【日积月累】后端刷题日志
刷题日志
-
-
- 说说对Java的理解
- JAVA中抽象类和接口之间的区别
- Java中的泛型
- == 和equals()的区别
- 八种基本数据类型与他们的包装类
- 在一个静态方法内调用一个非静态成员为什么是非法的
- 静态方法与实例方法有何不同
- 重载与重写
- 深拷贝浅拷贝
- 面向过程与面向对象
- 成员变量与局部变量
- Spring框架
- Spring的优势
- Spring,SpringMVC,SpringBoot之间的区别
- SOFABoot,SpringBoot之间的区别
- Spring Bean支持的作用域
- Spring容器的启动过程
- Spring Bean的生命周期
- Spring框架的 单例Bean是否是线程安全的
- Spring框架使用了哪些设计模式
- SpringMVC的优点是什么
- SpringMVC工作流程
- SpringMVC九大内置组件
- SpringBoot中的starter
- Spring的事务的实现原理
- Spring的事务什么时候会失效
- Spring的事务隔离级别
- Spring的事务传播机制
- Sring StringBuffer StringBuilder
- 泛型中super和extend的却别
- == 和 equals的区别
- 重载和重写的区别
- List和Set的区别
- ArrayList和LinkedList的区别
- 深拷贝和浅拷贝
- jdk1.7 1jdk1.8 的HashMap区别
- HashMap的put方法
-
说说对Java的理解
- 难度 ※
- 薪水 ※
JAVA具有三大特征,相辅相成,分别是封装继承与多态。
封装:在不影响使用的情况改变了类的数据结构,保护了数据,增加了代码的可维护性以及便于修改,增加了复用性。
继承:子类继承父类的一些特征,增强代码的复用性。
多态:最难最重要,一是继承,二是重写,三是父类引用指向子类对象,增加了代码的灵活性,可移植性。
JAVA中抽象类和接口之间的区别
- 难度 ※ ※
- 薪水 ※ ※
从两个方面描述,一是语法方面:
抽象类可以定义构造器而接口不能;
抽象类可以有抽象方法和具体方法,而接口全都是抽象方法
抽象类中成员可以是privatte ,default ,protected,public,而接口中成员全都是public
抽象类中的成员全都是成员变量,而接口中定义的成员变量实际都是常量
有抽象方法的类必须呗声明为抽象类,而抽象类未必要有抽象方法
抽象类可以包含静态方法,接口中不能有静态方法
一个类只能继承一个抽象类,但可以实现多个接口
语义:人类社会中既有概念的为抽象类,而接口描述是某些事务之间共有的概念
抽象是is 接口是can
Java中的泛型
从JDK1.5提供的一个在编译时检测类型安全的机制,本质就是参数化类型,给类型指定一个参数,在使用时在指定此参数的具体值,可以用在类,接口和方法中。
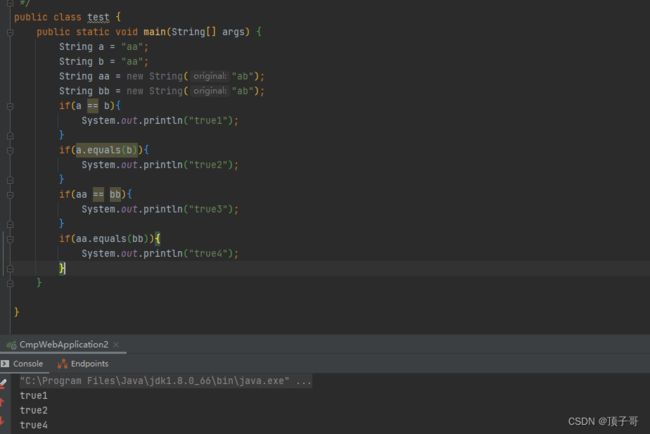
== 和equals()的区别
在比较基本数据类型时 == 比较的是值,在比较引用类型时,== 比较的是引用地址
equals不能判断基本数据类型的变量,只能判断两个对象是否相等,equals()方法存在与Object类中,如果没有被重写,则会比较对象,如果被重写,例如String类中,equals()方法是逐个比较string中的字符是否相等.
