Paper Reading:《LISA: Reasoning Segmentation via Large Language Model》

目录
- 简介
- 目标
- 创新点
- 方法
-
- 训练
- 实验
- 总结
简介
《LISA: Reasoning Segmentation via Large Language Model》基于大型语言模型的推理分割
日期:2023.8.1(v1)
单位:香港中文大学,思谋科技,微软亚洲研究院
论文地址:https://arxiv.org/abs/2308.00692
GitHub:https://github.com/dvlab-research/LISA
作者:
赖昕,香港中文大学三年级博士生,师从贾佳亚教授。主要研究方向是三维点云感知,迁移学习,半监督学习,小样本学习。已发表顶会顶刊论文8篇,其中一作4篇。
同等贡献
其他作者

 (Jiaya Jia:贾佳亚)
(Jiaya Jia:贾佳亚)
-
原文摘要
尽管近年来感知系统取得了显著进步,但它们在执行视觉识别任务之前,仍然依赖于明确的人类指令来识别目标对象或类别。这类系统缺乏主动推理和理解用户隐含意图的能力。在这项工作中,我们提出了一项新的分割任务–推理分割。该任务旨在根据复杂而隐含的查询文本输出分割掩码。此外,我们还建立了一个由一千多个图像-指令对组成的基准,其中包含用于评估目的的复杂推理和世界知识。最后,我们介绍了 LISA:大型语言指令分割助手,它继承了多模态大型语言模型(LLM)的语言生成能力,同时还具备生成分割掩码的能力。我们用 标记扩展了原始词汇,并提出了embedding-as-mask paradigm来解锁分割能力。值得注意的是,LISA 可以处理涉及以下方面的情况:1)复杂推理;2)世界知识;3)解释性回答;4)多回合对话。此外,当完全在无推理数据集上进行训练时,LISA 还表现出强大的zero-shot能力。此外,仅使用 239 个推理分割图像-指令对,对模型进行微调,也能进一步提高性能。实验表明,我们的方法不仅解锁了新的推理分割能力,而且在复杂推理分割和标准referring分割任务中都证明了其有效性。
目标
动机是想要实现推理分割Reasoning segmentation,即根据复杂而隐含的查询文本输出分割掩码。
如图1所示,可以处理各种场景,包括:1)复杂推理;2)世界知识;3)解释性答案;4)多回合对话。

我们为当前的多模态LLMs解锁了新的细分功能。所得到的模型(LISA)能够处理以下情况:1)复杂推理;2)世界知识;3)解释性答案;4)多回合对话
提出了模型LISA,一个大型语言指导分割助手,是一个能够产生分割掩码的多模态大语言模型。
它继承了多模态大型语言模型(LLM)的语言生成能力,同时还具备生成分割掩码的能力。我们用 标记扩展了原始词汇,并提出了嵌入作为掩码范式来解锁分割能力。
此外,为了验证有效性,我们建立了一个用于推理分割评估的基准,称为ReasonSeg。该基准包含超过1000个图像指令对,为任务提供了有说服力的评估指标。(Fig2为该数据集实例)

带注释的图像指令对的示例。左:短查询。右:长查询。
我看了一下提供的代码,个人认为,本质上就是LLaVA多模态大语言模型和SAM图像分割基础模型的组合应用。
创新点
提出了一种新的分割任务-推理分割(reasoning segmentation task)
建立了一个推理分割基准–ReasonSeg,其中包含一千多个图像指令对。
提出模型–LISA,该模型采用了嵌入作为掩码范式,增加了新的分割功能。当在不涉及推理的数据集上进行训练时,LISA 在推理分割任务上表现出了强大的zero-shot能力,并且通过在涉及推理的 239 对图像-指令对上进行微调,进一步提高了性能。
方法

给定输入图像和文本查询,多模态LLM生成文本输出。
token的最后一层嵌入然后通过解码器解码到分割掩码中。vision backbone的选择可以是灵活的(例如,SAM、Mask2Former)

