Spark_Spark 中Cache的作用 以及 具体的案例
参考文章:
https://blog.csdn.net/qq_20641565/article/details/76216417
今天模拟实现 broadcastJoin 的时候突然意识到了这个点,对 Spark 的 Cache 做个总结。
问题
在Spark中有时候我们很多地方都会用到同一个RDD, 按照常规的做法的话,那么每个地方遇到Action操作的时候都会对同一个算子计算多次。这样会造成效率低下的问题 !!!!
常见 transform , action 算子 =>
https://blog.csdn.net/u010003835/article/details/106341908
例如:
val rdd1 = sc.textFile("xxx")
rdd1.xxxxx.xxxx.collect
rdd1.xxx.xxcollect
方法
上面就是两个代码都用到了rdd1这个RDD,如果程序执行的话,那么sc.textFile(“xxx”)就要被执行两次, 可以把rdd1的结果进行cache到内存中,使用如下方法
val rdd1 = sc.textFile("xxx")
val rdd2 = rdd1.cache
rdd2.xxxxx.xxxx.collect
rdd2.xxx.xxcollect
示例
例如 如下Demo
package com.spark.test.offline.skewed_data
import org.apache.spark.SparkConf
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.sql.types.{StructField, _}
import org.apache.spark.sql.{Row, SparkSession}
import scala.collection.mutable
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
/**
* Created by szh on 2020/6/5.
*/
object JOINSkewedData2 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf
sparkConf
.setAppName("JOINSkewedData")
.set("spark.sql.autoBroadcastJoinThreshold", "1048576") //1M broadcastJOIN
//.set("spark.sql.autoBroadcastJoinThreshold", "104857600") //100M broadcastJOIN
.set("spark.sql.shuffle.partitions", "3")
if (args.length > 0 && args(0).equals("ide")) {
sparkConf
.setMaster("local[3]")
}
val spark = SparkSession.builder()
.config(sparkConf)
.getOrCreate()
val sparkContext = spark.sparkContext
sparkContext.setLogLevel("WARN")
//sparkContext.setCheckpointDir("")
val userArr = new ArrayBuffer[(Int, String)]()
val nameArr = Array[String]("sun", "zhen", "hua", "kk", "cc")
val threshold = 1000000
for (i <- 1 to threshold) {
var id = 10
if (i < (threshold * 0.9)) {
id = 1
} else {
id = i
}
val name = nameArr(Random.nextInt(5))
userArr.+=((id, name))
}
val rddA = sparkContext
.parallelize(userArr)
//spark.sql("CACHE TABLE userA")
//-----------------------------------------
//---------------------------------------
val arrList = new ArrayBuffer[(Int, Int)]
for (i <- 1 to (threshold * 0.1).toInt) {
val id = i
val salary = Random.nextInt(100)
arrList.+=((id, salary))
}
val rddB = sparkContext
.parallelize(arrList)
val broadData: Broadcast[Array[(Int, Int)]] = sparkContext.broadcast(rddB.collect())
import scala.util.control._
val resultRdd = rddA
.mapPartitions(arr => {
val broadVal = broadData.value
var rowArr = new ArrayBuffer[Row]()
val broadMap = new mutable.HashMap[Int, Int]()
while (arr.hasNext) {
val x = arr.next
val loop = new Breaks
var rRow: Row = null
//var rRow: Option[Row] = None
loop.breakable(
for (tmpVal <- broadVal) {
if (tmpVal._1 == x._1) {
rRow = Row(tmpVal._1, x._2, tmpVal._2)
//println(rRow)
loop.break
}
}
)
if (rRow != null) {
rowArr.+=(rRow)
rRow = null
}
}
println(rowArr.size)
rowArr.iterator
})
// .filter(x => {
// x match {
// case None => false
// case _ => true
// }
// })
val resultStruct = StructType(
Array(
StructField("uid", IntegerType, nullable = true)
, StructField("name", StringType, nullable = true)
, StructField("salary", IntegerType, nullable = true)
)
)
spark
.createDataFrame(resultRdd, resultStruct)
.createOrReplaceTempView("resultB")
val resultDF = spark
.sql("SELECT uid, name, salary FROM resultB")
//resultDF.checkpoint()
resultDF.cache()
resultDF.foreach(x => {
val i = 1
})
println(resultDF.count())
resultDF.show()
resultDF.explain(true)
Thread.sleep(60 * 10 * 1000)
sparkContext.stop()
}
}
注意其中
resultDF.foreach(x => {
val i = 1
})println(resultDF.count())
resultDF.show()
foreach, count , show 是 3个 Action 操作 !!
不对 resultDF 进行 cache, 整个任务的执行时间 如下图 :
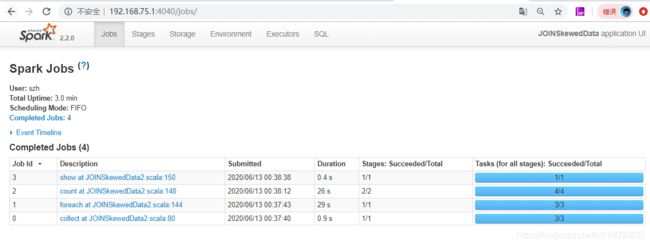
对 resultDF 进行 cache, 整个任务的执行时间 如下图 :
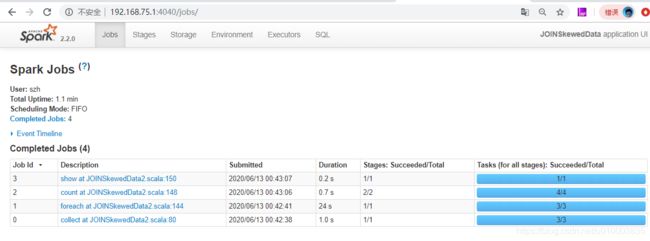
对比上图,可以清楚的看到没有进行 cache, count 对上游又重新计算了一遍多了20多秒 !!!!!