python3--爬虫--微博爬虫实战
爬取目标用户的微博
- 一、目标页面
- 二、解析页面内容
- 三、整个过程
- 四、结果展示
写在前面:微博有三个网站,不同的网站爬取得难度不同,分别是
网页端: http://weibo.com;
手机端: http://m.weibo.cn;
移动端: http://weibo.cn。
本篇主要爬取微博手机端的目标用户的微博内容,所谓目标用户是指,给定的用户id,而不是通过信息搜索得到。
一、目标页面
首先确定好目标用户,这里选择知名演员李现的微博账号。爬取数据不用于非法或者违规的用途,单纯用于学习研究。
打开李现的微博主页,在链接中可以看到他的账号id是2360812967,这个是用来识别每个微博账号的id。
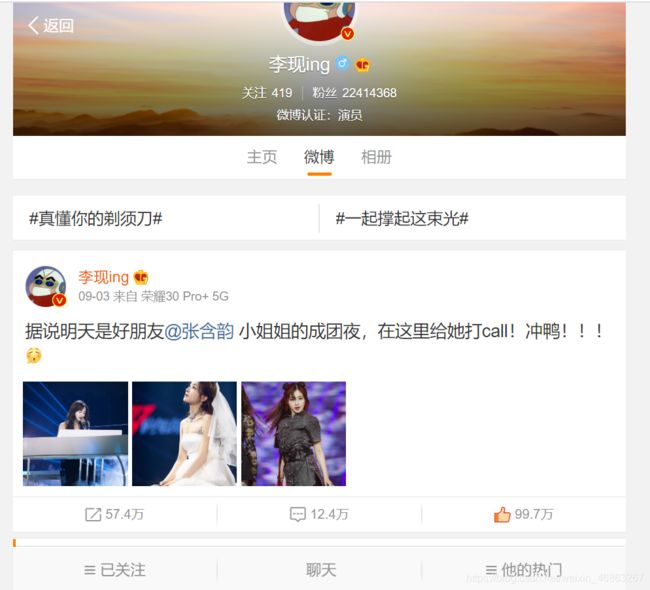
这是打开网页的源代码,会发现里面没有我们直接看到的如图中的内容,因为页面是通过Ajax动态渲染得到的,所以直接的网页源代码中没有内容。所以需要打开页面的开发者工具页面,找到对应的网页信息。在XHR中可以看到getIndex?这个链接中有对应的微博信息。而且往下滑会出现更多的微博和对应的getIndex?的链接。大概可以确定这个就是要爬取得目标页面。