LoRA:大型语言模型的低秩适配器
微调大模型的方法,可以在使用大模型适配下游任务时只需要训练少量的参数即可达到一个很好的效果。流程很简单,LoRA利用对应下游任务的数据,只通过训练新加部分参数来适配下游任务。
而当训练好新的参数后,利用重参的方式,将新参数和老的模型参数合并,这样既能在新任务上到达fine-tune整个模型的效果,又不会在推断的时候增加推断的耗时。

使用LLaVA-7B-v1-1或LLaVA-13B-v1-1作为多模态LLM ,并采用ViT-H SAM backbone 作为vision backbone Fenc。解码器**Fdec**使用的是微调的SAM的mask decoder。投影层γ是一个大小为[256,4096,4096]的MLP。
LLM: Large Language Model
LoRA: Low-Rank Adaptation of Large Language Models
LLaVA: Large Language and Vision Assistan,大型语言和视觉助手
训练
训练目标。使用文本生成损失Ltxt和分割掩码损失Lmask对模型进行端到端训练。总目标L是这些损失的加权和,由**λtxt和λmask**决定:
![]()
具体来说,Ltxt是文本生成的自回归交叉熵损失CE(auto-regressive cross-entropy),Lmask是掩码损失。为了计算Lmask,我们采用了逐像素二元交叉熵BCE损失(per-pixel binary cross-entropy)和DICE损失的组合,相应的损失权重分别为λbce和λdice。给定真值目标ytxt和M,这些损失可表示为:
![]()

