促科技创新:高德数据优化篇之OceanBase最佳实践
*作者介绍:振飞(高德地图总裁)、炳蔚(高德技术服务平台负责人)、福辰(高德服务端架构师)
*原文首发:微信公众号“高德技术”
高德成立于 2002 年,是中国领先的移动数字地图、导航及实时交通信息服务提供商,向终端用户提供包括导航、本地生活、叫车等服务的一站式入口。从拥有甲级测绘资质的领先地图厂商,到首家成功转型移动互联网的地理信息企业,再到国民出行平台,以及出门好生活开放服务平台。业务一直在进化,但高德“让出行和生活更美好”的初心未变,本质的核心专注点一直没有改变,就是地图导航,拥有从数据到软件到互联网的完整研发能力和经验,同时在人工智能、大数据、计算机视觉等一系列新技能方面也拥有深厚的积累。
地图是什么?它是真实(物理)世界在网络空间的数字化映射;高德的目标就是“连接真实世界,做好一张活地图”。作为如今各行各业都非常关注的一个概念,“数实融合”代表大家对于实体经济进一步升级发展的期望,代表着能力和效率的现象级提升,以及面向用户和消费者的更优质产品和服务。而要做到这一点,其中的关键在于推动实体经济和数字经济的高度融合,对于高德地图所在的交通出行行业来说,也是如此。我们致力于用“促科技创新、与生态共进”的方针,助力交通产业更好的实现数实融合。
从高德的视角,对于“数实融合”的理解是什么样的?一方面,我们明确了包括人、车、路、店等在内的实体要素,才是交通出行产业中的真正主体,相关领域中耕耘多年的企业和机构,才是真正值得尊重的老师傅,他们在各自领域的专业度和经验不可或缺;另一方面,科技创新平台提供了交通服务和海量用户之间的连接能力、数字化的展示平台,提供了产业要素转化为数据的能力,并且还能为各类新型交通服务提供强大的计算能力。
高德的二十余年,始终与大交通产业中其他领域的老师傅携手共进,尊重他们的专业领域,尊重他们的不可或缺,才得以与他们建立起了深厚的合作关系,成为他们服务的科技标配。2022 年 10 月 1 日,中国国庆黄金周假期的首日,高德实现了创纪录的 2.2 亿日活跃用户。在 2023 年 3 月,受到日益增长的同城通勤和城际出行需求推动,高德的日均活跃用户数量达到了 1.5 亿的新纪录。
高德一直不断地探索和应用新的技术,以持续提升用户体验、提高效率和降低成本。
首先是北斗高精度定位。作为一家科技企业,高德有幸见证了北斗从起步到世界一流的发展历程。尤其是 2020 年的北斗三号全球组网成功,客观上帮助我们在产品研发上迅速打开了新局面,车道级导航、智能红绿灯、绿色出行和位置共享报平安等一系列基于北斗高精尖技术的服务得以在手机上落地,并获得了行业内外的好评。如今,高德地图调用北斗卫星日定位量已超过 3000 亿次,且在定位时北斗的调用率已超越了 GPS 等其他卫星导航系统。
互联网地图用户高并发访问和随之而来的海量数据存储处理,是我们必须应对的技术难题。其中,云原生和行业无关化架构是高德地图服务端未来的努力方向。云原生是一个新的软件架构模式,它将应用程序和系统环境抽象化,并将它们封装到容器中,以实现快速、可靠和可扩展的部署和管理;云原生是未来软件架构的发展趋势,它的本质是更高维度的抽象、封装和屏蔽,高德地图服务端会聚焦于把云原生相关技术用到日常应用研发,以提高生产力,快速迭代产品,跟业务一起给用户最好的体验。行业无关化架构是针对高德应用的特点提出的,核心是解决研发效率的问题,业务上让更多的行业快速接入高德,技术上尝试元数据驱动+多租户隔离,屏蔽行业变化对底层的影响,做到行业无关化架构,以进一步提高生产力。
随着“高德地图”成为用户出行必备工具之一,其中数据的存储、加密、快速检索和绝对安全就非常重要,是我们工作的重点,目的是让用户在任何时刻、不同的端设备上都能快速的获得自己想要的真实世界的信息,让用户出行更美好。随着业务后续发展很快就会进入万亿时代,无论是存储成本,还是针对数据查询的性能来讲,数据治理对我们来说显得尤其重要,我们要让数据快速发挥出价值,带给用户最真实最实时的数据,还不会过度的浪费成本。
经过长时间的调研和测试对比,我们决定采用性价比极高的 OceanBase 来迎接高德万亿(条)数据时代!

正因为真实世界的数据存储量大,高德采用 OceanBase 来解决,此篇文章会让大家看到 OceanBase 在高德的实践体会,我们会从不同的视角去诠释整篇文章。整体如下:
-服务端的视角
1)我们为什么选择 OceanBase?
2)OceanBase 在高德落地过程中分应用的融合方案、痛点和收益?
3)OceanBase 在高德应用中未来的规划?
-读者的视角
1)高德为什么选择 OceanBase,背后选择的原因是什么?
2)高德怎么用 OceanBase 的,方案是什么,遇到了哪些问题,解决方案是什么?
3)OceanBase 在高德应用场景中,表现结果怎么样?稳定性和性能怎么样?降本效果怎么样?
4)结合我们自己的场景哪些可以用 OceanBase 帮我们解题?
-本文围绕以下几点来贯彻核心思想:
1)了解选择 OceanBase 的原因,了解 OceanBase 的落地实践;
2)了解分布式数据库和 OceanBase 相关技术内幕;
3)作为工具文章,在犹豫是否选择 OceanBase 的时候会给大家一些思路。

市场上提供的数据存储产品有很多, 简单罗列几个常用的(排名不分先后,没写进来的不代表不好)。
-
PolarDB
-
Lindorm
-
OB
-
ES
-
MongoDB
-
...
每种存储都有自己的特色,有关系型数据库,有分布式数据库,有列族数据库等在不同的场景都表现十分出色。然而我们为什么选择了 OceanBase 呢?
其实从 2021 年开始,我们就一直在做一个事,就是去 MongoDB。过去高德有一些业务服务用的 MongoDB 做存储,由于 MongoDB 的特性和设计特点,导致它偶尔会出现 CPU 占用很高,服务Pause无法正常提供服务。 对于上游来说体现就是超时问题了,如果访问量大且重试带来的阶梯效应就是毁灭的,服务基本被打垮。很多时候不是 MongoDB 本身的问题,它定义是分布式文档存储系统,通过 Documents 的方式来维护数据,理论上在关系型比较重的场景上确实不太适合。
后来我们服务就相继的迁移到 XDB、Lindorm、ES。选择 ES 是因为成本低和稳定性高;选择 Lindorm 是因为对于我们的异构场景、Key Value 场景和减少请求穿透到 XDB 的场景非常合适。那么就剩下数据库选型了,虽然 OceanBase 是 NewSQL 数据库,但是他保留了关系型数据库的特性,让我们以 NewSQL 的方式去管理数据,但不是说明任意场景都比较适合,在结构化数据量大的体系中,OceanBase 在降本上非常具有优势。
那么这里又有一个疑问?Lindorm 和 ES 不也可以做这种存储吗? 存储和检索都非常高效。 但是从工具的角度 Lindorm 和 ES 对我们来说都是加快检索和异构检索使用的,无法真正像关系型数据库那样去使用,往往后面都会存在一个数据库,会严重增加数据沉余和成本。
针对数据库的场景,我们其实都关注两点:OLTP 和 OLAP。PolarDB 是天然的 OLTP,分布式 MySQL 引擎后续架构也支持了 OLAP 设计。 然而 OceanBase 本身设计就是 NewSQL 模式,天然具备 OLTP 和 OLAP 两种场景,而且针对大数据有自己的压缩体系,在降本和应用都有天然的优势。
1.1 OceanBase 基础属性信息

图 1.1 OceanBase的基础属性信息
1.2 多方权衡后,为什么选择 OceanBase?
1)OceanBase 是基于 Paxos 一致性协议实现的数据多副本存储(多版本并行提交),满足多数派即可返回,最终一致性。
2)采用无共享的多副本架构,系统没有单点障碍,保证系统持续可用。即使单副本出现故障,也可以达到多数派可用。
3)OceanBase 是可以动态扩容的,扩容后分区表的数据会自动均衡到新节点上,对上层业务透明,节省迁移成本。
4)OceanBase 存储具有高度压缩的能力,数据可以压缩到原有数据到三分之一,对于存储量大的业务会极大降低存储成本。
5)OceanBase 作为准内存数据库,采用 LSM-Tree 存储引擎,增量数据操作内存,减少随机写,读写性能超传统关系型数据库,而且支持 Hash 和 B+Tree。
6)比较重要的是 OceanBase 也支持MySQL的协议,可以直接使用 MySQL 驱动访问,可以基本完全的将 OceanBase 当成分布式的 MySQL 使用。
在布式数据库出来之前,针对大数据量的读写场景广泛采用分库分表方案,也由此诞生了很多分库分表、读写分离中间件。这些方案虽然能带来一定的效果,也会引发一些后遗症,比如:
-
需要提前规划好分片规则,一旦定好规则就难以移动,扩展困难
-
分得太细会浪费资源,分得太粗会导致二次拆分
-
数据迁移困难
说到这里,大家应该还没太多体感,那么我们会从分布式数据库和 OceanBase 的一些技术角度去诠释上面的决策点(为方便更好的做决策,主要讲一些相应的分布式数据库和 OceanBase 技术原理,了解的同学可以直接跳过)。

