自动化工具selenium(1)(python版本)
面试题:一)什么是自动化?为什么要做自动化?
自动化测试可以代替一部分手工测试,在一定程度上提高测试效率不能够完全代替手工测试
1)自动化测试相比于手工测试来说人力的投入和时间的投入是非常非常少的,自动化测试能够提高测试效率,速度更快,程序执行的速度是大于手工测试的速度的;
2)在回归测试里面,如果你回归的功能越来越多,迭代的版本越来越多,版本回归压力也会越来越大,所以仅仅通过人工测试的方式来回归所有的版本肯定是不现实的,所以我们需要借助自动化进行回归
比如说微信这个APP当进行回归测试的时候功能是非常多的,这个时候手工测试比较麻烦


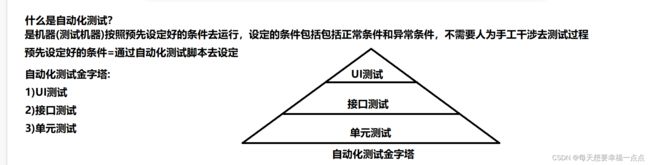
1)UI自动化维护的测试用例量要大于接口测试的测试用例用例量因为要选中元素,选中输入框,操作元素,页面元素非常非常多,UI自动化要在前端和后端开发完成之后才可以进行测试,UI自动化测试用例比单元测试自动化和接口自动化测试用例的维护量都是非常大的;
2)UI自动化往往在项目后期,前后端开发完成项目后期决定的
3)UI自动化适用于界面元素稳定不经常发生变化的项目
1)回归测试:把以前主要的功能进行测试,解放双手,进行大量反复的回归测试和兼容性测试,这不就可以重复的进行复用和重复使用;
2)自动化测试建立一个稳定可靠的测试过程,因为机器是比较准确的,只要你给机器输入的指令正确,机器如果不出问题的话,输出就是正常的,但是人有时候会抛喵,溜号;
3)比如说自动化测试可以进行一些复杂繁琐的测试,比如说测试登录功能的时候,请输入正确的用户名和密码,正确的用户名和错误的密码,错误的用户名和错误的密码;
依靠:数据驱动+自动化脚本(登录自动化脚本);
4)比如说精准记时,记录时间;
5)提高效率,节省资源(人可以在机器跑的过程中可以做其他的事情);

selenium介绍
1)Selenium是web应用中基于UI的自动化测试框架,是一款web自动化测试工具selenium1.0 + webdriver 构成现在的Selenium2.0
2)现在我们说起selenium,一般指的是Selenium2.0
它由Selenium IDE,Webdriver,Selenium Grid组成selenium IDE:自动化脚本录制工具
selenium GRID:做分布式测试(把我们的脚本铺在不同的机器上面)
selenium RC:服务器