== 在引用类型中比较引用地址 鄋 aa==bb false
八种基本数据类型与他们的包装类
byte short int long float double char boolean
1 2 4 8 4 8 1 1 字节 == 8bit位
Byte Short Integer Long Float Double Character Boolean
拆箱与装箱 基本数据类型与为包装类之间的转换
Byte Short Int Long这四种包装类默认创建类述职[-128,127]的相应类型的缓存数据
比较整形包装类对象之间的比较都用equals() 强制
题目
Integer i1= 40;
Integer i2 = new Integer(40);
System.out.println(i1==i2);
Integer i1= 40; 这一步发生了装箱,由于Integer 会默认创建范围-128到127的缓存数据,所以这一步i1使用的是常量池中的对象
Integer i2 = new Integer(40); 这一步是创建了一个新的 Integer对象
== 对于非基本数据类型的对象,比较的对象的引用地址,所以结果是false
在一个静态方法内调用一个非静态成员为什么是非法的
1.静态方法是属于类的,在类加载时就会分配内存,可以通过类名直接访问
2.而非静态成员属于实例对象,只有在对象实例化后才存在,然后通过实例化后的对象去访问
3.所以在类的非静态成员不存在时,静态成员就已经存在,调用一个不存在的成员是非法的。
静态方法与实例方法有何不同
1.静态方法可以通过 类名+方法名 或者 对象名+方法名来调用
2.而实例方法只能通过对象名+方法名来调用,也就是说调用静态方法无需创建对象
3.静态方法只能访问静态成员,包括静态成员变量 静态成员方法,不能访问实例成员变量和实例成员方法 而实例方法则么样限制
重载与重写
重载 overload 发生在编译时,在同一个类里,方法名相同,参数列表不同,返回值和访问修饰符可以不同
重写 override 发生在运行时,在子类和父类,方法名,参数列表相同,子类方法的返回值类型,子类方法抛出的异常都要比父类方法更小或相等;子类方法的访问修饰符要大于父类方法;如果父类方法被 private/static/final 修饰则不可重写;如果方法返回类型是void和基本数据类型,则返回值重写时不可修改,如果是引用类型,重写可以返回该引用类型的子类
深拷贝浅拷贝
浅拷贝:对于基本数据类型进行值传递(拷贝它的值),对于引用类型进行引用(地址)传递(拷贝它的引用地址)
深拷贝:对于基本数据类型进行值传递,对于引用数据类型,创建一个新的对象,并复制其内容,此时拷贝对象和被拷贝对象的引用地址完全不同
面向过程与面向对象
面向过程性能比较高
面向对象易维护,易扩展,易复用,灵活性高,具有继承,多态,封装特性,可以设计出低耦合系统。
Java是半编译语言,最终的执行代码无法直接在cpu上执行(需要有java环境),而面向过程的代码大多是可以直接编译成机械码在电脑上执行。
成员变量与局部变量
成员变量时属于类的,可以被 public private static等修饰符修饰
局部变量由方法中的变量或参数定义,不能被static修饰
成员变量和局部变量都能被final修饰
------------------------------------------------------------------------------------------Spring-------------------------------------------------------------------------------------
Spring框架
- Spring是一个轻量级的容器框架,容器:包含并管理应用对象的生命周期,spring是桶,对象是水
- Spring是为了简化企业开发而生的,使得开发变得更加优雅和简洁
- Spring最显著的两个特点是AOP和IOC
IOC即控制反转,由于自己来创建控制对象比较麻烦,所以可以把对象的创作控制权交给Spring来管理,可以通过AutoWride和resource来进行注入,IOC是一种思想,DI是一种实现的具体方式。
AOP即面向切面编程,对代码的一部分进行切割,在不改变原有代码的情况下对代码进行一个增强,一般使用jdk和cglib动态代理来实现,一般用作处理日志,事务配置等。
Spring的优势
