深入了解Kubernetes(k8s):安装、使用和Java部署指南(持续更新中)
目录
-
- Docker 和 k8s 简介
- 1、kubernetes 组件及其联系
-
- 1.1 Node
- 1.2 Pod
- 1.3 Service
- 2、安装docker
- 3、单节点 kubernetes 和 KubeSphere 安装
-
- 3.1 安装KubeKey
- 3.2 安装 kubernetes 和 KubeSphere
- 3.3 验证安装结果
- 4、集群版 kubernetes 和 KubeSphere 安装
- 5、kubectl 常用命令
- 6、资源编排 yaml 文件
-
- 6.1 yaml 简介
- 6.2 如何快速生成 yaml
- 7、pod
-
- 7.1 pod 简介
- 7.2 pod 数据卷
- 7.3 pod 拉取策略
- 7.4 pod 重启策略
- 7.5 pod 资源限制
- 7.6 pod 健康检查
- 7.7 pod 节点选择器(nodeSelector)
- 7.8 pod 节点亲和性(nodeAffinity)
- 8、node
-
- 8.1 node简介
- 8.2 node 污点
- 9、controller
-
- 9.1 Kubernetes Controllers 的类型
- 9.2 如何使用 Controller 部署应用
- 9.3 对外映射端口
- 9.4 Deployment 升级
-
- 9.4.1 升级命令
- 9.4.2 查看 Deployment 的版本和升级状态
- 9.4.3 查看 Deployment 的详细信息
- 9.4.4 回滚到上一版本
- 9.4.5 回滚到指定版本
- 10、k8s运行java项目
Docker 和 k8s 简介
Docker和Kubernetes是两个不同的概念和技术,它们在容器化应用和容器编排方面有着不同的功能和作用。
Docker:
- Docker是一个开源的容器化平台,用于构建、打包和运行应用程序。通过使用Docker,你可以将应用程序及其依赖项打包到一个独立的轻量级容器中,使其可以在不同的环境中进行部署。具体来说,Docker提供了容器的构建、管理和分发功能,使应用程序可以在隔离的环境中运行,同时也简化了部署和维护的过程。Docker利用容器化的方式,将应用程序与底层的操作系统隔离开来,提供了更好的可移植性和资源利用率。
Kubernetes:
- Kubernetes是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用程序。它提供了一种分布式系统的框架,用于通过自动化和编排容器的生命周期,实现应用程序的高可用性、弹性伸缩、服务发现和负载均衡等功能。Kubernetes提供了容器编排的能力,包括部署和管理容器、自动扩展、负载均衡、弹性伸缩、故障恢复等,使得应用程序可以在Kubernetes集群中高效和稳定地运行。
在实际应用中,通常会使用Docker来构建和打包应用程序的容器镜像,然后使用Kubernetes来部署和管理这些容器镜像,实现容器化应用程序的编排和运行。因此,Docker和Kubernetes通常是一起使用的,分别解决了容器化和容器编排的问题。
1、kubernetes 组件及其联系
1.1 Node
Node是Kubernetes集群中的工作节点,负责运行Pod,相当于集群中的主机。每个Node上运行着Kubernetes的代理组件kubelet,它负责与Master节点通信,并管理在该Node上运行的Pod。Node上还可以运行其他的辅助组件,如容器运行时Docker或CRI-O,网络插件、存储插件等。
1.2 Pod
Pod是Kubernetes的最小调度单元,它由一个或多个容器组成,共享资源并在Node上运行。Node提供了Pod运行所需的资源。Pod由控制平面中的调度器(Scheduler)将其调度到可用的Node上运行,并由Kubelet管理生命周期。Node上的kubelet负责创建、启动、监视和停止Pod中的容器。
1.3 Service
将pod的端口映射到外部,使外界可以通过 Service 来访问 pod。具体来说,Service 提供了一种抽象的入口点,它有自己的 IP 地址和端口,而不是直接暴露 Pod 的 IP 地址和端口。通过 Service,可以将流量从 Service 的 IP 和端口转发到后端 Pod 的实例。
Service 可以有以下几种类型:
- ClusterIP:默认类型,仅在集群内部可访问的虚拟 IP 地址。通过此类型的 Service,其他在集群内部的 Pod 或服务可以通过虚拟 IP 地址和 Service 的端口来访问该 Service。
- NodePort:可以供外网访问,当 Service 的类型设置为 NodePort 时,Kubernetes 在每个工作节点上选择一个随机端口,并将该端口映射到 Service 的端口。外部请求可以通过访问任意工作节点的 IP 地址和映射的端口,来访问 Service。
- LoadBalancer:可以供外网访问,且支持公有云,Kubernetes 在云平台上创建一个外部负载均衡器,并将流量从负载均衡器转发到 Service。外部负载均衡器会分配给 Service 一个外部 IP 地址,从而可以通过该 IP 地址来访问 Service。
- ExternalName:使用 ExternalName 类型的 Service,将 Service 映射到集群外部的 DNS 名称。此类型的 Service 通常用于向集群内部的服务提供外部 DNS 名称的别名。
通过配置 spec.type 来设置 Service 类型,例如:
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
nodePort: 30678 #(必须位于范围 30000-32767)
可以使用 kubectl expose 命令来快速创建和配置 Service。示例命令:
kubectl expose deployment my-deployment --name=my-service --type=NodePort --port=80 --target-port=8080
2、安装docker
docker入门
3、单节点 kubernetes 和 KubeSphere 安装
在 Linux 上以 All-in-One 模式安装 KubeSphere
3.1 安装KubeKey
KubeKey是一个服务器集群安装工具,用于快速部署和配置Kubernetes集群。它是一个基于Ansible和Kubernetes Bootstrapping工具的开源项目,旨在简化Kubernetes集群的安装和管理过程。
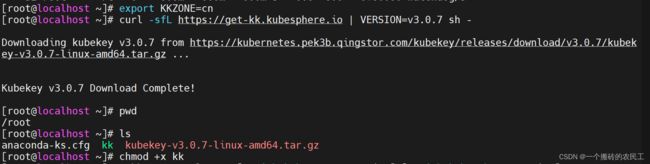
执行以下命令下载 KubeKey(过程有几分钟),为 kk 添加可执行权限:
export KKZONE=cn
curl -sfL https://get-kk.kubesphere.io | VERSION=v3.0.7 sh - chmod +x kk
3.2 安装 kubernetes 和 KubeSphere
因为我们选择的 kubernetes 高于 1.18版本,所以要先安装两个依赖,这个在官方文档有说明
sudo yum install -y conntrack-tools
sudo yum install -y socat
然后 执行如下命令同时安装 kubernetes 和 kubesphere (这里安装时间会很长)
./kk create cluster --with-kubernetes v1.22.12 --with-kubesphere v3.3.2
3.3 验证安装结果
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f
输出信息会显示 Web 控制台的 IP 地址和端口号,默认的 NodePort 是 30880。现在,您可以使用默认的帐户和密码 (admin/P@88w0rd) 通过 :30880 访问控制台。
#####################################################
### Welcome to KubeSphere! ###
#####################################################
Console: http://192.168.0.2:30880
Account: admin
Password: P@88w0rd
NOTES:
1. After you log into the console, please check the
monitoring status of service components in
"Cluster Management". If any service is not
ready, please wait patiently until all components
are up and running.