二)为什么选择selenium作为自动化测试工具?
selenium是web应用中的基于UI的自动化测试框架,支持多平台,多浏览器,多语言
选择它一定是有原因的
1)支持多浏览器,在进行兼容性测试的时候,我们要对浏览器进行测试,因为用户可能会使用多个浏览器,因为它可以支持多浏览器进行自动化测试;
2)支持多平台多个操作系统,下载驱动的时候就可以看到,比如说linux系统,mac系统,windows系统,MacOS系统;
3)开源免费,不用花钱;
4)selenium支持多语言,比如说JAVA还支持python;
5)selenium包底层有很多可以使用的API,来实现web自动化
自动化测试脚本可以重复的进行测试执行, 用的次数越多,越有价值
1)UI自动化:进行Web界面的测试,项目比较稳定,如果说我们的项目不稳定,需求在不断地发生变化,不适合做自动化测试,脚本还要进行改动,在我们项目的后期进行UI自动化测试,因为我们不同的用户有不同的操作习惯,所以我们的测试用例的维护量大
2)接口自动化:在项目前期就可以进行,项目前期就可以进行介入,测试用例的维护量比较少,可变性比较大,只要考虑输入和输出就可以了,我们还要从多角度验证非法的输入和输出,接口还要稳定
3.1)每次我们进行迭代的时候,我们把核心的功能和流程写成自动化脚本,而这些核心的功能和流程一般是不会发生改变的,就算要进行下一次迭代,也是在这些和新的功能和流程的基础上增加一些新的功能,我们进行回归测试就把自动化脚本执行一次
3.2)兼容性测试也可以用脚本,我们只需要在脚本中更改浏览器的驱动就可以了
3.3)自动化测试执行速度是很快的,例如咱们之前说的注册邮箱功能,24小时之内和给我们发邮件,那如果正好是24小时呢?我们就要对这个时间节点去进行测试,我们总不可能让人去拿着秒表来进行等待测试吧,况且人脑试想一个反应时间的,所以测试也会不准确,所以我们使用自动化脚本的方式会更准确
三)环境部署
selenium工具包
Chrome浏览器
ChromeDriver谷歌驱动
Java版本最低要求是8
四)什么是驱动?驱动的工作原理是什么?
4.1)汽车是具有驱动的,两个轮子也是有驱动的,四个轮子还是有驱动的,驱动可以使汽车跑起来
4.2)计算机里面也是有驱动程序的,可以驱动计算机和设备工作起来;
4.3)打开浏览器也是需要驱动的,在人工测试的情况下,人工可以手动的驱动打开浏览器
但是对于自动化测试来说,代码不能够手动的直接打开浏览器,需要借助驱动chromeDriver程序来协助打开浏览器,总结:代码可以驱使驱动打开浏览器
浏览器的驱动帮助selenium自动化代码主动打开浏览器,也就是驱动浏览器打开
五)(驱动=webdriver)的工作原理:
1)selenium-webdriver,将浏览器启动,将浏览器绑定一个端口,浏览器就做为了一个remote server
2)客户端也就是自动化测试脚本通过commandExecutor向remote server发送HTTP请求
3)remote server会把这个HTTP请求中的指令转化成浏览器的native指令然后去操纵浏览器

如果没有浏览器的驱动,脚本写好之后,是无法让浏览器执行相应的操作
Selenium RC 在浏览器中运行 JavaScript 应用,会存在环境沙箱问题,而 WebDriver 可以跳出 JavaScript 的沙箱,针对不同的浏览器创建更健壮的,分布式的,跨平台的自动化测试脚本;
前提:使用selenium来编写代码
1)我们使用的selenium编写的自动化脚本代码
会给浏览器的webdriver驱动发送一个HTTP请求
2)webdriver浏览器驱动会接受这个HTTP请求并进行解析
3)wendriver浏览器驱动会操控浏览器来执行一些操作,还是定位元素还是进行点击
4)浏览器会把执行结果包装成HTTP响应给驱动,驱动再把执行结果返回给应用程序
启动浏览器,把浏览器绑定到特定的端口,形成一个remote server,自动化脚本通过command executor,HTTP协议给remote server发送指令,去操纵浏览器
用Selenium实现自动化,主要需要三个东西:
1)自动化测试代码:自动化测试代码发送请求给浏览器的驱动,比如火狐驱动、谷歌驱动,IE驱动;
2)浏览器驱动:它来解析这些自动化测试的代码,解析后把它们发送给浏览器
3)浏览器:执行浏览器驱动发来的指令,并最终完成工程师想要的操作。
测试代码中包含了各种期望的对浏览器界面的操作,例如点击,测试代码通过给Webdriver发送指令,让Webdriver知道想要做的操作,而Webdriver根据这些操作在浏览器界面上进行控制,由此测试代码达到了在浏览器界面上操作的目的。
Selenium脚本执行时后端实现的流程:
1)对于每一条Selenium脚本,一个http请求会被创建并且发送给浏览器的驱动
2)浏览器驱动中包含了一个HTTP Server,用来接收这些HTTP请求
3)HTTP Server接收到请求后根据请求来具体操控对应的浏览器
4)浏览器执行具体的测试步骤
5)浏览器将步骤执行结果返回给HTTP Server
6)HTTP Server又将结果返回给Selenium的脚本,如果是错误的http代码我们就会在控制台看到对应的报错信息
1)webdiver:驱动浏览器做事情,是一个.exe文件,绕过了JavaScript的环境沙箱问题,当我们打开一个新的页面的时候,会出现被拦截的现象
2)脚本:就类似于乘客,脚本里面有详细的路线,去哪里,从哪里转
3)司机:根据乘客说的路线进行开车,拿钥匙开车,根据乘客的指示来进行操作
4)车:被驱动的工具,浏览器
5)webDriver根据脚本的指令驱动浏览器
必须知道请求驱动的地址是什么?那么此时驱动在这里面应该扮演这是一个啥样的角色呢?
驱动要接受请求并且要解析请求,所以说驱动是一个服务器的角色
驱动应该是一个HTTP服务器,IP+端口号,IP地址就是本机IP,端口号就是默认的9515,只有通过IP地址+端口号才可以定位到一个服务器的位置
乘客的指令=自动化脚本
webdriver=司机
浏览器=出租车
当前驱动程序已经建立好了TCP链接