2.1 云原生数据库的发展历程
云原生分布式数据库发展历程,经历以下 3 个阶段。
-
单机:传统单机数据库、依赖高端硬件、系统难以扩展、成本高。
-
PG-XC:基于中间件的分布式数据库(TDDL)。待解决全局一致性、跨库事务、复杂的 SQL 等问题。
-
NewSQL:高可用、水平扩展、分布式事务,全局一致性、复杂 SQL、自动负载均衡、OLAP 等。
-
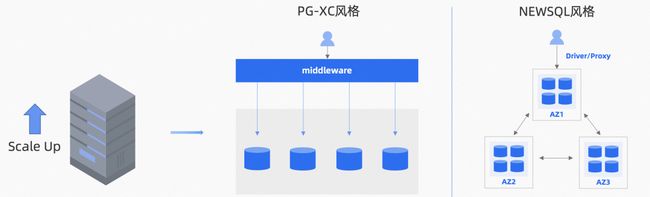
图 2.1 数据库发展历程 (图片引自OceanBase)
3 个阶段衍生出 3 种架构,但是统一被归整为 NewSQL 和 PG-XC 的 2 大类风格
-
Sharding on MySQL:一般我们可以在应用侧或者代理层做分片来管理多个 MySQL 物理库,以解决单机容量和性能不足的问题。现在正在使用的 TDDL 就是该架构,虽然计算存储资源可扩展,但在扩展和数据迁移时,业务系统层面需要做不少改造和业务数据的灰度,为了保证业务不停机会产生比较大的改造成本和数据迁移的风险。(PG-XC风格)
-
NewSQL:国内以 TiDB 和 OceanBase 为代表的原生支持分布式的关系型数据库,主要也是为了解决 MySQL 的问题。和 Sharding on MySQL 不同的是,NewSQL 将分片功能作为数据库的一部分来实现,并提供了动态扩缩容的能力,且对上层业务透明,具备透明可扩展性。
-
Cloud Native DB:云原生数据库国内以 PolarDB 为代表,具备池化的资源,也可以实现存储资源的动态扩缩容,其一般采用的主备方式来实现高可用,同时其扩容和主备探活等功能需要大量依赖外部系统。(PG-XC风格)
-

图 2.2 数据库3种架构 (图片引自阿里云[1])
从架构体系又分为 2 种流派:
-
Share-Nothing:架构的每个节点有独立的计算和存储功能并且节点之间不共享数据
-
无状态 SQL 计算节点,无限水平扩展
-
远程存储,共享存储节
-
强 SQL 支持( 系统自动扩展路由 )
-
和单机一样的事务支持
-
跨数据中心故障自动恢复
-
无限的弹性水平扩展
-
Share-Everying:也叫 Share-Storage,即 Share-Disk,架构是在存储层做了统一和共享,但计算节点是独立节点
-

图 2.3 数据库架构的2种流派 (图片引自论文Survey of Large-Scale Data Management Systems for Big Data Applications)
从上述图可以看出来,Share-Everying 的存储是共享的,前面计算节点多,查询量极大的情况下就会造成共享存储压力过大,导致查询性能非常低下。Share-Nothing 的则不然,有独立的计算和存储节点,数据不共享性能可靠,市面上的 NewSQL 大多数都是依照 Google 的 Spanner/F1 来进行设计的,这里先简单介绍下 Spanner/F1 职责:
-
F1 设计的目标
-
无限弹性水平扩展
-
跨数据中心故障自愈
-
事务的 ACID 一致性
-
全面的 SQL 支持,支持索引
-
-
Spanner 设计的目标
-
管理跨数据中心复制的数据
-
重新分片和平衡数据的能力
-
跨数据中心迁移数据
-
到这里想必大家都知道什么是 NewSQL 了, 完美的具备关系型数据库的基因且具备更加强的扩展性和性能,其实 NewSQL 跟分布式数据库不能完全画等号的。NewSQL 还是遵循事务 ACID,SQL 引擎那一套,保证的是无缝迁移。但是分布式数据库强调的是最终一致性,也是 NewSQL 要体现的,所以 NewSQL 是在原生分布式数据库上构建而成的“云原生分布式数据库”,有点绕嘴,用简单的描述来阐述下两种事务模型,大家平时用的最多的也是事务相关。
2.2 OceanBase 的技术内幕
数据库有 3 大特征,上文介绍了 OLTP 3 大特征(SQL 解析、事务、存储)中的 2 种,分别为事务&存储。 接下来会介绍 OceanBase 的技术内幕。然后也会介绍下 OceanBase 在 OLAP 上的表现。
先介绍OLAP 3 个特性:列存(解决宽表)、压缩(减少存储空间)、向量化 SIMD (Single Instruction Multiple Data) 即单条指令操作多条数据——原理即在 CPU 寄存器层面实现数据的并行操作
一、 OceanBase 存储引擎

图 2.4 OceanBase存储引擎架构 (图片引自OceanBase)
关键设计:
1)基于 LSM 理念自研底层存储引擎,未选择 RocksDB
2)宏块与微块存储介质,微块是数据的组织单元,宏块则是由微块组成。Compact 操作时可以在宏和微块两个级别判断,是否复用
3)多 Parttion 多副本解耦 Compact 操作,避免磁盘 IO 竞争
4)控制 User IO/System IO,减少前台请求影响
5)按行存储,按列编码,减少体积
6)三副本 Compaction 的 Checksum 防止静默错误
7)支持分布式事务
8)支持 B+Tree 和 Hash 索引模式,针对热数据做了很多优化,查询效率很高,本身也通过 Bloom Filter Cache 来加速查询
特性:
-
低成本,自研行列混存的压缩算法,压缩率较传统库提高 10+ 倍。
-
易使用,支持活跃事务落盘来保证大事务的正常执行和回滚。多级转储和合并来平衡性能和空间。
-
高性能,提供多级缓存保证低延时。OLAP 操作提供向量化支持。
-
高可靠,全局合并时多副本比对和主表与索引表比对校验和来保证用户数据正确性。
多类型缓存, 覆盖数据访问全链路
-
数据缓存:
-
Bloom Filter Cache:维护缓存静态数据的 Bloom Filter,快速过滤无需访问的数据。当一个宏块上的空查次数超过某个阈值时,就会自动构建 BloomFilter Cache。
-
Row Cache:数据行缓存,在进行单行或多行访问时构建并命中。
-
Block Index Cache:描述对每个宏块中所有的微块的范围,用于快速定位微块。
-
Block Cache:微块缓存,在对数据块访问是构建和命中。
-
Fuse Row Cache:数据在多 SSTable 中的融合结果。
-
···
-
-
Metadata缓存:
-
Partition Location Cache:用于缓存 Partition 的位置信息,帮助对一个查询进行路由。
-
Schema Cache:缓存数据表的元信息,用于执行计划的生成以及后续的查询。
-
Clog Cache:缓存 Clog 数据,用于加速某些情况下 Paxos 日志的拉取。
-
总结:
-
改进底层 SSTable 的存储结构,通过宏和微块的模式,解决写放大的问题,而且可以随时调整 Compact 时机,在挪移 Parttion 的时候,底层数据存储单元非常适合快速移动。
-
本身 OceanBase 也会对底层存储进行监控,控制 Compact 时机,不会导致前端请求收到影响,在 Compcat 也会针对数据进行对比,防止静默导致数据错乱,而且压缩比高,整体体积很小。
-
讲解存储和为什么 MySQL 不能 Online DDL 等。 主要介绍 B+Tree 和 LSM 的存储区别。
二、数据复制-Paxos

