学术加油站|基于LSM-tree存储系统的内存管理,最大限度降低I/O成本
本文系北京理工大学科研助理牛颂登所著,本篇也是 OceanBase 学术系列稿件第 10 篇。欢迎访问 OceanBase 官网获取更多信息:https://www.oceanbase.com/

「牛颂登:北京理工大学科研助理,硕士期间在电子科技大学网络空间安全研究院从事聚类和强化学习相关算法研究,在应用聚类研究个性化在线学习和强化学习的奖励函数设计方向取得了一定成果,目前研究方向为机器学习和数据库相结合的领域。」
今天分享的论文是"Breaking Down Memory Walls in LSM-based Storage Systems. PVLDB, 14(3): 241-254, 2020. doi: 10.5555/3430915.3442425 "
希望阅读完本文,你可以对基于 LSM-tree 存储系统的内存管理有新的收获,当然也可以有不同看法,欢迎在底部留言探讨。
今天为大家带来的这篇论文是加州大学的陈罗博士 2020 年发表于 PVLDB 的一篇论文:主要内容是其提出了一种动态的基于 LSM-tree 的存储系统的内存管理结构,以及根据工作负载动态调节写内存和缓冲区缓存内存分配的调优器,并在 AsterixDB 上分别以不同工作负载模式对单 LSM-tree 和多 LSM-tree 下的内存管理和内存调优器进行了性能测试。
自适应的内存管理结构
LSM-tree 被广泛应用于现代 NoSQL 系统中,如 LevelDB、RocksDB、Cassandra、HBase、X-Engine、AsterixDB 等。与传统的就地更新结构不同,LSM-tree 采用了非就地更新设计:首先在内存中缓冲所有写入,它们随后被刷新到磁盘,以形成不可变的磁盘组件;磁盘组件被定期合并,以提高查询性能和回收废弃记录所占用的空间。与所有的页面都在共享缓冲池中管理的就地更新系统相比,LSM-tree 引入了额外的内存墙,这些内存墙是指各个内存区域之间阻碍有效内存共享的障碍。
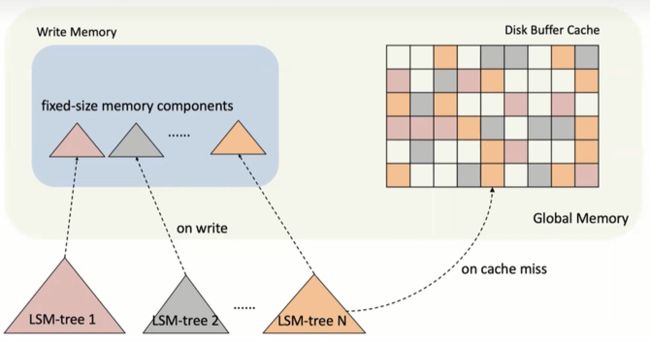
图1 基于 LSM-tree 的存储引擎结构
以图 1 为例,总内存被划分为存储内存组件的写内存和存储不可变页面的磁盘缓冲区缓存。在这样的一个结构中存在三道内存墙,首先是为内存组件被分配固定的大小,例如 RocksDB 为每个内存组件设置了大小为 64MB 的限制,而 AsterixDB 规定最大可写的数据集个数为 N 个(N 默认是 8),也就是说每个活跃的数据集只能得到 1/N 的总的写内存。这样做的好处是比较方便,而且一定程度上能保证鲁棒性[1],但因为固定或者平均分配不是最优的分配方法,因此可能对系统的性能有负面的影响。

图2 论文提出的自适应的内存管理结构
为了打破这三道内存墙,本文提出了一种自适应的内存管理结构,与前一种的不同体现在:
-
首先,不为每个内存组件设置大小限制,而是所有内存组件都是通过共享的内存池来管理的;
-
其次,根据不同的工作负载动态地将写内存的组件(即 SSTable 文件)进行刷盘操作,当 LSM-tree 没有足够的内存来存储传入的写操作时,将从池请求更多的页面,而当总体写内存使用过高时,将选择 LSM-tree 将其内存组件刷新到磁盘;
-
最后,论文提出的内存调优器可以自适应地调节写内存和缓冲区缓存的内存分配。
正是通过这样的结构有效地打破了前面的三道内存墙。
写内存管理
一、分区内存组件
