Tdengine学习笔记(一)
文章目录
-
-
-
- 时序数据库
- 1、安装与卸载
- 2、启动注意事项
- 3、数据导出导入
-
-
- taosdump主要参数
- 导出命令示例
- 导入命令示例
-
- 4、数据模型基本概念
-
- 数据采集点(Data Collection Point)
- 时间戳(Timestamp)
- 采集量(Metric)
- 标签(Tag)
- 5、数据表数据库
-
- 表
- 超级表(STable)
-
- 创建超级表命令:
- 子表(SubTable)
-
- 使用超级表创建子表命令:
- 库(Database)
-
- 创建库命令:
- 创建库命令:
-
-
时序数据库
工业物联网产生的数据量比传统的信息化要多数千倍甚至数万倍,并且是实时采集、高频度、高密度,动态数据模型随时可变。传统数据库在对这些数据进行存储、查询、分析等处理操作时捉襟见肘,迫切需要一种专门针对时序数据来做优化的数据库系统,即时间序列数据库。
时间序列数据库(Time Series Database)是用于存储和管理时间序列数据的专业化数据库,具备写多读少、冷热分明、高并发写入、无事务要求、海量数据持续写入等特点,可以基于时间区间聚合分析和高效检索,广泛应用在物联网、经济金融、环境监控、工业制造、农业生产、硬件和软件系统监控等场景。
1、安装与卸载
linux系统使用deb包
下载安装:所有下载链接 - TDengine | 涛思数据 (taosdata.com)
安装命令(版本号根据实际安装包):
如果是单机部署,不需要配置FQDN
sudo dpkg -i TDengine-server-2.4.0.7-Linux-x64.deb
卸载命令:
sudo dpkg -r tdengine
安装后对应目录位置/命令

自动生成配置文件目录、数据库目录、日志目录。
配置文件缺省目录:/etc/taos/taos.cfg, 软链接到/usr/local/taos/cfg/taos.cfg;
数据库缺省目录:/var/lib/taos, 软链接到/usr/local/taos/data;
日志缺省目录:/var/log/taos, 软链接到/usr/local/taos/log;
/usr/local/taos/bin目录下的可执行文件,会软链接到/usr/bin目录下;
/usr/local/taos/driver目录下的动态库文件,会软链接到/usr/lib目录下;
/usr/local/taos/include目录下的头文件,会软链接到到/usr/include目录下;
2、启动注意事项
2.4之后的版本,需要另启动taosadapt

3、数据导出导入
TDengine提供了taosdump工具帮助文件导入和导出
taostool下载安装:所有下载链接 - TDengine | 涛思数据 (taosdata.com)
导出导入前,先保证taos shell命令可以正常连接
taosdump主要参数
-o:指定输出文件的路径。文件会自动生成。一个dbs.sql文件,导出数据库、超级表;若干个XXX_tables.N.sql文件,文件名的规则:XXX是数据库名称,N是数字,从0开始递增
-u:用户名。
-p:密码。
-A:指示导出所有数据库的数据。
-D:表示指定数据库。
-i:表示输入目录。
-s:表示导出schema。
-t:指定导入到一个文件的表的个数。该参数可以控制输出文件的大小。(网上很多博客里面都有记录这个参数,但是好像taosdump已经不用这个参数了)
-B:指定一条import语句中包含记录的条数。注意:不要让sql语句超过64k,否则后续导入会出错。该参数为了后续导入时,提高导入速率。
-T: 指定导出数据时,启动的线程数。建议设置成机器上core的2倍。
可以通过 命令 taosdump --help 获取参数信息
导出命令示例
导出所有库
这里-o指定的dump文件夹需要手动建
./bin/taosdump -o ./dump -A -t 500 -B 100 -T 8
导入命令示例
文件夹导入
taosdump -i
4、数据模型基本概念
假设每个智能电表采集电流、电压、相位三个量,有多个智能电表,每个电表有位置 Location 和分组 Group ID 的静态属性. 其采集的数据类似如下的表格:
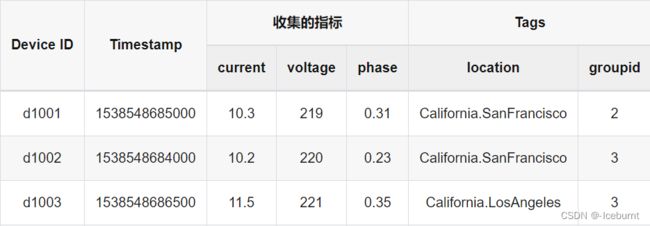