图 2.5 数据复制Paxos (图片引自OceanBase)
关键设计:
1)Paxos 与 Raft 最本质的区别是在于是否允许日志空洞,Raft 必须是连续的,只能串行无法并行,Multi-Paxos 允许日志空洞存在,应对复杂的网络环境更鲁棒。(市面上有很多针对 Raft 的优化,以 Beth Index 的方式去批量迭代 Index 等)
2)一次 WAL 日志
示例:顺序投票策略对于主库的负面影响比较严重,出于性能提升的原因,数据库的 MVCC 使得不存在相互关联的事务以并发处理,但是上述的顺序投票策略是的事务 #5-#9 可能被毫不相干的事务 #4 阻塞,且必须 Hold 在内存,如果是允许日志空洞,事务 #5-#9 就可以继续执行,#4 后续在落盘
三、数据复制-延展
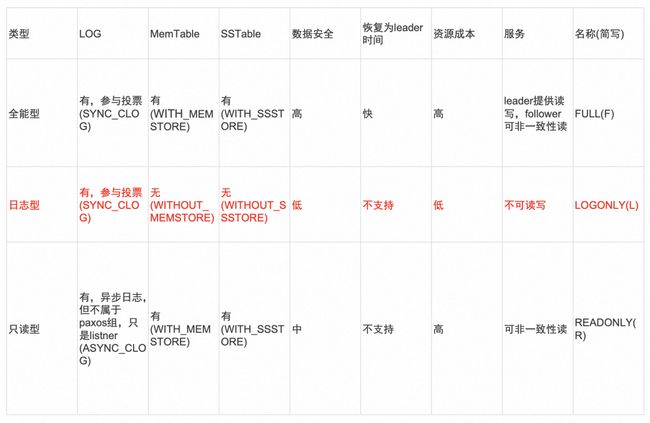
图 2.6 数据复制延展-副本类型 (图片引自OceanBase)
关键设计
1)全能型副本:拥有事务日志,MemTable 和 SSTable 等全部完整的数据和功能。可以随时快速切换为 Leader 对外提供服务。
2)日志型副本:只包含日志,没有 MemTable 和 SSTable,只参与投票和对外提供日志服务,也可以参加其他副本回复,但是不能对外提供服务。
3)只读型副本:拥有事务日志,MemTable 和 SSTable 等全部完整的数据和功能。他的日志比较特殊,它不作为 Paxos 承运参与投票,而是作为观察者实时追赶日志,然后在本地回放。对业务取数据一致性要求不高的时候提供只读服务。
四、分布式事务
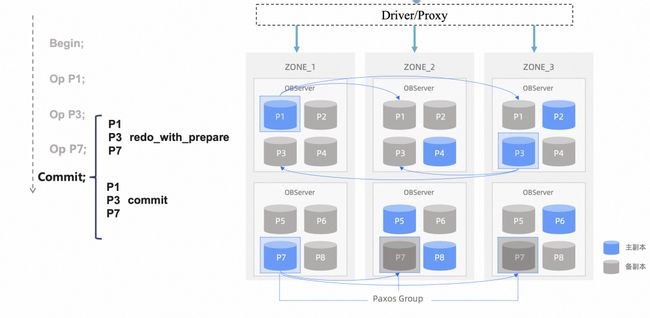
图 2.7 分布式事务 (图片引自OceanBase)
关键设计:
分布式事务:2pc + gps 线性一致性事务事务流程:
1)prepare:生成 prepare version = max(gts,max_readable_ts,log_ts)。
2)pre commit:推高本地Max readable timestamp。
3)commit/abort:日志多数派成功之后,解行锁,应答客户端。
4)clear:释放参与者上下文。
Percolator 模型
关键设计:
1)事务第一个分区作为协调者,其他分区作为参与者,事务本地提交,无需等待其他参与者返回。
2)参与者粒度分区,少部分分布式事务。
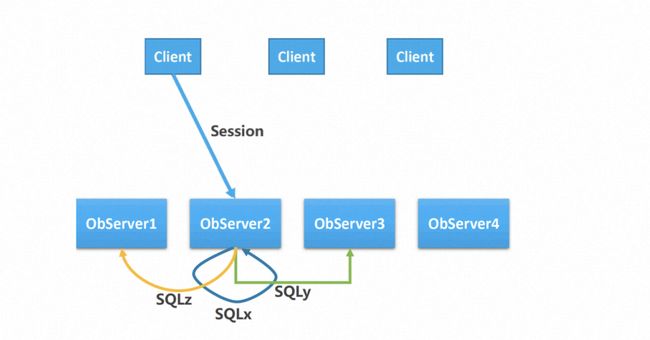
图 2.8 Percolator事务模型(图片引自OceanBase)
扩展:
1)租户级别的 GPS,基于 Paxos 保障稳定性。
2)实现类似 Truetime 的机制,在保证正确的情况下,允许多个事务复用 SYS,减少压力。
提前解行锁:
优化前:一个事务持锁的时间,包括了 4 个方方面:
1)数据写入
2)日志序列化
3)同步备份机网络通信
4)日志刷盘的耗时

图 2.9 事务优化过程解析 (图片引自OceanBase)
优化后:
1)日志序列化完成,提交到 Buffer Manager 之后。
2)就开始触发解行锁操作,不等日志多数派刷盘完成,从而降低事务持锁时间。
3)当事务解锁之后,允许后续事务进来操作同一行,达到多个事务并发更新的效果,提高吞吐。
五、向量化+并行执行引擎
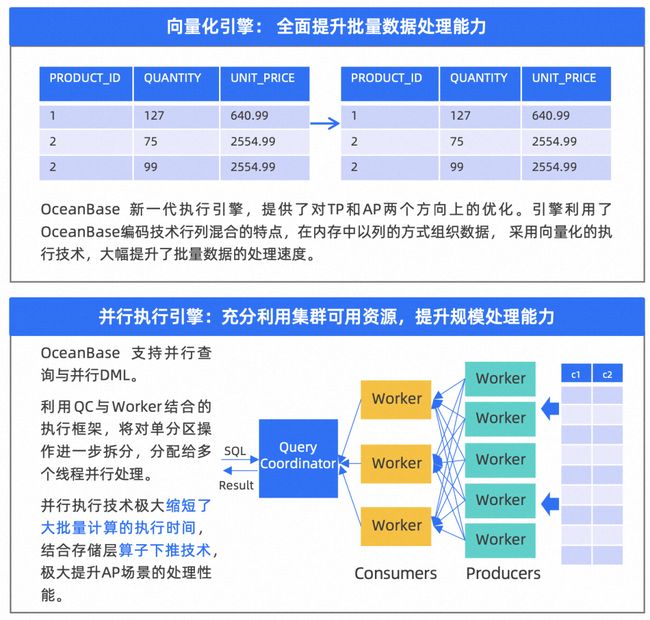
图 2.10 OceanBase并行引擎&向量化 (图片引自OceanBase)
上文提到了,AP 数据库 3 大特性,向量化,数据压缩,列存。OceanBase 的引擎在 TP 和 AP 上都有不错的表现,支持了向量化和并行执行引擎,提升了规模化处理逻辑。
六、 空间优化
OceanBase 的存储上是行列混存的,底层 SSTable 由若干个宏块(Macro Block)构成, 宏块 2M 固定大小的长度不可更改。在宏块内部数据被组织为多个大小为 16KB 左右的变长数据块,称之为微块(Micro Block),微块中包含若干数据行(Row),微块是数据文件读 IO 的最小单位。每个数据微块在构建时都会根据用户指定的压缩算法进行压缩,因此宏块上存储的实际是压缩后的数据微块。
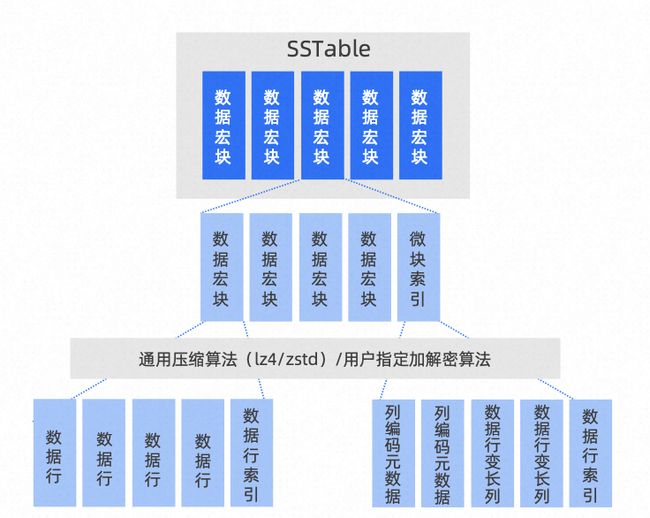
图 2.11 OceanBase的存储引擎空间优化 (图片引自OceanBase)
行列混合的存储结构 :
SSTable 由多个定长(2MB)的宏块组成,而每个宏块由多个变长的微块组成。微块是读 IO 的最小单位。OceanBase 微块有两种存储方式,平铺模式(Flat)或编码模式(Encoding) :平铺模式即为通常意义上的行存形态,微块内数据以行的顺序连续存储;编码模式在微块里仍旧存储完整的行数据,但存储组织方式则按照列的形式。OceanBase 根据数据格式与语义选择多种编码手段,以达到最佳的压缩效果。同时,在执行过程中,数据以列的组织方式载入内存提供给向量化引擎,进一步提升 HTAP 处理性能。
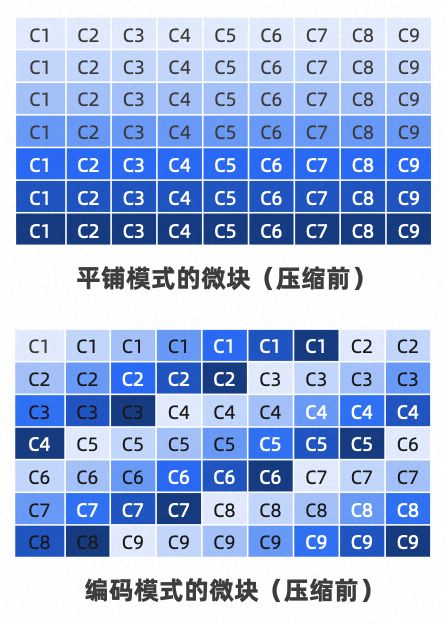
图 2.12 行列混合模式图形详解 (图片引自OceanBase)
OceanBase 数据库提供了多种按列进行压缩的编码格式,根据实际数据定义进行选择,包括列存数据库中常见的字典编码,游程编码 (Run-Length Encoding),整形差值编码 (Delta Encoding),常量编码,字符串前缀编码、Hex 编码、列间等值编码、列间子串编码等。
七、OLAP 场景支撑
上文我们说了,OLAP 场景 3 大特征 向量化 + 列存储 + 数据压缩是 AP 场景的大杀器,从上面介绍我们看到了,OceanBase 是一个引擎满足 TP 和 AP 两个场景。
-
支持列存和行存
-
支持向量化
-
支持并行计算
-
支持数据压缩,根据不同的类型压缩类型也不同
美中不足的是 OceanBase 在 AP 上支持不是特别完美,还在优化中。虽然支持列存储,但从原理上一个大宏块里面包含很多个小微块,宏块层面,数据还是按行扫描,微块层面,一个微块可能包含若干行,这些行是按列存储的。所以 OceanBase 这个架构还是行存架构,只有微观层面能享受部分列存带来的好处,想要彻底提升分析型性能表现,需要一个彻底的列存引擎。
八、OceanBase 更多场景支持
因为高德业务比较多样化,分别有结构化和非结构化的场景,OceanBase 在支持高德业务的同时也衍生迭代了不同功能行产品。
-
OceanBase 正常模式
-
OceanBase Key-Val模式
-
OceanBase NoSQL模式
-
OceanBase 纯列存模式
-
OceanBase Serverless模式

