【深入解读Redis系列】Redis系列(五):切片集群详解
首发博客地址
https://blog.zysicyj.top/
系列文章地址[1]
如果 Redis 内存很大怎么办?
假设一台 32G 内存的服务器部署了一个 Redis,内存占用了 25G,会发生什么?
此时最明显的表现是 Redis 的响应变慢,甚至非常慢。
这是因为 RDB 快照是通过 fork 子线程来实现的,fork 操作时间和 Redis 数据量成正相关,而 fork 时会阻塞主线程。
随着数据量的增加,fork 耗时也会增加。所以,当对 25G 的文件进行 fork 时,Redis 的响应就会变慢。
针对这种大数据量的存储,有什么其他的方案呢?
什么是切片集群?
Redis 分片集群是一种将 Redis 数据库分散到多个节点上的方式,以提供更高的性能和可伸缩性。在分片集群中,数据被分为多个片段,每个片段存储在不同的节点上,这些节点可以是物理服务器或虚拟服务器。
Redis 分片集群的主要目的是将数据分布在多个节点上,以便可以通过并行处理来提高读写吞吐量。每个节点负责处理一部分数据,并且在需要时可以进行扩展以适应更多的负载。此外,分片集群还提供了故障容错和高可用性的功能,即使其中一个节点发生故障,其他节点仍然可以继续工作。
比如我们将 25GB 的数据平均分成 5 份(当然,也可以不做均分),使用 5 个实例来保存,每个实例只需要保存 5GB 的数据。如下图所示:
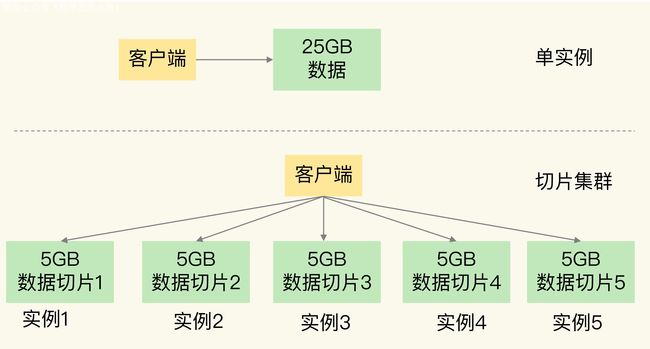 切片集群架构图
切片集群架构图
这样,每个实例只有 5GB 内存,执行 fork 的时候就快得多,不会阻塞主线程。
实际业务中,大数据量通常是无法避免的。而切片集群,就是一个非常好的方案。
如何保存更多数据?
我们可以纵向扩展也可以横向扩展
纵向扩展
即升级单个 Redis 实例的配置,如内存、硬盘、带宽、CPU 等
横向扩展
即增加 Redis 实例的个数
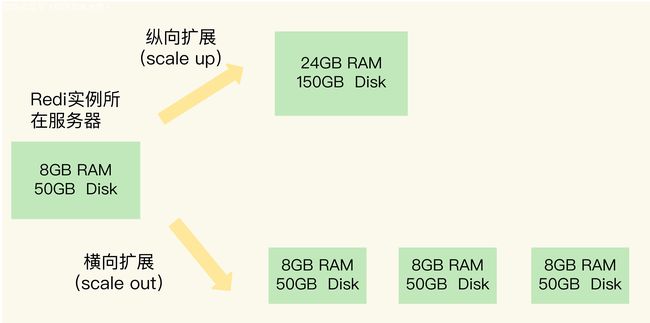 纵向扩展和横向扩展对比图
纵向扩展和横向扩展对比图
那么,纵向扩展和横向扩展的区别是什么呢?
