NLP模型(五)——Transformer模型实现(以一个小型文本翻译为例子)
文章目录
- 1. 数据集处理
-
- 1.1 提取源和目标
- 1.2 获取词典
- 1.3 字符串转为编号
- 1.4 得到输入输出
- 2. 制作数据管道
- 3. 构建模型
-
- 3.1 模型整体架构
- 3.2 编码器
-
- 3.2.1 Encoder 整体结构
- 3.2.2 位置编码
- 3.2.3 多头注意力机制
- 3.2.4 前馈神经网络
- 3.2.5 单层Encoder
- 3.3 编码器
-
- 3.3.1 Decoder整体结构
- 3.3.2 带mask的多头注意力机制
- 3.3.3 单层Decoder
- 3.4 预测层
- 4. 模型训练
-
- 5. 模型测试
1. 数据集处理
借由这里介绍Transformer,我们使用一个英文中文的小型翻译数据集来作为本次模型讲解的数据集,数据集下载的网址在这里 ,进去后选择英文-中文的数据集下载即可。
该数据集的格式为 English + TAB + Chinese + TAB + Attribution ,其中 Attribution 是指数据集的出处,个人用途的话不用管,数据集具体如下:
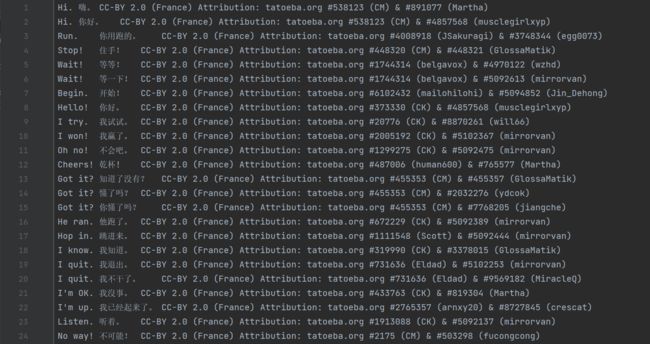
1.1 提取源和目标
首先,我们需要读取文件并将英文和中文分开,而且为了统一,我们将英文和中文的标点符号全部去掉,这个很简单,以前我们也进行过相似的处理,直接使用正则表达式即可,英文全部改成小写的字母,我们使用英文和中文的最大字符长度作为Encoder和Decoder的长度,所以还需要统计英文和中文分别的最大字符长度,代码如下:
import re
def get_sentences():
"""
得到中文和英文的最大长度,以及词源集合和目标词集合
:return:
"""
path = 'cmn-eng/cmn.txt'
# 记录中文和英文的最大长度
en_word_length = 0
ch_word_length = 0
source = []
target = []
with open(path, 'r', encoding='utf-8') as f:
# 逐行读取
for line in f:
line_data = line.split('\t')
# 去除标点符号
line_data[0] = re.sub(r'[^\w\s]', '', line_data[0])
line_data[1] = re.sub("[^\u4e00-\u9fa5]", "", line_data[1])
# 字母小写
line_data[0] = line_data[0].lower()
# 分别添加到源词和目标词中
source.append(line_data[0])
target.append(line_data[1])
# 得到最大的中文、英文长度
en_word_length = max(en_word_length, len(line_data[0].split(' ')))
ch_word_length = max(ch_word_length, len(line_data[1]))
return en_word_length, ch_word_length, source, target
max_en_length, max_ch_length, source, target = get_sentences()
1.2 获取词典
源词汇和目标词汇时字符类型的,而我们输入到模型中的必须时模型可以处理的数字类型的,这里我们采用对源词汇和目标词汇的每一个不同单词进行编号的形式,使得每一个词都有一个编号与之对应,因为英文我们是按照空格进行分词的,中文我们是按照字进行分词的,所以需要分别写两个函数。代码如下:
begin = ''
pad = ''
end = ''
def get_source_dict(sentences):
'''
得到词源的 字:索引 和 索引:字 的字典
:param sentences:
:return:
'''
source_words = set()
for i in sentences:
# 按空格进行分词
words = i.split(' ')
for j in words:
source_words.add(j)
source_words.add(pad)
# 得到 index: word 字典
idx2words = dict(enumerate(sorted(source_words)))
# 得到 word: index 字典
words2idx = {v: k for k, v in idx2words.items()}
return idx2words, words2idx
def get_target_dict(sentences):
'''
得到目标词的 字:索引 和 索引:字 的字典
:param sentences:
:return:
'''
target_words = set()
for i in sentences:
for j in i:
target_words.add(j)
target_words.add(begin)
target_words.add(pad)
target_words.add(end)
idx2words = dict(enumerate(sorted(target_words)))
words2idx = {v: k for k, v in idx2words.items()}
return idx2words, words2idx
source_idx2words, source_words2idx = get_source_dict(source)
target_idx2words, target_words2idx = get_target_dict(target)
# 字典大小
src_vocab_size = len(source_words2idx)
tgt_vocab_size = len(source_words2idx)
1.3 字符串转为编号