selenium IDE:自动化脚本录制工具
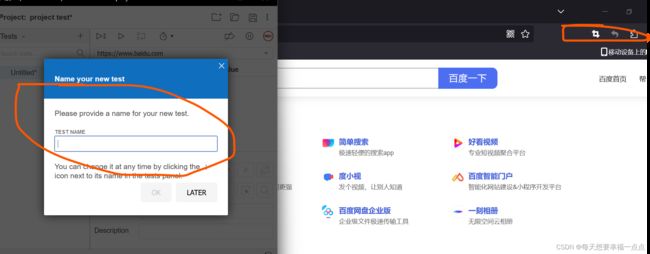
安装selenium IDE,先打开浏览器的扩展和主题搜索Selenium IDE,下载完成之后再来点击
1)先进行下载
2)找到启动位置
3)使用
4)进入到指定页面
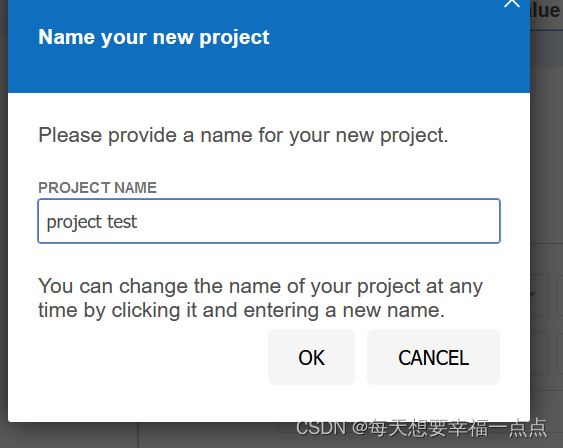
5)导出报告,点击下面的Tests下面的右键test点击export
6)点击run可以重新运行脚本


安装python:
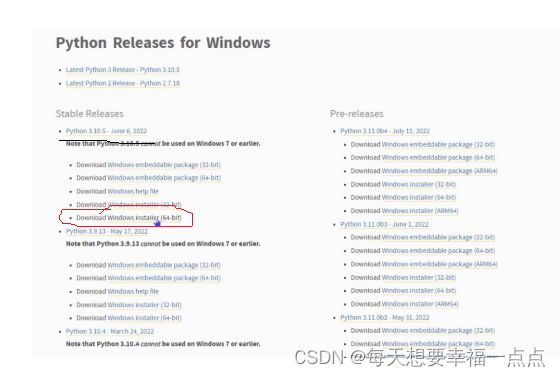
先去官网:Welcome to Python.org
点击下载,点击Windows
安装python和selenium:Docs

禅道是一款什么工具?设计理念是什么?
1)禅道是一款项目管理工具,可以管理整个软件的开发周期,是根据敏捷开发流程来进行设计的,所以可以进行敏捷开发的管理,适用于瀑布模型,适用于看板模型的项目管理
2)产品经理,项目经理,开发人员,测试人员都可以使用禅道
对页面的元素进行控制,所以说要先对页面元素进行控制,所以元素定位是非常重要的
比如说查询,删除,修改
一个简单脚本的构成:
1)在脚本头部导入需要的包
2)获取浏览器的驱动
3)使用浏览器对需要测试的文本系统进行操作
4)测试完毕关闭浏览器
第一个自动化测试脚本
我们就可以根据这个点击百度的输入框可以看到这个输入框的ID是全局唯一的