纵向扩展(Scale Up)和横向扩展(Scale Out)是常见的两种扩展方式,用于提升系统的性能和处理能力。它们有着不同的特点和适用场景。
- 纵向扩展: 纵向扩展是通过增加单个节点的硬件资源来提升系统性能。具体来说,是增加服务器的处理能力、存储容量或内存大小等。这可以通过升级服务器的 CPU、内存、硬盘等硬件设备来实现。
优点:
- 简单方便:纵向扩展只需要升级现有的服务器,不需要进行系统的重构和数据迁移。
- 成本相对较低:相对于横向扩展,纵向扩展的成本通常更低,因为只需要购买更高配置的硬件设备。
缺点:
- 有限的扩展能力:纵向扩展的扩展能力受限于单个节点的硬件资源,无法无限扩展。
- 单点故障:如果纵向扩展的节点发生故障,整个系统的可用性将会受到影响。
适用场景:
- 对于单个节点负载较高、需要处理大量并发请求的应用场景,纵向扩展可以提供更好的性能和响应能力。
- 当数据集较小,可以被一个节点的硬件资源容纳时,纵向扩展是一种经济有效的方式。
- 横向扩展: 横向扩展是通过增加多个节点来提升系统的性能和处理能力。每个节点可以是一台独立的服务器或者虚拟机。数据在多个节点上进行分片存储,各个节点共同处理请求,并共享负载。
优点:
- 无限扩展能力:横向扩展可以通过增加更多节点来实现无限的扩展能力,可以根据需求动态添加或移除节点。
- 高可用性:由于数据分布在多个节点上,即使其中一个节点发生故障,其他节点仍然可以继续工作,提供高可用性。
缺点:
- 复杂性增加:横向扩展需要进行数据分片和负载均衡的设计和实现,增加了系统的复杂性。
- 成本较高:相对于纵向扩展,横向扩展需要购买更多的服务器或虚拟机,成本较高。
适用场景:
- 对于需要处理大量并发请求、数据集较大的应用场景,横向扩展可以提供更好的性能和可伸缩性。
- 当需要保证系统的高可用性和故障容错能力时,横向扩展是一种可行的方案。
纵向扩展和横向扩展是两种不同的扩展方式,各自有着不同的优点和适用场景。在实际应用中,应根据具体需求和限制,选择合适的扩展方式来提升系统性能和可伸缩性。
在面向百万、千万级别的用户规模时,横向扩展的 Redis 切片集群会是一个非常好的选择。
Redis 是如何做分片的
Redis 通过一种称为哈希槽(hash slot)的机制来实现分片集群。哈希槽将整个数据集分成固定数量的槽,每个槽都有一个唯一的编号,通常是从 0 到 16383。
在 Redis 分片集群中,有多个节点(主节点和从节点),每个节点负责存储其中一部分的槽数据。节点之间通过集群间通信协议进行数据的交互和同步。
当一个客户端发送一个命令到 Redis 分片集群时,集群会根据命令涉及的键的哈希值将命令路由到正确的槽上。这个槽所在的节点负责处理这个命令并返回结果给客户端。
具体的分片过程如下:
- 客户端发送命令到 Redis 分片集群中的任意一个节点。
- 节点根据命令涉及的键的哈希值计算出对应的槽号。
- 节点根据槽号确定该槽所在的节点,并将命令路由到该节点。
- 该节点处理命令并返回结果给客户端。
当节点加入或离开集群时,Redis 分片集群会自动进行数据的重新分片和迁移,以保持数据的均衡和高可用性。具体的过程如下:
- 当一个新节点加入集群时,集群会将一部分槽从现有节点迁移到新节点上,以平衡数据负载。
- 当一个节点离开集群时,集群会将该节点负责的槽迁移到其他可用节点上,以保证数据的可用性。
通过哈希槽的机制,Redis 分片集群实现了数据的分片和自动迁移,以提供高可用性、扩展性和容错性。同时,节点间的通信和数据同步保证了集群的一致性和可用性。
详细说说哈希槽
Redis 哈希槽是 Redis 集群中用于分片数据的一种机制。哈希槽的概念可以简单理解为一种数据分片的方式,将所有的数据分散存储在多个节点上,以实现数据的高可用和扩展性。
Redis 集群中共有 16384 个哈希槽,每个槽可以存储一个键值对。当有新的键值对需要存储时,Redis 使用一致性哈希算法将键映射到一个哈希槽中。每个 Redis 节点负责管理一部分哈希槽,节点之间通过 Gossip 协议来进行信息交换,以保证集群的一致性。
在 Redis 集群中,当一个节点宕机或者新增加一个节点时,哈希槽会重新分配。集群会自动将宕机节点上的槽重新分配给其他节点,并且保证每个节点分配的槽数尽量均等。这样可以保证数据的高可用性和负载均衡。
使用 Redis 哈希槽的好处是可以方便地扩展集群的容量,当数据量增大时,可以通过增加节点来分担数据的存储压力。同时,由于哈希槽的分配是自动的,所以对于应用程序而言是透明的,不需要额外的逻辑来处理数据分片。
