分布式事务框架Seata
分布式事务框架Seata
一、seata是什么
- 在微服务架构下,由于数据库和应用服务的拆分,导致原本一个事务单元中的多个
DML 操作,变成了跨进程或者跨数据库的多个事务单元的多个 DML 操作,
而传统的数据库事务无法解决这类的问题,所以就引出了分布式事务的概念。 - 分布式事务本质上要解决的就是跨网络节点的多个事务的数据一致性问题,业内常
见的解决方法有两种
a. 强一致性,就是所有的事务参与者要么全部成功,要么全部失败,全局事务协
调者需要知道每个事务参与者的执行状态,再根据状态来决定数据的提交或者
回滚!
b. 最终一致性,也叫弱一致性,也就是多个网络节点的数据允许出现不一致的情
况,但是在最终的某个时间点会达成数据一致。
基于 CAP 定理我们可以知道,强一致性方案对于应用的性能和可用性会有影响,所以
对于数据一致性要求不高的场景,就会采用最终一致性算法。 - 在分布式事务的实现上,对于强一致性,我们可以通过基于 XA 协议下的二阶段提
交来实现,对于弱一致性,可以基于 TCC 事务模型、可靠性消息模型等方案来实
现。 - 市面上有很多针对这些理论模型实现的分布式事务框架,我们可以在应用中集成这
些框架来实现分布式事务。而 Seata 就是其中一种,它是阿里开源的分布式事务解决方案,提供了高性能且简单易用的分布式事务服务。
二、seata模块
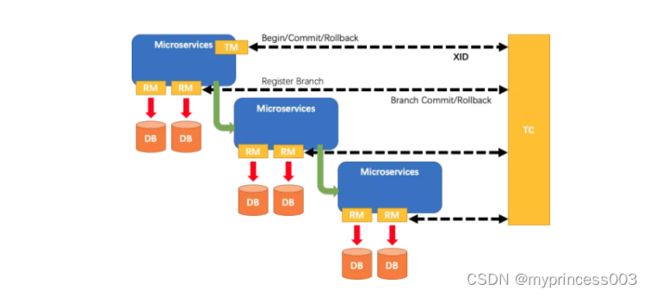
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
在 Seata 中,一个分布式事务的生命周期如下:
TM 请求 TC 开启一个全局事务。TC 会生成一个 XID 作为该全局事务的编号。
XID,会在微服务的调用链路中传播,保证将多个微服务的子事务关联在一起。
RM 请求 TC 将本地事务注册为全局事务的分支事务,通过全局事务的 XID 进行关联。
TM 请求 TC 告诉 XID 对应的全局事务是进行提交还是回滚。
TC 驱动 RM 们将 XID 对应的自己的本地事务进行提交还是回滚。
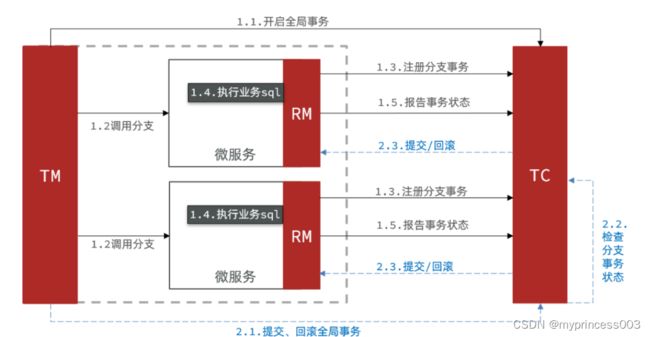
Seata的XA模型:
RM一阶段:
1)TM开启全局事务
2)TM调用分支RM、RM将分支注册到TC、RM执行SQL(但不提交!)、RM将执行状态报告给TC
TC二阶段:
1)TM提交全局事务
2)TC统计各分支状态,如果都成功,则通知RM提交。如果失败,则通知RM回滚。
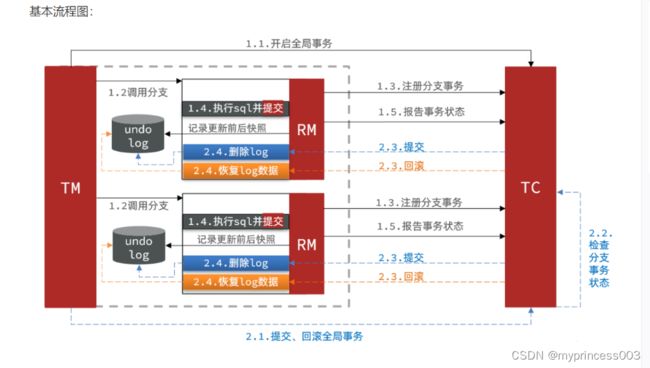
Seata AT模型:
一阶段:TM开启全局事务、TM调用分支、RM注册分支事务、RM记录undolog日志、RM提交事务、TCC记录各分支状态
二阶段:TM通知提交/回滚全局事务、TC检查各分支事务状态,成功,则删除undolog日志,失败,则根据undolog日志回滚。
脏写问题:
如果一个A事务执行sql并提交,另一个B事务也执行提交,此时A事务进行回滚,则会回滚为A记录的undolog日志,而B事务的更新修改记录会被忽略,出现了脏写问题。

解决:引入全局锁,在A事务提价事务释放DB锁之前,申请全局锁,而此时如果B事务进行操作修改,在执行更新数据库操作前会获取全局锁,获取失败,则无法更新,不断重试,但不能一直让其重试,否则A尝试获取B占用的DB锁则会造成死锁,一般让其重试30秒,然后失败则放弃其占有的DB锁,执行失败。A锁此时就能获取DB锁,执行回滚,然后再释放全局锁。
又引来新问题:如果是另一不归seata管理的事务的?全局锁失败!
XA也自动带来了解决的方案:
1)首先记录更新前的记录
2)记录更新后的记录。
完整正确的执行流程如下:
1)原数据假设为100,undolog记录100这个数值。
2)A事务获取DB锁将数据修改为90,此时undolog记录这条90。
3)A事务获取全局锁,并提交事务释放DB数据库锁
4)A事务回滚,在回滚为100前,会比较此时数据是否是90。假设,不归Seata管理的B事务,不需要获取全局锁,然后成功获取DB锁并修改了数据为80,则此时A事务将90(A修改后)与80(B修改)比较,则回滚失败。

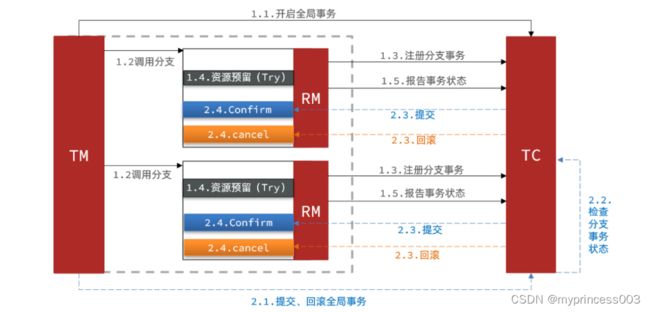
Seata TCC模型:
Try: 判断是否有可用数据,足够则冻结可用数据。
Confirm: 完成资源的操作业务;要求try成功,confirm一定要成功。
Cancel: 预留资源释放,可以理解为try方向操作。
阶段1:检查资源是否足够,足够则冻结资源,执行try方法
阶段2:执行成功,则执行Confirm方法删除冻结资源。执行失败,执行Canel逻辑,恢复冻结资源
四种事务优缺点介绍:
XA:强一致性,无代码侵入、但一阶段事务不提交、会锁住资源,导致性能低。需要依赖数据库的事务特性。
AT:默认,弱一致性,无代码侵入,一阶段事务直接提交,失败则根据undolog日志回滚,隔离性引入全局锁,但并发几率低,所以性能会比XA好。
TCC:无需依赖关系型数据库,基于资源预留隔离。try、confirm、canel需要人工手写,而且需要考虑空悬挂、空回滚、幂等性判断,较为复杂、性能最好,但成本太高。
Seaga:适用于长事务类型,无太多应用场景。