OceanBase 在高德多个业务场景均有落地,支撑着高德业务数据的稳定性下面将介绍三个不同架构下,典型的业务落地场景:
-
强一致金融场景的业务落地
-
海量数据,多点写入场景落地
-
中心写单元读场景落地
3.1 强一致金融场景落地实践
一、业务背景及诉求
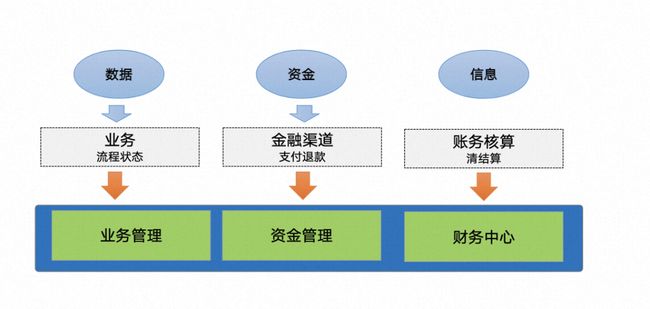
图 3.1 财务结算业务架构
高德 359 行财务结算服务主要服务于高德信息业务的结算和财务数据,主要诉求是要求数据强一致性,保障数据不丢失,跨地域容灾能力。
二、业务痛点与技术解题
-
财务结算服务作为与 B 端商家合作的钱款计算的一环,对数据一致性有极高的要求,不能出现因数据不一致或最终一致而导致钱款计算错误的情况。
-
财务结算服务业务逻辑复杂,需要降低迁移改造成本,最好能完整兼容原业务所使用的 SQL 协议,平滑替换底层数据库,不需要业务过多的改造。
-
为了提升财务结算系统的数据强一致性,优先选择了三机房的部署架构。
业务架构图如下,图中红框内容即本次数据迁移 OceanBase 时涉及到的系统改造部分,使用 Diamond 做 XDB 和 OceanBase 的数据源路由控制,通过 OMS 做数据迁移,并使用MAC进行迁移前后的两份数据的核验。
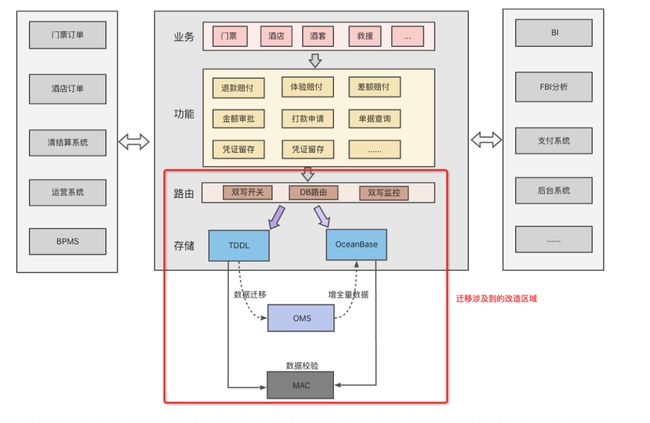
图 3.2 财务结算OB改造设计
三、为什么选择 OceanBase?
1)财务需要数据的强一致性和跨地域容灾,而 OceanBase 提供的能力完美支持该需求,其提供的跨地域部署的能力,可使得财务数据同时写入多地域的数据副本中,即使一地域不可用后仍然能保证有完整的数据可用。并且 OceanBase 的 Paxos 一致性协议可保证 OceanBase 多副本数据写入成功后才应答成功,为分布式多副本数据的强一致提供了保证。
2)为了验证和解决 SQL 兼容问题,未使用 OceanBase 提供的 OceanBase Client 去访问 OceanBase,而是使用原生的 MySQL 数据库 的SDK 驱动,通过 MySQL 驱动访问 OceanBase,在 OceanBase 上回放财务全量 SQL 并验证通过。
3)为了降低财务结算系统改造量,将 OceanBase 的表按不同的功能进行建设,将原有分库分表的设计逻辑应用到 OceanBase 分区表的分区键设计上,以便上层业务可透明的切换数据源。对于数据量比较稳定的维表数据,比如合同数据等,将其建设为单表,避免全局分布式事务,提高频繁查询的性能。
-
解题设计核心要点:
1)迁移数据,将数据从 XDB(类似 MySQL)到 OceanBase 的数据平滑迁移。
2)协议兼容,验证 OceanBase 的 SQL 协议兼容能力,达到业务可平滑迁移应用代码无须修改 。
四、迁移方案要点
数据迁移:通过使用 OMS 进行数据迁移,数据一致性的校验通过使用集团的 MAC 系统来核对,而实时的数据写入不一致问题通过监控方式报警处理。
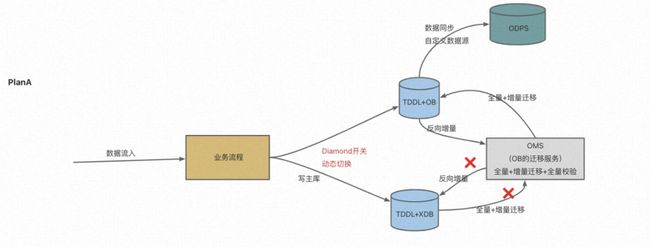
图 3.3 财务结算系统数据迁移设计
因财务结算非 C 端业务,核心关注是数据的强一致型和跨地域容灾型。并在平衡成本后,在 OceanBase 的同城三机房、两地三中心和三地五中心的部署方案中选择使用同城三机房的部署方案,既可以实现财务结算的数据一致性和跨地域容灾的目标,也能一定程度上节省成本,后续有需要也可以快速升级为三地五中心部署。
在完全切换 OceanBase 前,XDB 和 OceanBase 都有全量的业务数据,并可通过 MAC 每天进行全量数据核对,同时对于增量数据不一致情况及时报警处理。同时又因为 XDB 和 OceanBase 都保有全量数据,因此一旦切流遇到问题,可通过开关一键回切原 XDB 数据库。
五、部署架构
-
采用同地三机房部署
-
OceanBase 原生支持能力,多份数据同时写入,无同步延时问题
-

图 3.4 财务结算部署架构
六、业务收益
-
提升存储稳定性,高可用和容灾能力,跨地域级别的容灾能力。
-
强一致的存储保证,对于结算财务类的数据,保障较高的一致性,而非用最终一致性的妥协换取其他方面的能力。
-
提升扩展性,提升数据库弹性扩缩容的能力,存储横向扩展对上层系统透明,极大降低数据迁移的风险。
-
数据压缩,减少数据占用的存储容量,OceanBase 使用的 LSM-tree 结构存储最大可压缩数据至原大小的 35%,降低存储费用成本。
-
平衡升级:迁移 OceanBase 后仍然可使用 MySQL 原生驱动,使用 MySQL 5.7 版本的 SQL 进行业务功能开发,兼容原有存储(XDB)的协议,极大降低业务系统改造成本。
-
整理压测结果
目前压测数据写流量在 4K 左右,RT 稳定在 1ms 左右。
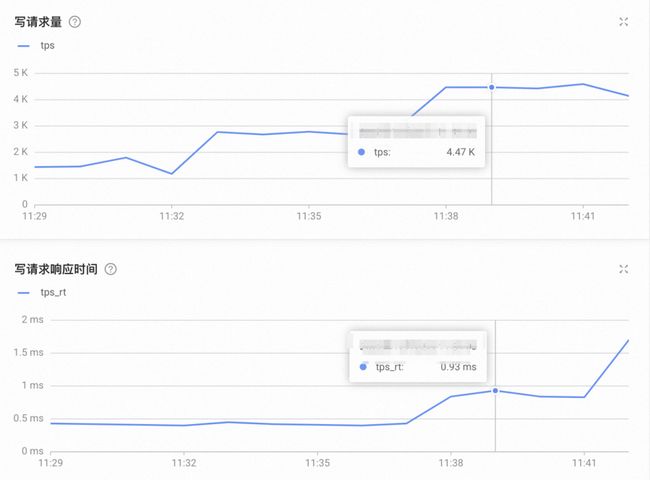
图 3.5 财务结算迁移OceanBase效果收益
3.2 海量数据多点写入场景落地实践
一、业务背景
高德地图云同步是高德地图的基础业务服务,主要负责数据的云端存储,多端设备数据同步。
图 3.6 多端设备数据同步云端设计
云同步的业务系统部署架构示意图如下:可以看出云同步业务用户多点就近接入,一次请求系统会多次读写数据库,因此可以看出系统需要,支持海量数据,多点写入,读写性能出色的数据库。
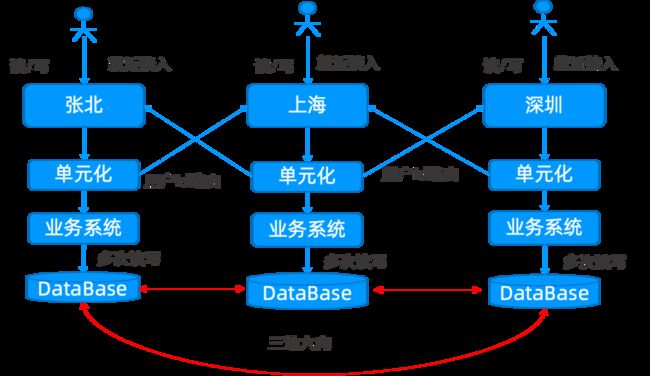
图 3.7 云同步单元化系统架构
二、业务痛点与技术解题
业务上需要保证数据多端准确写入,及时更新,更换设备后的数据快速读取;数据上随着高德业务的迅速发展云同步存储着大量数据,怎么做到保证稳定性为前提,追求极致性能,同时极大的降低业务成本,也是云同步系统需要技术解题的突破点,从云同步的业务分析得出整体数据库选型要求如下:
三、异地多活、海量数据存储、低成本
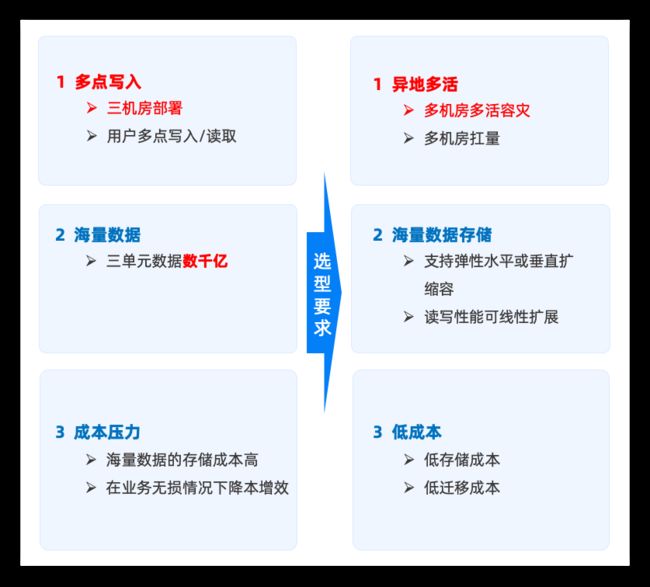
图 3.8 云同步选型详解
四、可行性分析
可以看出,针对我们的业务场景,OceanBase 完全符合了业务上数据库选型要求,从原理上分析(原理详见上节):
-
从成本上,针对云同步的结构化的海量数据,其"低成本存储的高级压缩技术",数据文本压缩+行列存储数据特性压缩,将成本压缩到极致,且数据量越大优势越大。
-
从原理上,LSM-Tree 的底层数据结构,内存处理增、删、改与批量顺序的磁盘写入极大提高了写入性能,足以支持了数万级 TPS 的数据写入,其 B+ 树的索引支撑了数十万 QPS 的业务读请求。
-
从架构上,其多单元同步链路,OMS 的秒级数据同步能力,保障了多机房数据同步低延迟支撑了多机房多活的可行性。
-
从业务上
-
分布式原生数据库从本质解决了业务研发需要考虑的分库分表问题。
-
业务特性为多端数据同步,可用 ID 作为分区键,所有操作在单分区内完成极大提升读写性能。
-
多语言 SDK,支撑各类业务系统,极大简化对接成本;同时支持 SQL 形式,更换配置无业务入侵。
-