接下来得问题,就是找到对应得页面得URL,尤其是向下滑得过程中产生得新的页面。
简单对比和分析可以发现,第二个getindex?开始是关于用户发博得内容。
header中得request URL分别是:
- https://m.weibo.cn/api/container/getIndex?type=uid&value=2360812967&containerid=1076032360812967
- https://m.weibo.cn/api/container/getIndex?type=uid&value=2360812967&containerid=1076032360812967&since_id=4537401894771336
- https://m.weibo.cn/api/container/getIndex?type=uid&value=2360812967&containerid=1076032360812967&since_id=4528777969276951
后面得URL中多了一个since_id 的参数,肉眼上并看不出有什么规律,但是在开发者工具页面中,可以找到这个since_id参数。比如第三个URL中的since_id参数就是从第二个URL中response中得到的since_id。即向下滑的过程中,新产生的页面链接中的since_id参数与当前页面中得到的since_id参数有关。根据这个逻辑,我们就可以构造函数来获得当前页面的这个参数组成下一个访问页面的URL链接。
def get_since_id(count_id,header,sin_id):
#构造一个函数得到当前页面的since_id参数
import requests,time
from urllib.parse import urlencode
base_url='https://m.weibo.cn/api/container/getIndex?'
info={'uid':str(count_id),
'type':'uid',
'value':str(count_id),
'containerid':'107603'+str(count_id),
'since_id':sin_id
}
URL=base_url+urlencode(info)#构造当前页面的URL
print('为了获取下一个since_id的URL:\n',URL)
r=requests.get(URL,headers=header)
#print(r.json())
if r.json()['ok']==0:#如果正常访问出错
time.sleep(3)#休眠时间
r=requests.get(URL,headers=header,timeout=6)#应该属于加载错误,重新再加载一次
if r.json()['ok']==0:
return sin_id#还是出错,则返回当前页面链接中的since_id
elif r.json()['ok']==1:#如果正常访问
try:
since_id=r.json()['data']['cardlistInfo']['since_id']
return since_id
except:
r=requests.get(URL,headers=header,timeout=6)
try:
since_id=r.json()['data']['cardlistInfo']['since_id']
return since_id
except:
print(r.json()['data']['cardlistInfo'])#最后一页没有since_id字段
return None
elif r.json()['ok']==1:
try:
since_id=r.json()['data']['cardlistInfo']['since_id']
#print('下一个since_id:',since_id)
return since_id
except:
r=requests.get(URL,headers=header,timeout=6)
try:
since_id=r.json()['data']['cardlistInfo']['since_id']
return since_id
except:
print(r.json()['data']['cardlistInfo'])#最后一页没有since_id字段
return None
解决了下一个页面的URL链接问题,接下来就是获得当前页面的有效信息内容。
def get_response(count_id,sin_id):
import requests
from urllib.parse import urlencode
base_url='https://m.weibo.cn/api/container/getIndex?'
info={'uid':str(count_id),
'type':'uid',
'value':str(count_id),
'containerid':'107603'+str(count_id),
'since_id':sin_id
}
URL=base_url+urlencode(info)
#print(URL)
#print('URL:',URL)
r=requests.get(URL,headers=headers)
response=r.json()['data']['cards']
if len(response)<10:#正常来讲,一个页面看了是有10条的微博,如果少于10条,可能是内容加载不全
r=requests.get(URL,headers=headers,timeout=6)#再次加载
response=r.json()['data']['cards']#获取内容
if len(response)==0:#如果没有微博,打印出来方便后续输出
print(response)
return response
二、解析页面内容
请求得到的内容是json数据结构,层层解析可以知道微博内容相关的信息都在【data】【cards】里面。并且是列表结构
def get_records(items):
records=[]
error_list=[]
key_error_count=0
for item in items:
#print(item)
record={}
try:
item=item['mblog']
except KeyError:
key_error_count=key_error_count+1
continue
else:
try:
record['id']=item['id']#微博id
record['created_at']=item['created_at']#发博时间
record['followers_count']=item['user']['followers_count']
record['follow_count']=item['user']['follow_count']
record['reposts_count']=item['reposts_count']#转发数量
comments_num=item['comments_count']
record['comments_count']=comments_num#评论数量
record['attitudes_count']=item['attitudes_count']#点赞数量
record['strategy_display_text_min_number']=item['number_display_strategy']['display_text_min_number']
#record['palce_name']=item['product_struct'][0]['name']
record['raw_text']=item['raw_text']#微博内容
record['pic_num']=item['pic_num']#图片数量
if record['pic_num']>0:
#如果有图片,并将每个图片的链接保存
record['pic_link_num']=len(item['pics'])
for i in range(len(item['pics'])):
link='pic_link'+str(i+1)
record[link]=item['pics'][i]['url']
records.append(record)
except:
error_list.append((item['id'],item['created_at'],item['raw_text']))
if len(records)==len(items)-key_error_count:
return records
else:
print(error_list)
return records
三、整个过程
先将目标账号的信息输入
headers={XXXX}#定义headers
id_=2360812967#目标账号信息
since_id=''#开始为空
all_records=[]#用于存放所有微博记录
n=1
import time
since_id_list=[]
while (n<20):#循环条件设置
count=0
print('==========================第%d次=============================='%n)
response=get_response(id_,since_id)
time.sleep(2)
print('本次since_id:%s'%since_id)
print(len(response))
records=get_records(response)
print('本次微博条数:',len(records))
all_records=all_records+records
since_id_list.append(since_id)
temp_since_id=get_since_id(id_,headers,since_id)
while temp_since_id==since_id and count<3:
temp_since_id=get_since_id(id_,headers,since_id)
count+=1
if temp_since_id==since_id and count==3:
print ('当前since_id加载失败')
break
elif temp_since_id==None:
print('未获得下一个since_id')
break
else:
since_id=temp_since_id
n+=1
'''for i in range(len(all_records)):
print(all_records[i])'''
print(len(all_records))
四、结果展示

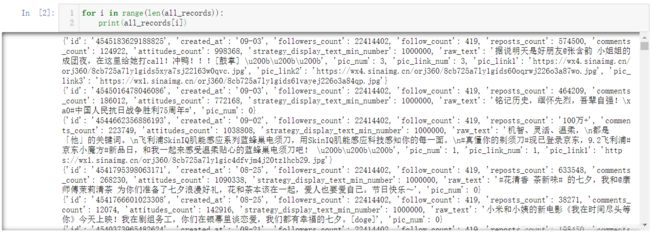

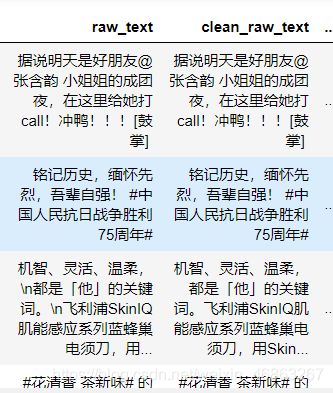
当然可以在解析页面的时候将微博的文本内容进行简单的清洗操作,比如去除换行符等,这样结果就会干净很多。
》》》最后,无论python还是爬虫都刚刚起步,如有问题欢迎指出《《《
》》》》》》》欢迎更多关于爬虫方面的交流《《《《《《《《《《