- Spring通过DI,AOP和消除样板式代码来简化企业级开发(Spring的IOC和AOP)
- Spring拥有庞大的生态,它将Spring扩展到了不同的领域,如Web服务,移动开发,REST,NOSQL等(Spring)
- Spring代码相对独立,污染极低(Spring)
- Spring独立于应用服务器,可以做到一次写,多出用 Write Once Run Anywhere(Spring)
- Spring的IOC容器降低了业务对象替换的复杂性,提高了组件之间的解耦(Spring的IOC)
- Spring的AOP允许将一些通用任务,例如安全,事务,日志等进行集中式处理。从而提供了更好的复用(Spring的AOP)
- Spring的ORM和DAO提供了与第三方持久层框架的良好整合,并简化了底层数据库的访问,也可通过它的核心包直接访问(Spring的ORM)
- Spring的高度开放性,并不强制应用完全依赖Spring,开发者可自由选用Spring框架的部分或全部(Spring)
Spring,SpringMVC,SpringBoot之间的区别
Spring是一个一站式的轻量级java开发框架,底层支撑,全栈的一个框架,针对于开发的WEB层(SpringMVC),业务层(IOC),持久层(jdbcTemplate)等都提供了多种配置和解决方案
SpringMVC是一个WEB框架,是一个基于Servlet的一个MVC框架,通过XML配置,统一开发前端视图和后端逻辑
SpringBoot是一个脚手架,并且相对于SpringMVC,SpringBoot简化路配置流程,SpringBoot更专注于单体微服务接口的开发和前端解耦。
SOFABoot,SpringBoot之间的区别
- SOFABoot相对于SpringBoot提供了基于Spring的上下文隔离和模块化开发能力,使得每个SOFABoot模块独立使用Spring上下文,避免不同SOFABoot模块间的冲突
- 增加模块并行加载和Spring Bean异步初始化能力,加速了应用的启动速度
- 日志空间隔离,避免中间件和应用日志绑定
- 增加基于SOFAArk的类隔离能力,方便解决类冲突问题
- 扩展SpringBoot健康检查,额外提供了Readiness Check 能力 保证应用实例安全上线
- 增加中间件集成管理能力,每一个SOFA中间件都是独立可插拔的组件
Spring Bean支持的作用域
Spring默认是单例Bean,在容器中有且仅有一个对象
- singleton:使用该属性创建Bean实例,IOC容器每次返回的是同一个Bean实例
- prototype:使用该属性创建Bean实例,IOC容器每次返回的是一个新的Bean实例
- request:该属性进队HTTP请求产生作用,使用该属性创建Bean实例时,每次HTTP请求都会创建一个新的Bean,适用于WebApplicationContext环境
- session:该属性仅用于HTTP Session ,同一个Session共享一个Bean实例,不同Session使用不同的Bean实例
- global-session:该属性仅用于HTTP Session,所有的Session共享一个Bean实例。
Spring容器的启动过程
- 进行扫描,得到所有BeanDefinition对象,并存入一个Map中
- 然后筛选出所有非懒加载的单例BeanDefinition创建Bean(对于多例Bean和懒加载的单例Bean则会在每次获取Bean时去创建它)
- 利用BeanDefiniton创建Bean就是Bean的生命周期,期间包括了BeanDefinition合并,推断构造方法,实例化,属性填充,初始化前,初始化,初始化后等步骤
- 单例Bean创建完之后,Spring就会发布一个容器启动事件
- 容器启动结束
Spring Bean的生命周期
Spring Bean的生命周期可以利用Bean存活期间指定时刻完成一些相关操作,一般是在Bean初始化后和销毁执行前的一些操作
Spring容器可以创建并管理singleton作用域的Bean实例,而对于prototype作用域的Bean只负责创建Bean实例,接着Bena实例就交给客户端管理,Spring容器不再参与。
- Bean定义 BeanDefinition
- 实例化 Instantiation
- 属性赋值 populate
- 初始化 initialization