2. Please change the default password after login.
#####################################################
https://kubesphere.io 20xx-xx-xx xx:xx:xx
#####################################################
登录至控制台后,您可以在系统组件中查看各个组件的状态。如果要使用相关服务,您可能需要等待部分组件启动并运行。您也可以使用 kubectl get pod --all-namespaces 来检查 KubeSphere 相关组件的运行状况。
4、集群版 kubernetes 和 KubeSphere 安装
// 关闭 防火墙
systemctl stop firewalld
systemctl disable firewalld
// 关闭 selinux:# 永久
sed -i 's/enforcing/disabled/' /etc/selinux/config
// 关闭 swp
sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
// 主机名:
hostnamectl set-hostname <hostname>
// 在 master 添加 hosts(改成对应ip和主机名):
cat >> /etc/hosts << EOF
192.168.31.61 k8s-master
192.168.31.62 k8s-node1
192.168.31.63 k8s-node2
EOF
// 将桥接的 IPv4 流量传递到 iptables 的链:
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
// 时间同步:
yum install ntpdate -y
ntpdate time.windows.com
// 安装 kubeadm,kubelet 和 kubectl
yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0
systemctl enable kubelet
部署 Kubernetes Master
(1)在 192.168.31.61(Master)执行
kubeadm init \
--apiserver-advertise-address=192.168.31.61 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.17.0 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=10.244.0.0/16
解释:
kubeadm init:该命令用于初始化一个新的Kubernetes主节点。
--apiserver-advertise-address=192.168.31.61:指定 Kubernetes 控制平面组件master api暴露给其他节点和客户端访问的 IP 地址。
--image-repository registry.aliyuncs.com/google_containers:指定使用的镜像仓库地址。这里使用了 registry.aliyuncs.com/google_containers 作为镜像仓库,该仓库保存了 Kubernetes 相关的镜像。
--kubernetes-version v1.17.0:指定要安装和使用的 Kubernetes 版本。这里指定了v1.17.0。
--service-cidr=10.96.0.0/12:指定服务网络的网段,该网段用于分配给 Kubernetes 服务(service)的虚拟 IP 地址。在本例中,服务 CIDR 被设置为10.96.0.0/12。
--pod-network-cidr=10.244.0.0/16:指定 Pod 网络的网段,该网段用于分配给 Pod 的虚拟 IP 地址。在本例中,Pod 网络 CIDR 被设置为10.244.0.0/16。
由于默认拉取镜像地址 k8s.gcr.io 国内无法访问,这里指定阿里云镜像仓库地址。
(2)使用 kubectl 工具:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
$ kubectl get nodes
安装 Pod 网络插件(CNI)
kubectl apply –f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl get pods -n kube-system
确保能够访问到 quay.io 这个 registery。如果 Pod 镜像下载失败,可以改这个镜像地址加入 s Kubernetes Node
(1)在 192.168.31.62/63(Node)执行
向集群添加新节点,执行在 kubeadm init 输出的 kubeadm join 命令:
kubeadm join 192.168.31.61:6443 --token esce21.q6hetwm8si29qxwn \
--discovery-token-ca-cert-hash
sha256:00603a05805807501d7181c3d60b478788408cfe6cedefedb1f97569708be9c5
