BeanFactoryPostProcessor深度解读
文章目录
- 一、前言
-
- 1、BeanFactoryPostProcessor介绍
- 2、相关类介绍
-
- (1)、ConfigurationClassPostProcessor
- (2)、自定义后置处理器
- 3、约定
- 二、调用链及其他措施
- 三、核心方法的执行
-
- 1、相关变量介绍
- 2、BeanDefinitionRegistryPostProcessor对象
-
- (1)、执行postProcessBeanDefinitionRegistry()
-
- ①、来自参数的对象
- ②、来自容器的PriorityOrdered对象
- ③、来自容器的Ordered对象
- ④、来自容器的其他对象
- (2)、postProcessBeanFactory()的执行
- 3、BeanFactoryPostProcessor对象
-
- (1)、来自参数的对象
- (2)、来自容器的对象
-
- ①、PriorityOrdered对象
- ②、Ordered对象
- ③、其他对象
- 四、执行顺序总结
- 五、问题解答
一、前言
在spring中BeanFactoryPostProcessor的执行是非常重要的一部分,无论是扫描的实现还是拓展spring都需要涉及到这部分。BeanFactoryPostProcessor的执行时机是在BeanFactory实例化之后,可以修改beanFactory。
1、BeanFactoryPostProcessor介绍
BeanFactoryPostProcessor是spring提供的一个接口,其内部只有一个方法:
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException;
BeanFactoryPostProcessor还有一个子接口BeanDefinitionRegistryPostProcessor,其内部添加了一个方法:
void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) throws BeansException;
这2个接口都很重要,在下文中约定:;下文提到的。
2、相关类介绍
这里介绍一些BeanFactoryPostProcessor与BeanDefinitionRegistryPostProcessor的实现类。
(1)、ConfigurationClassPostProcessor
这个类非常重要,其实现了BeanDefinitionRegistryPostProcessor接口与PriorityOrdered接口:
public class ConfigurationClassPostProcessor implements BeanDefinitionRegistryPostProcessor,
PriorityOrdered, ResourceLoaderAware, BeanClassLoaderAware, EnvironmentAware
其相关方法如下:
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
int registryId = System.identityHashCode(registry);
if (this.registriesPostProcessed.contains(registryId)) {
throw new IllegalStateException(
"postProcessBeanDefinitionRegistry already called on this post-processor against " + registry);
}
if (this.factoriesPostProcessed.contains(registryId)) {
throw new IllegalStateException(
"postProcessBeanFactory already called on this post-processor against " + registry);
}
this.registriesPostProcessed.add(registryId);
/**
* @author lcy
* 处理配置beanDefinition
*/
processConfigBeanDefinitions(registry);
}
就是在这个方法里将配置类指定的类解析为BeanDefinition对象,并放入BeanFactory的beanDefinitionMap中。
还有一点需要说明,这个类是在执行AnnotationConfigApplicationContext的无参构造方法时被解析为beanDefinition并放入map中的。
(2)、自定义后置处理器
为了测试执行流程,我自己写了3个相关后置处理器:
public class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor
public class MyBeanDefinitionRegistryPostProcessor implements BeanDefinitionRegistryPostProcessor
public class ParamBeanDefinitionRegistryPostProcessor implements BeanDefinitionRegistryPostProcessor
并重写了相应方法,用于打印一些标记。
3、约定
为了易于表述和理解,下文中遵循以下约定:
- 提到的BeanFactoryPostProcessor实现类和对象,指的是只实现了BeanFactoryPostProcessor而未实现BeanDefinitionRegistryPostProcessor的类或其对象,而后置处理器则是对二者的统称。注意,这里的后置处理器专指bean工厂后置处理器,而无bean后置处理器的含义。
- 提到的对象可能只是以BeanDefinition的形式存在于容器中,还未真正产生,具体情况依据上下文。
- 提到的对象有可能是spring bean,但为了易于表述,可能会把bean称为对象。