- 销毁 destruction
BeanDefinition
↓
通过InstantiationAwareBeanPostProcessor.postProcessorBeforeInstantiation()方法
进行实例化预处理
↓
实例化 Instantiation
↓
通过InstantiationAwareBeanPostProcessor.postProcessorAfterInstantiation()方法
实例化后处理
↓
通过InstantiationAwareBeanPostProcessor.postProcessorProperties()方法
实例化后处理,设置属性前调用
↓
设置属性Populate IOC注入(DI 依赖注入 Dependency Injection)
↓
如果当前Bean实现了BeanNameAware接口,会调用setBeanName()方法
如果当前Bean实现了BeanFactoryAware接口,会调用setBeanFactory()方法
如果当前Bean实现了ClassLoaderAware接口,会调用setBeanClassLoader()方法
如果实现类*.Aware接口,就会调用相关方法
↓
通过BeanPostProcessor.postProcessBeforeInitialization()方法
初始化前置处理
↓
如果实现类Initialition接口,会调用afterPropertiesSet()方法
↓
初始化Initialition init-method属性设置的初始化方法
↓
通过BeanPostProcessor.postProcessAfterInitialization()方法
初始化后置处理
↓
对于singletonBean,返回Bean给用户,放入缓存池
对于prototypeBean ,返回Bean给用户,剩下生命周期由用户控制
↓
销毁Destroction destory-method属性设置的销毁方法
如果有实现DisponsableBena接口,会调用destory()方法

总结:
- Bean定义
- Bean实例化(会有实例化前后置处理,调用postProcessorBefore/After Instantiation方法)
- Bean的属性注入(如果实现了相关的Aware接口,就调用相关接口,如BeanNameAware,BeanFactoryAware,BeanClassLoeader)
- Bean的初始化(执行initialization-method属性设置的方法,会有初始化的前后置处理,调用postProcessorBefore/After Initialization,对于单例Bean会返回给用户,放入缓存池,对于多例Bean,也会返回给用户,剩下生命周期由用户执行)
- Bean的销毁(执行destory-method属性设置的方法,如果实现类Disponseable接口,会调用destory方法)
参考文章:一文读懂 Spring Bean 的生命周期
Spring框架的 单例Bean是否是线程安全的
单例Bean每次创建返回的都是同一个对象,线程不安全。
Spring中对象默认是单例的,框架并没有对bean多线程进行封装处理。
要保证线程安全最简单的方式的把Bean的作用域编程prototype,这样每次创建的返回的都是新的对象来保证线程安全。
在使用的时候不要再bean中声明任何有状态的实例变量或者类变量,有状态就是有数据存储的功能。如果必须创建,可以通过创建ThreadLocal把变量编程线程私有,如果bean的实例变量或者类变量需要在多个线程之间贡献,那么只能通过synchronized,lock,cas等方法实现线程同步。但由于有加锁,会导致执行比较慢。
Spring框架使用了哪些设计模式
tips:23中设计模式:单原生双工,桥组装适享外代,观模职命状,备迭访中解策
- 工厂模式 BeanFactory就是一种工厂模式的体现,用来创建对象实例
- 模板方法 解决代码重复性问题 如RestTemplate,JDBCTemplate
- 观察者模式 一对多的依赖关系,监听器 Spring中的listener
- 代理模式 Spring中AOP用到了JDK的动态代理和cglib的字节码技术
- 单例模式 单例Bean
SpringMVC的优点是什么
