C++面试题(吴)-计算机网络部分(2)和常见设计模式
目录
1.网络部分
3.32 说说浏览器从输入 URL 到展现页面的全过程
3.33 简述 HTTP 和 HTTPS 的区别?
3.34 说说 HTTP 中的 referer 头的作用
3.35 说说 HTTP 的方法有哪些
3.36 简述 HTTP 1.0,1.1,2.0 的主要区别
3.37 说说 HTTP 常见的响应状态码及其含义
3.38 说说 GET请求和 POST 请求的区别
3.39 说说 Cookie 和 Session 的关系和区别是什么
3.40 简述 HTTPS 的加密与认证过程
2.设计模式
2.1 说说什么是单例设计模式,如何实现
2.2 简述一下单例设计模式的懒汉式和饿汉式,如何保证线程安全
2.3 请说说工厂设计模式,如何实现,以及它的优点
2.4 请说说装饰器计模式,以及它的优缺点
5.5 请说说观察者设计模式,如何实现
1.网络部分
3.32 说说浏览器从输入 URL 到展现页面的全过程
参考回答
1 、输入地址
2 、浏览器查找域名的 IP 地址
3 、浏览器向 web 服务器发送一个 HTTP 请求
4 、服务器的永久重定向响应
6 、服务器处理请求
7 、服务器返回一个 HTTP 响应
8 、浏览器显示 HTML
9 、浏览器发送请求获取嵌入在 HTML 中的资源(如图片、音频、视频、 CSS 、 JS 等等)
3.33 简述 HTTP 和 HTTPS 的区别?
参考回答
1. HTTP :是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准
( TCP ),用于从 WWW 服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,
使网络传输减少。HTTPS:是以安全为目标的 HTTP 通道,简单讲是 HTTP 的安全版,即 HTTP 下加入 SSL 层, HTTPS 的安全基础是SSL ,因此加密的详细内容就需要 SSL 。
HTTPS 协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
2. HTTP 与 HTTPS 的区别
https 协议需要到 ca 申请证书,一般免费证书较少,因而需要一定费用。
http 是超文本传输协议,信息是明文传输, https 则是具有安全性的 ssl 加密传输协议。
http 和 https 使用的是完全不同的连接方式,用的端口也不一样,前者是 80 ,后者是 443 。
http 的连接很简单,是无状态的; HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认
证的网络协议,比 http 协议安全。
3.34 说说 HTTP 中的 referer 头的作用
参考回答
1. HTTP Referer 是 header 的一部分,当浏览器向 web 服务器发送请求的时候,一般会带上 Referer ,告诉服务器该网页是从哪个页面链接过来的,服务器因此可以获得一些信息用于处理。
2. 防盗链。假如在 www.google.com 里有一个 `www.baidu.com` 链接,那么点击进入这个 `www.baidu.com`,它的 header 信息里就有: Referer= http://www.google.com 只允许我本身的网站访问本身的图片服务器,假如域是 www.google.com ,那么图片服务器每次取到Referer 来判断一下域名是不是 www.google.com ,如果是就继续访问,不是就拦截。将这个http 请求发给服务器后,如果服务器要求必须是某个地址或者某几个地址才能访问,而你发送的referer 不符合他的要求,就会拦截或者跳转到他要求的地址,然后再通过这个地址进行访问。
3. 防止恶意请求
比如静态请求是 *.html 结尾的,动态请求是 *.shtml ,那么由此可以这么用,所有的 *.shtml 请
求,必须 Referer 为我自己的网站。
4. 空 Referer
定义 : Referer 头部的内容为空,或者,一个 HTTP 请求中根本不包含 Referer 头部(一个请求并不