得到了上述的编码后,我们就可以将我们源词汇和目标词汇中每一句话的每一个词替换成相对应的编号了,注意,在这里我们需要将源词汇的长度统一为最大英文长度,目标词汇的长度统一为最大中文长度,如果长度不够,那么需要添加 pad 符进行填充。
import torch
def source_string_to_int(table, length, vocab):
"""
将每条数据按照字典对应的编码转为编码格式
string -- 输入的字符串
length -- 想要转为的编码的长度
vocab -- 字符与数字对应的字典
"""
result = []
for string in table:
string = string.replace(',', '')
# 如果大于这个长度就截断,英文按照空格分词
if len(string.split(' ')) > length:
string = ' '.join(string.split(' ')[: length])
# 填充字典里没有的字符为''的编码
rep = list(map(lambda x: vocab.get(x), string.split(' ')))
# 如果小于规定长度则用''的编码进行填充
if len(string.split(' ')) < length:
rep += [vocab[pad]] * (length - len(string.split(' ')))
result.append(rep)
return torch.tensor(result)
def target_string_to_int(table, length, vocab):
"""
将每条数据按照字典对应的编码转为编码格式
string -- 输入的字符串
length -- 想要转为的编码的长度
vocab -- 字符与数字对应的字典
"""
result = []
for string in table:
string = string.replace(',', '')
# 如果大于这个长度就截断,中文按照字分词
if len(string) > length:
string = string[:length]
# 填充字典里没有的字符为''的编码
rep = list(map(lambda x: vocab.get(x), string))
# 如果小于规定长度则用''的编码进行填充
if len(string) < length:
rep += [vocab[pad]] * (length - len(string))
result.append(rep)
return torch.tensor(result)
# 得到词源和目标词的编码
encode_input = source_string_to_int(source, max_en_length, source_words2idx)
decode = target_string_to_int(target, max_ch_length, target_words2idx)
1.4 得到输入输出
首先我们来看Transformer的结构,包含输入输出的地方有三个,
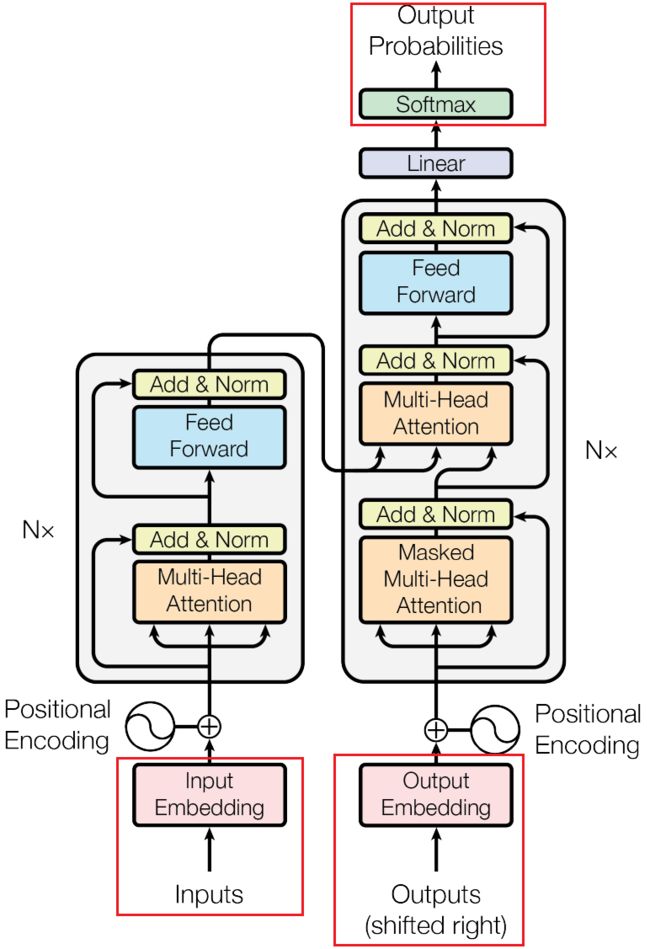
首先编码器只有一个输入,那肯定是输入的源句子,但是解码器有两个输入,一个是上面的,一个是下面的。仔细回想一下,比如 “I have a cat” 一句话中,我们需要在前面添加一个
由此,解码器的两个输入也就一目了然了,下面的输入是在前面加上一个
# 得到decode的输入,在每一句话前面加上一个begin
decode_input = torch.cat((torch.full((decode.size()[0], 1), target_words2idx[begin]), decode), dim=1)
# 得到decode的输出,在每一句话后面加上一个end
decode_output = torch.cat((decode, torch.full((decode.size()[0], 1), target_words2idx[end])), dim=1)
# decoder的长度+1
max_ch_length += 1
2. 制作数据管道
在这里我们需要的只是随机选择一个数,然后抽取对应的 encode_input, decode_input, decode_output 进行运算即可。代码如下:
import torch.utils.data as Data
# 自定义数据集函数
class MyDataSet(Data.Dataset):
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
# 设置批量大小为128,随机抽取
loader = Data.DataLoader(MyDataSet(encode_input, decode_input, decode_output), 128, True)
3. 构建模型
3.1 模型整体架构
在观看Transformer的架构之前,我们先将一些需要设置的超参数进行设置,
d_model = 512 # 字 Embedding 的维度
d_ff = 2048 # 前向传播隐藏层维度
d_k = d_v = 64 # K(=Q), V的维度
n_layers = 6 # 有多少个encoder和decoder
n_heads = 8 # Multi-Head Attention设置为8
Transformer 一层的架构如下,接下来我们按照这个架构进行构建即可。
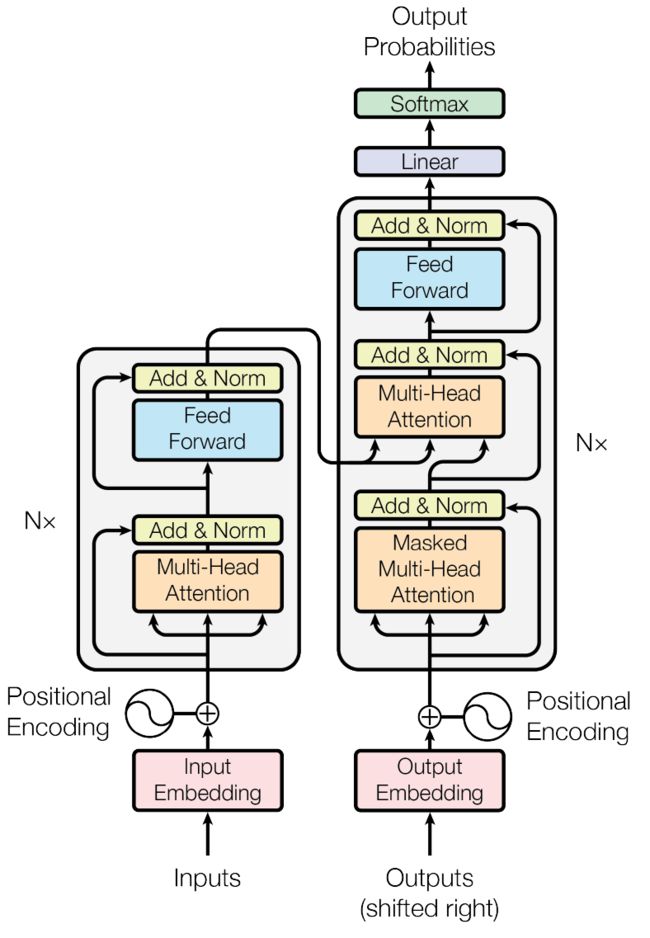
Transformer 含有若干个编码器和解码器,将待翻译的句子输入进编码器,然后将编码器的结果与翻译好的句子输入到解码器来进行解码预测,最后将其传入一个线性层加上一个softmax层计算损失,这就是Transformer的全部流程,故,我们可以构建模型结构如下:
import torch.nn as nn
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