1)通过ID来进行定位元素:
# coding = utf-8 # 上面是设置脚本的编码形式防止乱码 from selenium import webdriver # 上面导入所需要的工具包 import time # 1.获取浏览器的驱动,在里面直接填入浏览器驱动的在windows的地址,驱动单词首字母必须大写 browser = webdriver.Edge("C://Users//18947//AppData//Local//Programs//Python//Python310//msedgedriver.exe") time.sleep(3) # 2.在浏览器的搜索栏里面自动输入你想要访问界面的url browser.get("http://www.baidu.com") time.sleep(3) # 3.定位界面中的元素并进行操作,这里是直接定位输入框输入selenium browser.find_element_by_id("kw").send_keys("selenium") time.sleep(3) browser.find_element_by_id("su").click() time.sleep(3) # 4.推出浏览器并且里缓存垃圾 browser.quit();
from selenium import webdriver import time # 获得浏览器的驱动 driver = webdriver.Edge("C://Users//18947//AppData//Local//Programs//Python//Python310//msedgedriver.exe") # 在浏览器搜索框里面输入要进行访问的web界面 driver.get("http://www.baidu.com") time.sleep(3) # 用ID定位元素 driver.find_element_by_id("kw").send_keys("六一儿童节") time.sleep(3) driver.find_element_by_id("su").click() time.sleep(3) driver.quit()# coding = utf-8 from selenium import webdriver # 拿到对应浏览器的驱动 import time # 你的驱动已经放到环境变量下仍然报错找不到驱动,所以需要手动指定,其他的正常按照教程操作即可 browser = webdriver.Edge("C:\Program Files\Python310\Scripts\msedgedriver.exe") # msedgedriver' executable needs to be in PATH 翻译过来驱动必须放到环境变量下,帮我找到你的驱动位置 #当前调用的浏览器是是edge,那么就需要使用edge的驱动来打开edge浏览器,而你下载的是谷歌驱动,所以无法打开edge浏览器 browser.get("http://www.baidu.com"); time.sleep(2) #用id来进行定位百度搜索框,因为我们后期要进行操作,id在整个页面是唯一的 browser.find_element_by_id("kw").send_keys("博客系统"); time.sleep(5); #先选择百度一下按钮,进行点击 browser.find_element_by_id("su").click(); time.sleep(2); #关闭浏览器 quit方法在关闭浏览器的时候可以关闭浏览器的一些缓存 browser.quit();
2)尝试用name属性来定位页面中的元素
通过ID来进行选中元素进行操作(使用浏览器的百度搜索框)(没有ID属性无法进行获取)我们通过name属性来进行操作页面上面的元素(操作禅道)(name名字相同无法进行获取)
from selenium import webdriver import time # 获得浏览器的驱动 driver = webdriver.Edge("C://Users//18947//AppData//Local//Programs//Python//Python310//msedgedriver.exe") # 在浏览器搜索框里面输入要进行访问的web界面 driver.get("http://www.baidu.com") time.sleep(3) # 我们尝试用name定位元素 driver.find_element_by_name("wd").send_keys("六一儿童节") time.sleep(3) # 在这里面我们发现我们无法针对百度的按键来确定name,因为百度的那个按钮是没有name属性的 driver.find_element_by_id("su").click() time.sleep(3) driver.quit()打开禅道通过name属性
#我们先进行打包 import time from selenium import webdriver url="http://127.0.0.1:88/zentao/user-login-L3plbnRhby8=.html"; #指定浏览器驱动的位置 diver=webdriver.Edge("C:\Program Files\Python310\Scripts\msedgedriver.exe"); diver.get(url); #我们用name来进行定位 diver.find_element_by_name("account").send_keys("admin");#选中用户名标签,输入用户名 time.sleep(6); diver.find_element_by_name("password").send_keys("125034");#选中密码标签,输入密码 time.sleep(6); diver.find_element_by_id("submit").click();#选中点击按钮,进行点击 time.sleep(3) #关闭浏览器 diver.quit();
3)我们通过class_name的方式来进行操作页面上面的元素:(百度搜索框)(class_name重复可能无法获取)
本质上来说classname=一个控件的class属性,里面有一个字符串就是classname
from selenium import webdriver import time driver=webdriver.Edge("C:\Program Files\Python310\Scripts\msedgedriver.exe"); url="http://www.baidu.com"; driver.get(url); #我们现在使用classname属性来进行定位浏览器 driver.find_element_by_class_name("s_ipt").send_keys("鲜花"); driver.find_element_by_class_name("se-bn").click(); #driver.find_element_by_id("su").click(); #className四经常容易重复,除非这个className属性是全局唯一的 time.sleep(1); driver.quit();
4)linktext定位元素适用于可点击的链接,也就是最后直接输入文字
通过linktext的方式来获取到文字链接,在上面选中的是页面的地图或者新闻
通过linktext获取元素的方式只是输入文字即可,但是文字必须全局唯一
from selenium import webdriver import time diver=webdriver.Edge("C:\Program Files\Python310\Scripts\msedgedriver.exe"); url="http://www.baidu.com"; diver.get(url); time.sleep(3); diver.find_element_by_link_text("地图").click();#如果说页面上有相同的链接地址,那么我们就无法定位到页面上面的链接 time.sleep(3); diver.close();