是由链接触发产生的)直接在浏览器的地址栏中输入一个资源的URL 地址,那么这种请求是不会包含 Referer 字段的,因为这是一个“ 凭空产生 ” 的 HTTP 请求,并不是从一个地方链接过去的。那么在防盗链设置中,允许空Referer 和不允许空 Referer 有什么区别?允许Referer 为空,意味着你允许比如浏览器直接访问。
5. 防御 CSRF
比对 HTTP 请求的来源地址,如果 Referer 中的地址是安全可信任的地址,那么就放行。
3.35 说说 HTTP 的方法有哪些
参考回答
GET : 用于请求访问已经被 URI (统一资源标识符)识别的资源,可以通过 URL 传参给服务器
POST :用于传输信息给服务器,主要功能与 GET 方法类似,但一般推荐使用 POST 方式。
PUT : 传输文件,报文主体中包含文件内容,保存到对应 URI 位置。
HEAD : 获得报文首部,与 GET 方法类似,只是不返回报文主体,一般用于验证 URI 是否有效。
DELETE :删除文件,与 PUT 方法相反,删除对应 URI 位置的文件。
OPTIONS :查询相应 URI 支持的 HTTP 方法。
3.36 简述 HTTP 1.0,1.1,2.0 的主要区别
参考回答
http/1.0 :
1. 默认不支持长连接,需要设置 keep-alive 参数指定
2. 强缓存 expired 、协商缓存 last-modified\if-modified-since 有一定的缺陷http 1.1 :
1. 默认长连接 (keep-alive) , http 请求可以复用 Tcp 连接,但是同一时间只能对应一个 http 请求 (http 请求在一个Tcp 中是串行的 )
2. 增加了强缓存 cache-control 、协商缓存 etag\if-none-match 是对 http/1 缓存的优化http/2.0 :
1. 多路复用,一个 Tcp 中多个 http 请求是并行的 ( 雪碧图、多域名散列等优化手段 http/2 中将变得多余 )
2. 二进制格式编码传输
3. 使用 HPACK 算法做 header 压缩
4. 服务端推送
3.37 说说 HTTP 常见的响应状态码及其含义
参考回答
200 : 从状态码发出的请求被服务器正常处理。
204 : 服务器接收的请求已成功处理,但在返回的响应报文中不含实体的主体部分【即没有内
容】。
206 : 部分的内容(如:客户端进行了范围请求,但是服务器成功执行了这部分的干请求)。
301 : 跳转,代表永久性重定向(请求的资源已被分配了新的 URI ,以后已使用资源,现在设置了
URI )。
302 : 临时性重定向(请求的资源已经分配了新的 URI ,希望用户本次能够使用新的 URI 来进行访
问。
303 : 由于请求对应的资源存在的另一个 URI (因使用 get 方法,定向获取请求的资源)。
304 : 客户端发送附带条件的请求时,服务器端允许请求访问资源,但因发生请求未满足条件的情
况后,直接返回了 304 。
307 : 临时重定向【该状态码与 302 有着相同的含义】。
400 : 请求报文中存在语法错误(当错误方式时,需修改请求的内容后,再次发送请求)。
401 : 发送的请求需要有通过 HTTP 认证的认证信息。
403 : 对请求资源的访问被服务器拒绝了。
404 : 服务器上无法找到请求的资源。
500 : 服务器端在执行请求时发生了错误。
503 : 服务器暂时处于超负载或者是正在进行停机维护,现在无法处理请求。
答案解析 1XX : 信息类状态码(表示接收请求状态处理)
2XX : 成功状态码(表示请求正常处理完毕)
3XX : 重定向(表示需要进行附加操作,已完成请求)
4XX : 客户端错误(表示服务器无法处理请求)
5XX : 服务器错误状态码(表示服务器处理请求的时候出错)
3.38 说说 GET请求和 POST 请求的区别
参考回答
1. GET 请求在 URL 中传送的参数是有长度限制的,而 POST 没有。
2. GET 比 POST 更不安全,因为 参数直接暴露在 URL 上,所以不能用来传递敏感信息。
3. GET 参数通过 URL 传递, POST 放在 Request body 中。
4. GET 请求参数会被完整保留在浏览器历史记录里 ,而 POST 中的参数 不会被保留 。