5、kubectl 常用命令
kubectl常用命令
6、资源编排 yaml 文件
6.1 yaml 简介
apiVersion(API版本)
指定要使用的Kubernetes API版本。
- apiVersion: v1:指定使用 Kubernetes 核心 API 的 v1 版本。
- apiVersion: apps/v1:指定使用 Apps API 的 v1 版本,用于部署、副本集和状态集等应用相关功能。
- apiVersion: batch/v1:指定使用 Batch Job API 的 v1 版本,用于定义和管理作业和定时任务。
- apiVersion: extensions/v1beta1:指定使用 Extensions API 的 v1beta1
版本,用于一些较旧的扩展部署资源类型,如 Ingress。
kind(类型)
kind 用于指定所定义的资源类型。下面是一些常见的 kind 参数示例:
- kind: Pod:表示定义一个 Pod 资源,用于运行一个或多个容器的最小部署单元。
- kind: Deployment:表示定义一个 Deployment 资源,用于管理应用程序的部署和扩缩容。
- kind: Service:表示定义一个 Service 资源,用于提供稳定的网络访问地址和负载均衡,以与 Pod 通信。
- kind: ConfigMap:表示定义一个 ConfigMap 资源,用于保存应用程序的配置信息。
- kind: Secret:表示定义一个 Secret 资源,用于保存敏感信息,如密码、凭证等。
- kind: Ingress:表示定义一个 Ingress 资源,用于管理对集群内部的 HTTP 和 HTTPS 服务的访问。
还有许多其他资源类型可供选择,每种资源类型都具有不同的用途和特点。
metadata(元数据)
提供有关资源的元数据信息,如名称、标签等。您可以为资源指定一个唯一的名称,并为其添加标签,以便更好地组织和管理资源。
spec(规格)
在此部分,您可以定义资源的详细配置信息。这取决于资源的类型。例如,在Pod资源的spec部分,您可以指定容器镜像、端口、环境变量等配置信息。
以下是一个Pod资源的简单示例:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: nginx
ports:
- containerPort: 80
在命令行中,可以通过以下方式使用YAML文件:
kubectl apply -f <path-to-yaml-file>
6.2 如何快速生成 yaml
举例:
kubectl create deployment web --image=nginx -o yaml --dry-run > my.yaml
kubectl create deployment web:创建名为 web 的Deployment,使用 nginx镜像作为Pod的容器。
--image=nginx:指定要使用的镜像。-o yaml:将输出的资源配置以YAML格式显示。
--dry-run:仅模拟执行操作,不会在集群中实际创建资源。> my.yaml:将输出的YAML配置保存到 my.yaml 文件中。
生成yaml文件如下:
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: web
name: web
spec:
replicas: 1
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
resources: {}
status: {}
7、pod
7.1 pod 简介
在Kubernetes(简称为K8s)中,Pod是最小的可部署和调度的单位。Pod是一组容器的集合,它们共享相同的网络命名空间和存储卷,并以一个单元进行部署和调度。每个Pod都被视为Kubernetes中的一个原子单位。
-
Pod的存在意义:
抽象容器:Pod提供了对容器和应用程序的抽象,使得它们可以作为一个整体进行部署和管理。
紧密耦合容器:Pod内的容器可以共享同一个网络和存储空间,并可通过本地通信进行交互,便于实现相关容器之间的协作和通信。 -
与Docker容器实例的关系:
Docker是一种开源的容器化平台,用于打包、分发和运行应用程序。Pod可以包含一个或多个Docker容器,因此可以说Pod是一个或多个Docker容器的逻辑组合和抽象。Kubernetes使用Docker来实现对容器的创建、分发和运行,利用Docker镜像作为容器的基础。Kubernetes在管理和编排方面对Docker进行了扩展,使得运行在Kubernetes中的Docker容器更加灵活和可靠。
7.2 pod 数据卷
同一个pod 中的容器是如何公用数据卷实现数据共享的,如下所示:
apiVersion: v1
kind: Pod
metadata:
name: shared-volume-pod1
spec:
volumes:
- name: shared-data
emptyDir: {} # 空目录数据卷
containers:
- name: container1
image: my-image
volumeMounts:
- name: shared-data
mountPath: /shared-data
readOnly: false
- name: container2
