Android-关于页面卡顿的排查工具与监测方案
作者:一碗清汤面
前言
关于卡顿这件事已经是老生常谈了,卡顿对于用户来说是敏感的,容易被用户直接感受到的。那么究其原因,卡顿该如何定义,对于卡顿的发生该如何排查问题,当线上用户卡顿时,在线下无法复现时,又如何获取信息来定位问题?
什么是卡顿
一般来说, 12FPS (每秒显示帧数)为最低标准,低于 12fps 画面基本上就不是连续的,而当大于 60FPS 时,人眼很难区分出来明显的变化,所以 60FPS 是衡量一个界面流畅程度的重要指标。但 FPS 低并不意味着卡顿发生,而卡顿发生 FPS 一定不高,而是以一段时间内的掉帧程度来衡量的。
假设按照 60FPS 来说, 一帧的时间为 1000ms/60 = 16.6667ms,如果某次掉帧严重,导致 1000ms 内 FPS 极低,那么就会造成画面卡住的现象。
卡顿排查工具
排查卡顿的工具有很多,大部分分为两种类型:
instrument:获取一段时间内所有函数的调用过程,可以通过分析这段时间内的函数调用流程,再进一步分析待优化的点。
sample:有选择性或者采用抽样的方式观察某些函数调用过程,可以通过这些有限的信息推测出流程中的可疑点,然后再继续细化分析。
1. CPU Profiler
CPU Profiler 是 Android Studio 自带的工具,可以查看 CPU、内存、网络和电池资源的使用情况。它可以以图形的形式展示执行时间、调用栈,而且信息全面包含所有线程,我们可以通过 Debug 类的方法来检测区间的代码:
Debug.startMethodTracing("xxx");
...
Debug.stopMethodTracing();
最终会在 sd 卡的 Android/data/packagename/files 文件夹下生成一个 xxx.trace 文件。通过 AS 解析我们可以看到这段时间内函数的调用以及耗时,帧率情况,CPU 的情况以及其他线程的情况,我们可以分析到具体的位置来调整,例如:

但是工具本身会带来很大的性能开销,所以有时无法反映真实的情况。
2. Systrace
systrace 是 Android 4.1 新增的性能分析工具, systrace 利用了 Linux 的ftrace调试工具,相当于在系统各个关键位置都添加了一些性能探针,也就是在代码里加了一些性能监控的埋点。Android 在 ftrace 的基础上封装了atrace,并增加了更多特有的探针,例如 Graphics、Activity Manager、Dalvik VM、System Server 等。 systrace 工具只能监控特定系统调用的耗时情况,它是属于 sample 类型,而且性能开销非常低。但是它不支持应用程序代码的耗时分析,所以在使用时有一些局限性。
使用方法:
systrace.py -t 10 sched gfx view wm am app webview -a com.example.android_kt_wandroid
它也可以使用代码的方式插桩到方法前后进行分析:
Trace.begainSection(name);
...
Trace.endSection(name);
使用 systrace 工具会生成一份 .systrace 文件,我们可以在 Chrome 浏览器输入 chrome://tracing Load文件,它同样可以看 cpu,frame,thread 的一些情况:

通过右侧的 Alerts 可以提示一些掉帧的建议。

小结一下:无论使用哪种卡顿监控工具,最后我们都可以得到卡顿时的堆栈和当时 CPU 运行的一些信息。大部分的卡顿问题都比较好定位,例如主线程执行一个耗时任务、读一个非常大的文件或者是执行网络请求等。
卡顿监测方案
有些时候我们根本使不上上述几个工具,比如某用户反馈 xxx 页面 xxx 时卡的一批,等我实际去按用户所述的步骤操作时,整个流程十分流畅,所以我们是需要用户卡顿时的一些信息,比如用户的系统版本、CPU 负载、网络环境、应用数据等,脱离这个现场,我们本地难以复现,也就很难去解决问题。
1.消息队列
这种方式依赖主线程 Looper,监控每次 dispatchMessage 的执行耗时,BlockCanary 就是这样实现的
public static void loop() {
...
for (;;) {
...
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
...
}
}
主线程所有的任务都是在 dispatchMessage(msg) 方法中执行完成,那我们通过自定义 Printer,在 dispatchMessage(msg) 前后分别记录时间,并且在此之前通过另外一个线程通过 Thread#getStackTrace 接口,一直获取主线程执行堆栈信息并记录起来,当 dispatchMessage(msg) 超过一个阈值时,我们就通知另一个线程获取堆栈信息来做分析。
2.Choreographer
这种方式依赖 Choreographer 模块,我们知道, Android 系统每隔 16ms 发出 VSYNC 信号,来通知界面进行重绘、渲染,每一次同步的周期为 16.6ms,代表一帧的刷新频率。SDK 中包含了一个相关类,以及相关回调。理论上来说两次回调的时间周期应该在 16ms,如果超过了 16ms 我们则认为发生了卡顿,利用两次回调间的时间周期来判断是否发生卡顿。
我们可以在 Choreographer 模块注册一个 FrameCallback 监听对象,同时通过另外一条线程循环记录主线程堆栈信息,并在每次 Vsync 事件 doFrame 通知回来时,循环注册该监听对象,间接统计两次 Vsync 事件的时间间隔,当超出阈值时,取出记录的堆栈进行分析。
3.插桩
上述的两种方式都要单开一个线程记录方法堆栈会占用系统资源,其次有时会出问题,因为正在运行的函数有可能并不是真正耗时的函数。
例如:假设一次消息循环执行了三个函数,整个消息执行为 3000ms,由于函数 A (1500ms) 和函数 B (1000ms) 已经执行完毕,我们得到的函数 C (500ms) 并不耗时,因此我们需要拿到每个函数的耗时。
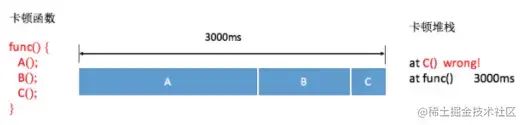
我们可以通过自定义 transform 在编译期拿到所有的 class 文件,通过 ASM 工具在所有的方法前后进行插桩,在运行时检测到卡顿后取出方法信息。
//插桩前
void func(){
dosomething();
}
//插桩后
void func(){
Trace.i(x);
dosomething();
Trace.o(x);
}
但是也会有很多细节和优化的点:
- 避免方法数暴增。在函数的入口和出口应该插入相同的函数,在编译时提前给代码中每个方法分配一个独立的 ID 作为参数。
- 过滤简单的函数。过滤一些类似直接 return、i++ 这样的简单函数,并且支持黑名单配置。对一些调用非常频繁的函数,需要添加到黑名单中来降低整个方案对性能的损耗。
- 优化编译期的耗时。可以通过线程池以异步的方式插桩,结合 Future。
- 运行时存储方法信息的方式。将方法信息以 int 值保存,类似于 MeasureSpec 的设计。
微信的开源项目 matrix 中 Trace Canary 模块已经解决上述问题,感兴趣的可以看下源码。
总结
到此我们了解了几种卡顿监控的方法,已经可以解决我们的部分问题,其实很多时候卡顿问题并不难解决,相较解决来说,更困难的是如何快速发现这些卡顿点,以及通过更多的辅助信息找到真正的卡顿原因。
为了帮助到大家更好的全面清晰的掌握好性能优化,准备了相关的学习路线以及核心笔记(还该底层逻辑):https://qr18.cn/FVlo89

性能优化核心笔记:https://qr18.cn/FVlo89
启动优化

内存优化

UI优化

网络优化

Bitmap优化与图片压缩优化:https://qr18.cn/FVlo89

多线程并发优化与数据传输效率优化
体积包优化

《Android 性能监控框架》:https://qr18.cn/FVlo89
《Android Framework学习手册》:https://qr18.cn/AQpN4J
- 开机Init 进程
- 开机启动 Zygote 进程
- 开机启动 SystemServer 进程
- Binder 驱动
- AMS 的启动过程
- PMS 的启动过程
- Launcher 的启动过程
- Android 四大组件
- Android 系统服务 - Input 事件的分发过程
- Android 底层渲染 - 屏幕刷新机制源码分析
- Android 源码分析实战
- ……