5. GET 请求只能进行 url 编码,而 POST 支持多种编码方式 。
6. GET 请求会被浏览器主动 cache ,而 POST 不会,除非手动设置。
7. GET 产生的 URL 地址可以被 Bookmark ,而 POST 不可以。
8. GET 在浏览器回退时是无害的,而 POST 会再次提交请求
3.39 说说 Cookie 和 Session 的关系和区别是什么
参考回答
1. Cookie 与 Session 都是会话的一种方式。它们的典型使用场景比如 “ 购物车 ” ,当你点击下单按钮
时,服务端并不清楚具体用户的具体操作,为了标识并跟踪该用户,了解购物车中有几样物品,服
务端通过为该用户创建 Cookie/Session 来获取这些信息。
2. cookie 数据存放在客户的浏览器上, session 数据放在服务器上。
3. cookie 不是很安全 ,别人可以分析存放在本地的 COOKIE 并进行 COOKIE 欺骗 考虑到安全应当使用session。
4. session 会 在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能 考虑到减轻服务器性能方面,应当使用COOKIE 。
5. 单个 cookie 保存的数据不能超过 4K ,很多浏览器都限制一个站点最多保存 20 个 cookie 。
3.40 简述 HTTPS 的加密与认证过程
参考回答
1. 客户端在浏览器中输入一个 https 网址,然后连接到 server 的 443 端口 采用 https 协议的 server 必须
有一套数字证书(一套公钥和密钥) 首先 server 将证书(公钥)传送到客户端 客户端解析证书,
验证成功,则生成一个随机数(私钥),并用证书将该随机数加密后传回 server server 用密钥解密
后,获得这个随机值,然后将要传输的信息和私钥通过某种算法混合在一起(加密)传到客户端 客户端用之前的生成的随机数(私钥)解密服务器端传来的信息
2. 首先浏览器会从内置的证书列表中索引,找到服务器下发证书对应的机构,如果没有找到,此时就会提示用户该证书是不是由权威机构颁发,是不可信任的。如果查到了对应的机构,则取出该机构颁发的公钥。
用机构的证书公钥解密得到证书的内容和证书签名,内容包括网站的网址、网站的公钥、证书的有
效期等。浏览器会先验证证书签名的合法性。签名通过后,浏览器验证证书记录的网址是否和当前
网址是一致的,不一致会提示用户。如果网址一致会检查证书有效期,证书过期了也会提示用户。
这些都通过认证时,浏览器就可以安全使用证书中的网站公钥了。
2.设计模式
2.1 说说什么是单例设计模式,如何实现
参考回答
1. 单例模式定义
保证 一个类仅有一个实例 ,并提 供一个访问它的全局访问点,该实例被所有程序模块共享 。
那么我们就必须保证:
(1) 该类不能被复制。
( 2 )该类不能被公开的创造。
那么对于 C++ 来说,它的 构造函数,拷贝构造函数和赋值函数都不能被公开调用 。
2. 单例模式 实现方式
单例模式通常有两种模式,分别为 懒汉式单例 和 饿汉式单例 。两种模式实现方式分别如下:
(1)懒汉式设计模式实现方式(2种)
a. 静态指针 + 用到时初始化
b. 局部静态变量
(2)饿汉式设计模式(2种)
a. 直接定义静态对象
b. 静态指针 + 类外初始化时 new 空间实现
答案解析
1. 懒汉模式
懒汉模式的特点 是 延迟加载, 比如配置文件,采用懒汉式的方法,配置文件的 实例直到用到的时候
才会加载,不到万不得已就不会去实例化类,也就是说在第一次用到类实例的时候才会去实例化 。
以下是懒汉模式实现方式 C++ 代码:
//代码实例(线程不安全)
template
class Singleton
{
public:
static T& getInstance()
{
if (!value_)
{
value_ = new T();
}
return *value_;
}
private:
Singleton();
~Singleton();
static T* value_;
};
template
T* Singleton::value_ = NULL; 在单线程中,这样的写法是可以正确使用的,但是在多线程中就不行了,该方法是线程不安全的。
