Docker 底层原理浅析
作者:vitovzhong,腾讯 TEG 应用开发工程师
容器的实质是进程,与宿主机上的其他进程是共用一个内核,但与直接在宿主机执行的进程不同,容器进程运行在属于自己的独立的命名空间。命名空间隔离了进程间的资源,使得 a,b 进程可以看到 S 资源,而 c 进程看不到。
1. 演进
对于统一开发、测试、生产环境的渴望,要远远早于 docker 的出现。我们先来了解一下在 docker 之前出现过哪些解决方案。
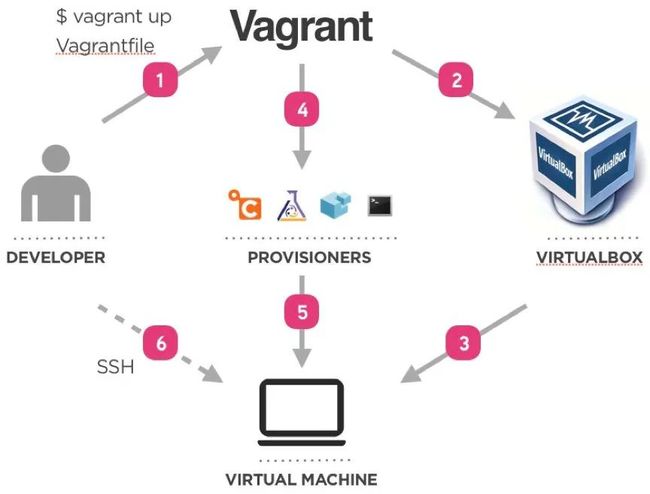
1.1 vagrant
Vagarant 是笔者最早接触到的一个解决环境配置不统一的技术方案。它使用 Ruby 语言编写,由 HashCorp 公司在 2010 年 1 月发布。Vagrant 的底层是虚拟机,最开始选用的是 virtualbox。一个个已经配置好的虚拟机被称作 box。用户可自由在虚拟机内部的安装依赖库和软件服务,并将 box 发布。通过简单的命令,就能够拉取 box,将环境搭建起来。
// 拉取一个ubuntu12.04的box
$ vagrant init hashicorp/precise32
// 运行该虚拟机
$ vagrant up
// 查看当前本地都有哪些box
$ vagrant box list
如果需要运行多个服务,也可以通过编写 vagrantfile,将相互依赖的服务一起运行,颇有如今 docker-compose 的味道。
config.vm.define("web") do |web|web.vm.box = "apache"
end
config.vm.define("db") do |db|db.vm.box = "mysql”
end
1.2 LXC (LinuX Container)

在 2008 年,Linux 2.6.24 将 cgroups 特性合入了主干。Linux Container 是 Canonical 公司基于 namespace 和 cgroups 等技术,瞄准容器世界而开发的一个项目,目标就是要创造出运行在 Linux 系统中,并且隔离性良好的容器环境。当然它最早也就见于 Ubuntu 操作系统上。
2013 年,在 PyCon 大会上 Docker 正式面世。当时的 Docker 是在 Ubuntu 12.04 上开发实现的,只是基于 LXC 之上的一个工具,屏蔽掉了 LXC 的使用细节(类似于 vagrant 屏蔽了底层虚拟机),让用户可以一句 docker run 命令行便创建出自己的容器环境。
2. 技术发展
容器技术是操作系统层面的虚拟化技术,可以概括为使用 Linux 内核的 cgroup,namespace 等技术,对进程进行的封装隔离。早在 Docker 之前,Linux 就已经提供了今天的 Docker 所使用的那些基础技术。Docker 一夜之间火爆全球,但技术上的积累并不是瞬间完成的。我们摘取其中几个关键技术节点进行介绍。

2.1 Chroot
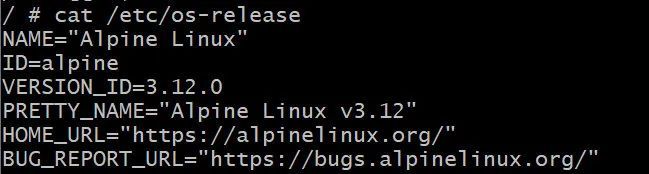
软件主要分为系统软件和应用软件,而容器中运行的程序并非系统软件。容器中的进程实质上是运行在宿主机上,与宿主机上的其他进程共用一个内核。而每个应用软件运行都需要有必要的环境,包括一些 lib 库依赖之类的。所以,为了避免不同应用程序的 lib 库依赖冲突,很自然地我们会想是否可以把他们进行隔离,让他们看到的库是不一样的。基于这个朴素的想法,1979 年, chroot 系统调用首次问世。来举个例子感受一下。在 devcloud 上申请的云主机,现在我的 home 目录下准备好了一个 alpine 系统的 rootfs,如下:

在该目录下执行:
chroot rootfs/ /bin/bash
然后将/etc/os-release 打印出来,就看到是”Alpine Linux”,说明新运行的 bash 跟 devcloud 主机上的 rootfs 隔离了。
2.1 Namespace
简单来说 namespace 是由 Linux 内核提供的,用于进程间资源隔离的一种技术,使得 a,b 进程可以看到 S 资源;而 c 进程看不到。它是在 2002 年 Linux 2.4.19 开始加入内核的特性,到 2013 年 Linux 3.8 中 user namespace 的引入,对于我们现在所熟知的容器所需的全部 namespace 就都实现了。
Linux 提供了多种 namespace,用于对多种不同资源进行隔离。容器的实质是进程,但与直接在宿主机执行的进程不同,容器进程运行在属于自己的独立的命名空间。因此容器可以拥有自己的 root 文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。
还是来看一个简单的例子,让我们有个感性认识,namespace 到底是啥,在哪里能直观的看到。在 devcloud 云主机上,执行:ls-l /proc/self/ns 看到的就是当前系统所支持的 namespace。

接着我们使用 unshare 命令,运行一个 bash,让它不使用当前的 pid namespace:
unshare --pid --fork --mount-proc bash
然后运行: ps -a 看看当前 pid namespace 下的进程都有哪些:

在新起的 bash 上执行:ls -l /proc/self/ns, 发现当前 bash 的 pid namespace 与之前是不相同的。

既然 docker 就是基于内核的 namespace 特性来实现的,那么我们可以简单来认证一下,执行指令:
docker run –pid host --rm -it alpine sh
运行一个简单的 alpine 容器,让它与主机共用同一个 pid namespace。然后在容器内部执行指令 ps -a 会发现进程数量与 devcloud 机器上的一样;执行指令 ls -l /proc/self/ns/ 同样会看到容器内部的 pid namespace 与 devcloud 机器上的也是一样。
2.2 cgroups
cgroups 是 namespace 的一种,是为了实现虚拟化而采取的资源管理机制,决定哪些分配给容器的资源可被我们管理,分配容器使用资源的多少。容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样。这种特性使得容器封装的应用比直接在宿主运行更加安全。例如可以设定一个 memory 使用上限,一旦进程组(容器)使用的内存达到限额再申请内存,就会出发 OOM(out of memory),这样就不会因为某个进程消耗的内存过大而影响到其他进程的运行。
还是来看个例子感受一下。在 devcloud 机器上运行一个 apline 容器,限制只能使用前 2 个 CPU 且只能使用 1.5 个核:
docker run --rm -it --cpus "1.5" --cpuset-cpus 0,1 alpine
然后再开启一个新的终端,先看看系统上有哪些资源是我们可以控制的:
cat /proc/cgroups
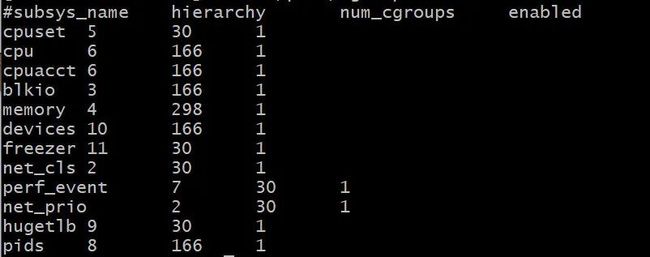
最左边一侧就是可以设置的资源了。接着我们需要找到这些控制资源分配的信息都放在哪个目录下:
mount | grep cgroup
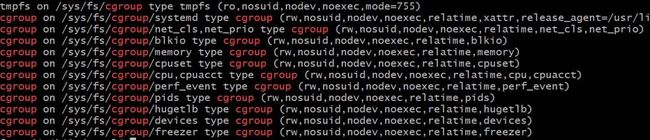
然后我们找到刚刚运行的 alpine 镜像的 cgroups 配置:
cat /proc/`docker inspect --format='{{.State.Pid}}' $(docker ps -ql)`/cgroup

