org.dom4j.Element的常用方法举例
org.dom4j.Element的常用方法举例
- 一、以xml进行举例说明
-
- 1、读取xml
-
- (1)、从文件中读取
- (2)、从字符串中读取
- 2、Element的常用方法
-
- (1)、获取节点名称
- (2)、获取节点的值
- (3)、设置节点值
- (4)、增加或修改节点属性
- (5)、获取节点属性的个数
- (6)、获取节点的子节点
- (7)、根据子节点的名字获取子节点
- (8)、添加子节点
- (9)、删除某个子节点
一、以xml进行举例说明
1、读取xml
这里读取文件用“org.dom4j.io.SAXReader”这个类,使用“org.dom4j.Document”接收文档数据。

这是测试使用的xml文件“testXml.xml”:
<FOX version="1.0">
<SIGNONMSGSRSV1>
<SONRS>
<STATUS>
<CODE>0CODE>
<SEVERITY>INFOSEVERITY>
STATUS>
<DTSERVER>2023-05-25 15:43:53DTSERVER>
SONRS>
SIGNONMSGSRSV1>
<SECURITIES_MSGSRSV1>
<QUERYACCEPTTRNRS>
<TRNUID>202305251543515222TRNUID>
<STATUS>
<CODE>0CODE>
<SEVERITY>INFOSEVERITY>
<MESSAGE>处理成功!MESSAGE>
STATUS>
<RSBODY>
<CLIENTREF>202305241745245833CLIENTREF>
<RESULTCODE>2RESULTCODE>
RSBODY>
QUERYACCEPTTRNRS>
SECURITIES_MSGSRSV1>
FOX>
(1)、从文件中读取
读取文件使用“SAXReader”的“read(File file)”方法。

测试:
public static void main(String[] args) {
SAXReader reader = new SAXReader();
Document doc = null;
String xmlFile = "D:\\opt\\jeecg-boot\\upload\\cib\\testXml.xml";
try {
doc = reader.read(new File(xmlFile));
} catch (Exception e) {
e.printStackTrace();
}
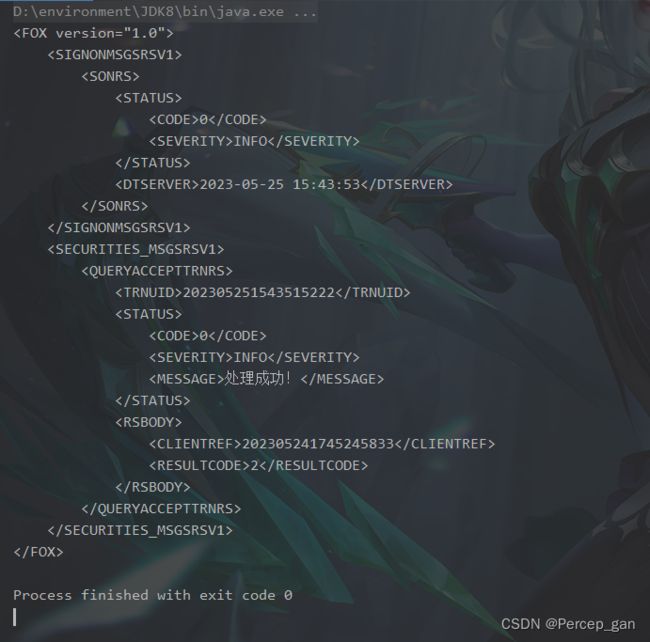
System.out.println(doc.getRootElement().asXML());
}
asXML()方法以xml的形式输出
运行结果如下:

成功读取xml文件中的数据。
(2)、从字符串中读取
使用“read(InputStream in)”方法从字符串中读取
public static void main(String[] args) {
String xmlStr = "0INFO 2023-05-2515:43:53 202305251543515222 0INFO 处理成功! 202305241745245833 2 这是格式化xml字符输出的方法:
/**
* 以xml的形式输出节点
* @param element
*/
private static String printXML(Element element) {
OutputFormat outputFormat = OutputFormat.createPrettyPrint(); //格式化打印xml文件
outputFormat.setEncoding("UTF-8");
StringWriter stringWriter = new StringWriter();
XMLWriter xmlWriter = new XMLWriter(stringWriter, outputFormat);
String xmlPrint = null;
try {
xmlWriter.write(element);
xmlPrint = stringWriter.toString();
System.out.println(xmlPrint);
xmlWriter.close();
} catch (IOException e) {
e.printStackTrace();
}
return xmlPrint;
}
运行结果如下:
我一般就使用这两种方式读取xml文件。
2、Element的常用方法
下面演示“org.dom4j.Element”的常用方法。
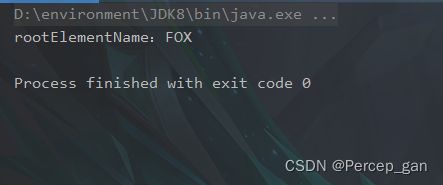
(1)、获取节点名称
使用“getName()”方法获取节点名称,节点名称就是标签名称。
代码如下:
public static void main(String[] args) {
String xmlStr = "0INFO 2023-05-2515:43:53 202305251543515222 0INFO 处理成功! 202305241745245833 2 运行结果如下:
(2)、获取节点的值
代码如下:
public static void main(String[] args) {
String xmlStr = "0INFO 2023-05-2515:43:53 202305251543515222 0INFO 处理成功! 202305241745245833 2 运行结果如下:

节点的值是xml标签中的文本值,子节点(子标签)不属于节点的值。
要想看到效果,可以在字符串中加上:
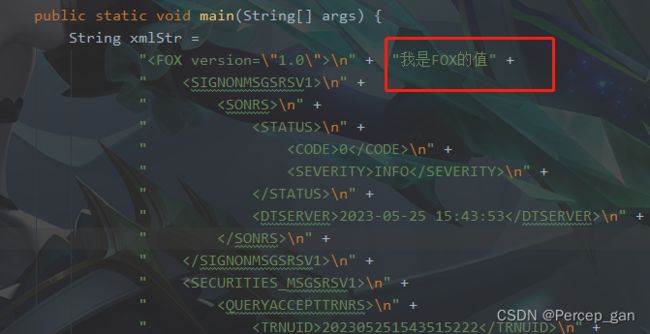
再次运行:
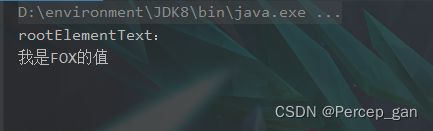
这里会换行是因为有换行符“\n”。
还有一个“getTextTrim()”方法,顾名思义就是获取节点值的同事去掉前后两边的空格、换行符等。
(3)、设置节点值
上面是直接在字符串中增加的节点值,还可以通过Element的方法设置,代码如下:
public static void main(String[] args) {
String xmlStr = "0INFO 2023-05-2515:43:53 202305251543515222 0INFO 处理成功! 202305241745245833 2 运行结果如下:

(4)、增加或修改节点属性
字符串串中的version="1.0"就是“FOX”的属性,现在我要使用“(String name, String value)”方法加上page=“1”的属性,代码如下:
public static void main(String[] args) {
String xmlStr = "0INFO 2023-05-2515:43:53 202305251543515222 0INFO 处理成功! 202305241745245833 2 运行结果如下:

此外,“addAttribute”方法也可以修改已经存在的标签属性,比如我要报“version”的值设置为“2.0”,代码如下:
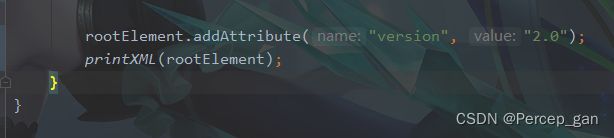
运行结果如下:

(5)、获取节点属性的个数
通过“attributeCount()”方法获取节点属性的个数,代码如下:
public static void main(String[] args) {
String xmlStr = "0INFO 2023-05-2515:43:53 202305251543515222 0INFO 处理成功! 202305241745245833 2 运行结果如下:

“FOX”节点的属性就是只有“version”一个。
(6)、获取节点的子节点
使用“elements()”获取节点所有的子节点,代码如下:
public static void main(String[] args) {
String xmlStr = "0INFO 2023-05-2515:43:53 202305251543515222 0INFO 处理成功! 202305241745245833 2 运行结果如下:

可以看到已经返回所有的子节点。
“elements”还有其他重载方法,比如:“elements(String name)”方法,传入子节点的名称时,会返回子节点中所有该名称的的节点,为了演示效果,在xml字符串新增了一个“SECURITIES_MSGSRSV1”节点(标签),如下图:

代码如下:
//这里补全的代码没有Element类型,自己手动加上
List<Element> SECURITIES_MSGSRSV1List = rootElement.elements("SECURITIES_MSGSRSV1");
for (Element SECURITIES_MSGSRSV1 : SECURITIES_MSGSRSV1List) {
System.out.println("SECURITIES_MSGSRSV1_name:" + SECURITIES_MSGSRSV1.getName() + ",SECURITIES_MSGSRSV1_text:" + SECURITIES_MSGSRSV1.getText());
}
运行结果如下:
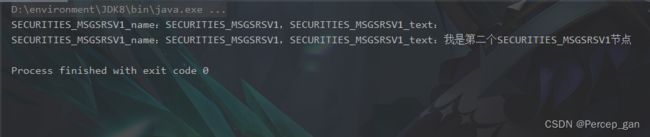
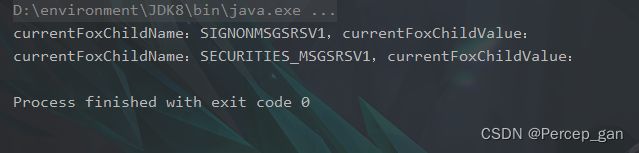
也可以使用“elementIterator()”方法,它是Element的一个迭代方法,也可以枚举子节点,举例如下:
Iterator foxIterator = rootElement.elementIterator();
Element currentFoxChildElement = null;
while (foxIterator.hasNext()) {
currentFoxChildElement = (Element) foxIterator.next();
System.out.println("currentFoxChildName:" + currentFoxChildElement.getName() + ",currentFoxChildValue:" + currentFoxChildElement.getText());
}
运行结果如下:
“elementIterator”也有其他重载方法,比如:“elementIterator(String name)”方法,传入子节点名称就会返回所有该名称的子节点,还是以新增的第二个“SECURITIES_MSGSRSV1”做演示,代码如下:
Iterator SECURITIES_MSGSRSV1Iterator = rootElement.elementIterator("SECURITIES_MSGSRSV1");
Element currentSECURITIES_MSGSRSV1 = null;
while (SECURITIES_MSGSRSV1Iterator.hasNext()) {
currentSECURITIES_MSGSRSV1 = (Element) SECURITIES_MSGSRSV1Iterator.next();
System.out.println("SECURITIES_MSGSRSV1_name:" + currentSECURITIES_MSGSRSV1.getName() + ",SECURITIES_MSGSRSV1_text:" + currentSECURITIES_MSGSRSV1.getText());
}
运行结果如下:

(7)、根据子节点的名字获取子节点
使用“element(String name)”方法获取子节点,注意没有后面没有“s”,代码如下:
public static void main(String[] args) {
String xmlStr = "0INFO 2023-05-2515:43:53 202305251543515222 0INFO 处理成功! 202305241745245833 2 运行结果如下:

利用这个方法可以获取很深的子节点,比如我要获取“SEVERITY”节点,代码如下:

运行结果如下:

可以看到已经获取到了对应的子节点。这种方式可以解决“com.alibaba.fastjson.JSONObject”通过“getJSONObject”方法获取多层数据下,某一层存在一个以上key报转换类型异常的问题。
不过使用的时候也要小心,一定要保证对应的子节点存在,不然很容易导致空指针异常。
假如对应的子节点存在一个以上,则返回第一个子节点,比如我在xml字符串中加入了一个和“SEVERITY”的子节点:
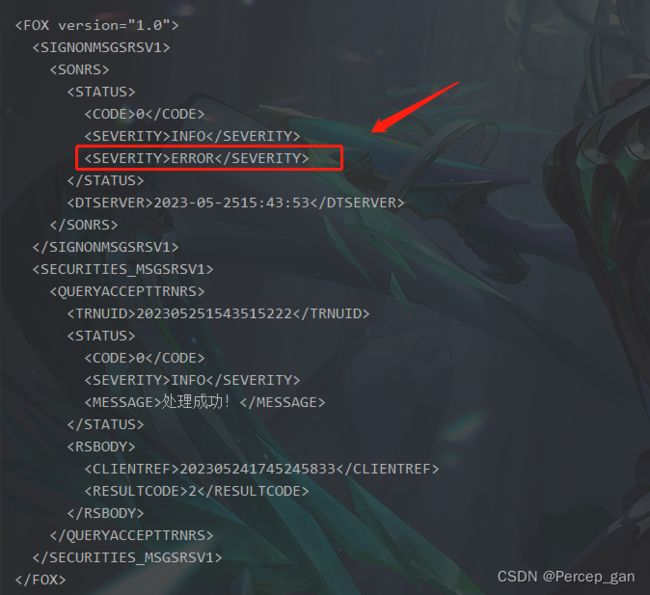
增加打印节点的值,再次运行,结果如下:

可以看到当有多个相同节点名称的时候,返回第一个对应的子节点。
那要是我要找到第二个相同子节点怎么办?可以使用“elements”带节点名称的方法,获得相同名称的所有子节点集合,再根据索引获得指定子节点,获得第二个子节点代码如下:
List<Element> SEVERITYElementList = rootElement.element("SIGNONMSGSRSV1").element("SONRS").element("STATUS").elements("SEVERITY");
Element currentSEVERITYElement = null;
for (int i = 0; i < SEVERITYElementList.size(); i++) {
currentSEVERITYElement = SEVERITYElementList.get(i);
if ("SEVERITY".equals(currentSEVERITYElement.getName()) && 1 == i) {
System.out.println("currentSEVERITYName:" + currentSEVERITYElement.getName() + ",currentSEVERITYValue:" + currentSEVERITYElement.getText());
}
}
运行结果如下:

成功获得对应的第二个子节点。
(8)、添加子节点
“Element”使用“addElement(String name)”方法添加子节点,我这里传的是子节点的名称,代码如下:
public static void main(String[] args) {
String xmlStr = "0INFO ERROR 2023-05-2515:43:53 202305251543515222 0INFO 处理成功! 202305241745245833 2 运行结果如下:
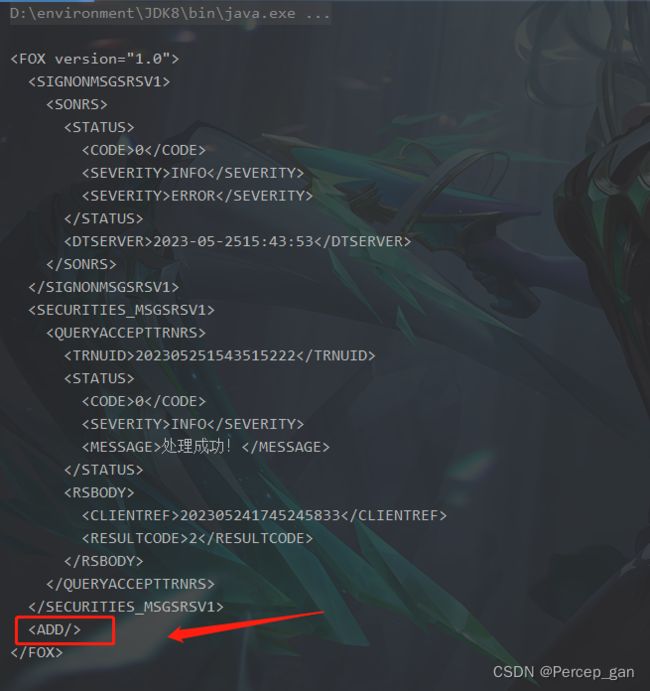
可以看到已经增加了子节点(子标签),但这样的标签在xml中是不合法的,可以显示地设置一下文本值,代码如下:

再次运行:
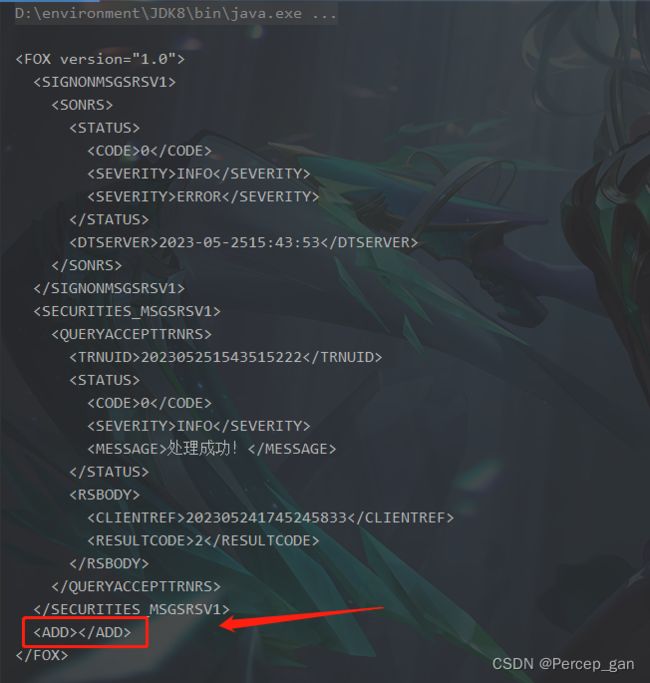
可以看到新增的子节点(子标签)正常了。
(9)、删除某个子节点
需要先使用“element”方法获取到对应的节点,再使用“remove(Element element)”方法删除节点,比如我要删除字符串中的“SECURITIES_MSGSRSV1”节点,代码如下:
public static void main(String[] args) {
String xmlStr = "0INFO ERROR 2023-05-2515:43:53 202305251543515222 0INFO 处理成功! 202305241745245833 2 运行结果如下:
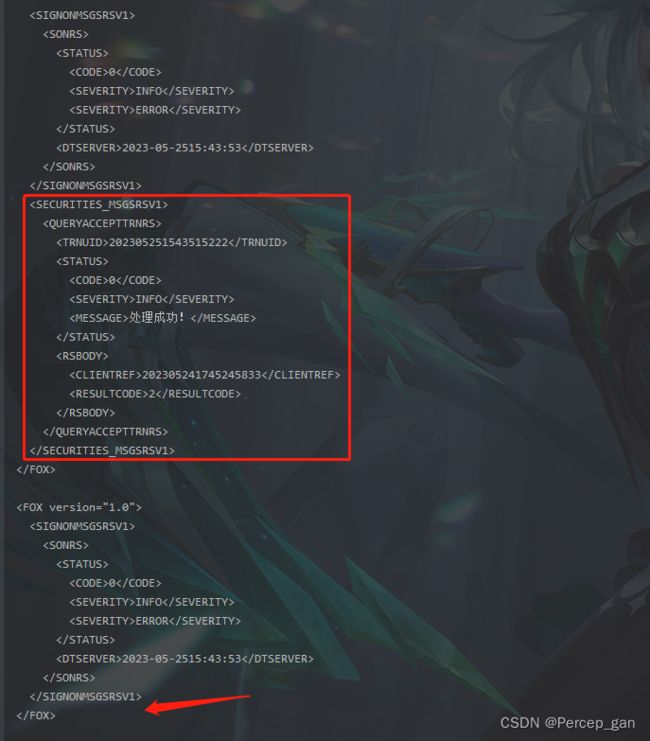
可以看到已经删除“SECURITIES_MSGSRSV1”。
当尝试使用“remove(Namespace namespace)”方法删除节点时,发现是删除失败的。代码如下:
public static void main(String[] args) {
String xmlStr = "0INFO ERROR 2023-05-2515:43:53 202305251543515222 0INFO 处理成功! 202305241745245833 2 运行结果如下:

debug发现所有的删除方法最后都会走这个方法:

而“contentShadow”是一个集合,发现是“Element”集合
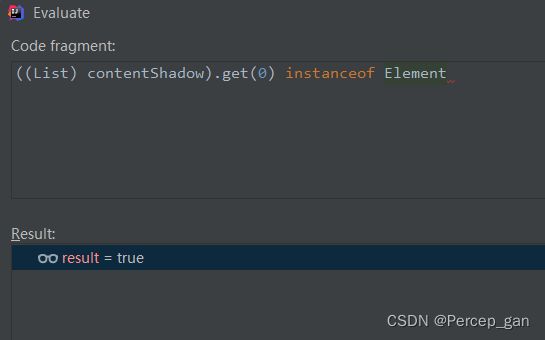
只有传的是“Element”,“answer”才会返回“true”,才会走删除节点“childRemoved(Node node)方法”。