# 编码器层
self.Encoder = Encoder().cuda()
# 解码器层
self.Decoder = Decoder().cuda()
# 线性层
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False).cuda()
def forward(self, enc_inputs, dec_inputs):
"""
整体的Transformer层
:param enc_inputs: [batch_size, max_ch_length]
:param dec_inputs: [batch_size, max_ch_length]
:return:
"""
enc_outputs, enc_self_attns = self.Encoder(enc_inputs) # enc_outputs: [batch_size, max_ch_length, d_model],
# enc_self_attns: [n_layers, batch_size, n_heads, max_ch_length, max_ch_length]
dec_outputs, dec_self_attns, dec_enc_attns = self.Decoder(
dec_inputs, enc_inputs, enc_outputs) # dec_outpus : [batch_size, max_ch_length, d_model],
# dec_self_attns: [n_layers, batch_size, n_heads, max_ch_length, max_ch_length],
# dec_enc_attn : [n_layers, batch_size, max_ch_length, max_en_length]
dec_logits = self.projection(dec_outputs) # dec_logits: [batch_size, max_ch_length, tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
3.2 编码器
知道了Transformer的整体结构后,我们首先来实现编码器,也就是上图中左边的部分。
3.2.1 Encoder 整体结构
Encoder层首先输入时将其转为Embedding形式,然后与其位置编码进行相加,通过一个多头注意力机制和一个带残差和层归一化的前馈神经网络层,然后再经过一个残差和层归一化将其传递给下一个Encoder 或者将信息传给Decoder,整体结构如下:
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
# 嵌入层
self.src_emb = nn.Embedding(src_vocab_size, d_model)
# 位置嵌入
self.pos_emb = PositionalEncoding(d_model)
# 单层Encoder
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs):
"""
enc_inputs: [batch_size, src_len]
"""
# 嵌入向量编码
enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]
# 与位置嵌入相加
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, src_len, d_model]
# 将填充的信息遮住,防止做注意力计算
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len]
enc_self_attns = []
for layer in self.layers:
# enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
接下来我们分别对其进行实现即可。
3.2.2 位置编码
编码器中的输入是嵌入向量的形式,也就是需要输入映射为 d_model 维度的向量,这里使用一层 Embedding 层即可,输入还需要采用位置编码,这里我们用Transformer原文中使用的位置编码,即奇数位置的编码为:
sin ( ω 1 ⋅ t ) , ω k = 1 1000 0 2 k / d \sin(\omega_1\cdot t),\omega_{k}=\frac{1}{10000^{2k/d}} sin(ω1⋅t),ωk=100002k/d1
其中 t t t 为每个 token 的位置,比如位置1,位置2 ⋯ \cdots ⋯ ,偶数位置的编码只需要将 sin \sin sin 变为 cos \cos cos 即可。故其实现如下:
import numpy as np
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding,self).__init__()
self.dropout = nn.Dropout(p=dropout)
pos_table = np.array([
[pos / np.power(10000, 2 * i / d_model) for i in range(d_model)]
if pos != 0 else np.zeros(d_model) for pos in range(max_len)])
# 字嵌入维度为偶数时
pos_table[1:, 0::2] = np.sin(pos_table[1:, 0::2])
# 字嵌入维度为奇数时
pos_table[1:, 1::2] = np.cos(pos_table[1:, 1::2])
self.pos_table = torch.FloatTensor(pos_table).cuda() # enc_inputs: [seq_len, d_model]