这样,把二者拼接起来,就可以看到这个容器的资源配置了。我们先来验证 cpu 的用量是否是 1.5 个核:
cat /sys/fs/cgroup/cpu,cpuacct/docker/c1f68e86241f9babb84a9556dfce84ec01e447bf1b8f918520de06656fa50ab4/cpu.cfs_period_us
输出 100000,可以认为是单位,然后再看配额:
cat /sys/fs/cgroup/cpu,cpuacct/docker/c1f68e86241f9babb84a9556dfce84ec01e447bf1b8f918520de06656fa50ab4/cpu.cfs_quota_us
输出 150000,与单位相除正好是设置的 1.5 个核,接着验证是否使用的是前两个核心:
cat /sys/fs/cgroup/cpuset/docker/c1f68e86241f9babb84a9556dfce84ec01e447bf1b8f918520de06656fa50ab4/cpuset.cpus
输出 0-1。
目前来看,容器的资源配置都是按照我们设定的来分配的,但实际真能在 CPU0-CPU1 上限制使用 1.5 个核吗?我们先看一下当前 CPU 的用量:
docker stats $(docker ps -ql)

因为没有在 alpine 中运行程序,所以 CPU 用量为 0,我们现在回到最开始执行 docker 指令的 alpine 终端,执行一个死循环:
i=0; while true; do i=i+i; done
再来观察当前的 CPU 用量:

接近 1,但为啥不是 1.5?因为刚刚运行的死循环只能跑在一个核上,所以我们再打开一个终端,进入到 alpine 镜像中,同样执行死循环的指令,看到 CPU 用量稳定在了 1.5,说明资源的使用量确实是限制住了的。

现在我们对 docker 容器实现了进程间资源隔离的黑科技有了一定认识。如果单单就隔离性来说,vagrant 也已经做到了。那么为什么是 docker 火爆全球?是因为它允许用户将容器环境打包成为一个镜像进行分发,而且镜像是分层增量构建的,这可以大大降低用户使用的门槛。
3. 存储
Image 是 Docker 部署的基本单位,它包含了程序文件,以及这个程序依赖的资源的环境。Docker Image 是以一个 mount 点挂载到容器内部的。容器可以近似理解为镜像的运行时实例,默认情况下也算是在镜像层的基础上增加了一个可写层。所以,一般情况下如果你在容器内做出的修改,均包含在这个可写层中。
3.1 联合文件系统(UFS)
Union File System 从字面意思上来理解就是“联合文件系统”。它将多个物理位置不同的文件目录联合起来,挂载到某一个目录下,形成一个抽象的文件系统。
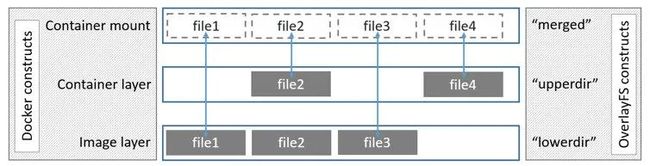
如上图,从右侧以 UFS 的视角来看,lowerdir 和 upperdir 是两个不同的目录,UFS 将二者合并起来,得到 merged 层展示给调用方。从左侧的 docker 角度来理解,lowerdir 就是镜像,upperdir 就相当于是容器默认的可写层。在运行的容器中修改了文件,可以使用 docker commit 指令保存成为一个新镜像。
3.2 Docker 镜像的存储管理
有了 UFS 的分层概念,我们就很好理解这样的一个简单 Dockerfile:
FROM alpine
COPY foo /foo
COPY bar /bar
在构建时的输出所代表的含义了。

但是使用 docker pull 拉取的镜像文件,在本地机器上存储在哪,又是如何管理的呢?还是来实际操作认证一下。在 devcloud 上确认当前 docker 所使用的存储驱动(默认是 overlay2):
docker info --format '{{.Driver}}'
以及镜像下载后的存储路径(默认存储在/var/lib/docker):
docker info --format '{{.DockerRootDir}}'
当前我的 docker 修改了默认存储路径,配置到/data/docker-data,我们就以它为例进行展示。先查看一下该目录下的结构:
tree -L 1 /data/docker-data
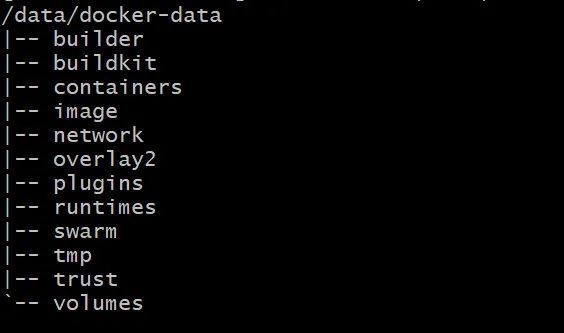
关注一下其中的 image 和 overlay2 目录。前者就是存放镜像信息的地方,后者则是存放具体每一分层的文件内容。我们先深入看一下 image 目录结构:
tree -L 2 /data/docker-data/image/
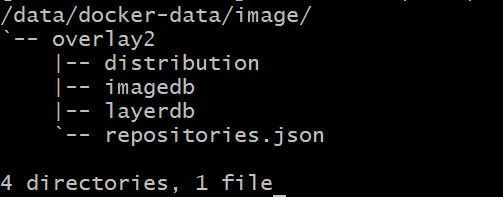
留心这个 imagedb 目录,接下来以我们以最新的 alpine 镜像为例子,看看 docker 是如何管理镜像的。执行指令:
docker pull alpine:latest