使用新的内存管理结构,内存组件可以变得非常大,因为它的大小不受限制。现有的 LSM-tree 实现使用跳表或者 B+ 树来管理内存组件,并始终将内存组件完全刷新到磁盘。但是,这减少了内存的使用,原因有两个:
首先,因为 B+ 树的页面大约有 2/3 是满的,所以在使用时可更新的 B+ 树存在内部碎片;
其次,考虑一个很大的 memtable 对象被刷新到磁盘之后,内存释放出来,新的 memtable 在前一段时间内内存利用率都很低,这降低了随着时间推移的平均内存利用率。

图3 分区内存组件的LSM-tree结构
为了最大限度地利用内存,论文针对单个 LSM-tree 的内存组件提出使用内存分区的 LSM-tree 来管理写内存,即写内存也采用分层的方式。 如图 3 所示,可以分为 M0,M1 和 M2 三层,在 M0 处有一个活动的 SSTable 用于存储传入的写操作。当 M1 存满时,它的一个 SSTable 将使用内存合并到下一个层 M1。在选择合并的 SST 时,论文使用了一种贪婪选择策略,通过最小化在 M1 层重叠的 SSTable 的大小与所选的在 M0 处的 SSTable 的大小之间的比值来选择 SSTable 进行合并。
M2 层的内存 SSTable 最终被刷新到磁盘。对于内存组件存满所触发的刷新,M2 的 SSTable 将以循环方式刷新到磁盘。对于由事务日志长度过长所触发的刷新,使用最小日志序列号(Log Sequence Number,LSN)的 SSTable 将被刷新到磁盘。
这样的结构提高了内存利用率并降低了写入放大。首先,LSM-tree 比 B+ 树获得了更高的空间利用率;其次,由于所提的结构是范围分区的,它可以使用部分刷新,一次刷新一个内存 SSTable,从而使写内存始终保持满的状态。
二、多 LSM-tree 内存管理
在管理多个 LSM-tree 时,一个基本问题是如何将写内存分配给这些 LSM-tree。由于写内存是按需分配的,所以这个问题变成了如何选择要刷盘的 LSM-tree。对于日志触发的刷新,应该刷新 LSN 最小的 LSM-tree 以执行日志截断;对于内存触发的刷新,现有的 LSM-tree 实现(如 RocksDB 和 HBase)选择使用最大的内存组件刷新 LSM-tree。直观的感觉是,刷新这个 LSM-tree 可以回收最多的写内存,这些内存可以用于后续的写操作。但是,此策略可能不适合分区内存组件,因为由于部分 SSTable 刷新,刷新任何 LSM-tree 都将回收相同数量的写内存。
一种可选的方法是最小日志序列号策略,即每次选择最旧的 LSN 进行刷盘操作。这样做,LSM-tree 的刷新速率会与它的写入速率大致正比,而且比较热的 LSM-tree 会比较冷的 LSM-tree 更频繁地刷新。此外,当刷新是以日志触发型的刷新主导时,这样的策略还有助于日志截断。
论文提出了一种最优的刷盘策略,当给定 K 个 LSM-tree 的时候,写内存的分配可以被定义为一个最小化写成本的优化问题,即通过最小化第 i 个 LSM-tree 的写速率与每个条目大小的比值,乘上每个条目的写成本,这样一个式子来实现最优的写内存分配,如下式①所示。

其中 ai 为第 i 个 LSM-tree 的内存分配比,ri 为第 i 个 LSM-tree 的写速率,Ci 是每个条目的写 I/O 成本。而 Ci 可以通过初次写入日志时的成本和每次合并时产生的成本之和计算,如下式 ②:
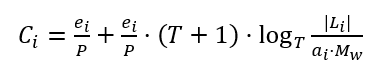
其中 ei 为条目大小,P 为磁盘页面大小,T 为合并策略的大小比,|Li | 为第 i 层的大小,Mw 为总的写内存大小。将②式带入①式,再由拉格朗日乘数法可得下方③式:
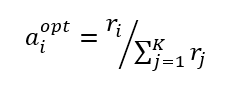
即第 i 个 LSM-tree 的最优内存分配比等于它的写速率占所有 LSM-tree 的写速率的比值。也就是说,分配给 LSM-tree 的写内存应该与它的写速率成正比,较热的 LSM-tree 相比于较冷的 LSM-tree 会获得更多的写内存。
三、内存管理方案评估
论文首先对提出的分区内存组件方法和最优刷盘策略进行了评估实验,采用的测试平台是 AsterixDB,基线分别是基于静态 B+ 树和动态 B+ 树的内存管理方法。静态的 B+ 树内存管理方法下,分为 AsterixDB 默认设置的活跃数据集个数为 8 的 B+ 树静态默认基线和每个实验下不同的活跃数据集个数 B+ 树静态调节基线。动态 B+ 树内存管理方法是指不为每个内存组件设置大小限制。刷新策略分别采用了最大内存、最小日志序列号的刷新策略和论文提的最优刷新策略,并在 YCSB 的不同读写比率的工作负载模式进行了实验。
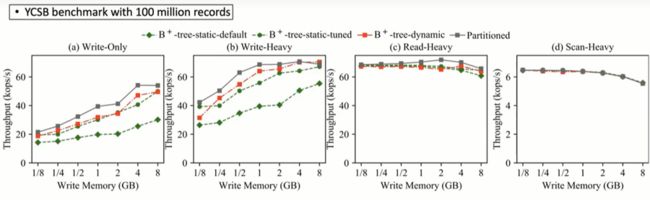
图4 单LSM-tree的内存组件实验评估结果
图 4 为在单个 LSM-tree 的内存管理对比实验,可以看到针对不同的工作负载,尤其是写入繁重的工作负载(图 4 b)下,由于分区内存组件方法更有效地利用写内存,对系统的性能提升最大。
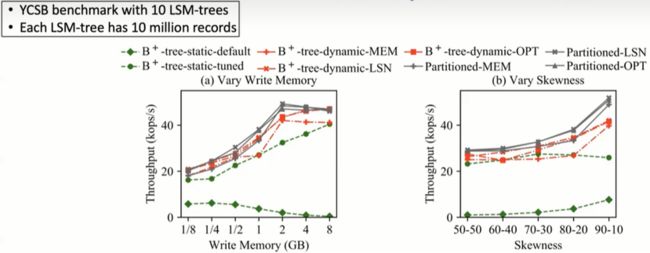
图5 多LSM-tree内存组件实验评估结果
图 5 为在多个 LSM-Tree 的对比实验下,最小日志序列号策略和最优刷新策略通过在 LSM - 树之间更好地分配写内存,提升了系统整体的吞吐量。
内存调优器
一、调优方法
内存调优器的目标是在写内存和缓冲区缓存之间找到最优的内存分配,以最小化每个操作的 I/O 成本,这反过来又可以最大限度地提高系统效率和总体吞吐量。假设总可用内存为 M,为了便于讨论,假设写内存大小为 x,这意味着缓冲区缓存大小为 M-x。设写内存为 x 时,write(x) 和 read(x) 是每次操作的写成本和读成本。调优目标是最小化每个操作的加权 I/O 成本,得到以下公式④:

这里的两个加权参数 ω 和 γ 允许用户针对不同的用例调整调优目标。例如,在机械硬盘上,因为 LSM-tree 主要使用顺序 I/ O 进行写操作,ω 可以设置得更小;而在固态硬盘上,因为 SSD 的写操作通常比读操作成本更大,ω 可以设置得更大些。由于最佳的内存分配依赖于所处的工作负载,因此论文中采用了在线调优方法来执行连续调优。通过对 cost(x) 进行求导得出了 write(x) 和 read(x) 的导数,并通过实时的统计影响 write(x) 和 read(x) 导数的一些量,来调节动态地内存的分配。
二、实际中的 I/O 成本
内存调优器的最优性取决于 cost(x) 的形状。为了确保内存调优器总是找到全局最小值,cost’(x) 应该最多有一个根。直观上,当分配的写内存的大小比较小的时候,会有大量的合并操作,合并成本会比较大,总的 I/O cost 也会比较大;而当分配的写内存大小非常大的时候,合并成本会相应减小,但是会增加缓存未命中(buffer cache miss),读的成本会增加,总的 I/O 成本也会增加。因此,一个最优的 x 应该平衡读和写的成本。