def forward(self, enc_inputs):
"""
将嵌入向量与位置编码进行相加
:param enc_inputs: [batch_size, seq_len, d_model]
:return:
"""
enc_inputs += self.pos_table[:enc_inputs.size(1), :]
return self.dropout(enc_inputs.cuda())
3.2.3 多头注意力机制
多头注意力机制实际上就是多个自注意力机制并行运算然后相加的操作,在进行多头注意力计算之前,我们需要将我们填充的长度遮住,也就是需要一个mask矩阵,因为我们填充的长度
def get_attn_pad_mask(seq_q, seq_k):
"""
将注意力矩阵中的 遮住
:param seq_q:
:param seq_k:
:return:
"""
# seq_q 用于升维,为了做attention,mask score矩阵用的
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# 判断 输入那些含有P(=0),用1标记 ,[batch_size, 1, len_k]
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)
return pad_attn_mask.expand(batch_size,len_q,len_k) # 扩展成多维度 [batch_size, len_q, len_k]
之后,计算多头注意力机制只需要传入 Q , K , V Q,K,V Q,K,V 和mask过后的注意力矩阵即可,计算如下:
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
"""
计算注意力分数
:param Q: [batch_size, n_heads, len_q, d_k]
:param K: [batch_size, n_heads, len_k, d_k]
:param V: [batch_size, n_heads, len_v(=len_k), d_v]
:param attn_mask: [batch_size, n_heads, seq_len, seq_len]
:return:
"""
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask, -1e9) # 如果是停用词P就等于 0
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]
return context, attn
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask):
"""
计算多头注意力分数
:param input_Q: [batch_size, len_q, d_model]
:param input_K: [batch_size, len_k, d_model]
:param input_V: [batch_size, len_v(=len_k), d_model]
:param attn_mask: [batch_size, seq_len, seq_len]
:return:
"""
residual, batch_size = input_Q, input_Q.size(0)
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # Q: [batch_size, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # K: [batch_size, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,
2) # V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1,
1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask) # context: [batch_size, n_heads, len_q, d_v]
# attn: [batch_size, n_heads, len_q, len_k]
context = context.transpose(1, 2).reshape(batch_size, -1,
n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v]
output = self.fc(context) # [batch_size, len_q, d_model]
return nn.LayerNorm(d_model).cuda()(output + residual), attn
3.2.4 前馈神经网络
前馈神经网络实际就是一个单纯的线性层,但是,在传入之前我们需要进行残差计算以及层归一化运算,使得训练更容易。
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False))
def forward(self, inputs):
"""
前馈神经网络
:param inputs: [batch_size, seq_len, d_model]
:return:
"""
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model).cuda()(output + residual) # [batch_size, seq_len, d_model]
3.2.5 单层Encoder
Encoder层是由很多个单层Encoder层进行叠加而来的,每一个单层Encoder都实现了上面的多头注意力机制、前馈神经网络、残差计算和层归一化,而整个Encoder层只需要堆叠单层Encoder即可,代码如下:
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention() # 多头注意力机制
