Paper Reading:《Semantic-SAM: Segment and Recognize Anything at Any Granularity》

目录
- 简介
- 目标
- 创新点
-
- 复现SAM
- 超越SAM
- 方法
-
- 模型
- 训练
- 实验
-
- SA-1B 与通用分割数据集的联合训练
- SA-1B 与细粒度分割数据集的联合训练
- 结论
简介
Semantic-SAM: Segment and Recognize Anything at Any Granularity(语义-SAM:多粒度、多语义的统一分割模型
单位:香港科技大学,微软, IDEA,威斯康星大学麦迪逊分校,香港大学,清华
日期:2023.7.10
第一作者:李峰
论文地址:https://arxiv.org/abs/2307.04767
github:https://github.com/UX-Decoder/Semantic-SAM.
作者PR:https://zhuanlan.zhihu.com/p/642863391
本文简述:
Semantic-SAM是一个在多个粒度(granularity)上分割(segment)和识别(recognize)物体的通用图像分割模型。和SAM相比,该模型有两个优点:
(1) 语义感知,即模型能够给分割出的实体提供语义标签;
(2) 粒度丰富,即模型能够分割从物体到部件的不同粒度级别的实体。
在 SA-1B数据集、通用分割数据集(COCO等)和部件分割数据集(PASCAL Part等)上联合训练模型,并系统研究了在SA-1B 上定义的交互分割任务(promptable segmentation)和其他分割任务(例如,全景分割和部件分割)上多任务联合训练的相互促进作用

Fig1:
能够处理各种分割任务,包括开放集分割和交互式分割。
(a)我们的模型可以进行实例分割、语义分割、全景分割和部分分割。
(b)我们的模型能够输出不同粒度的多级语义。
©我们将我们的模型与一个喷漆模型连接起来,执行多级喷漆。提示分别是“蜘蛛侠”和“宝马汽车”。注意,只需要单击一次就可以分别产生(b)和©中的结果
- 摘要(原文翻译)
该模型提供了两个关键优势:语义感知和粒度丰富。为了实现语义感知,我们跨三个粒度整合多个数据集,并引入对象和零件的解耦分类。这使得我们的模型能够捕获丰富的语义信息。 对于多粒度能力,我们在训练期间提出了一种多选择学习方案,使每次点击都能生成与多个真实掩模相对应的多个级别的掩码。值得注意的是,这项工作代表了在 SA-1B、通用和part分割数据集上联合训练模型的首次尝试。实验结果和可视化表明我们的模型成功实现了语义感知和粒度丰富。此外,将 SA-1B 训练与其他分割任务(例如全景和part分割)相结合,可以提高性能。 我们将提供代码和演示以供进一步探索和评估。
目标
复现SAM的分割效果并达到更好的粒度和语义功能,建立一个强大的vision foundation model
Semantic-SAM 支持广泛的分割任务及其相关应用,包括:
- Generic Segmentation 通用分割(全景/语义/实例分割)
- Part Segmentation 细粒度分割
- Interactive Segmentation with Multi-Granularity Semantics 具有多粒度语义的交互式分割
- Multi-Granularity Image Editing 多粒度图像编辑
创新点
复现SAM
SAM是Semantic-SAM的子任务。 我们开源了复现SAM效果的代码,这是开源社区第一份基于DETR结构的SAM复现代码。
超越SAM
- 粒度丰富性: Semantic-SAM能够产生用户点击所需的所有可能分割粒度(1-6)的高质量实体分割,从而实现更加可控和用户友好的交互式分割。
- 语义感知性。Semantic-SAM使用带有语义标记的数据集和SA-1B数据集联合训练模型,以学习物体(object)级别和细粒度(part)级别的语义信息。
- 多功能。Semantic-SAM 实现了高质量的全景,语义,实例,细粒度分割和交互式分割,验证了SA-1B 和其他分割任务的相互促进作用。
只需单击一下即可输出多达 6 个粒度分割! 与 SAM 相比,更可控地匹配用户意图,不用担心鼠标移动很久也找不到想要的分割了!
方法
模型