SpringMVC是一个以Servlet为基础的MVC框架,好处就是分层设计 模型视图控制,前端视图展示和后端逻辑分层处理,有利于业务系统的扩展性和可维护性,可以并行开发,提升效率。
SpringMVC工作流程
画图。。。
1.用户发起请求到DispatcherServlet
2.DispatcherServlet发起请求Handler到HandlerMapping
3.HandlerMapping返回处理器执行链HandlerExcutionChain
4.DispatcherServlet向HandlerAdapter(处理器适配器)请求执行Handler
5.HandlerAdapter向Handler(处理器)执行Handler
6.Handler返回ModelAndView给HandlerAdapter
7.HandlerAdapter返回ModelAndView给DispatcherServlet
8.DispatcherServlet向ViewResolver(试图解析器)发起试图解析请求
9.ViewResolver向DispatcherServlet返回View对象
10.DispatcherServlet通过向JSP,freemaker前端模板进行页面渲染,填充数据
11.DispatcherServlet返回给用户
SpringMVC九大内置组件
HandlerMapping
HandlerAdapter:调用Handler,HandlerAdapter是工人,Handler是工具
HandlerExceptionResolver 对异常的处理
ViewResolver
RequestToViewNameTranslator
LocaleResolver
ThemeResolver
MultipartResolver
FlasMapManager
SpringBoot中的starter
starter就是一个jar包,开发人员只需要将starter包依赖进应用中,进行相关属性配置,就可以进行代码开发,而不需要单独进行bean对象的配置。
Spring的事务的实现原理
在使用Spring时,可以有两种事务的实现方式,一种是编程式事务,即用户通过代码来控制事务的逻辑处理,还有一种是声明式事务,通过@Transactional注解来实现,当添加这个注解之后,事务的自动提交功能就会关闭,由spring框架来帮助进行控制。
事务操作是AOP的一个核心体现,通过动态代理来实现。在实际应用中,一般是通过给方法添加**@Transactional注解,添加注解后,spring会基于该类生成一个代理对象(通过jdk或者cglib),会将这个代理对象作为,当使用这个代理对象的方法时,如果有事务处理,会先把自动提交给关闭掉,然后再去实现具体的业务逻辑,如果执行逻辑没有出现异常,那么spring框架会把当前事务直接提交,如果出现任何异常情况,那么直接进行回滚**操作,用户可以控制对那些异常进行回滚提交。
TransactionInterceptor 关键对象
Spring的事务什么时候会失效
1.bean对象没有呗spring容器管理(自己创建了对象,没有配置)
2.方法的访问修饰符不是public
3.自身调用问题(没有走AOP的代理过程,同一个类中方法的相互调用this)
4.数据库不支持事务()
5.数据源没有配置事务管理器
6.异常被捕获
7.异常类型错误或配置错误
Spring的事务隔离级别
和数据库里支持的隔离级别一抹一眼
读未提交
读已提交
可重复读
串行化
在进行配置,如果spring和数据库隔离级别不同,以spring为主。
Spring的事务传播机制
spring中存在七种传播特性
- REQUIRED:默认的传播特性,如果没有事务,则新建一个事务,如果存在事务,则加入这个事务
- SUPPORTS:当前存在事务,则加入事务,如果没有事务,则已非事务的方式执行
- MANDATORY:当前存在事务,则加入事务,如果没有事务,则抛出异常
- REQUIRED_NEW:创建一个新事物,如果存在当前事务,则挂起该事务
- NOT_SUPPORTED:以非事务方式执行,如果当前执行事务,则挂起当前事务
- NEVER:如果当前事务存在,则抛出异常
- NESTED:如果当前存在事务,则在嵌套事务中执行,否则新建一个事务
=========================================================================================================