图 3.9 云同步迁移 OceanBase 可行性分析
五、落地方案
从原理上分析了整体方案的可行性与业务收益,剩下就是业务数据源切换,主要分为 DAO 层改造、数据迁移、业务放量,达到目标用户无感,无损切换数据源。
-
DAO 层业务改造,使用 OceanBase Client 实现业务逻辑改造。
-
简单通用的 SDK,Java SDK 的流式编程,简单易用
-
业务无 SQL 语句配置
-
调用过程 SDK 封装业务无感
-
-
数据迁移:全量数据迁移,使用集团内部工具 DATAX 将 ID 分桶并发拉取,整体数千亿数据 2 天左右完成全量同步,采用 OceanBase 异地备份恢复能力,将数据同步到其他单元,天级完成。
-
数据比对:业务自研千亿级数据对比、更新、同步框架,实现千亿数据天级对比完成,通用框架,实现增量/全量对比/修复。
-
灰度迁移:数据双写,ID 维度白名单/灰度,支持比例控制,核心支持按 ID 随时回滚。
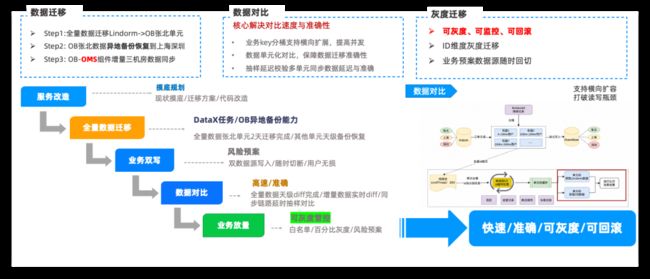
图 3.10 云同步迁移 OceanBase 落地方案
部署架构
-
多点写入
-
三地读写
-
无网络延迟
-
-
同城双主库容灾,异地多活容灾
-
同城数据库侧容灾切流
-
三地业务侧容灾切流
-
-
三地六向数据同步
-
三地六向秒级同步
-
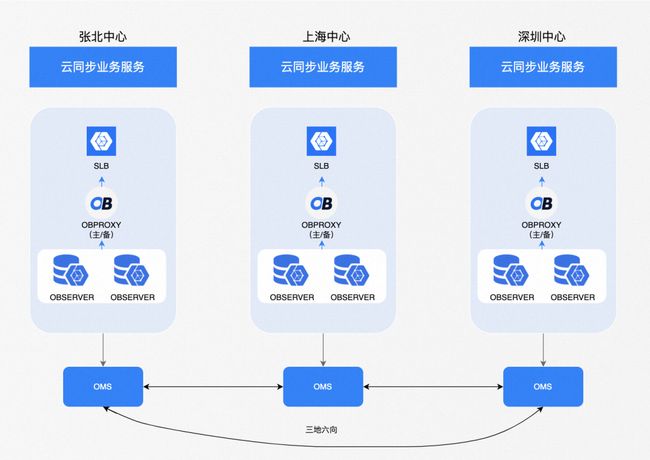
图 3.11 云同步迁移 OceanBase 部署架构
六、业务收益
整体降本明显,性能出色。
性能-压测数据:读单单元 8wqps,三单元 24wqps,写 2.8wtps,读 in 查询,写批量写入,平均 RT 均在 2~3ms。

图 3.12 云同步迁移OceanBase收益成果
3.3 中心读写单元读架构落地实践
一、业务背景
高德地图评价业务在辅助用户出行、交易等决策方面有着积极正向的引导,且评论覆盖与 POI 的 CTR、CVR 呈正相关;在本地生活大战略背景之下,高德评价业务的建设帮助高德地图从平台采集数据迈入到 UGC 时代。

图 3.13 评价业务效果展现
从评价业务的形态来看,内容生成有一定门槛,写入 TPS 不会太高,但是内容会在高德端内各个入口投放,对 RT 响应有很高的需求,作为一个读多写少的场景,需要有一个支持海量数据存储,可异地容灾,读写性能出色的数据库。
二、业务痛点与技术解题
-
评价系统作为整体评价的入口,对于性能有极致的要求,整体 RT 必须控制在 15ms 以内。
-
为了提升读性能,整体采用用户就近接入,三单元读数据,中心写入数据,对于读数据需要异地容灾能力。
-
需要支持后续数据量的持续增长。
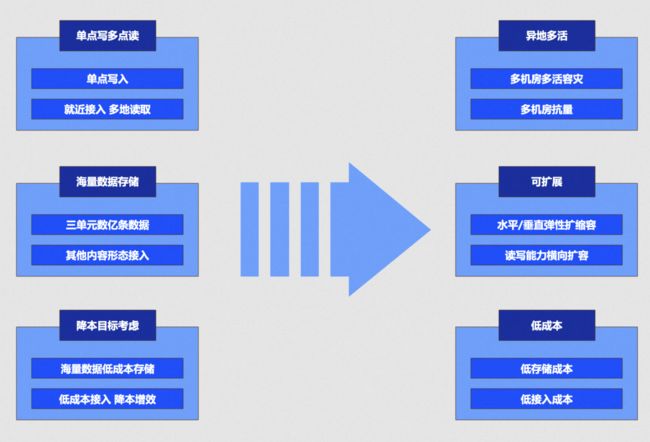
图 3.14 评价系统痛点分析
上述按照评价的业务场景,采用 OceanBase 主备集群的架构,支撑着整体高德评价系统的大量读写,三单的读性能得到极大提升,主备延迟在秒级,完全满足性能要求。
-
为什么选择中心写单元读?
评价的业务特点决定写入 TPS 不会太高,中心写能满足当前阶段的系统发展诉求,多点写在容灾能力上更优,但是会带来数据冲突等一系列问题,复杂度更高。综合系统和业务的发展阶段,我们选择了中心写单元读的方案。
-
为什么选择 OceanBase?
我们从成本,架构特点等多个方面横向对比了多个数据库,最终选择 OceanBase:
-
业务上,业务不断发展,数据量不断增长,需要解决数据存储的瓶颈,OceanBase 优异的横向扩容能力能很好的解决这个问题。
-
成本上,OceanBase 自研的基于行列混存结构/高效数字编码的存储压缩技术,将成本压缩到极致,能有效的降低评价数据的存储成本。
-
原理上,基于 LSM-Tree 的底层数据结构,极大提高了写入性能,足以满足评价场景的写入诉求。基于 B+ 树的索引,能满足评价场景大量读的查询诉求。
-
架构上,基于 OceanBase 主备库的架构,利用集群原生的复制能力,实现秒级同步,可靠性高。
三、部署架构图
-
中心写入
-
中心写单元读,架构更加简单,不用担心数据覆盖的问题
-
同城双主容灾,异地多活容灾
-
同城多机房容灾切流
-
三地读容灾切流
-
三地主备数据同步
-
利用集群间原生同步能力,秒级同步

