IBM Platform LSF在IC行业内的使用


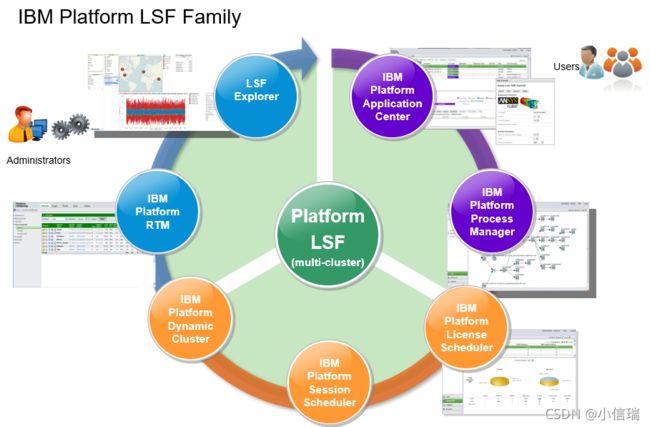
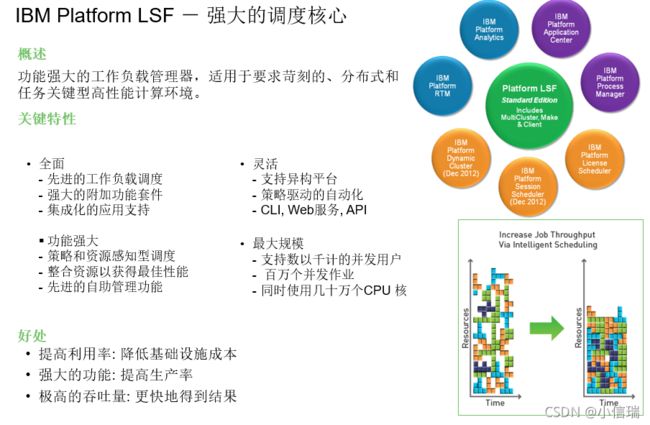
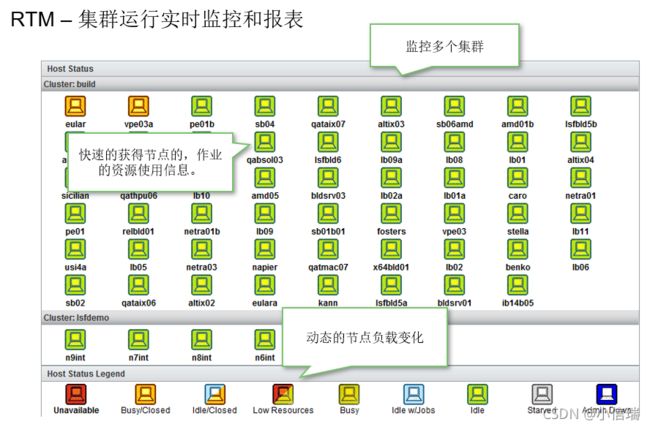


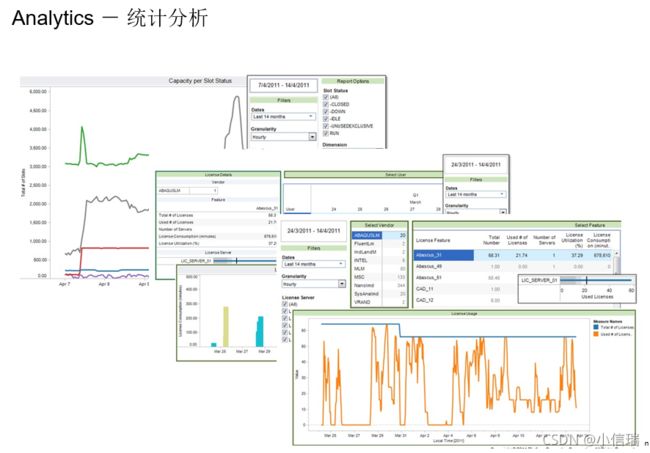
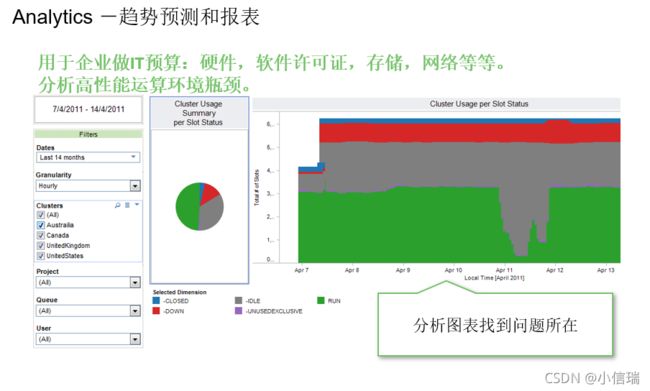
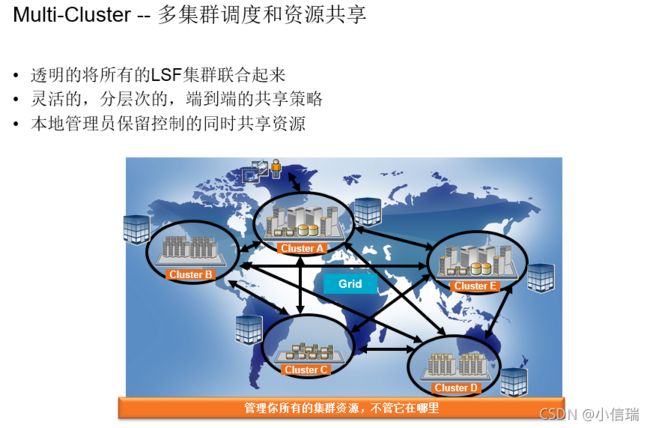
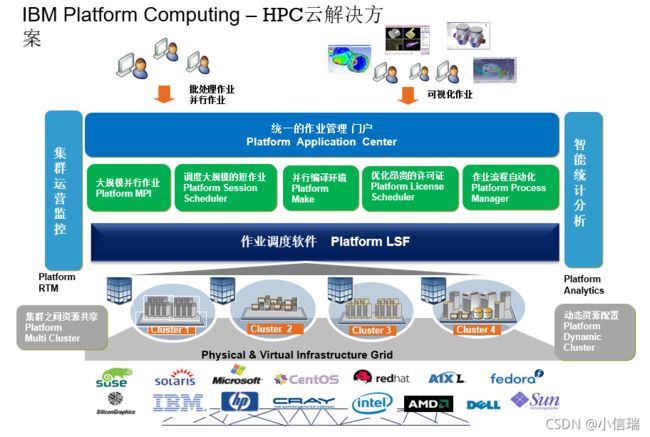