Semantic-SAM的模型结构基于Mask DINO进行开发。主要改进在decoder部分,同时支持通用分割和交互式分割。通用分割的实现与Mask DINO相同。
交互式分割包括point和box两种形式,其中box到mask不存在匹配的歧义,实现方式与通用分割相同;
point类型的交互处理方法如下,用户的point输入被转换成6个prompt, 每个prompt包含一个可学习的level embedding进行区分。这6个prompt通过decoder产生6个不同粒度的分割结果,以及object和part类别。
具体表达式解释:
将point和box的prompt统一表达,即point pormpt(x,y)转为b=box(x,y,w,h),只不过给w,h比较小的值。为了获取更多粒度的mask,采用了6个交互点(sam使用了3个)
一个point/box b = (x, y, w, h)分别编码为K(K=6)个内容嵌入content embeddings和1个位置嵌入position embedding。我们将其内容嵌入表示为一组查询向量Q = (q1,···,qK)。对于第i个查询:![]()
level是粒度级别;type区分查询类型click 还是box embeddings.
Semantic-SAM的掩码解码器将输入图像的点击表示为:
![]()
DeformDec(·,·,·)是一个可变形的解码器deformable decoder,它以查询特征Q、参考框b和图像特征F作为输入,输出查询的特征。oi是第i个输入查询qi的模型输出
oi= (ci, mi)由预测的**语义类别ci和掩码mi**组成,分别用于构造概念识别损失和掩码预测损失(concept recognition loss and mask prediction loss)
此外:
visual backbone:预训练的swin-T/L;language backbone,预训练的UniCL
AdamW作为优化器
point prompt和mask采用多对多匹配的形式,而sam用的多对一,也就是一个point的输出的3个mask只和一个gt的mask进行匹配,这导致在小mask中的点作为prompt时,预测的大mask效果不太好。
训练
- 关于数据集
为了学到物体级别(object)和部件级别(part)的语义,Semantic-SAM同时从多个数据集中进行学习,如多粒度数据集(SA-1B),物体级别数据集(如COCO),以及部件级别数据集(如Pascal Part)。
为了从联合数据集中学习语义感知性和粒度丰富性,我们引入以下两种训练方法:
- 识别任何内容
解耦物体分类与部件分类的语义学习: 为了学习到可泛化的物体和部件语义,我们采用解耦的物体分类和部件分类,以使得只有object标注的数据也可以学习到一些通用的part语义。例如,head是在几乎所有动物上都通用的part,我们期望模型从有标注的dog head,cat head,sheep head等head中学习到可泛化的lion,tiger,panda等head的识别能力。
在这里插入图片描述
- 任何粒度的分段
Many-to-Many的多粒度学习: 对于交互式分割中的point输入,Semantic-SAM利用6个prompt去输出多粒度的分割结果,并用包含该点击的所有标注分割来作为监督。这种从多个分割结果到多个分割标注的Many-to-Many的匹配和监督,使得模型能够达到高质量的多粒度分割效果。

Fig5:交互学习策略比较:a)一对一:关注对象级的传统交互式分割模型,即SEEM; b)多对一:针对单一粒度的多选择学习,即SAM; c)多对多:我们的交互式学习策略。我们强制该模型预测单个点击的所有可能粒度,以实现更可控的分割。d)因此,我们的输出粒度更丰富,以生成不同的输出掩码。
实验
SA-1B 与通用分割数据集的联合训练
我们发现,联合训练 SA-1B 和通用分割数据集可以提高通用分割性能,如对COCO分割和检测效果有大幅提升。
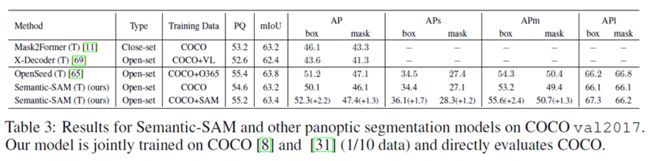
Tab3:Semantic-SAM 和其他全景分割模型在 COCO val2017 上的结果。我们的模型在 COCO 和 (1/10 数据)上进行了联合训练,并直接对 COCO 进行了评估。
值得注意的是,OpenSeed和Semantic-SAM都是基于Mask DINO。我们与SA-1B的联合训练甚至优于使用Object365训练的OpenSeed。另外,由于SA-1B中存在大量的小物体,因此,添加SA-1B主要是为了提高小物体检测(APs和APm)的能力。
SA-1B 与细粒度分割数据集的联合训练
同样的,联合训练 SA-1B 和细粒度分割数据集可以提高部件分割性能。

Tab4:Semantic-SAM 和其他部件分割模型在 Pascal Part 上的结果。我们的模型在 Pascal Part和 SA-1B(1/10 数据)上进行了联合训练,并直接对 Pascal Part 进行了评估。
Semantic-SAM的prompt从大量数据中学到了固定模式的表征