Sring StringBuffer StringBuilder
Sring 是final修饰的 表示常量
StringBuffer 是线程安全的,可修改的 被synchronized,性能较差
StringBuilder 与StringBuffer类似,但是是线程不安全的,在单线程环境下性能较好
泛型中super和extend的却别
表示包括T在内的任何T的子类 表示包括T在内的任何T的父类 泛型在编译中会有效果,在运行时不生效 泛型擦除
== 和 equals的区别
== 如果是基本数据类型,比较的是值,如果是引用类型,比较的是引用地址
equals 具体看各个类重写equals方法,例如String 虽然是引用类型,但是类中重写了equals方法,但是方法内部比较的是字符串中各个字符是否全部相等,当然equals也能够比较基本数据类型,但是由于基本数据类型不是对象,所以会自动装箱为包装类对象来对equals进行调用
重载和重写的区别
重载 发生在同一个类中,方法名相同 参数列表不同(参数类型,个数,顺序不同),方法的返回值和修饰符可以不同,发生在编译时
重写 发生在父子类中,子类重写父类的方法,方法名和参数列表必须相同,子类返回范围小于等于父类,子类抛出异常范围小于父类,访问修饰符范围大于父类,如果父类访问修饰符为private则子类就不能重写
List和Set的区别
List 有序可重复,按照对象进入的顺序保存对象,允许多个NULL对象,可以使用迭代器取所有元素,还可以使用get获取
Set 无序,不可重复,最多语序有一个NULL元素对象,取元素只能通过迭代器取到所有元素,再逐一便利
ArrayList和LinkedList的区别
两者底层采用的数据结构不同,ArrayList使用的数组,数组的增删慢而查询快,更适合随机查找
LinkedList使用的是链表,而链表(块中保存了当前的值和指向下一个块的指针)是增删快查询慢,它的查询只能一个个来
两者都实现了List接口,linkedList还是先了Deque()相关接口 队列相关接口
深拷贝和浅拷贝
浅拷贝只会拷贝基本数据类型的值,以及实例对象的引用地址
深拷贝是指即会拷贝基本数据类型的值,也会针对实例对象的引用地址所指向的对象进行拷贝,深拷贝出俩的对象,内部的属性指向的不是同一个对象。
jdk1.7 1jdk1.8 的HashMap区别
1.7中底层是数组+链表,1.8中底层是数组+链表+红黑树,加入红黑树的目的是提高HashMap插入和查询的整体效率(链表的插入的效率比较低(在插入之前需要查找是否存在,需要遍历),主要就是把一些较长的链表改造成红黑树来使用)
1.7中链表的插入使用的是头插法,1.8中链表插入使用的是尾插法,因为1.8插入key和value需要判断链表元素的个数,所以需要遍历链表统计元素个数,正好使用尾插法
1.7中哈希算法比较,1.8中进行了简化,因为哈希算法的目的就是提高散列性,来提供HashMap的整体效率,而1.8中新增了红黑树,简化了哈希算法,减少CPU资源
HashMap的put方法
HashMap的put方法的大体流程,需要分版本讨论
1.根据key通过哈希算法与 与运算得到数组下标
2.如果数组下标位置的元素为空,则将key和value封装为Entry(JDK1.7中是Entry对象,JDK1.8中是Node对象),并放入该位置
3.如果数组位置下标元素不为空,分情况讨论
3.1如果是JDK1.7,则先判断是否需要扩容,如果要就进行扩容,如果不用扩容就生成Entry对象,并使用头插法添加到当前位置的的链表中
3.2 如果是JDK1.8,则需要先判断当前位置上的Node类型,看是红黑树Node,还是链表Node
3.2.1 如果是红黑树Node,则将key和value封装成一个红黑树结点并添加到红黑树中区,在这个过程中会判断红黑树中是否存在当前key,如果存在则更新value
3.2.2 如果此位置上的Node对象是链表结点,则将key和value封装为一个链表Node并通过尾插法插入到链表的最后位置去,因为是尾插法,所以需要遍历链表,在遍历链表的过程中会判断是否存在当前key,如果存在则更新value,当遍历完链表后,将新链表Node插入到链表中区,插入到链表中后,会看到当前链表的结点个数,如果大于等于8,那么则会将该链表转成红黑树
3.2.3将key和value封装为Node插入到链表或红黑树中后,再判断是否需要扩容,如果需要就扩容,如果不需要就结束put方法