self.pos_ffn = PoswiseFeedForwardNet() # 前馈神经网络
def forward(self, enc_inputs, enc_self_attn_mask):
"""
单独的编码层计算
:param enc_inputs: [batch_size, src_len, d_model]
:param enc_self_attn_mask: [batch_size, src_len, src_len]
:return:
"""
#输入3个enc_inputs分别与W_q、W_k、W_v相乘得到Q、K、V
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, # enc_outputs: [batch_size, src_len, d_model],
enc_self_attn_mask) # attn: [batch_size, n_heads, src_len, src_len]
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size, src_len, d_model]
return enc_outputs, attn
3.3 编码器
接下来我们再实现Transformer右边的结构,也就是编码器的结构。
3.3.1 Decoder整体结构
Decoder与Encoder有一些不同,不仅其内部多了一个带 Mask 的多头注意力,而且Decoder还需要接受Encoder传递过来的信息,其整体代码如下:
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs):
"""
dec_inputs: [batch_size, tgt_len]
enc_intpus: [batch_size, src_len]
enc_outputs: [batch_size, src_len, d_model]
"""
dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).cuda() # [batch_size, tgt_len, d_model]
# Decoder输入序列的pad mask矩阵
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).cuda() # [batch_size, tgt_len, tgt_len]
# Masked Self_Attention:当前时刻是看不到未来的信息的
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).cuda() # [batch_size, tgt_len, tgt_len]
# Decoder中把两种mask矩阵相加(既屏蔽了pad的信息,也屏蔽了未来时刻的信息)
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0).cuda() # [batch_size, tgt_len, tgt_len]
# 这个mask主要用于encoder-decoder attention层
# get_attn_pad_mask主要是enc_inputs的pad mask矩阵(因为enc是处理K,V的,求Attention时是用v1,v2,..vm去加权的,
# 要把pad对应的v_i的相关系数设为0,这样注意力就不会关注pad向量)
# dec_inputs只是提供expand的size的
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
Decoder中的多头注意力机制与Encoder中的一致,接下来我们对其中的带mask的多头注意力机制进行讲解即可。
3.3.2 带mask的多头注意力机制
带mask的多头注意力机制听着不同,其实也就是改变了一下mask矩阵而已,原来的多头注意力机制是将pad填充的信息进行了mask,现在是将矩阵进行上三角的mask操作,具体如下:
def get_attn_subsequence_mask(seq):
"""
获取mask过后的注意力矩阵
:param seq: [batch_size, tgt_len]
:return:
"""
# 生成上三角矩阵
attn_shape = [seq.size(0), seq.size(1), seq.size(1)] # [batch_size, tgt_len, tgt_len]
subsequence_mask = np.triu(np.ones(attn_shape), k=1)
subsequence_mask = torch.from_numpy(subsequence_mask).byte() # [batch_size, tgt_len, tgt_len]
return subsequence_mask
3.3.3 单层Decoder
Decoder是由多个单层的Decoder堆叠在一起的,这与Encoder的组成一样,因此,单层Decoder的计算就显得尤为重要,根据Transformer里面的结构,其既需要带mask的多头注意力,又需要不带mask的多头注意力,需要注意的是,不带mask的多头注意力这里是将Encoder信息结合的点,其 K , V K,V K,V 使用的是Encoder传递过来的信息进行变换的,而其 Q Q Q 依然使用的是Decoder的信息,代码实现如下:
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
"""
计算单独的解码层
:param dec_inputs: [batch_size, tgt_len, d_model]
:param enc_outputs: [batch_size, src_len, d_model]
:param dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