- 提到的PriorityOrdered对象指的是实现了PriorityOrdered接口的类的对象,Ordered对象指的是只实现Ordered接口的类的对象,而其他对象指的是未实现以上2接口的类的对象。
二、调用链及其他措施
在AnnotationConfigApplicationContext的refresh()内部的
invokeBeanFactoryPostProcessors(beanFactory)
完成了对
BeanFactoryPostProcessor对象与BeanDefinitionRegistryPostProcessor对象相关方法的执行。该方法具体逻辑如下:
protected void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory) {
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
// Detect a LoadTimeWeaver and prepare for weaving, if found in the meantime
// (e.g. through an @Bean method registered by ConfigurationClassPostProcessor)
if (beanFactory.getTempClassLoader() == null && beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
}
在这个方法内,最重要的就是第一行代码,需要注意到,这一行代码的第二个参数:getBeanFactoryPostProcessors(),其结果一般是空,除非在执行这行代码前,程序员向容器中添加了BeanFactoryPostProcessor实现类的对象或BeanDefinitionRegistryPostProcessor实现类的对象。添加方式如下:
AnnotationConfigApplicationContext ac=new AnnotationConfigApplicationContext();
ac.register(AppConfig.class);
//向容器中添加一个后置处理器
ac.addBeanFactoryPostProcessor(new ParamBeanDefinitionRegistryPostProcessor());
ac.refresh();
可以看到,我在ac.refresh()前向容器中添加了一个ParamBeanDefinitionRegistryPostProcessor对象。接下来详解下面的方法:
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
三、核心方法的执行
1、相关变量介绍
Set processedBeans = new HashSet<>();
这个集合里存放执行过postProcessBeanDefinitionRegistry()的对象(不包括参数中的)的name。
List regularPostProcessors = new ArrayList<>();
这个集合存放参数中的BeanFactoryPostProcess对象。
List registryProcessors = new ArrayList<>();
这个集合存放所有执行过postProcessBeanDefinitionRegistry()的对象(包括参数中的)。
List currentRegistryProcessors = new ArrayList<>();
这个集合存放马上要执行postProcessBeanDefinitionRegistry()的BeanDefinitionRegistryPostProcessor对象。
List priorityOrderedPostProcessors = new ArrayList<>();
这个集合存放实现了PriorityOrdered接口的BeanFactoryPostProcessor对象。
List orderedPostProcessorNames = new ArrayList<>();
这个集合存放实现了Ordered接口的BeanFactoryPostPrpocessor对象的name。
List nonOrderedPostProcessorNames = new ArrayList<>();
这个集合存放未实现PriorityOrdered与Ordered接口的BeanFactoryPostProcessor对象的name。
以上变量都非常重要,但是其具体作用此处无法表述,在具体的执行逻辑中,会分析其作用。
2、BeanDefinitionRegistryPostProcessor对象
首先会针对所有的BeanDefinitionRegistryPostProcessor对象进行处理,其内部有2个方法,相关执行顺序如下:
(1)、执行postProcessBeanDefinitionRegistry()
先执行的是所有BeanDefinitionRegistryPostProcessor对象的postProcessBeanDefinitionRegistry()。依据对象来源及信息不同,执行顺序如下:
①、来自参数的对象
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
}
else {
regularPostProcessors.add(postProcessor);
}
}
可以看到,如果是BeanDefinitionRegistryPostProcessor对象,则执行相应的方法,并将其加入到registryProcessors这个集合中,否则(也就是说是BeanFactoryPostProcessor子类),则将其加入到regularPostProcessors这个集合中。
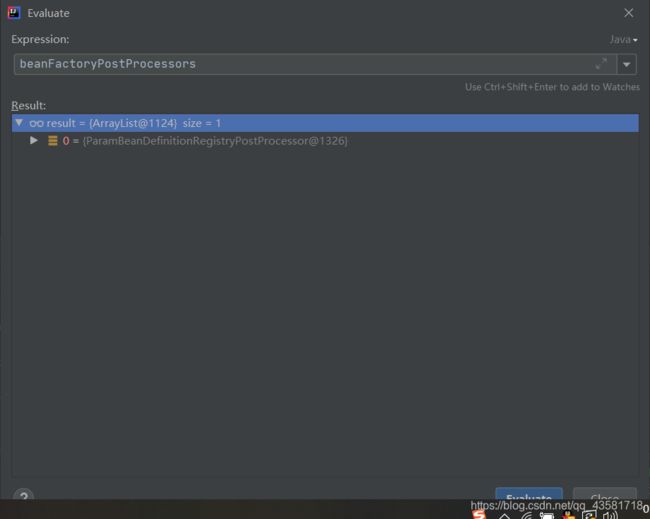
通过debug可以看到,遍历的beanFactoryPostProcessors中就只有我们之前添加的ParamBeanDefinitionRegistryPostProcessor对象。