从不同类型的数据(包括语义分割数据、referring分割数据和视觉问题解答(VQA)数据)中提取训练数据进行说明。
训练数据由三部分组成:
-
语义分割数据集。(使用ADE20K, COCO-Stuff, PACO-LVIS, PartImageNet, PASCAL-Part)
-
基于文本的分割(Referring Segmentation)数据集。refCOCO, refCOCO+, refCOCOg, and refCLEF 数据集
原文里是”Vanilla Referring Segmentation Dataset“,说明一下”vanilla“什么意思。
Vanilla原义香草,香草味就是老美的原味,所以vanilla这个单词引申含义就有“普通的、原始的”的意思。
-
可视化问答(VQA)数据集。使用GPT-4生成的LLaVA-Instruct-150k数据
可训练的参数
为了保持预训练的多模态 LLM(即我们实验中的 LLaVA)的泛化能力,利用 LoRA进行了有效的微调,并完全冻结了vision backbone Fenc。
解码器 Fdec 是完全微调的。此外,LLM 的词嵌入和 γ 的投影层也是可训练的
实验
训练数据:语义分割数据集、基于文本的分割(Referring Segmentation)数据集、可视化问答(VQA)数据集,再加上本篇paper建立的ReasonSeg数据集(收集了1218张图像,其中239张训练,200张验证和779张测试),该数据集作为推理分割的基准,主要目的是用于评估。
评价指标有gIoU和cIoU。 由于cIoU较偏向大面积物体,且波动较大,所以首选评价指标是gIoU。
gIoU: generalized IoU
cIoU: complete IoU
ft:表示使用 239 个推理分割图像-指令对来微调模型Tab1:reasoning segmentation推理分割结果,超过20%的gIoU性能提升来完成涉及复杂推理的任务
Tab2:vanilla referring segmentation任务的比较
Tab3:消融实验,为了验证SAM以外的Vision Backbone也适用于我们的框架,分别使用SAM和Mask2FormerSwin-L的Vision Backbone,无论我们是否在ReasonSeg训练集上微调模型,SAM都比Mask2FormerSwin-L表现更好;
同时发现对SAM的vision backbone进行LoRA微调的效果没有更好,所以没有使用LoRA微调
Tab4:在实验1和实验3,证明SAM预训练权重的有效性;实验2和3中,使γ成为MLP在gIoU中的性能几乎没有下降,但在cIoU中具有相对较高的性能;实验3和4中,比较了是否使用GPT3.5重新表述文本指令,结果证明,使用重新表述是一种有效的数据增强策略
Tab5:展示了每种类型的数据对性能的贡献,影响最大的是语义分割数据集的使用(实验4)
Fig5:提供了与现有相关工作的视觉比较,包括开放词汇语义分割模型(OVSeg)、referring分割模型(GRES)和广义分割模型(X-Decoder和SEEM)。这些模型无法处理具有各种错误的显示案例,而我们的方法产生了准确和高质量的分割结果。
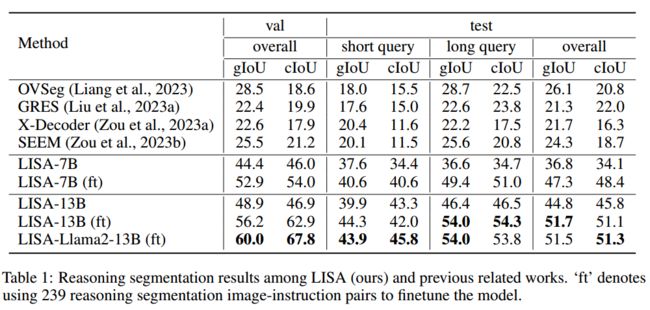
LISA 和之前相关工作的推理分割结果。ft "表示使用 239 个推理分割图像-指令对来微调模型。
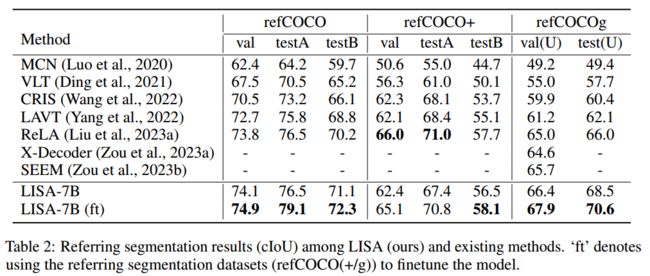
参考LISA(我们的)和现有方法之间的分割结果(cIoU)ft’表示使用参考分割数据集(refCOCO(+/g))来微调模型
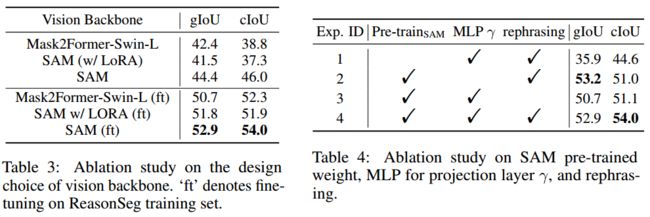
3:视觉主干设计选择的消融研究ft表示对ReasonSeg训练集进行微调
4:SAM预训练重量、投影层MLPγ的消融研究和重新表述
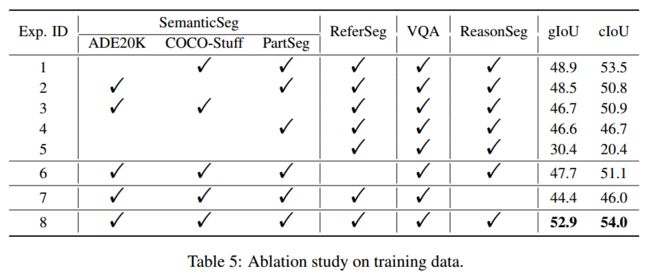
训练数据的消融研究

LISA(我们的)与现有相关方法的视觉比较。更多的例子在附录中给出。
总结
- 原文conclusion
在这项工作中,我们提出了一种新的分割任务——推理分割。该任务比普通参考分割任务更具挑战性,因为它需要模型根据隐含的用户指令进行主动推理。为了进行有效的评估,我们为这项任务引入了一个基准,即ReasonSeg。我们希望这一基准将有利于相关技术的发展。最后,我们介绍了我们的模型——LISA。通过采用嵌入作为掩模范式,它为当前的多模态LLM注入了新的分割能力,并且在推理分割任务上表现得出奇地好,即使在无推理数据集上进行训练也是如此。因此,它展示了在各种场景中与分割掩码输出聊天的能力。我们相信,我们的工作将为LLM和以vision为中心的任务相结合的方向提供新的线索。