a. 假如线程 A 和线程 B, 这两个线程要访问 getInstance 函数,线程 A 进入 getInstance 函数,并检测 if
条件,由于是第一次进入, value 为空, if 条件成立,准备创建对象实例。
b. 但是,线程 A 有可能被 OS 的调度器中断而挂起睡眠,而将控制权交给线程 B 。
c. 线程 B 同样来到 if 条件,发现 value 还是为 NULL ,因为线程 A 还没来得及构造它就已经被中断了。
此时假设线程 B 完成了对象的创建,并顺利的返回。
d. 之后线程 A 被唤醒,继续执行 new 再次创建对象,这样一来,两个线程就构建两个对象实例,这
就破坏了唯一性。另外,还存在内存泄漏的问题,new 出来的东西始终没有释放,下面是一种饿汉式的一种改进。
//代码实例(线程安全)
emplate
class Singleton
{
public:
static T& getInstance()
{
if (!value_)
{
value_ = new T();
}
return *value_;
}
private:
class CGarbo
{
public:
~CGarbo()
{
if(Singleton::value_)
delete Singleton::value_;
}
};
static CGarbo Garbo;
Singleton();
~Singleton();
static T* value_;
};
template
T* Singleton::value_ = NULL; 在程序运行结束时,系统会调用 Singleton 的静态成员 Garbo 的析构函数,该析构函数会删除单例的
唯一实例。使用这种方法释放单例对象有以下特征:
a. 在单例类内部定义专有的嵌套类;
b. 在单例类内定义私有的专门用于释放的静态成员;
c. 利用程序在结束时析构全局变量的特性,选择最终的释放时机。
(2) 懒汉模式实现二:局部静态变量
//代码实例(线程不安全)
template
class Singleton
{
public:
static T& getInstance()
{
static T instance;
return instance;
}
private:
Singleton(){};
Singleton(const Singleton&);
Singleton& operator=(const Singleton&);
}; 同样,静态局部变量的实现方式也是线程不安全的。如果存在多个单例对象的析构顺序有依赖时,
可能会出现程序崩溃的危险。对于局部静态对象的也是一样的。因为 static T instance ;语句不是一个原子操作,在第一次被调用时会调用Singleton的构造函数,而如果构造函数里如果有多条初始化语句,则初始化动作可以分解为多步操作,就存在多线程竞争的问题。为什么存在多个单例对象的析构顺序有依赖时,可能会出现程序崩溃的危险?

原因:由于静态成员是在第一次调用函数 GetInstance 时进行初始化,调用构造函数的,因此构造
函数的调用顺序时可以唯一确定了。对于析构函数,我们只知道其调用顺序和构造函数的调用顺序
相反,但是如果几个 Singleton 类的析构函数之间也有依赖关系,而且出现类似单例实例 A 的析构函
数中使用了单例实例 B ,但是程序析构时是先调用实例 B 的析构函数,此时在 A 析构函数中使用 B 时
就可能会崩溃。
//代码实例(线程安全)
#include
#include
using namespace std;
class Log
{
public:
static Log* GetInstance()
{
static Log oLog;
return &oLog;
}
void Output(string strLog)
{
cout<Output(__FUNCTION__);
}
void fun()
{
Log::GetInstance()->Output(__FUNCTION__);
}
private:
Context(){}
Context(const Context& context);
};
int main(int argc, char* argv[])
