generative-model [What are Diffusion Models?]
目录
What are Diffusion Models?
Forward diffusion process
Connection with stochastic gradient Langevin dynamics
Reverse diffusion process
Parameterization of Lt for Training Loss
Connection with noise-conditioned score networks (NCSN)
Parameterization of
Parameterization of reverse process variance
Speed up Diffusion Model Sampling
Conditioned Generation
Classifier Guided Diffusion
Classifier-Free Guidance
Scale up Generation Resolution and Quality
Quick Summary
What are Diffusion Models?
Previous work's limitations:
-- GAN models are known for potentially unstable training and less diversity in generation due to their adversarial training nature.
-- VAE relies on a surrogate loss.
-- Flow models have to use specialized architectures to construct reversible transform.
Diffusion models are inspired by non-equilibrium thermodynamics. 非平衡热力学
他们定义了一个马尔可夫扩散步骤链,以缓慢地向数据添加随机噪声,然后学习逆转扩散过程以从噪声中构建所需的数据样本。与VAE或流动模型不同,扩散模型是通过固定程序学习的,并且潜在变量具有高维数(与原始数据相同)。
![generative-model [What are Diffusion Models?]_第1张图片](http://img.e-com-net.com/image/info8/f34d0cde12044ea6bd82ac950f9a3132.jpg)
Forward diffusion process
给定从真实数据分布中采样的数据点,让我们定义一个正向扩散过程,在该过程中,我们将少量高斯噪声添加到样品中,产生一系列嘈杂的样本;即通过缓慢添加(去除)噪声生成样品的正向(反向)扩散过程的马尔可夫链。
![generative-model [What are Diffusion Models?]_第2张图片](http://img.e-com-net.com/image/info8/5ff53b6ead0140599bf2cd2a2e2aa70e.jpg)
![generative-model [What are Diffusion Models?]_第3张图片](http://img.e-com-net.com/image/info8/86d3d42bea24498ea4fc9fc715087414.jpg)
Connection with stochastic gradient Langevin dynamics
朗格文动力学是物理学中的一个概念,用于对分子系统进行统计建模。结合随机梯度下降,随机梯度Langevin dynamics(Welling & Teh 2011)可以从概率密度产生样本p(x) 仅使用渐变在马尔可夫更新链中:
![generative-model [What are Diffusion Models?]_第4张图片](http://img.e-com-net.com/image/info8/566c250c17044e61bf34f3e2596151f9.jpg)
Reverse diffusion process
逆转上述过程并从中采样,就能从高斯噪声输入中重新创建真实样本
![generative-model [What are Diffusion Models?]_第5张图片](http://img.e-com-net.com/image/info8/1625c08553a2474e9e76fbbddaec5b9c.jpg)
Parameterization of Lt for Training Loss
我们需要学习一个神经网络来近似反向扩散过程中的条件概率分布,我们想训练μ,因为Xt在训练时可作为输入,我们可以重新参数化高斯噪声项以使其预测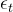 从输入Xt在时间步长t:
从输入Xt在时间步长t:
![generative-model [What are Diffusion Models?]_第6张图片](http://img.e-com-net.com/image/info8/81f30c3f0345489381a3435635750900.jpg)
![generative-model [What are Diffusion Models?]_第7张图片](http://img.e-com-net.com/image/info8/7cc294cdde5e4fa0ab8c370739c0067b.jpg)
Connection with noise-conditioned score networks (NCSN)
![generative-model [What are Diffusion Models?]_第8张图片](http://img.e-com-net.com/image/info8/8d50b517e6644082bfc309258b5ecd47.jpg)
Parameterization of 
![generative-model [What are Diffusion Models?]_第9张图片](http://img.e-com-net.com/image/info8/7df59d292b7e40e3bb204e9145c67576.jpg)
Parameterization of reverse process variance 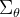
![generative-model [What are Diffusion Models?]_第10张图片](http://img.e-com-net.com/image/info8/24551000a8cf469abb13b4b9c5dce604.jpg)
Speed up Diffusion Model Sampling
![generative-model [What are Diffusion Models?]_第11张图片](http://img.e-com-net.com/image/info8/917f3081a7fc42adaf0d5e0b8fb97da8.jpg)
与DDPM相比,DDIM能够:
- 使用更少的步骤生成更高质量的样本。
- 具有“一致性”属性,因为生成过程是确定性的,这意味着以同一潜在变量为条件的多个样本应该具有类似的高级特征。
- 由于一致性,DDIM 可以在潜在变量中执行语义上有意义的插值。
![generative-model [What are Diffusion Models?]_第12张图片](http://img.e-com-net.com/image/info8/7b1b6795462448bd9063ed4a1d933c94.jpg)
Conditioned Generation
在具有条件信息(如 ImageNet 数据集)的图像上训练生成模型时,通常会生成以类标签或一段描述性文本为条件的样本。
Classifier Guided Diffusion
![generative-model [What are Diffusion Models?]_第13张图片](http://img.e-com-net.com/image/info8/01376a5653ce42b6a180c139412007f6.jpg)
![generative-model [What are Diffusion Models?]_第14张图片](http://img.e-com-net.com/image/info8/f723a74271284bbaad10708cfa845334.jpg)
Classifier-Free Guidance
![generative-model [What are Diffusion Models?]_第15张图片](http://img.e-com-net.com/image/info8/7ce24a2723174a398332e6a175b7db6f.jpg)
Scale up Generation Resolution and Quality
![generative-model [What are Diffusion Models?]_第16张图片](http://img.e-com-net.com/image/info8/276fa4f90ff146138436adcc829c8491.jpg)
他们发现最有效的噪声是在低分辨率下应用高斯噪声,在高分辨率下应用高斯模糊。
此外,他们还探索了两种需要对训练过程进行小幅修改的调理增强形式。
请注意,条件反射噪声仅适用于训练,不适用于推理。
![generative-model [What are Diffusion Models?]_第17张图片](http://img.e-com-net.com/image/info8/10b5b83cb9ea439eb208bf8422997608.jpg)
![generative-model [What are Diffusion Models?]_第18张图片](http://img.e-com-net.com/image/info8/e9f64d8e7c0b4ecca7cad0aade4e87ed.jpg)
Quick Summary
Pros: Tractability and flexibility are two conflicting objectives in generative modeling. Tractable models can be analytically evaluated and cheaply fit data (e.g. via a Gaussian or Laplace), but they cannot easily describe the structure in rich datasets. Flexible models can fit arbitrary structures in data, but evaluating, training, or sampling from these models is usually expensive. Diffusion models are both analytically tractable and flexible
优点:可处理性和灵活性是生成建模中两个相互冲突的目标。可处理的模型可以进行分析评估和廉价拟合数据(例如通过高斯或拉普拉斯),但它们不能在丰富的数据集中轻松描述结构。灵活的模型可以适应数据中的任意结构,但从这些模型中评估、训练或采样通常成本高昂。扩散模型在分析上既易于处理又灵活
Cons: Diffusion models rely on a long Markov chain of diffusion steps to generate samples, so it can be quite expensive in terms of time and compute. New methods have been proposed to make the process much faster, but the sampling is still slower than GAN.
缺点:扩散模型依赖于长马尔可夫扩散步骤链来生成样本,因此在时间和计算方面可能非常昂贵。已经提出了新的方法来使该过程更快,但采样仍然比GAN慢。
笔记摘自Lil'Log--【写的真好啊 respect】
What are Diffusion Models? https://lilianweng.github.io/posts/2021-07-11-diffusion-models/#speed-up-diffusion-model-sampling
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/#speed-up-diffusion-model-sampling