②、来自容器的PriorityOrdered对象
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
首先,从beanFactory中拿到所有BeanDefinitionRegistryPostProcessor对象的name,然后从中选择实现了PriorityOrdered的。接下来,拿到name对应的bean,将bean放入currentRegistryProcessors集合中,同时将name放入processedBeans集合中。需要注意到,在getBean()执行完成后,所提到的对象就一定真正产生了,而且还成为了一个bean。
在循环执行完后,currentRegistryProcessors中就存放了刚才循环中找到的合适的BeanDefinitionRegistryPostProcessor对象一般情况下,这里找到的就是ConfigurationClassPostProcessor对象。
接下来会针对currentRegistryProcessors中存放的对象排序,并将所有对象存放到registryProcessors这个集合中。在此之后,就会真正执行currentRegistryProcessors中所有对象的postProcessBeanDefinitionRegistry(),而ConfigurationClassPostProcessor的postProcessBeanDefinitionRegistry()中完成的功能之一就是扫描,也就是说,在执行完这一行代码后,例如加了@Component的组件(类)就会被扫描、解析成BeanDefinition对象存入beanDefinitionMap中。最后,在将currentRegistryProcessors集合清空,以便下次使用。
这里会有一个问题,为什么需要先将合适的对象存放到currentRegistryProcessors中,而不是直接在找到其后便直接执行呢?在结尾我会谈谈我对这个问题的看法。

在方法执行前,可以看到beanDefinitionMap中只有一些spring内置的类与AppConfig类的BeanDefinition对象。前面提到过,spring内置的这些是在AnnotationConfigApplicationContext的无参构造方法中添加进去的,也正是因为beanDefinitionMap中存在ConfigurationClassPostProcessor对应的BeanDefinition,在beanFactory.getBeanNamesForType()中才能拿到其name。而AppConfig是在AnnotationConfigApplicationContext的register()中注册进去的。

与上一张图对比,可以看到beanDefinitionMap中增加了几个beanDefiniiton,而我提供的2个加了@Component的后置处理器也在其中。可以证明,就是在这里完成的扫描。
③、来自容器的Ordered对象
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
这里的执行逻辑与上一步几乎相同,但是有几点需要说明:
- 此时的beanFactory.getBeanNamesForType()返回的就不只是ConfigurationClassPostProcessor对象,因为此时我提供的2个后置处理器已经放入了beanDefinitionMap中,所以其name也会被拿到。
- 在从所有name中找的合适的name的判断中,除了要求实现Ordered接口,还添加了一项要求:不能存在于processedBeans中,这里就体现了processedBeans保证每个BeanDefinitionRegistryPostProcessor对象的postProcessBeanDefinitionRegistry()只会被执行一遍。也不难看出,之所以processedBeans中不需要存放参数中对象的name,是因为其不会被反复拿出,而存在于beanDefinitionMap中的后置处理器会被反复拿出,比如ConfigurationClassPostProcessor对象的name在上一次与这一次均被getBeanNamesForType()拿出来了。
- 到这里至少可以看出currentRegistryProcessors的以下作用:循环中找到的合适的BeanDefinitionRegistryPostProcessor对象会被首先放进这个集合中,然后再统一执行。在执行后,再将集合清空,以便下次循环中使用。
④、来自容器的其他对象
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
}
这段代码与上面的差别也不大,这里就其中的差异谈谈:
- 在判断合适的BeanDefinitionRegistryPostProcessor对象的逻辑中,并没有要求其实现任何接口。
- 整段代码被包含在一个while循环中,被一个reiterate变量控制。这是因为,在执行postProcessBeanDefinitionRegistry()中,可能会向beanDefinitionMap中添加新的BeanDefinitionRegistryPostProcessor对象。为了保证这个新添加的对象的postProcessBeanDefinitionRegistry()被执行,采用了一个while循环,只要某一次for循环中发现了合适的BeanDefinitionRegistryPostProcessor对象(也可以理解为"新的",因为所有执行过方法的对象都不是合适的),reiterate就会被设置为true,否则其被设置为false。
(2)、postProcessBeanFactory()的执行
在前面几步,所有BeanDefinitionRegistryPostProcessor的postProcessBeanDefinitionRegistry()已经全部执行过了,但是由于BeanDefinitionRegistryPostProcessor是继承了BeanFactoryPostProcessor