LSF在IC设计中有哪些值得匹配的
1、管理低利用率Job
•针对short normal这类队列,查询20分钟以后,Job利用率依然很低的Job信息。
•$bjobs -u all -q short -o ‘id user queue stat ugroup first_host sla idle_factor slots run_time mem max_mem avg_mem job_name:15 cmd:45 eresreq start_time cpu_used’ | grep -Ev ‘xterm|console|gnome-terminal|verdi’ | grep -v JOBID| awk ‘{if(($10>1200)&&($8<0.12)&&(KaTeX parse error: Expected 'EOF', got '&' at position 8: 8!='-')&̲&(NF!=’-’’)) print $0}’
2.允许Job可以resize
•LSF可以通过lsb.applications 引入特定设置,允许用户的Job,可以被resize。
•Job在运行过程中,调整Job所需要CPU的数量(主要是减少,增加取决于剩余CPU)
•bresize release “4*hostA" JobID
3.配置严格的LDAP群组提交权限限制
•首先,可以通过Linux群组跟项目对应的方式,将每个项目对应多个Linux群组
•然后,可以通过bsub -G ug-projectA-xx来严格限制Linux的群组跟项目提交权限统一
•需要配置3个地方:etc/egroup lsb.users etc/esub
4.自动绑定core,避免Job在多个Core上漂移
•针对单core的队列,一般我们在short和normal的队列,只允许一个Job用一个CPU core
•cpubind=“affinity[thread(1,same=numa,exclusive=(core,injob)):cpubind=thread:distribute=pack]”
•可提升Job的计算效率
5.LSF设置elim信息
•举例:获取服务器/scratch磁盘目录大小 elim.scratch
#!/bin/sh
VOLUME=/scratch
RESOURCE=scratch
while true;do
root=df --block-size=1K $VOLUME | tail -1 | awk '{print $3}'
echo “1 $RESOURCE $root”
sleep 30
done
•在lsf.shared和lsf.cluster.clusername添加scratch相关资源配置,lsload –l可查看
6.配置内存不足自动挂起Job
•可以避免服务器死机
•不止内存,还有其他资源不足,如/tmp、服务器瞬时负载过高、/scratch空间不足
•lsb.queues:
Begin Queue
QUEUE_NAME = normal
r1m = 2.0/2.5 # loadSched/loadStop
mem = 20480/5120
tmp = 40960/20480
local = 40960/20480
7.配置Explorer,ElasticSearch存储Job信息

8.配置guarantee资源池
•主要有2种方式存在:slots guarantee和hosts guarantee两种
•一般slots保障,用于大量验证的情况,比如模拟的模块spice仿真,数字的regression验证。后端K库也可以用slots保障。
•而Hosts保障,经常用于综合,STA,BES,PD&PR等场景。
•lsb.serviceclasses:
Begin ServiceClass
NAME = ProjectA_SClass
GOALS = [GUARANTEE]
ACCESS_CONTROL = USERS[ProjectA_verify]
AUTO_ATTACH = N
End ServiceClass
•lsb.resources:
Begin GuaranteedResourcePool
NAME = 36c512g_SPool
TYPE = slots
HOSTS = 36c512gS_hgrp
ADMINISTRATORS=hpc-admins
DISTRIBUTION = [noClass,3600] [ProjectA_SClass,400]
End GuaranteedResourcePool
想要了解更多LSF相关资讯,可搜索:江苏信瑞一芯科技有限公司~~~江苏信瑞一芯科技有限公司是国内IBM的银牌代理商、netapp的金牌代理商。