image: my-image
volumeMounts:
- name: shared-data
mountPath: /shared-data
readOnly: false
在上述的示例中,我们定义了一个具有两个容器的Pod(shared-volume-pod1)。Pod中使用了一个空目录数据卷(emptyDir),命名为"shared-data"。两个容器(container1和container2)都挂载了这个共享数据卷,并在各自的容器内将其挂载到了相同的路径(/shared-data)。
这样,两个容器就可以通过在该路径下进行读写操作来共享数据。在上面的示例中,共享的数据卷是一个空目录,因此容器可以对该目录进行写入操作,并且该操作对另一个容器也是可见的。注意,如果需要在Pod之间实现持久化的数据共享,可以考虑使用其他类型的数据卷,例如持久卷(Persistent Volume)。
需要强调的是,共享的数据卷只对同一个Pod内的容器可见,如果需要在不同的Pod之间实现数据共享,可以考虑使用网络存储卷(Network Storage Volume),例如NFS(Network File System)等。
7.3 pod 拉取策略
Always(总是拉取):无论镜像是否存在于节点上,都会拉取最新的镜像。IfNotPresent(默认值,如果不存在则拉取):仅当镜像不存在于节点上时,才会拉取镜像。Never(从不拉取):仅当镜像已经存在于节点上时,才会使用该镜像。PullIfNotPresent(如果不存在则拉取,否则使用本地镜像):首次创建Pod时,将拉取镜像;之后的创建和更新将使用本地镜像。
spec:
containers:
- name: my-container
image: my-image:latest
imagePullPolicy: Always # IfNotPresent、Never、PullIfNotPresent
7.4 pod 重启策略
Always(默认):当Pod中的容器退出后,Kubernetes会立即重启该容器,保持Pod一直运行。这是默认的重启策略,适用于绝大多数应用。OnFailure:当Pod中的容器因为错误或异常而退出时,Kubernetes会重启容器。如果容器成功运行并退出,Pod不会被重启。适用于一些可以自恢复的应用场景。Never:当Pod中的容器退出后,Kubernetes不会自动重启Pod。该策略通常用于管理具有手动生命周期的Pod,一旦容器退出,Pod将保持在非运行状态。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
restartPolicy: Always # 重启策略
containers:
- name: my-container
image: my-image
7.5 pod 资源限制
resources 用来限制容器的内存和cpu
apiVersion: v1
kind: Pod
metadata:
name: resource-limit-pod
spec:
containers:
- name: my-container
image: my-image
resources:
limits:
cpu: "1"
memory: "1Gi"
requests:
cpu: "500m"
memory: "500Mi"
在上述示例中,limits表示容器能够使用的资源上限,即资源的最大可用量。requests表示容器对资源的需求或保留量,即资源的最低要求量。Pod中的my-container容器被限制为最多使用1个CPU核心(limits.cpu),并且保证Pod被调度到具有至少0.5个CPU核心可用的节点上(requests.cpu)。
7.6 pod 健康检查
在Kubernetes中,你可以通过定义健康检查来监视和管理Pod的运行状态。健康检查可确保Pod中的容器正常运行,并及时检测和处理容器故障或不可用情况。Kubernetes支持以下两种类型的健康检查:
- Liveness Probe(存活探针):用于检测容器是否处于正常运行状态。如果存活探针失败,则Kubernetes会认定容器不可用,并根据重启策略进行相应的处理。
- Readiness Probe(就绪探针):用于检测容器是否准备好接收请求。如果就绪探针失败,则Kubernetes会将Pod从服务的负载均衡中移除,直到容器就绪。
以下是两种探针的示例:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-image
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 10
periodSeconds: 5
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
上述示例中,指定了存活探针和就绪探针。存活探针通过发送HTTP GET请求来检测容器的健康状态,路径为/health,端口为8080。就绪探针使用TCP Socket来检测容器的就绪状态,端口为8080。
在配置探针时,你可以指定以下参数:
- initialDelaySeconds:容器启动后等待多长时间开始执行第一次探测。
- periodSeconds:连续进行两次探测之间的时间间隔。
- successThreshold:成功探测的连续次数,任务完成后容器将被认为是可用的。