图 3.15 评价系统部署架构
四、核心要点
-
张北中心主集群可读可写,实现强一致读。
-
上海和深圳为备集群,通过 OceanBase 原生的集群复制能力同步,秒级延迟,实现非强一致异构存储的高流量低耗时读业务。
五、数据一致性保障
-
实时:OceanBase 主备之间通过集群原生的同步能力,可靠性非常高,基本不需要担心。
-
离线:提供离线分析的兜底手段,通过 MAC 平台 T+1 分析监控数据一致性。
-
延迟监控:OceanBase 主备之间通过集群原生的主备同步延迟监控能力进行监控,集群级别的复制能力性能很高,正常的延迟都在秒级。
上述采用 OceanBase 主备集群的架构,支撑着整体高德评价系统的大量读写,三单的读性能得到极大提升,主备延迟在秒级,完全满足性能要求。
六、索引设计实践
面对大数据量的 C 端场景,基本都需要建立分区表对数据分片实现存储的横向扩容,下面我们就讨论分区场景下的索引设计。评价场景下最核心的模型就是评价基础信息,其他如评价标签、评价元素、评价评分等都可以通过评价 ID 关联出来,因此我们主要讨论如何设计索引实现评价主表(appraise_base)高效查询。
(1)分区键设计
最开始我们使用评价(appraise_id)作为分区键
partition by key(appraise_id) partitions 512
这么设计的考虑是:通过评价 ID 进行分区,数据分散比较均匀,同时通过评价 ID 也是高频查询,这种方案是个比较常规且通用的设计,表面上看起来并没有什么问题。但是按照线上流量实际压测时发现一直达不到预期效果。我们开始静下心来和 OceanBase 同学一起分析原因:
分析业务流量发现,大多数查询都是评价者(appraiser_id)维度进行查询(业务场景是查询用户在 POI 下是否首评、POI 详情页展示用户最新一条评价),这部分查询都是都是走了全局索引,而全局索引场景下索引和数据不一定在同一个节点上,大多数请求都需要经过一次跨机分布式事务,消耗了较多数据库资源。
对线上查询流量分析:
-
用户维度单个、批量查询(占比 75%)
-
通过评价 ID 查询(占比 15%)
-
评价对象维度查询/按时间分页查询(占比 10%)
到这里问题原因就比较清晰了,因为分区设计的缺陷导致大量的查询走到一个低效的索引上,整体性能上不去,这里引出了分区设计一个很重要的原则——在 main SQL 维度建立分区键!分区索引的性能是最好的。
因此改为评价者(appraiser_id)维度建立分区键
partition by key(appraiser_id) partitions 512
(2)索引设计
分区键确定后其他维度的查询一般都设置为全局索引,分区键维度的多条件查询设置为本地索引,具体为
PRIMARY KEY (`appraise_id`, `appraiser_id`),KEY `idx_appraiser_id_gmt_create` (`appraiser_id`, `gmt_create`) BLOCK_SIZE 16384 GLOBAL,KEY `idx_targetid_gmt_create` (`appraise_target_id`, `gmt_create`) BLOCK_SIZE 16384 GLOBAL,KEY `idex_modified_status` (`gmt_modified`, `status`) BLOCK_SIZE 16384 GLOBALpartition by key(appraiser_id)
-
评价者 ID 维度(appraiser_id)设置分区键
-
评价 ID(appraise_id)设置为主键查询
-
评价对象维度(appraise_target_id)设置全局索引查询
这里有没有发现 idx_appraiser_id_gmt_create 的索引设置有点不太合理,索引被设置为全局索引了,这里可以设置为性能更好的本地索引,原因为:appraiser_id 已经是分区键,通过 appraiser_id 路由到的分片上有全量的的数据,通过本地索引完全能定位到数据,不需要走全局索引查询,这个索引最终改为本地索引:
KEY `idx_appraiser_id_gmt_create` (`appraiser_id`, `gmt_create`) BLOCK_SIZE 16384 LOCAL,
(3)分区表下的数据更新
业务上评价数据都是通过评价 ID(appraise_id)进行更新,在实际压测中发现 CPU 会飙升到 70% 左右,排查发现通过appraise_id更新时不带分区键,定位分区有额外的成本,因此在更新条件中加入了分区键,这样在相同的压力下 CPU 降至 20% 以下。
评价系统-索引设计总结如下图:在分区表场景下,有一个好的索引设计非常重要。

图 3.16 评价系统索引设计实践总结
七、业务收益
-
新的数据库架构完全支撑整体评论体系的读写性能
-
分布式数据库,不用担心后续的海量数据增长导致重新分库分表
-
整体压测结果如下:读/写 2w,平均响应稳定在 1~2ms

图 3.17 评价系统迁移OceanBase收益成果

4.1 关于为什么选择 OceanBase
在第二节,第三节分别讲述了,OceanBase 的技术内幕,和高德在 OceanBase 的落地场景,但是详细考虑为什么选择 OceanBase,就是关于数据库的选型是怎么思考的?我想说“一切基于业务场景,不同业务适合考虑不同数据库”,如果业务只有一个很小的场景,几十万条数据,几百 QPS 的查询,且数据基本不增长,那单实例的 MySQL 就足够满足要求,以云同步业务(3.2 节)看,云同步业务特性:单元化、海量数据存储、海量请求,而云同步经历 Mongo->Lindorm->OceanBase,为什么进行迁移,同时为什么不使用 MySQL,我们对比如下:
PS:关于为什么我们业务上既考虑关系型数据库,又考虑NoSQL数据库,我们业务上本质是结构化数据,适合关系型数据库,但是整体业务查询简单,对于NoSQL或者KV同样可以支撑我们的业务。

表 4.1 数据库选型属性信息
我们最关注的三点:稳定性、业务支撑、成本,三个角度综合考量,OceanBase 是我们看到的最优解,确定了数据库,我们就要选择 OceanBase 的部署架构。
4.2 OceanBase部署架构选择
从上面的项目实践可以看出,我们对于异地多活的部署使用了两种架构:多点写入和中心写入多单元读,针对OceanBase也同样的是两种不同的架构:
一、架构选择-多点写入
对于多点写入的部署架构,三个单元的数据库相互独立,通过 OceanBase 提供的数据同步工具 OMS 进行三地六向的相互同步,此种部署架构优势如下:
-
用户就近接入,读写对应单元,无数据延迟
-
实现完美的异地多活,各单元异地容灾,机房故障,随时切流,用户无损

图 4.1 OceanBase单元化部署架构
二、架构选择-中心写单元读
对于中心写单元读系统架构,主要采用 OceanBase 的主从架构,整体优势如下:
-
整体对于读支撑能力提供三倍,同时节省了网络耗时
-
主从架构为集群内部机制,自动同步,运维更简单
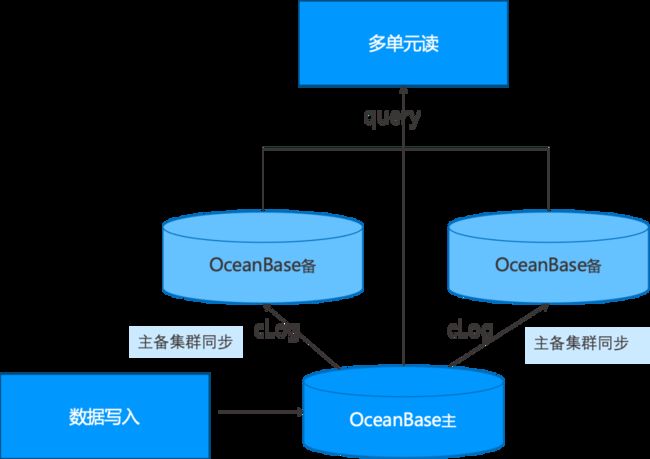
图 4.2 OceanBase的中心写单元读架构
三、架构选择-同城多机房读写
-
用户请求到业务系统无法避免的物理延迟(30~50ms)
-
同城多机房灾备,无法媲美异地灾备能力
-
架构简单运维方便
四、关于多单元数据同步
其实中心写,单元读也可以采用 OMS,但是没必要:

表 4.2 多单元数据同步对比
五、架构选择结论
不用结构有不同的优劣,具体采用哪种架构要看业务需求,如果业务对读延迟没有强要求,可采用主备模式,否则选择多单元 OMS 同步模式,而针对本身就是单元化的云同步业务,多点写入是我们最好的选择。
六、多点写入系统的问题与解决方案
关于多点写入的系统(3.2 节云同步系统举例),整体会有很多疑问点,例如:
-
云同步系统是否业务一定要单元化?不单元化会有什么问题?
-
从成本考虑,已经单元化,三个单元是否可以不存全量数据?
-
单元化系统容灾切流是否会有问题?
1.云同步系统为什么要实现单元化
业务背景分析:
(1)从业务要求上,一次请求,云同步系统需要与数据库多次交互,数据库必须是张北、上海、深圳,三中心来降低网络延迟。
(2)从用户访问上,通过APP访问,目前的方式是就近接入,但是用户的连续两次请求很可能跨中心。
(3)三单元数据库同步是一定存在延迟的,只能缩小延迟,但是不可避免(例如网络物理延迟)。
异常情况举例(出现数据缺失与覆盖详见 4.2.7.2):
用户连续两次请求更改同一条数据,但是请求跨中心(第一次张北中心,第二次上海中心),会产生什么情况?
(1)用户第一次请求张北更新成功。
(2)用户第二次请求上海更新成功。
(3)如果两次的请求的间隔小于同步延迟,那么数据同步过来后,上海中心的数据最新数据,会被张北中心的数据覆盖,张北中心的数据最新数据,会被上海中心的数据覆盖;会产生数据的不一致性。
单元化解决的问题:
(1) 将用户请求封闭在同一中心单元,解决可能产生的数据不一致性问题。
(2)用户最多产生一次网络延迟,入口层识别用户单元分发时,可能产生转发到其他单元,业务与数据库多次交互均无额外网络延迟。
2. 单元化系统每个单元是否要存全量数据
(1)从成本角度看,单元化系统只存储对应单元数据,不需要数据同步,同时存储成本很低(优点)。
(2)但是三个单元存储非全量数据,业务将无法进行容灾切流,只能依靠数据库同城容灾,做不到异地多活容灾(缺点)。
结论:要看系统对于容灾的稳定性要求,如果要做到异地多活,随时切流容灾,则需要每个单元存储全量数据。
3. 单元化系统容灾切流是否会有问题
单元化系统解决了日常情况的数据一致性问题,但是如果系统发生容灾切流,依然会产生数据一致性问题,需要进一步解决。

图 4.3 单元化部署同步延时
七、切流态的数据缺失和覆盖解决方案
1. 什么情况下会有数据缺失
对于数据缺失很好理解,用户从一个单元切换到另外一个单元,如果用户前一个单元的数据刚写入,但是由于同步链路延迟,用户已经切换到其他单元,但是之前写入的数据还没同步过来,这样,就产生了数据缺失。
2.什么情况下会有数据覆盖
这是个极端情况,不过也有可能发生,如下图,如果用户先执行 1,后执行2,在执行 1 和 2 之间发生了用户单元切换,如果数据延迟大于用户操作会发生什么?会造成数据永久性差异,同时张北 OB 存在数据错误。
-
对于张北 OB 如果数据延迟:则 2 先进行,1 通过同步链路进行,最终数据,id = 1 name = 'a'。
-
对于深圳 OB:则 1 先进行,2 后进行,最终数据,id = 1 name = 'b'。
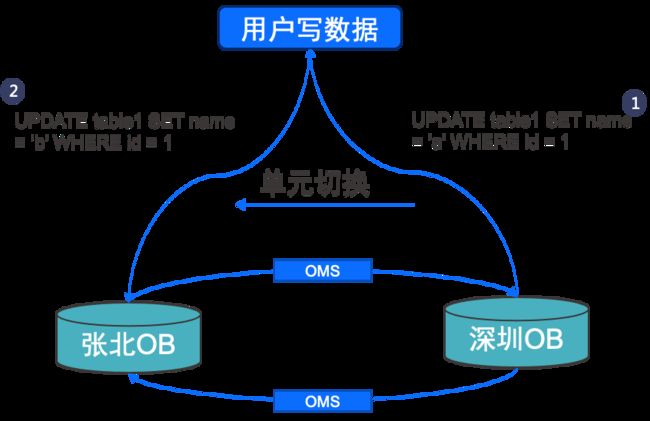
图 4.4 数据覆盖问题详解
3. 解决方案是什么
-
业务侧保证禁写时间,同时要求 OMS 不能有长延迟。
-
OMS 数据同步时保证数据不被覆盖(目前 OMS 支持启停后重新追数据,会比较时间戳),所以我们在切流预案中集成了 OMS 的启停。
-
OMS 延迟越低,风险越小。

图 4.5 避免数据覆盖设计
4. OMS同步怎么降低延迟
OMS 同步链路的拆分与相互独立。同步链路可以从数据库维度拆分到表维度,相互链路独立,无影响,同时提升同步性能。

图 4.6 OMS 如何降低延时
5. OMS 降低延迟效果
在我们降所有表独立成三条链路后,测试数据结果,峰值写入百兆/秒,同步延迟在 10s~20s 之间。
图 4.7 OMS 降低延时效果 (注:因数据敏感,部分数据脱敏)
4.3 选择分区表,还是单表?
一、业务设计选择-分区表 or 单表
-
业务增长迅猛一定选择分区表。
-
注意目前 OceanBase 的分区数量最大 8192,且分区数在创建时即固定,不可自动分列。

图 4.8 OceanBase 表设计选型详解
二、业务设计选择-全局索引 or 局部索引
-
局部索引:索引和数据相同的分区规则,在同一机器上,可避免部分分布式事务。
-
全局索引:不管是全局分区索引还是全局不分区索引,其都可能导致索引和数据不在同一机器上,每次写入都是跨机分布式事务。换句话说全局索引会影响表数据写入性能。
1.使用全局索引的场景
-
有除主键外的全局唯一性的强需求,需要全局性的唯一索引。
-
查询条件没有分区谓词,无高并发写入。避免全局扫描,可构建全局索引,但一般限制在4条全局索引内。
2. 全局索引、局部索引性能对比
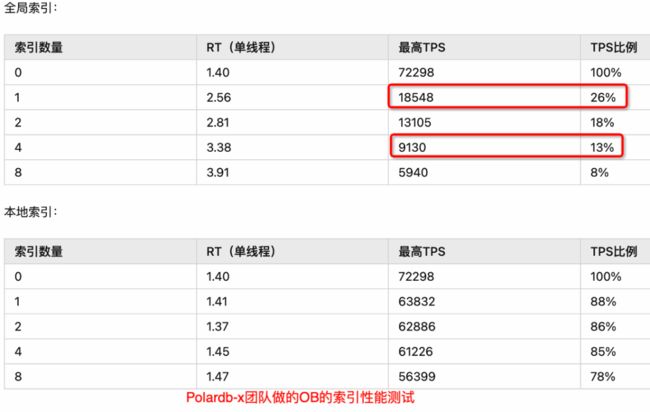
图 4.9 OceanBase索引间性能对比[2]
引用自:https://www.zhihu.com/question/400141995/answer/2652474150
3. 局部索引读写注意事项
针对局部索引的读写,一定要在请求时指定分区键,这样在 OceanBase 实际处理时才会直接确定对应分区,整体性能会有明显差距,以高德评价系统为例,Update 场景下命中分区键 CPU 使用率从 75% 降低到 20% 以下。
4. 全局索引使用的注意事项
1)使用全局索引需要避免扫描行数过大,扫描行数过大会带来大量 RPC 调用,导致 RT 过高,建议对大查询做分批查询。
2)不建议使用全局索引做更新操作,基于全局索引更新性能比较查,QPS 高时系统负载比较高。
三、业务设计选择-OBKV or OceanBase普通版本
一句话解释 OBKV 版本和 OceanBase 普通版本,OBKV 版本没有 SQL 解析优化器,很多 SQL 需要业务手动优化 SQL,指定索引等,但 KV 版本比普通版本要便宜。

表 4.3 OceanBase版本之间的成本对比
PS:目前 OBKV 版提供了 SDK,支持 Java/Go/Rust 语言。
四、业务设计选择-什么时候使用复制表?
复制表概念:OceanBase 有一种表类型叫做复制表,这种表数据不像分区表一样做分片存储,也不像单表一样只存储于单个 OBServer 上,而是会将全部数据完整的存储在所有 OBServer 上。
主要优势:复制表数据存在于所有 OBServer, 数据库在制定查询计划时会做针对性优化,尽量保证从本地机器获取数据,避免远程调用。
使用场景:如果某张表数据很少,且业务上这张表需要与其它分区表做大量 JOIN 查询,可以将这张表设置复制表,提升 JOIN 性能。有个常见的例子,我们系统中通用会有一些基础数据表,比如城市表、类目表等,这类表如果需要与其他表做 JOIN 查询,可以考虑设置成复制表,这样可以避免跨分区 JOIN。
五、 业务设计选择-Leader 副本是否要分散到各个 OBServer上?
OceanBase 一个 Zone 通常有 3 个 OBServer 节点,默认情况下系统中所有分区表 Lead 副本只分布在一台。OBServer 上,这台 OBServer 抗住这个Zone所有读写请求。我们可以考虑将 Leader 副本分布到所有 OBServer 上,这样可以提升整个系统的资源使用率。但是这样也会带来其他问题,如果我们系统中存在大量跨分区的读写操作,会增加很多远程调用,导致读写 RT 升高。
大多数情况下,我们使用系统默认配置就行,只有当遇到数据库性能问题时才考虑打散 Leader 副本,并进行压力测试验证效果。使用场景总结如下:
分散 Leader 副本:系统中大部分查询都可以使用局部索引完成,只有少量查询使用全局索引,且系统中写操作使用分布式事务场景也不多。
不分散 Leader 副本:系统中有一定比例的全局索引或写分布式事务,这种情况下打散后会导致这部分读写操作 RT 升高。
六、业务设计选择-主键和分区键设置
主键:OceanBase 作为传统关系型数据库替代品,经常使用在 OLTP 场景,作为业务系统主数据库使用,这种场景下推荐使用自增主键,便于后期维护、数据异构等。OceanBase 虽然自带自增主键,但是只能保证在一个分区内具有单调性,不推荐使用。建议使用外置分布式 ID 方案,比如“数据库号段模式” 或者 “雪花算法”等。
分区键:
1)OceanBase 分区方式设置很灵活,支持多级分区、Hash 和 Range 函数分区,通常情况下我们使用最多是基于某一个字段 Hash 分区。
2)分区键选择上需要综合考虑查询方式和数据热点问题,通常情况下我们可以使用查询最多的一个维度作为分区键,保证大部分查询可以有最佳的性能。
3)如果系统中有一组表,彼此关系比较密切,经常一起 JOIN 使用,这组表可以使用相同的分区方式,且设置相同的分区数量,数据库可以保证这组表同一个分片下的数据分布在同一个 OBSever 上。比如订单表和订单明细表可以都使用用户 ID 为分区键。
4)分片数量要适宜,分片太大对查询性能有影响,这个要注意按自己场景设定并测试验证。
4.4 业务落地的瓶颈
针对云同步这样海量的读写,同时针对节假日出行高峰,我们的流量即可能翻倍,经过压测,我们发现了部分瓶颈。
一、瓶颈-流量稍高,Client 明显报错超时
-
Java Client 代码问题,在发起请求处理链接,不合理使用 Synchronized。
-
升级最新包即可解决。