{
Context::GetInstance()->fun();
return 0;
} 在这个反例中有两个 Singleton: Log 和 Context , Context 的 fun 和析构函数会调用 Log 来输出一些信
息,结果程序 Crash 掉了,该程序的运行的序列图如下(其中画红框的部分是出问题的部分):
解决方案: 对于析构的顺序,我们可以用一个容器来管理它,根据单例之间的依赖关系释放实例,
对所有的实例的析构顺序进行排序,之后调用各个单例实例的析构方法,如果出现了循环依赖关
系,就给出异常,并输出循环依赖环。
2. 饿汉模式
单例类定义的时候就进行实例化 。因为 main 函数执行之前,全局作用域的类成员静态变量
m_Instance 已经初始化,故 没有多线程的问题 。
(1) 饿汉模式实现一:直接定义静态对象
//代码实例(线程安全)
//.h文件
class Singleton
{
public:
static Singleton& GetInstance();
private:
Singleton(){}
Singleton(const Singleton&);
Singleton& operator= (const Singleton&);
private:
static Singleton m_Instance;
};
//CPP文件
Singleton Singleton::m_Instance;//类外定义-不要忘记写
Singleton& Singleton::GetInstance()
{
return m_Instance;
}
//函数调用
Singleton& instance = Singleton::GetInstance(); 优点:
实现简单,多线程安全。
缺点:
a. 如果存在多个单例对象且这几个单例对象相互依赖,可能会出现程序崩溃的危险。原因 : 对编译
器来说,静态成员变量的初始化顺序和析构顺序是一个未定义的行为 ; 具体分析在懒汉模式中也讲到了。
b. 在程序开始时,就创建类的实例,如果 Singleton 对象产生很昂贵,而本身有很少使用,这种方
式单从资源利用效率的角度来讲,比懒汉式单例类稍差些。但从反应时间角度来讲,则比懒汉式单
例类稍好些。
使用条件:
a. 当肯定不会有构造和析构依赖关系的情况。
b. 想避免频繁加锁时的性能消耗
(2) 饿汉模式实现二:静态指针 + 类外初始化时 new 空间实现
//代码实例(线程安全)
class Singleton
{
protected:
Singleton(){}
private:
static Singleton* p;
public:
static Singleton* initance();
};
Singleton* Singleton::p = new Singleton;
Singleton* singleton::initance()
{
return p;
}#include
#include
#include 2.2 简述一下单例设计模式的懒汉式和饿汉式,如何保证线程安全
参考回答
1. 懒汉式设计模式
懒汉模式的特点是延迟加载,比如配置文件,采用懒汉式的方法,配置文件的实例直到用到的时候
才会加载,不到万不得已就不会去实例化类,也就是说在第一次用到类实例的时候才会去实例化。
2. 饿汉模式
单例类定义的时候就进行实例化。因为 main 函数执行之前,全局作用域的类成员静态变量
m_Instance 已经初始化,故 没有多线程的问题。 懒汉设计模式两种实现方式线程不安全问题的解决:同上。
2.3 请说说工厂设计模式,如何实现,以及它的优点
参考回答
1. 工厂设计模式的定义
定义一个创建对象的接口,让子类决定实例化哪个类,而对象的创建统一交由工厂去生产,有良好
的封装性 ,既做到了解耦,也保证了最少知识原则。
2. 工厂设计模式分类
工厂模式属于创建型模式,大致可以分为三类, 简单工厂模式、工厂方法模式、抽象工厂模式 。听
上去差不多,都是工厂模式。下面一个个介绍:
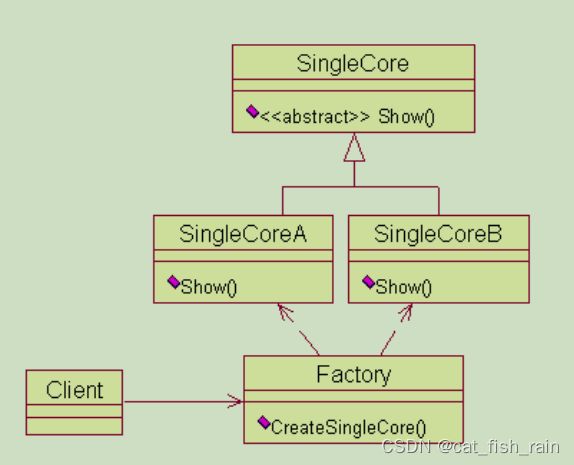
(1)简单工厂模式
它的主要特点是 需要在工厂类中做判断,从而创造相应的产品 。 当增加新的产品时,就需要修改工
厂类。