- failureThreshold:失败探测的连续次数,任务未能完成后容器将被认为是不可用的。
- timeoutSeconds:探测超时时间。
除了HTTP和TCP之外,Kubernetes还支持其他类型的存活探针和就绪探针。以下是一些常见的探针类型及其示例:
- Exec Probe(执行探针):通过在容器内执行命令来检测容器的健康和就绪状态。
livenessProbe:
exec:
command:
- cat
- /var/healthy
readinessProbe:
exec:
command:
- cat
- /var/ready
上述示例中,Exec探针通过在容器内执行命令cat /var/healthy和cat /var/ready来检测容器的存活和就绪状态。
- TCP Socket Probe(TCP套接字探针):通过尝试与容器的特定端口建立TCP连接来检测容器的健康和就绪状态。
livenessProbe:
tcpSocket:
port: 8080
readinessProbe:
tcpSocket:
port: 8080
上述示例中,TCP Socket探针通过尝试与容器的8080端口建立TCP连接来检测容器的存活和就绪状态。
- Command Probe(命令探针):直接执行命令来检测容器的健康和就绪状态。
livenessProbe:
exec:
command:
- check-health
readinessProbe:
exec:
command:
- check-readiness
上述示例中,Command探针通过执行自定义命令check-health和check-readiness来检测容器的存活和就绪状态。
7.7 pod 节点选择器(nodeSelector)
通过在 Pod 配置文件中添加 nodeSelector 字段,可以根据节点上的标签来选择合适的节点。调度器将根据指定的节点选择器匹配规则,将 Pod 调度到具有相匹配标签的节点上。
首先,在你的节点上添加标签。例如,下面两个节点分别添加到 app=dev 和 app=pro的标签上
kubectl label nodes node1 app=dev
kubectl label nodes node2 app=dev
kubectl label nodes node3 app=pro
kubectl label nodes node4 app=pro
例如,在 Pod 的配置文件中使用 nodeSelector 可以这样指定将 Pod 调度到具有 app=dev标签的节点上:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-image
nodeSelector:
app: dev
那么,这个pod创建的实例将被调度到 env=dev标签的某个 node 节点上
注:启动 nodeSelector 下面的标签名是自定义的,可以是 app 也可以是 anv、abc等。
7.8 pod 节点亲和性(nodeAffinity)
Pod 节点亲和性(Node Affinity)是一种机制,用于在 Kubernetes 中指定 Pod 应该调度到具有特定标签的节点上。通过使用亲和性规则,可以对节点进行更精确的选择,并将 Pod 分配到合适的节点上。
- 硬性亲和性(Hard Affinity):使用硬性亲和性规则,强制将 Pod
调度到具有指定标签的节点上。只有符合指定亲和性规则的节点才会被考虑。 - 软性亲和性(Soft Affinity):使用软性亲和性规则,尽量将 Pod
调度到具有指定标签的节点上。如果找不到符合亲和性规则的节点,Pod 也可以被调度到其他节点上。
亲和性规则可以通过以下两个属性进行定义:
- requiredDuringSchedulingIgnoredDuringExecution:定义了硬性亲和性规则,要求将 Pod
调度到具有指定标签的节点上。 - preferredDuringSchedulingIgnoredDuringExecution:定义了软性亲和性规则,尽量将 Pod
调度到具有指定标签的节点上,但不是必须的。
以下是一个示例,演示了如何使用亲和性规则在 Pod 配置中指定节点亲和性:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-image
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: app
operator: In
values:
- web
- app
在这个示例中,我们将 Pod 的亲和性设置为硬性规则,并要求将 Pod 调度到具有 app=web 或 app=app 标签的节点上。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: my-image
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 50
preference:
matchExpressions:
- key: app
operator: In
values:
- web
在这个示例中,我们将 Pod 的亲和性设置为软性规则。我们使用 preferredDuringSchedulingIgnoredDuringExecution 属性来指定软亲和性规则。
