postgresql-集合运算
postgresql-集合运算
- 简介
- UNION
- INTERSECT
- EXCEPT
- 分组与排序
- 集合操作优先级
简介
数据库中的表(table)本质上就是由行(row)组成的集合。因此,PostgreSQL 同样支持集
合论中的集合操作,包括并集(UNION)、交集(INTERSECT)和差集(EXCEPT):
UNION操作符用于将两个查询结果合并成一个结果集,返回出现在第一个查询或者出现
在第二个查询中的数据INTERSECT操作符用于返回两个查询结果中的共同部分,即同时出现在第一个查询结
果和第二个查询结果中的数据EXCEPT操作符用于返回出现在第一个查询结果中,但不在第二个查询结果中的数据
这三个操作符的作用如下图所示:

UNION
UNION 操作符用于将两个查询结果合并成一个结果集,返回出现在第一个查询或者出现在
第二个查询中的数据:
-- 语法
SELECT column1, column2
FROM table1
UNION [DISTINCT | ALL]
SELECT col1, col2
FROM table2;
其中,DISTINCT 表示将合并后的结果集进行去重;ALL 表示保留结果集中的重复记录;如
果省略,默认为 DISTINCT。例如
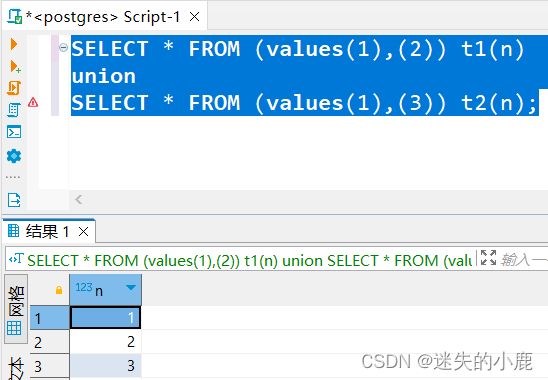
SELECT * FROM (values(1),(2)) t1(n)
union
SELECT * FROM (values(1),(3)) t2(n);
SELECT * FROM (values(1),(2)) t1(n)
union all
SELECT * FROM (values(1),(3)) t2(n);

第一个查询结果中只有一个数字 1,第二个查询结果中保留了重复的数字 1。
INTERSECT
INTERSECT 操作符用于返回两个查询结果中的共同部分,即同时出现在第一个查询结果和
第二个查询结果中的数据:
-- 语法
SELECT column1, column2
FROM table1
INTERSECT [DISTINCT | ALL]
SELECT col1, col2
FROM table2;
其中,DISTINCT 表示将合并后的结果集进行去重;ALL 表示保留结果集中的重复记录;如
果省略,默认为 DISTINCT。例如:
select * from (values(1),(2)) t1(n)
intersect
select * from (values(1),(3)) t2(n);


select * from (values(1),(1),(2)) t1(n)
intersect all
select * from (values(1),(1),(3)) t2(n);

第一个查询结果中只有一个数字 1;第二个查询虽然使用了 ALL 选项,结果也只有一个 1;
第三个查询结果中有两个 1。
EXCEPT
EXCEPT 操作符用于返回出现在第一个查询结果中,但不在第二个查询结果中的数据:
select column1, column2
from table1
except [distinct | all]
select col1, col2
from table2;
其中,DISTINCT 表示将合并后的结果集进行去重;ALL 表示保留结果集中的重复记录;如
果省略,默认为 DISTINCT。例如:
select * from (values(1),(1),(2)) t1(n)
except
select * from (values(1),(3)) t2(n);

select * from (values(1),(1),(2)) t1(n)
except all
select * from (values(1),(3)) t2(n);

第一个查询结果中没有数字 1;第二个查询结果中保留了一个数字 1。
分组与排序
对于分组操作,集合操作符中的每个查询都可以包含一个 GROUP BY,不过它们只针对各
自进行分组;如果想要对最终结果进行分组,需要在外层嵌套一个 SELECT 语句:
select n, count(*) from (
select * from (values(1),(2)) t1(n)
union all
select * from (values(1),(3)) t2(n)) t
group by n;

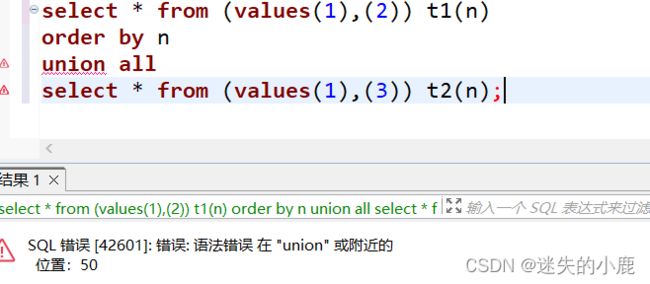
如果要对集合运算的数据进行排序,需要将 ORDER BY 子句写在最后;集合操作符中的第
一个查询中不能出现排序操作:
select * from (values(1),(2)) t1(n)
order by n
union all
select * from (values(1),(3)) t2(n);
集合操作优先级
PostgreSQL 支持同时使用多个集合操作符,此时我们需要注意它们的优先级:
SELECT column1, column2
FROM table1
UNION [DISTINCT | ALL]
SELECT col1, col2
FROM table2
INTERSECT [DISTINCT | ALL]
SELECT c1, c2
FROM table3;
多个集合操作符使用以下执行顺序:
- 相同的集合操作符按照从左至右的顺序执行;
INTERSECT的优先级高于UNION和EXCEPT- 使用括号可以修改集合操作的执行顺序。
以下示例使用了两个 UNION 操作符,其中一个增加了 ALL 选项:
select * from (values(1)) t1(n)
union all
select * from (values(1)) t2(n)
union
select * from (values(1)) t3(n);
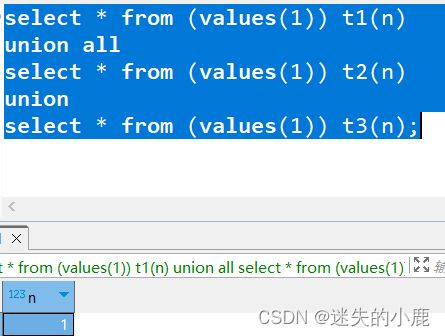
查询最终的结果只有一个数字 1,因为最后的 UNION 去除了重复的数据。
以下示例使用了两个不同的集合操作符:
select * from (values(1)) t1(n)
union all
select * from (values(1)) t2(n)
intersect
select * from (values(1)) t3(n);

查询最终的结果包含了两个数字 1,因为 INTERSECT 先执行,最后的 UNION ALL 保留了
重复的数据
最后看一个使用括号的示例:
(
select * from (values(1)) t1(n)
union all
select * from (values(1)) t2(n)
)
intersect
select * from (values(1)) t3(n);