举例: 有一家生产处理器核的厂家,它只有一个工厂,能够生产两种型号的处理器核。客户需要什
么样的处理器核,一定要显示地告诉生产工厂。下面给出一种实现方案:
//程序实例(简单工厂模式)
enum CTYPE {COREA, COREB};
class SingleCore
{
public:
virtual void Show() = 0;
};
//单核A
class SingleCoreA: public SingleCore
{
public:
void Show() { cout<<"SingleCore A"< 优点: 简单工厂模式可以根据需求,动态生成使用者所需类的对象 ,而使用者不用去知道怎么创建对象,使得各个模块各司其职,降低了系统的耦合性。
缺点: 就是要 增加新的核类型时,就需要修改工厂类。 这就违反了开放封闭原则:软件实体(类、
模块、函数)可以扩展,但是不可修改。
(2)工厂方法模式
所谓工厂方法模式,是指定义一个用于创建对象的接口,让子类决定实例化哪一个类。 Factory
Method 使一个类的实例化延迟到其子类。
举例: 这家生产处理器核的产家赚了不少钱,于是决定再开设一个工厂专门用来生产 B 型号的单
核,而原来的工厂专门用来生产 A 型号的单核。这时,客户要做的是找好工厂,比如要 A 型号的核,就找A 工厂要;否则找 B 工厂要,不再需要告诉工厂具体要什么型号的处理器核了。下面给出一个实现方案:
//程序实例(工厂方法模式)
class SingleCore
{
public:
virtual void Show() = 0;
};
//单核A
class SingleCoreA: public SingleCore
{
public:
void Show() { cout<<"SingleCore A"< 优点: 扩展性好,符合了开闭原则 ,新增一种产品时,只需增加改对应的产品类和对应的工厂子类即可。
缺点: 每增加一种产品,就需要增加一个对象的工厂 。如果这家公司发展迅速,推出了很多新的处
理器核,那么就要开设相应的新工厂。在 C++ 实现中,就是要定义一个个的工厂类。显然,相比简
单工厂模式,工厂方法模式需要更多的类定义。
(3)抽象工厂模式
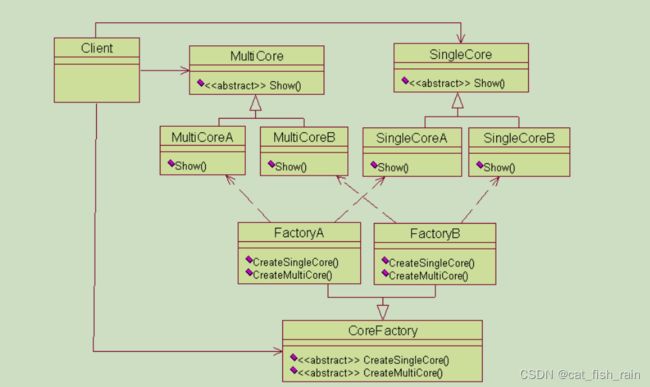
举例: 这家公司的技术不断进步,不仅可以生产单核处理器,也能生产多核处理器。现在简单工厂
模式和工厂方法模式都鞭长莫及。抽象工厂模式登场了。它的定义为 提供一个创建一系列相关或相
互依赖对象的接口,而无需指定它们具体的类 。具体这样应用,这家公司还是开设两个工厂,一个
专门用来生产 A 型号的单核多核处理器,而另一个工厂专门用来生产 B 型号的单核多核处理器,下面给出实现的代码:
//程序实例(抽象工厂模式)
//单核
class SingleCore
{
public:
virtual void Show() = 0;
};
class SingleCoreA: public SingleCore
{
public:
void Show() { cout<<"Single Core A"< 优点: 工厂抽象类创建了多个类型的产品,当有需求时,可以创建相关产品子类和子工厂类来获
取。
缺点: 扩展新种类产品时困难 。抽象工厂模式需要我们在工厂抽象类中提前确定了可能需要的产品种类,以满足不同型号的多种产品的需求。但是如果我们需要的产品种类并没有在工厂抽象类中提前确定,那我们就需要去修改工厂抽象类了,而一旦修改了工厂抽象类,那么所有的工厂子类也需要修改,这样显然扩展不方便。
答案解析
三种工厂模式的 UML 图如下:
1. 简单工厂模式 UML
2. 工厂方法的UML图
 3. 抽象工厂模式的UML图
3. 抽象工厂模式的UML图
2.4 请说说装饰器计模式,以及它的优缺点
参考回答
1. 装饰器计模式的定义
指在 不改变现有对象结构的情况下,动态地给该对象增加一些职责(即增加其额外功能)的模式 ,
它属于对象结构型模式。
2. 优点
(1) 装饰器是继承的有力补充,比继承灵活,在不改变原有对象的情况下,动态的给一个对象扩
展功能,即插即用;
(2)通过使用不用装饰类及这些装饰类的排列组合,可以实现不同效果;
(3)装饰器模式完全遵守开闭原则。
3. 缺点