在本例中,我们使用 weight 属性为规则指定了一个权重值为 50。这个权重值表示了调度器在调度 Pod 时对这个规则的偏好程度。较高的权重值表示较高的偏好。
我们还使用 preference.matchExpressions 来定义一个节点选择器规则,要求将 Pod 调度到具有 app=web 标签的节点上。但请注意,这是一个软性规则,如果找不到具有这样的节点,Pod 也可以被调度到其他节点上。
8、node
8.1 node简介
Node 是指运行着容器化应用程序的物理或虚拟机器。Node 是 Kubernetes 集群中的工作节点,也被称为 Minion。
Node 是运行着容器化应用程序的工作节点,在 Kubernetes 集群中承担着运行、管理和提供服务的角色,Kubernetes 通过管理 Node,实现了应用程序容器的高可用性、可扩展性和弹性。
8.2 node 污点
节点污点(Node Taint)是一种在 Kubernetes 中用于标记节点的机制。通过给节点设置污点,可以影响 Pod 调度行为,限制哪些 Pod 可以调度到该节点上。
节点污点由两个部分组成:键和值。它们一起形成一个污点,用于标记节点。节点上可以设置多个污点,以便更精确地控制 Pod 的调度。
当节点设置了污点时,只有那些设置了相应的容忍(Toleration)规则的 Pod 才能被调度到该节点上。如果 Pod 没有匹配的容忍规则,则调度器会视其为不可调度的。
以下是一个设置节点污点的示例:
kubectl taint nodes <node-name> <taint-key>=<taint-value>:<taint-effect>
node-name: 是要设置污点的节点名称。
taint-key:是污点键的名称。
taint-value:是污点键的值。
taint-effect:是污点的效果。
污点的效果可以是以下三种之一:
NoSchedule:该节点一定不会被调度。PreferNoSchedule:该节点尽量不被调度。NoExecute:该节点一定不会被调度外,还会驱逐已经运行在节点上的Pod。
以下是一个设置节点污点的示例命令:
kubectl taint nodes node1 key1=value1:NoSchedule
这个命令将名为 node1 的节点上设置了一个键值为 key1=value1 的污点,并将其效果设置为 NoSchedule,这样没有相应容忍规则的 Pod 将无法调度到该节点上。
9、controller
9.1 Kubernetes Controllers 的类型
Kubernetes 提供了几种类型的 Controller,以下是最主要和最常用的可以用于部署和管理应用的 Controller:
- ReplicaSet: ReplicaSet Controller确保在任何时候都有一定数量的Pod副本在运行。如果有太多的副本,它会开始杀掉多余的。如果副本数太少,它会启动更多的副本。
- Deployment: Deployment Controller 在 ReplicaSet的基础上扩展,增加了版本控制和滚动升级的功能。你可以定义新的 Deployment 版本并逐渐将旧的 Pod 更换为新版本。
- StatefulSet: StatefulSet Controller 用于管理有状态的应用,如数据库。与 Deployment不同的是,StatefulSet 启停顺序是严格有序的,并且每个 Pod 有持久化的唯一标识。
- DaemonSet: DaemonSet Controller 确保每一个节点上都运行一个 Pod的副本,一般用于运行日志收集、监控等节点级别的后台服务。
- Job 和 CronJob: Job Controller 确保任务能够完成,CronJob Controller则可以在指定时间周期内完成运行。
9.2 如何使用 Controller 部署应用
以 Deployment Controller 为例,我们可以创建以下 YAML 文件部署一个简单的 Nginx:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
使用下面的命令部署应用:
kubectl apply -f nginx-deployment.yaml
9.3 对外映射端口
一旦部署了你的 Deployment,你可能需要让外部流量能够访问你的应用。这就需要使用 Service 来实现。例如,以下的 Service 将能够将流量从节点的端口30678转发到你的应用:
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: NodePort
ports:
- protocol: TCP
port: 80
targetPort: 8080
nodePort: 30678 #(必须位于范围 30000-32767)
selector:
app: nginx
使用下面的命令创建 Service:
kubectl apply -f nginx-service.yaml
protocol: TCP:指定服务使用的协议为 TCP。
port: 80:定义了服务(service)在集群内的端口,这是对外公开的端口。
targetPort: 8080:指定了服务将流量转发到后端 Pod 时使用的目标端口。
nodePort: 30678:指定了服务在每个节点(node)上打开的端口,以供从集群外部通过节点的 IP 地址和此端口访问服务。