Fig7: Semantic-SAM一共有6个可学习的prompt。对于不同图片的点击,观察每个prompt对应的分割结果,可以发现每个prompt的分割都会对应一个固定的粒度。这表明每个prompt学到了一个固定的语义级别,输出更加可控。
Semantic-SAM与SAM, SA-1B Ground-truth 的比较

Fig6:(a)(b) 分别是我们的模型和 SAM 的分割输出。 每行最左边图像上的红点是用户点击的。 © 显示包含用户点击的 Groud-truth 分割。 与 SAM 相比,我们具有更好的分割质量和更丰富的粒度。
每行最左边图像上的红点是用户点击的位置,(a)(b) 分别是Semantic-SAM和 SAM 的分割输出, © 是包含用户点击的 Groud-truth 分割。 与 SAM 相比,Semantic-SAM具有更好的分割质量和更丰富的粒度,方便用户找到自己需要的分割粒度,可控性更好。

Tab5:在COCO V al2017上评估SAM和我们的模型的1-click mIoU(表示为1-IoU)。在相同的设置下,我们的模型优于SAM。
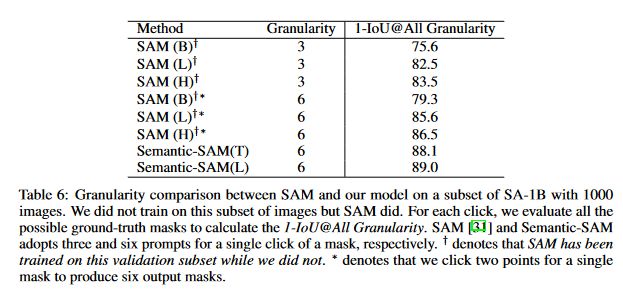
**Tab6:**比较了SAM和我们的模型在单次点击的输出粒度上的差异。我们采用匈牙利匹配来匹配所有可能的
-
消融实验

**Tab7:**当使用多对多匹配来匹配每次点击的所有可能的真值掩码时,1-IoU@All的粒度性能得到了显著提高
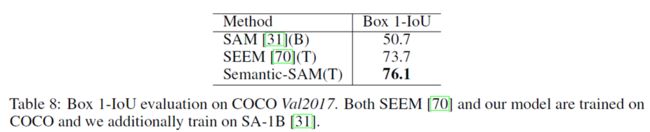
**Tab8:**1-IoU box的值,与对象级交互分割模型SEEM和多粒度模型SAM相比,Semantic-SAM有更好的性能
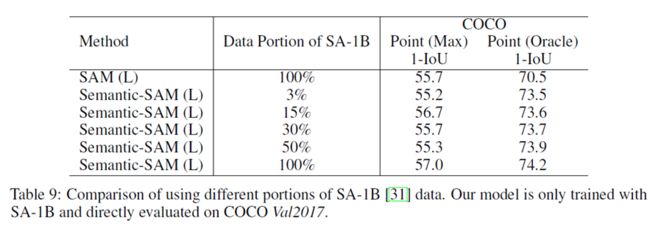
**Tab9:**使用更多SA-1B数据进行训练时COCO Val 2017的性能改进。超过总数据量的15%,性能就饱和了
结论
主要就是基于前作mask dino,结合sam的prompt思路,在sa1b和其他数据集上进行独立或联合训练。
论文很有借鉴性,可以参考其代码,结合sa1b和自己的数据集去训练,提高在自己数据集上的泛化性。
该paper的第一作者(以及同组人员)的研究路线清晰,有递进感,每个阶段承接的感觉
近两年的paper:DAB-DETR、DN-DETR、DINO、Mask-DINO、Semantic-SAM
DAB-DETR: Dynammic Anchor Boxes are better querying for DETR,动态锚框是更好的DETR查询
DN-DETR: accelerate DETR training by introducing query DeNoising,引入查询去噪加速DETR训练
DINO: DETR with Improved deNoising anchOr boxes, DETR,具有改进的去噪锚盒,用于端到端目标检测
Mask DINO: Towards A Unified Transformer-based Framework for Object Detection and Segmentation,面向一个统一的基于Transformer的对象检测和分割框架
DINO:
一种目标检测模型,属于DETR类型的检测器,是端到端可学习的
Mask-DINO:
一种统一的目标检测和分割框架。Mask DINO通过添加一个支持所有图像分割任务(实例、全景和语义)的mask预测分支,扩展了DINO(DETR with Improved Denoising Anchor Boxes)。它利用DINO的查询嵌入对高分辨率像素嵌入图进行点积来预测一组二进制mask。DINO中的一些关键组件通过共享架构和训练过程进行了扩展,以进行分割任务