装饰模式会增加许多子类,过度使用会增加程序得复杂性 。
4. 装饰模式的结构与实现
通常情况下,扩展一个类的功能会使用继承方式来实现。但继承具有静态特征,耦合度高,并且随
着扩展功能的增多,子类会很膨胀。如果使用组合关系来创建一个包装对象(即装饰对象)来包裹
真实对象,并在保持真实对象的类结构不变的前提下,为其提供额外的功能,这就是装饰模式的目
标。下面来分析其基本结构和实现方法。
装饰模式主要包含以下角色:
(1)抽象构件( Component )角色:定义一个抽象接口以规范准备接收附加责任的对象。
(2)具体构件( ConcreteComponent )角色:实现抽象构件,通过装饰角色为其添加一些职责。
(3)抽象装饰( Decorator )角色:继承抽象构件,并包含具体构件的实例,可以通过其子类扩展
具体构件的功能。
(4)具体装饰( ConcreteDecorator )角色:实现抽象装饰的相关方法,并给具体构件对象添加
附加的责任。装饰模式的结构图如下图所示:
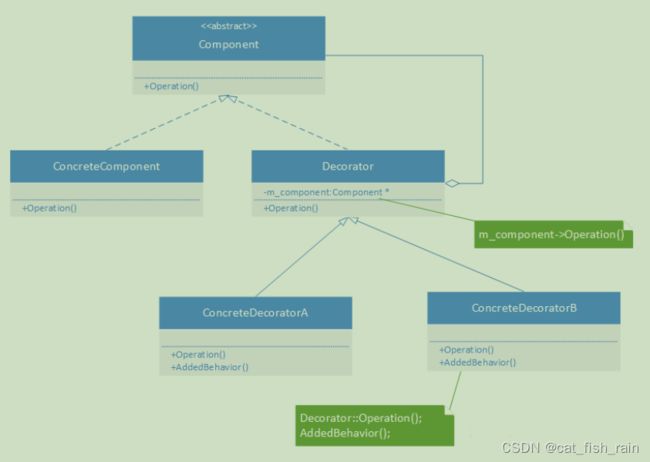
装饰模式结构图
装饰模式的实现代码如下:
#include
#include
//基础组件接口定义了可以被装饰器修改的操作
class Component {
public:
virtual ~Component() {}
virtual std::string Operation() const = 0;
};
//具体组件提供了操作的默认实现。这些类在程序中可能会有几个变体
class ConcreteComponent : public Component {
public:
std::string Operation() const override {
return "ConcreteComponent";
}
};
//装饰器基类和其他组件遵循相同的接口。这个类的主要目的是为所有的具体装饰器定义封装接口。
//封装的默认实现代码中可能会包含一个保存被封装组件的成员变量,并且负责对齐进行初始化
class Decorator : public Component {
protected:
Component* component_;
public:
Decorator(Component* component) : component_(component) {
}
//装饰器会将所有的工作分派给被封装的组件
std::string Operation() const override {
return this->component_->Operation();
}
};
//具体装饰器必须在被封装对象上调用方法,不过也可以自行在结果中添加一些内容。
class ConcreteDecoratorA : public Decorator {
//装饰器可以调用父类的是实现,来替代直接调用组件方法。
public:
ConcreteDecoratorA(Component* component) : Decorator(component) {
}
std::string Operation() const override {
return "ConcreteDecoratorA(" + Decorator::Operation() + ")";
}
};
//装饰器可以在调用封装的组件对象的方法前后执行自己的方法
class ConcreteDecoratorB : public Decorator {
public:
ConcreteDecoratorB(Component* component) : Decorator(component) {
}
std::string Operation() const override {
return "ConcreteDecoratorB(" + Decorator::Operation() + ")";
}
};
//客户端代码可以使用组件接口来操作所有的具体对象。这种方式可以使客户端和具体的实现类脱耦
void ClientCode(Component* component) {
// ...
std::cout << "RESULT: " << component->Operation();
// ...