紧接着查看它的镜像 ID:docker image ls alpine:latest
记住这个 ID a24bb4013296,现在可以看一下 imagedb 目录下的变化:
tree -L 2 /data/docker-data/image/overlay2/imagedb/content/ | grep
a24bb4013296
![]()
多了这么一个镜像 ID 的文件,它是一个 json 格式的文件,这里包含了该镜像的参数信息:
jq .
/data/docker-data/image/overlay2/imagedb/content/sha256/a24bb4013296f61e89ba57005a7b3e52274d8edd3ae2077d04395f806b63d83e
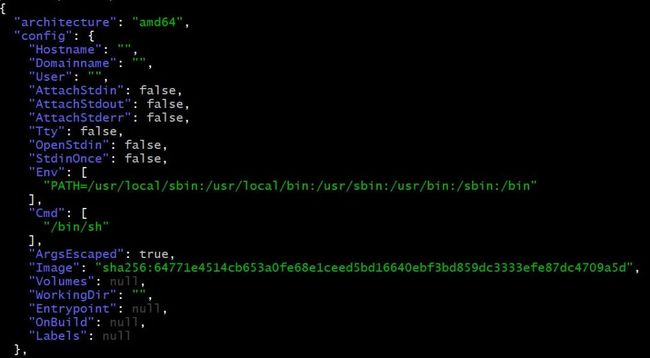
接下来我们看看将一个镜像运行起来之后会有什么变化。运行一个 alpine 容器,让它 sleep10 分钟:
docker run --rm -d alpine sleep 600
然后找到它的 overlay 挂载点:
docker inspect --format='{{.GraphDriver.Data}}' $(docker ps -ql) | grep MergedDir

结合上一节讲到的 UFS 文件系统,可以 ls 一下:
ls /data/docker-data/overlay2/74e92699164736980c9e20475388568f482671625a177cb946c4b136e4d94a64/merged
![]()
看到它就是合并后所呈现在 alpine 容器的文件系统。先进入到容器内:
docker exec -it $(docker ps -ql) sh
紧接着新开一个终端查看容器运行起来后跟镜像相比,有哪些修改:
docker diff $(docker ps -ql)

在/root 目录下,增加了 sh 的历史记录文件。然后我们在容器中手动增加一个 hello.txt 文件:
echo 'Hello Docker' > hello.txt

这时候来看看容器默认在镜像之上增加的可写层 UpperDir 目录的变化:
ls /data/docker-data/overlay2/74e92699164736980c9e20475388568f482671625a177cb946c4b136e4d94a64/diff
这就认证了 overlay2 驱动是将镜像和可写层的内容 merged 之后,供容器作为文件系统使用。多个运行的容器共用一份基础镜像,而各自有独立的可写层,节省了存储空间。
这个时候,我们也可以回答一下镜像的实际内容是存储在哪里呢:
cat /data/docker-data/overlay2/74e92699164736980c9e20475388568f482671625a177cb946c4b136e4d94a64/lower
查看这些分层:
ls /data/docker-data/overlay2/l/ZIIZFSQUQ4CIKRNCMOXXY4VZHY/
就是 UFS 中低层的镜像内容。
总结
这一次跟大家分享了 Docker 所使用的底层技术,包括 namespace,cgroups 和 overlay2 联合文件系统,着重介绍了隔离环境是如何在宿主机上演进实现的。通过实际手动操作,对这些概念有了真实的感受。希望下一次为大家再介绍 docker 的网络实现机制。
欢迎关注我们的视频号:腾讯程序员
最新视频:程序员的小黄鸭
腾讯技术官方交流微信群已经开放
进群添加微信:journeylife1900
(备注:腾讯技术)