:param dec_enc_attn_mask: [batch_size, tgt_len, src_len]
:return:
"""
# 带mask的多头注意力
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs,
dec_inputs, dec_self_attn_mask) # dec_outputs: [batch_size, tgt_len, d_model]
# dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
# 不带mask的多头注意力,其 Q 是Decoder的信息,K,V都是Encoder的信息
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs,
enc_outputs, dec_enc_attn_mask) # dec_outputs: [batch_size, tgt_len, d_model]
# dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs = self.pos_ffn(dec_outputs) # dec_outputs: [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attn, dec_enc_attn
3.4 预测层
最后的预测层也就是一个线性层加上一个softmax即可,跟一般的预测输出一样,这块在Transformer的整体架构那里已经进行了实现。
4. 模型训练
构建完模型后,就需要对模型进行训练了,将模型的输出与现实的输出做交叉熵损失,当作模型的损失,代码如下:
def train():
model = Transformer().cuda()
model.load_state_dict(torch.load('transformer.params'))
#忽略 占位符 索引为0
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.99)
pre = 100000
for epoch in range(100):
epoch_loss = 0
for enc_inputs, dec_inputs, dec_outputs in loader:
enc_inputs, dec_inputs, dec_outputs = enc_inputs.cuda(), dec_inputs.cuda(), dec_outputs.cuda()
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
loss = criterion(outputs, dec_outputs.view(-1))
epoch_loss += loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(epoch_loss))
# 如果训练的损失减小,则保存模型
if epoch_loss < pre:
torch.save(model.state_dict(), 'transformer.params')
pre = epoch_loss
train()
5. 模型测试
训练好模型后,需要进行模型的测试,比如使用一个 “I have an apple” 进行测试,但是,我们模型的输入 model(enc_inputs, dec_inputs) 中前一个参数是Encoder的编码,可以得到,但是后一个参数是Decoder的编码,这是我们需要预测的信息,这怎么进行输入呢?
这里,我们可以将模型拆为Encoder和Decoder,分别使用其两个部分的信息,先使用Encoder编码得到编码信息,然后从
def detect(words):
clone = Transformer()
clone.load_state_dict(torch.load('transformer.params'))
clone.eval()
# 编码
words = words.lower()
enc_input = list(map(lambda x: source_words2idx.get(x), words.split(' ')))
if len(words.split(' ')) < max_en_length:
enc_input += [source_words2idx[pad]] * (max_en_length - len(words.split(' ')))
enc_input = torch.tensor(enc_input).view(1, -1).cuda()
# 从 begin 编码开始逐个预测
start_symbol = target_words2idx[begin]
enc_outputs, enc_self_attns = clone.Encoder(enc_input)
dec_input = torch.zeros(1, max_ch_length).type_as(enc_input.data)
next_symbol = start_symbol
for i in range(0, max_ch_length):
dec_input[0][i] = next_symbol
dec_outputs, _, _ = clone.Decoder(dec_input, enc_input, enc_outputs)
projected = clone.projection(dec_outputs)
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
next_word = prob.data[i]
next_symbol = next_word.item()
print([target_idx2words[n.item()] for n in dec_input[0]])
detect("I have an apple")