每一条记录都有设备 ID、时间戳、采集的物理量(如上表中的 current、voltage 和 phase)以及每个设备相关的静态标签(location 和 groupid)。每个设备是受外界的触发,或按照设定的周期采集数据。采集的数据点是时序的,是一个数据流。
数据采集点(Data Collection Point)
数据采集点是指按照预设时间周期或受事件触发采集物理量的硬件或软件。
一个数据采集点可以采集一个或多个采集量,但这些采集量都是同一时刻采集的,具有相同的时间戳。
智能电表示例中的 d1001、d1002、d1003、d1004 等就是数据采集点。
时间戳(Timestamp)
Timestamp代表数据产生的时间点,可以写入时指定,也可由系统自动生成;
采集量(Metric)
采集量是指传感器、设备或其他类型采集点采集的物理量,比如电流、电压、温度、压力、GPS 位置等,是随时间变化的,数据类型可以是整型、浮点型、布尔型,也可是字符串。随着时间的推移,存储的采集量的数据量越来越大。智能电表示例中的电流、电压、相位就是采集量。
标签(Tag)
标签是指传感器、设备或其他类型采集点的静态属性,不是随时间变化的,比如设备型号、颜色、设备的所在地等,数据类型可以是任何类型。虽然是静态的,但 TDengine 容许用户修改、删除或增加标签值。与采集量不一样的是,随时间的推移,存储的标签的数据量不会有什么变化。智能电表示例中的 location 与 groupid 就是标签。
5、数据表数据库
表
为充分利用其数据的时序性和其他数据特点,TDengine 采取一个数据采集点一张表的策略,要求对每个数据采集点单独建表(比如有一千万个智能电表,就需创建一千万张表,上述表格中的 d1001,d1002,d1003,d1004 都需单独建表),用来存储这个数据采集点所采集的时序数据。
优点:
- 可采用无锁方式来写,写入速度就能大幅提升
- 写的操作可用追加的方式实现,进一步大幅提高数据写入速度
- 如果读取一个时间段的数据,它能大幅减少随机读取操作,成数量级的提升读取和查询速度
- 对于不同数据类型,采用不同压缩算法,而且由于一个数据采集点的采集量的变化是缓慢的,压缩率更高。
采用一个数据采集点一张表的方式,能最大程度的保证单个数据采集点的插入和查询的性能是最优的。
超级表(STable)
表用来代表一个具体的数据采集点,超级表用来代表一组相同类型的数据采集点集合。
1、一张超级表包含的多个子表具有相同的采集量,但有不同的标签值
2、对于超级表修改数据模式,所包含的子表都会生效
3、超级表不可写入数据,只能写入子表中
创建超级表命令:
CREATE STABLE meters (ts timestamp, current float, voltage int, phase float) TAGS (location binary(64), groupId int);
具体定义以及细节请见 TDengine SQL 的超级表管理 章节。
子表(SubTable)
当为某个具体数据采集点创建表时,用户可以使用超级表的定义做模板,同时指定该具体采集点(表)的具体标签值来创建该表。通过超级表创建的表称之为子表。
子表与常规表格的差异:
- 子表在正常表的基础上有扩展,它是带有静态标签的,而且这些标签可以事后增加、删除、修改
- 一张超级表包含多张子表,但普通表不属于任何超级表
- 普通表与子表不可以互相转化
使用超级表创建子表命令:
CREATE TABLE d1001 USING meters TAGS ("California.SanFrancisco", 2);
详细细则请见 TDengine SQL 的表管理 章节。
库(Database)
一个库里,可以有一到多个超级表,但一个超级表只属于一个库。一个超级表所拥有的子表全部存在一个库里。
创建库命令:
CREATE DATABASE power KEEP 365 DURATION 10 BUFFER 16 WAL_LEVEL 1;
详细的语法及参数请见 数据库管理 章节。
一个库里,可以有一到多个超级表,但一个超级表只属于一个库。一个超级表所拥有的子表全部存在一个库里。
创建库命令:
CREATE DATABASE power KEEP 365 DURATION 10 BUFFER 16 WAL_LEVEL 1;
详细的语法及参数请见 数据库管理 章节。