}
int main() {
Component* simple = new ConcreteComponent;
std::cout << "Client: I've got a simple component:\n";
ClientCode(simple);
std::cout << "\n\n";
Component* decorator1 = new ConcreteDecoratorA(simple);
Component* decorator2 = new ConcreteDecoratorB(decorator1);
std::cout << "Client: Now I've got a decorated component:\n";
ClientCode(decorator2);
std::cout << "\n";
delete simple;
delete decorator1;
delete decorator2;
return 0;
} 5.5 请说说观察者设计模式,如何实现
参考回答
1. 观察者设计模式的定义
指 多个对象间存在一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到
通知并被自动更新 。这种模式有时又称作发布 - 订阅模式、模型 - 视图模式,它是对象行为型模式。
2. 优点
(1) 降低了目标与观察者之间的耦合关系 ,两者之间是抽象耦合关系。符合依赖倒置原则。
(2) 目标与观察者之间建立了一套触发机制。
3. 缺点
(1)目标与观察者之间的依赖关系并没有完全解除,而且有可能出 现循环引用。
(2) 当观察者对象很多时,通知的发布会花费很多时间,影响程序的效率。
4. 观察者设计模式的结构与实现
观察者模式的主要角色如下:
(1) 抽象主题 ( Subject )角色:也叫抽象目标类,它提供了一个用于保存观察者对象的聚集类和
增加、删除观察者对象的方法,以及通知所有观察者的抽象方法。
(2) 具体主题 ( Concrete Subject )角色:也叫具体目标类,它实现抽象目标中的通知方法,当
具体主题的内部状态发生改变时,通知所有注册过的观察者对象。
(3) 抽象观察者 ( Observer )角色:它是一个抽象类或接口,它包含了一个更新自己的抽象方
法,当接到具体主题的更改通知时被调用。
(4) 具体观察者 ( Concrete Observer )角色:实现抽象观察者中定义的抽象方法,以便在得到
目标的更改通知时更新自身的状态。
可以举个博客订阅的例子,当博主发表新文章的时候,即博主状态发生了改变,那些订阅的读者就会收 到通知,然后进行相应的动作,比如去看文章,或者收藏起来。博主与读者之间存在种一对多的依赖关系。下面给出相应的UML 图设计 :

观察者模式的结构图
可以看到博客类中有一个观察者链表(即订阅者),当博客的状态发生变化时,通过 Notify 成员函数通知所有的观察者,告诉他们博客的状态更新了。而观察者通过Update 成员函数获取博客的状态信息。代码实现不难,下面给出C++ 的一种实现。
//观察者
class Observer
{
public:
Observer() {}
virtual ~Observer() {}
virtual void Update() {}
};
//博客
class Blog
{
public:
Blog() {}
virtual ~Blog() {}
void Attach(Observer *observer) { m_observers.push_back(observer); } //添
加观察者
void Remove(Observer *observer) { m_observers.remove(observer); } //移
除观察者
void Notify() //通知观察者
{
list::iterator iter = m_observers.begin();
for(; iter != m_observers.end(); iter++)
(*iter)->Update();
}
virtual void SetStatus(string s) { m_status = s; } //设置状态
virtual string GetStatus() { return m_status; } //获得状态
private:
list m_observers; //观察者链表
protected:
string m_status; //状态
}; 以上是观察者和博客的基类,定义了通用接口。博客类主要完成观察者的添加、移除、通知操作,设置和获得状态仅仅是一个默认实现。下面给出它们相应的子类实现。
//具体博客类
class BlogCSDN : public Blog
{
private:
string m_name; //博主名称
public:
BlogCSDN(string name): m_name(name) {}
~BlogCSDN() {}
void SetStatus(string s) { m_status = "CSDN通知 : " + m_name + s; } //具体设置
状态信息
string GetStatus() { return m_status; }
};
//具体观察者
class ObserverBlog : public Observer
{
private:
string m_name; //观察者名称
Blog *m_blog; //观察的博客,当然以链表形式更好,就可以观察多个博客
public:
ObserverBlog(string name,Blog *blog): m_name(name), m_blog(blog) {}
~ObserverBlog() {}
void Update() //获得更新状态
{
string status = m_blog->GetStatus();
cout<Attach(observer1);
blog->SetStatus("发表设计模式C++实现(15)——观察者模式");
blog->Notify();
delete blog; delete observer1;
return 0;
}