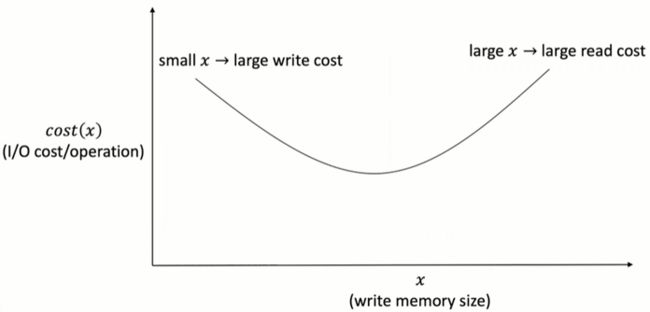
图6 操作的I/O成本受写内存的大小影响
论文通过实验发现许多实际工作负载的 cost(x) 通常允许内存调优器找到全局最小值。图 7 描绘了实验中 YCSB 写繁重工作负载(其中写和读的比重分别占 50%)和 TPC-C 工作负载的 I/O 成本。这些操作分布在 10 个 LSM-tree 中,每个 LSM-tree 有 1000 万条记录,遵循 80-20 热点分布。对于 TPC-C,比例因子设置为2000。可以看到,对于这两种工作负载,总 I/O 成本都有一个全局最小值。论文还通过改变总的内存大小和读写比率来评估其他配置,并发现总的 I/O 成本总是具有相同的总体形状。

图7 不同写内存大小下的I/O成本
三、性能评估
在所有实验中,初始写内存大小设置为 64MB,模拟缓存大小设置为 128MB。LSM-tree 有 1 亿条记录,总容量为 110GB。为了评估内存调优器的准确性,在 TPC-C 上进行了一组实验,以比较调优后的性能和最佳性能。这里使用 TPC-C,因为它比 YCSB 表示更复杂、更实际的工作负载。比例系数设定为 2000。因为对于用到的 SSD 写入的成本是读取的两倍,在实验中,设置写权值 ω 为 2,读权值 γ 为 1,以平衡这两个成本。
为了找到最优内存分配(称为 opt),使用穷尽搜索来评估不同的内存分配,增量为 128MB。为了显示内存调优器的有效性,实验包含了两个额外的基线。第一个基线(称为 64M)总是将写内存设置为 64MB,这是内存调优器的起点;第二个基线(称为 50%)在缓冲区缓存和写内存之间平均分配总的内存预算。总内存预算从 4GB 改为 20GB,每个实验运行 1 小时。图 8 显示了每个操作的加权 I/O 成本和不同内存分配的事务吞吐量。
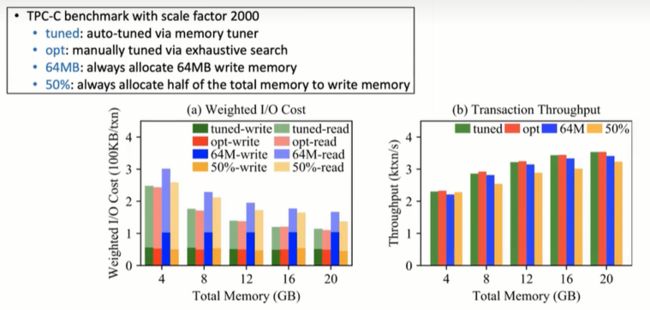
图8 TPC-C上的内存调优器性能评估
使用穷举搜索,论文发现最小化加权 I/O 成本也可以最大化事务吞吐量。自动调优的 I/O 成本和吞吐量(tuned)非常接近于通过穷举搜索找到的最优值,这表明了内存调优器的有效性。此外,内存调优器的性能明显优于两个基于启发式的基线。分配较小的写内存可以使读开销最小化,但会导致更高的写开销。相比之下,分配一个大的写内存可以使写开销最小化,但是读开销会增加很多。因此,这两种分配也不能最大化总体事务吞吐量。
结语
本论文提出可以促进自适应内存管理的 LSM 内存管理结构,通过分区内存组件结构和新的刷盘策略,以更好地利用写入内存;为了打破写内存和缓冲区缓存之间的内存墙,引入了内存调优器,它可以根据工作负载模式连续地调优内存分配。实验证明,通过这些技术一起支持自适应内存管理,以最大限度地降低了基于 LSM 的存储系统的 I/O 成本。
参考文献:
[1] Taewoo Kim, Alexander Behm, Michael Blow, et al. 2020. Robust and efficient memory management in Apache AsterixDB. Software: Practice and Experience 50, 7 (2020), 1114–1151.
欢迎访问 OceanBase 官网获取更多信息:https://www.oceanbase.com/