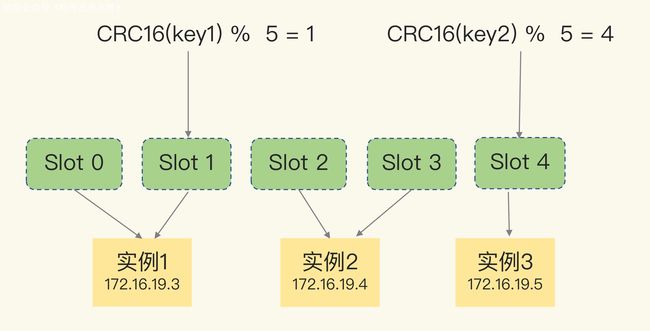
手动分配哈希槽
示意图中的切片集群一共有 3 个实例,假设有 5 个哈希槽,我们可以通过下面的命令手动分配哈希槽:实例 1 保存哈希槽 0 和 1,实例 2 保存哈希槽 2 和 3,实例 3 保存哈希槽 4。
redis-cli -h 172.16.19.3 –p 6379 cluster addslots 0,1
redis-cli -h 172.16.19.4 –p 6379 cluster addslots 2,3
redis-cli -h 172.16.19.5 –p 6379 cluster addslots 4
在集群运行的过程中,key1 和 key2 计算完 CRC16 值后,对哈希槽总个数 5 取模,再根据各自的模数结果,就可以被映射到对应的实例 1 和实例 3 上了。
!! 在手动分配哈希槽时,需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作。
客户端如何定位数据?
在 Redis 集群中,客户端定位数据的过程如下:
- 客户端根据键使用一致性哈希算法(Consistent Hashing)计算哈希值。
- 根据哈希值,客户端将键映射到某个哈希槽。
- 客户端向集群的其中一个节点发送命令请求。
- 接收到请求的节点根据哈希槽的分配信息,确定哪个节点负责管理该哈希槽。
- 负责该哈希槽的节点将命令请求转发给对应的数据节点。
- 数据节点执行命令,将结果返回给负责该哈希槽的节点。
- 负责该哈希槽的节点将结果返回给客户端。
通过这个过程,客户端可以定位到存储在 Redis 集群中的数据,并且可以与集群进行交互。这种方式使得客户端可以直接与任意一个节点进行通信,而不需要知道具体的数据分布和节点拓扑。
一致性哈希算法是用来解决数据分片和负载均衡的常用方法,它可以将数据均匀地分布到不同的节点上,避免某个节点负载过高。同时,当节点发生故障或者新增节点时,一致性哈希算法可以最小化数据的迁移量,使得集群可以快速调整和恢复。
需要注意的是,Redis 集群的客户端不需要手动实现一致性哈希算法,因为该算法已经由 Redis 集群内部实现。客户端只需要使用对应的库或驱动程序,如redis-py-cluster库,来连接 Redis 集群,并且直接使用普通的 Redis 命令进行数据操作。库会自动处理数据的定位和节点间的转发。
Moved 重定向命令
在 Redis 集群中,当客户端向一个节点发送命令请求时,如果该节点不负责处理该命令所涉及的哈希槽,它会返回一个 MOVED 重定向错误。
MOVED 重定向错误包含了正确的节点信息,告诉客户端应该向哪个节点重新发送命令。客户端可以根据 MOVED 错误中的信息,更新自己的节点映射表,然后重新发送命令到正确的节点。
以下是一个使用 Python 的 redis-py 库处理 MOVED 重定向错误的示例:
import redis
# 创建Redis集群连接
cluster = redis.RedisCluster(host='127.0.0.1', port=7000)
# 存储数据
cluster.set('key1', 'value1')
# 获取数据
try:
value = cluster.get('key1')
print(value)
except redis.exceptions.RedisClusterError as e:
if isinstance(e, redis.exceptions.ResponseError) and e.args[0].startswith('MOVED'):
# 解析MOVED错误信息
_, slot, addr = e.args[0].split()
host, port = addr.rsplit(':', 1)
# 更新节点映射表
cluster.connection_pool.nodes.set_node(host, int(port))
# 重新发送命令
value = cluster.get('key1')
print(value)
# 关闭连接
cluster.close()
在以上示例中,如果客户端收到一个 MOVED 错误,它会解析错误信息,获取正确的节点地址,并更新节点映射表。然后,客户端可以重新发送命令到正确的节点进行数据操作。
需要注意的是,MOVED 重定向错误只会在 Redis 集群模式下发生,单机模式不会出现该错误。因此,只有在使用 Redis 集群时,才需要处理 MOVED 重定向错误。在实际开发中,可以使用相应的库或驱动程序来自动处理 MOVED 错误,而无需手动编写处理逻辑。