现在,你可以通过任意 Node 的 30678 端口访问你的 Nginx 应用。所以你可以通过访问 节点IP地址:30678 来访问端口为 80 的 Service。Service 会将流量转发到与其标签选择器匹配的 Pod 上的 8080 端口处运行的应用程序。
9.4 Deployment 升级
9.4.1 升级命令
kubectl set image deployment <deployment-name> <container-name>=<new-image>
示例:kubectl set image deployment my-nginx nginx=nginx:1.15

从上面可以看出 nginx:1.15 正在启动中,原来的版本还在运行中,过一会儿查看只有一个pod了 执行逻辑:首先会去远程拉取镜像到本地docker镜像仓库,然后启动nginx:1.15并停掉之前的版本。
执行逻辑:首先会去远程拉取镜像到本地docker镜像仓库,然后启动nginx:1.15并停掉之前的版本。
9.4.2 查看 Deployment 的版本和升级状态
kubectl rollout history deployment <deployment-name>
kubectl rollout status deployment <deployment-name>
示例:
kubectl rollout history deployment my-nginx
kubectl rollout status deployment my-nginx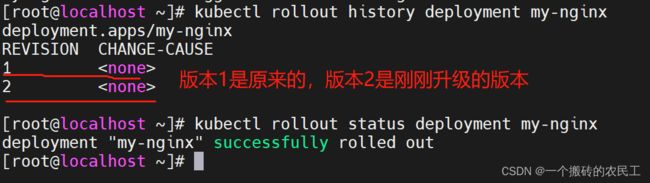
9.4.3 查看 Deployment 的详细信息
kubectl describe deployment <deployment-name>
示例:
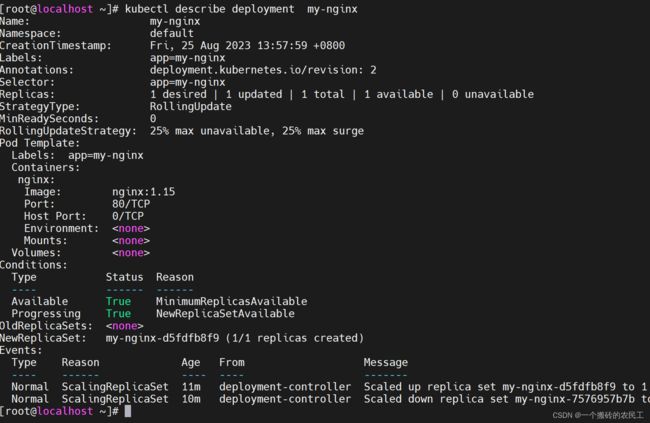
9.4.4 回滚到上一版本
kubectl rollout undo deployment <deployment-name>
示例:kubectl rollout undo deployment my-nginx

9.4.5 回滚到指定版本
kubectl rollout undo deployment <deployment-name> --to-revision=<revision>
示例:kubectl rollout undo deployment my-nginx --to-revision=2

10、k8s运行java项目
1、先创建Dockerfile
FROM openjdk:8-jdk-alpine
WORKDIR /app
COPY target/my-project.jar /app/my-project.jar
EXPOSE 8080
ENTRYPOINT ["java","-jar","/app/my-project.jar"]
2、打包项目上传到服务器、在Dockerfile目录下执行以下命令来基于 Dockerfile 构建 Docker 镜像
docker build -t my-java-app .
3、推送 Docker 镜像到远程仓库,这里以阿里云仓库为例
docker login --username=盛万坪 registry.cn-hangzhou.aliyuncs.com
# 然后输入密码
docker tag seres-gateway:v1 registry.cn-hangzhou.aliyuncs.com/dev_swp/my_ubuntu
docker push registry.cn-hangzhou.aliyuncs.com/dev_swp/my_ubuntu
# seres-gateway:v1 本地仓库镜像:版本
# registry.cn-hangzhou.aliyuncs.com/dev_swp/my_ubuntu 分别对应阿里云docker仓库地址,命名空间,仓库名
4、创建一个 Deployment 的配置文件 - deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-java-app
labels:
app: my-java-app
spec:
replicas: 1
selector:
matchLabels:
app: my-java-app
template:
metadata:
labels:
app: my-java-app
spec:
containers:
- name: my-java-app
image: yourdockerhubusername/my-java-app:1.0
ports:
- containerPort: 8080
kubectl apply -f deployment.yaml
5、Service 以暴露你的 Java 应用
创建一个 service.yaml 文件:
apiVersion: v1
kind: Service
metadata:
name: my-java-app-service
spec:
selector:
app: my-java-app
ports:
- protocol: TCP
port: 8080
targetPort: 8080
nodePort: 30080
type: NodePort
kubectl apply -f service.yaml