5)通过这个文字链接的一部分也就是partial_link_text来进行获取
下面选择选择百度页面上的文字链接也就是hao123
import time driver=webdriver.Edge("C:\Program Files\Python310\Scripts\msedgedriver.exe"); url="http://www.baidu.com"; driver.get(url); time.sleep(2); #我们现在使用partial-link-text来进行定位,如果页面上面有相同的元素,那么直接会报错,element not interactable driver.find_element_by_partial_link_text("hao").click(); time.sleep(2); driver.quit();
6)通过tagname的方式,本质上就是标签名字
使用通常会报错,因为标签名在整个页面中不能重复
element not interactable,下面的程序会发生报错这个选中的元素tagname必须全局唯一,下列程序失败的原因就是无法定义唯一的input标签
from selenium import webdriver import time url="http://www.baidu.com" driver=webdriver.Edge("C:\Program Files\Python310\Scripts\msedgedriver.exe"); driver.get(url); driver.find_element_by_tag_name("input").send_keys("鲜花"); driver.find_element_by_tag_name("input").click(); driver.quit();
4)我们通过xpath属性来定位页面中唯一的元素
通过xpath属性我们可以定位全局唯一元素
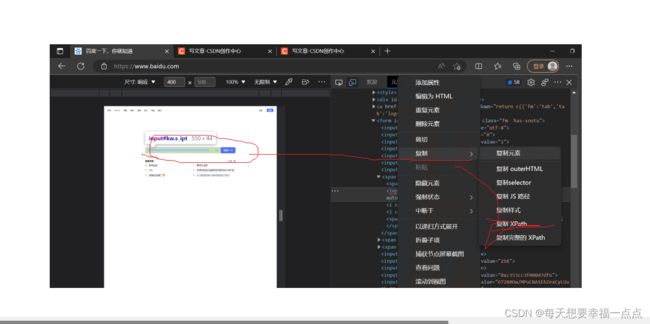
如何来获取元素的xpath属性呢?
1)在页面上右键检查
2)通过终端控制台上面右上角的小正方形来进行选中页面中的元素
3)选中要即将选中的元素,进行右键
from selenium import webdriver import time diver=webdriver.Edge("C:\Program Files\Python310\Scripts\msedgedriver.exe"); diver.get("http:www.baidu.com"); diver.find_element_by_xpath("//*[@id='kw']").send_keys("你爱我吗");#我们的*已经把前面的路径省略掉 time.sleep(2); diver.find_element_by_xpath("//*[@id='su']").click(); #当咱们的这个元素没有id属性,name属性也没有,没有class,就算有也不是全局唯一的,那么我们就可以用xpath来进行全局定位到我们的元素,我们使用 #xpath就可以唯一定位到这个个元素 time.sleep(2); diver.quit();

8)使用cssselector的方式来进行获取元素:进行百度输入框搜索(和选择xpath的方式一样)
from selenium import webdriver import time #注意我们这里的find_element不要写成find_elements driver=webdriver.Edge("C:\Program Files\Python310\Scripts\msedgedriver.exe"); driver.get("http://www.baidu.com"); driver.find_element_by_css_selector("#kw").send_keys("你好呀"); time.sleep(2); driver.find_element_by_css_selector("#su").click(); time.sleep(2); driver.quit();