所以其内部还有postProcessBeanFactory()需要执行。
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
在之前的执行中,每个执行过postProcessBeanDefinitionRegistry()的BeanDefinitionRegistryPostProcessor对象都被放进registryProcessors集合中,所以只需要将这个集合中的对象的postProcessBeanFactory()执行一遍就可以了。而且执行顺序与这些对象的postProcessBeanDefinitionRegistry()执行顺序一致。
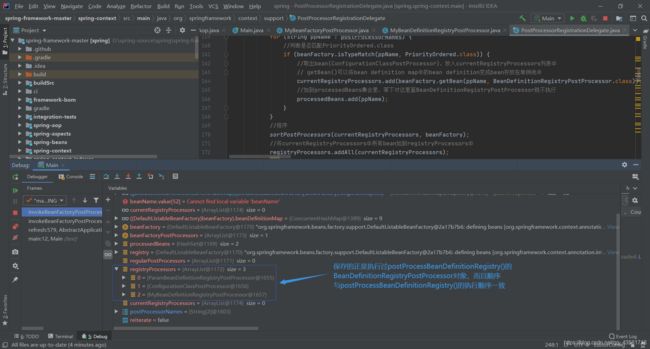
通过debug可以清楚的看到registryProcessors内的对象与这些对象的顺序。
3、BeanFactoryPostProcessor对象
BeanFactoryPostProcessor对象只有postProcessBeanFactory()这一个方法需要执行,下面详细说明其执行顺序与逻辑。
(1)、来自参数的对象
之前有提到,如果参数中的是BeanFactoryPostProcessor对象,则直接放入regularPostProcessors集合中。所以,只需要将这个集合中对象的postProcessBeanFactory()执行一遍即可。
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
这里就体现了regularPostProcessors保存参数中BeanFactoryPostProcessor对象的作用及意义。
(2)、来自容器的对象
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
}
else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
}
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
else {
nonOrderedPostProcessorNames.add(ppName);
}
}
首先,先从容器中拿到所有BeanFactoryPostProcessor对象的name,注意此时那些BeanDefinitionRegistryPostProcessor对象的name也会被拿出来。然后循环这些map,按以下情况分别处理:
- 如果processedBeans中包含了此name,即:此name对应的是BeanDefinitionRegistryPostProcessor对象,则不做任何处理。
- 如果name对应对象的类实现了PriorityOrdered接口,则将对应对象放入priorityOrderedPostProcessors集合中
- 如果name对应对象的类实现了Ordered接口,则将对应对象的name放入orderedPostProcessorNames中。
- 将其他name放进nonOrderedPostProcessorNames集合中。
那么,又有一个问题来了,直接拿PriorityOrdered接口的对象可以理解,毕竟马上就要执行。那么,为什么对于Ordered接口和未实现其他接口的对象只是拿name,而不是顺便也把对象拿出来?我会在结尾谈谈我的理解。
①、PriorityOrdered对象
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);
这个地方比较简单,就是先对priorityOrderedPostProcessors集合中对象排序,然后遍历执行其中对象的postProcessBeanFactory方法。
②、Ordered对象
List orderedPostProcessors = new ArrayList<>(orderedPostProcessorNames.size());
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
由于之前已经获得了相应的name,这里就是获得orderedPostProcessorNames中name对应的对象,然后对这些对象排序,并依次执行其postProcessBeanFactory()。
③、其他对象
List nonOrderedPostProcessors = new ArrayList<>(nonOrderedPostProcessorNames.size());
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
这一段就很好理解,就是通过name获得对象并保存起来,然后统一执行对象的postProcessBeanFactory()。
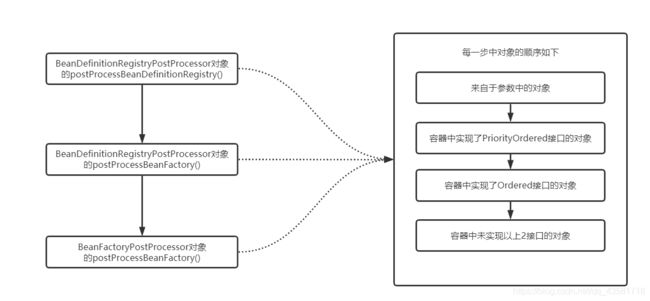
四、执行顺序总结
五、问题解答
上文中提到过2个问题,分别是currentRegistryProcessors的作用和为什么对于非PriorityOrdered对象最开始只是拿name。为了解决这2个问题,先要明确一个点,那就是后置处理器可能对beanFactory做出修改,而通过getBean()获得的对象是由beanFactory产生的,也就是说,执行过的后置处理器会影响之后后置处理器的创建。
- 之所以需要先将扫描到的同一优先级对象先保存在一个集合中,再统一执行,而不是在拿到对象时就直接执行其相关方法?这是为了避免同一优先级中先执行的对象影响后执行的对象,只要把同一优先级的对象先拿到并保存起来,先执行的对象就不会对后执行的对象造成影响,毕竟已经把对象拿出来了。当然,另外一点是,只有先保存起来,才能对同一优先级的对象进行排序。
- 之所以最开始只保存name,则是为了保证优先级高的后置处理器的执行会对优先级低的后置处理器的创建造成影响。即:最开始只拿name,而在优先级高的后置处理器相应方法执行过后,才取优先级低的后置处理器对象(getBean())。
这里总结一下:保证同一优先级的后置处理器彼此互不影响,而高优先级的后置处理器影响低优先级后置处理器对象的创建。