是个位数或者几千几万