ASK 命令
在 Redis 集群中,当客户端向一个节点发送一个不可处理的命令时,节点会返回一个 ASK 错误,指示客户端应该向指定的节点发送命令。客户端可以根据 ASK 错误中的信息,更新自己的节点映射表,并将命令发送到正确的节点上。
以下是一个使用 Python 的 redis-py 库处理 ASK 命令的示例:
import redis
# 创建Redis集群连接
cluster = redis.RedisCluster(host='127.0.0.1', port=7000)
# 存储数据
cluster.set('key1', 'value1')
# 获取数据
try:
value = cluster.get('key1')
print(value)
except redis.exceptions.RedisClusterError as e:
if isinstance(e, redis.exceptions.ResponseError) and e.args[0].startswith('ASK'):
# 解析ASK错误信息
_, slot, addr = e.args[0].split()
host, port = addr.rsplit(':', 1)
# 更新节点映射表
cluster.connection_pool.nodes.set_node(host, int(port))
# 重新发送命令
value = cluster.get('key1')
print(value)
# 关闭连接
cluster.close()
在以上示例中,如果客户端收到一个 ASK 错误,它会解析错误信息,获取正确的节点地址,并更新节点映射表。然后,客户端可以重新发送命令到正确的节点进行数据操作。
需要注意的是,ASK 命令只会在 Redis 集群模式下发生,单机模式不会出现该错误。因此,只有在使用 Redis 集群时,才需要处理 ASK 命令。在实际开发中,可以使用相应的库或驱动程序来自动处理 ASK 错误,而无需手动编写处理逻辑。
举个例子
可以看到,由于负载均衡,Slot 2 中的数据已经从实例 2 迁移到了实例 3,但是,客户端缓存仍然记录着“Slot 2 在实例 2”的信息,所以会给实例 2 发送命令。实例 2 给客户端返回一条 MOVED 命令,把 Slot 2 的最新位置(也就是在实例 3 上),返回给客户端,客户端就会再次向实例 3 发送请求,同时还会更新本地缓存,把 Slot 2 与实例的对应关系更新过来。
需要注意的是,在上图中,当客户端给实例 2 发送命令时,Slot 2 中的数据已经全部迁移到了实例 3。在实际应用时,如果 Slot 2 中的数据比较多,就可能会出现一种情况:客户端向实例 2 发送请求,但此时,Slot 2 中的数据只有一部分迁移到了实例 3,还有部分数据没有迁移。在这种迁移部分完成的情况下,客户端就会收到一条 ASK 报错信息,如下所示:
GET hello:key
(error) ASK 13320 172.16.19.5:6379
这个结果中的 ASK 命令就表示,客户端请求的键值对所在的哈希槽 13320,在 172.16.19.5 这个实例上,但是这个哈希槽正在迁移。此时,客户端需要先给 172.16.19.5 这个实例发送一个 ASKING 命令。这个命令的意思是,让这个实例允许执行客户端接下来发送的命令。然后,客户端再向这个实例发送 GET 命令,以读取数据。
ASK 命令详解
在下图中,Slot 2 正在从实例 2 往实例 3 迁移,key1 和 key2 已经迁移过去,key3 和 key4 还在实例 2。客户端向实例 2 请求 key2 后,就会收到实例 2 返回的 ASK 命令。
ASK 命令表示两层含义:第一,表明 Slot 数据还在迁移中;第二,ASK 命令把客户端所请求数据的最新实例地址返回给客户端,此时,客户端需要给实例 3 发送 ASKING 命令,然后再发送操作命令。
和 MOVED 命令不同,ASK 命令并不会更新客户端缓存的哈希槽分配信息。所以,在上图中,如果客户端再次请求 Slot 2 中的数据,它还是会给实例 2 发送请求。这也就是说,ASK 命令的作用只是让客户端能给新实例发送一次请求,而不像 MOVED 命令那样,会更改本地缓存,让后续所有命令都发往新实例。
参考资料
[1]系列文章地址: https://blog.zysicyj.top/categories/技术文章/后端技术/系列文章/Redis/
本文由 mdnice 多平台发布