图 4.10 瓶颈Client延时问题
二、瓶颈-读写流量增加,业务超时明显
-
随着压测的增加,平均 RT 明显上涨,且失败超时明显增加。
-
原因:Proxy 侧性能瓶颈。

图 4.11 读写流量增加业务超时明显(注:因数据敏感,部分数据脱敏)
三、瓶颈-业务机器扩容失败,无法链接数据库
-
扩容失败提示无法连接数据库。
-
业务系统不断重试依然无法连接。
原因是:单 Proxy 链接数有上限。
四、瓶颈解决-海量数据云上部署架构优化
OB Cloud(原 OceanBase 公有云),正常部署架构为 Client -> SLB -> Proxy -> OBServer,如下图 4.4.3 左图,但是针对海量数据请求可能存在瓶颈,单 Proxy 的链接数,读写性能不足以支撑业务请求时,可以进行架构优化,进行水平拆分;多单元 OBServer 之间可以采用 OMS 进行数据同步,针对高 TPS 的写入,同时写入数据量很大的情况下,OMS 同样可以进行拆分,正常情况下,一条同步链路支撑两点数据库之间的全量同步,优化架构可以拆分成表维度互相同步(详见:4.2.7.4节)。
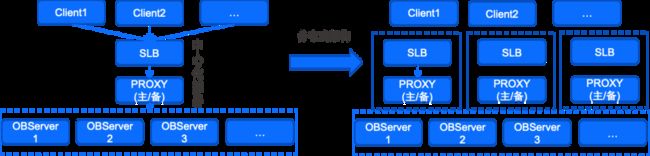
图 4.12 针对海量请求的OceanBase水平拆分
五、业务落地-优化效果
在刚刚过去的出行高峰,云同步业务峰值 OceanBase 整体 RT 平稳在 2~3ms
图 4.13 海量数据延时优化效果 (注:因数据敏感,部分数据脱敏)
4.5 当然我们也趟过一些坑
一、OBKV 版不支持 SQL 优化器,使用索引需要程序指定
OBKV 版本:为了达到最大的性能优化,针对我们没有复杂查询的业务,我们采用 OBKV 版本,此版本不支持,SQL 优化索引自动选择的能力,需要程序指定,示例如下:
我们创建了"item_uid", "item_id"的联合索引,在 OBKV 如果业务需要走索引,要制定 indexName,如代码行 6。
TableQuery query = obTableClient.query(table).setScanRangeColumns("item_uid", "item_id"); for (String itemId : itemIdSet) { query.addScanRange(new Object[]{uidStr, itemId}, new Object[]{uidStr, itemId}); } QueryRESultSet rESults = query .indexName(INDEX_UID_ITEM_ID) .execute();
同时正如上面提到请求需要指定分区键,我们在使用时,一定注意指定分区键,我们这里分区键是 uid。
public TableQuery queryWithFilter(int uid, String table, ObTableFilterList filterList) { return obTableClient .query(table) .setScanRangeColumns("uid") .addScanRange(uid, uid) .setFilter(filterList); }
二、OMS clog丢失、OMS 同步明显延迟触发报警
在第四节开头的多点写入部分介绍了三地六向数据同步的架构,OMS 会有 Store节点,而Store节点的数据是在 内存存储 的,在我们压测时发现,当写入数据量过大时,会导致内存覆盖,导致同步日志 Clog 丢失,针对此种解决方案为:内存+日志落盘,保证日志持久化,那如果磁盘满了怎么办?目前磁盘余量会比较大,同时加设磁盘的相关报警,值班人员随时关注。

图 4.14 OMS 数据链路
三、主从架构高德评论库上海备集群缩容后无法提供服务
业务解决在发现问题时第一时间做了业务切流,整体业务无影响,这也同样体现出异地多活的重要性,可以迅速容灾。
-
直接原因:集群缩容,把 SLB 切换到了不支持备集群的 OBProxy 版本上,导致服务不可用。
-
根本原因:公有云上 OceanBase 集群的 OBProxy 默认是和 OBServer 同机部署,3 月初为了配合支持主备库和 POC 测试,将 OBProxy 部署模式切到了独立支持主备库的实例和版本部署,但是元信息记录没有修改(仍然为混部模式)。导致本次缩容过程中,识别到混部模式后,认为需要修改 SLB 挂载的 OBProxy 信息,从而挂载到了现在的不支持主备库的版本,业务访问异常。
问题解决方案
-
OBProxy 运维操作自动化优化:避免操作疏漏引入的后续问题,支持创建各版本 OBProxy 集群、SLB 绑定 OBProxy 等。
-
释放节点操作新增静默期:有问题可以马上回滚。
四、OBServer 部分节点 CPU 被打满
问题现象:某一天中午突然收到告警,CPU 被打满,整体现象如下图 4.5.2 和 4.5.3:
图 4.15 OceanBase异常节点CPU (注:因数据敏感,部分数据脱敏)
图 4.16 OceanBase正常节点CPU(注:因数据敏感,部分数据脱敏)
问题分析:通过阿里云 SQL 分析发现,数据库存在部分慢查询以及大量 KILL QUERY 请求记录
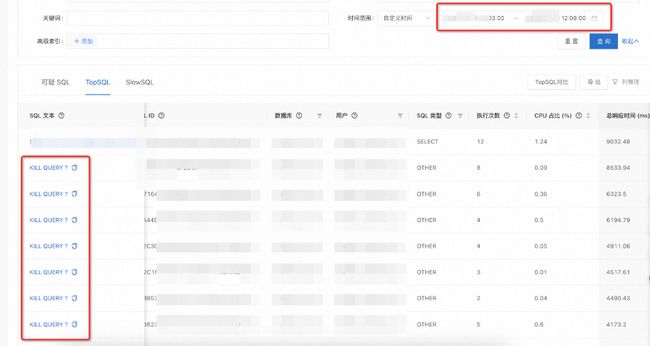
图 4.17 云SQL分析CPU问题效果(注:因数据敏感,部分数据脱敏)
问题原因:
出问题 SQL 的业务场景:通过工单 ID 查询工单的回调记录,倒序取 100 条
select gmt_create,id from table a where a.feedback_id=xxxx order by gmt_create asc,id DESC limit 100;
PRIMARY KEY (`feedback_id`, `id`),KEY `idx_gmt_create_id` (`gmt_create`, `id`) BLOCK_SIZE 16384 LOCALpartition by hash(feedback_id)
这个 SQL 存在两种执行计划:
计划 A:使用主键索引,走 feedback_id 维度的主键索引查询(feedback_id为分区键)。
计划 B:使用本地索引 idx_gmt_create_id,走 feedback_id 维度的本地索引查询。
正常情况下工单的回调记录就几十条(小 ID),执行计划选择的是A,但是那天刚好有个工单有某种异常导致下游一直发送回调消息,回调记录达到5w条(大 ID),这时候 OceanBase 引擎认为计划B性能更佳,根据 OceanBase 执行计划的淘汰机制,一段时间的执行计划切换为计划B。这时候小 ID 的查询也切换到计划B上,小 ID SQL 走了 idx_gmt_create_id local 索引导致性变差超时,引起应用大量发起 KILL QUERY,最终导致 CPU 打满。
小 ID 走本地索引性能变差的原因:
与 OceanBase 确认是排序引起的性能问题,具体为正向排序当前 3.2.3.3 版本做了性能优化,目前版本逆序排序还未做优化,从而出现 Desc 排序耗时超 5 秒的情况。大 ID 执行时扫描的记录数达到 Limit 时会提前结束扫描全部子分区,而小 ID 查询时总记录数不足 Limit,在未做优化的时候需要扫描全分区,导致性能问题出现。
解决方案:
-
为解决大小 ID 查询性能不一致的问题,需要重构 idx_gmt_create_id 索引,增加 feedback_id 筛选列,避免全分区扫描。具体索引为 KEY `idx_feedback_id_gmt_create_id` (`feedback_id`, `gmt_create`, `id`) BLOCK_SIZE 16384 LOCAL。
-
OceanBase 侧做逆序排序优化,新版本已修复。

高德本着“促科技创新,与生态共进”初心,通过技术创新的手段连接真实世界,做好一张活地图,让出行变得更加美好。在过程中我们会通过技术的手段去高效的迭代产品提升用户体验,也会通过技术的手段去降低成本,涵盖人力成本和资源成本。
其实互联网发展到现在这个阶段,2 个关键词“降本”和“提效”也非常重要。我们已经从“单体架构”过渡到“分布式架构”到现在的“微服务架构”进入到未来的“云原生架构”,数据也从当初 xG 衍生到现在的 xPB 级别。伴随着 ChatGPT 出现,算法也达到了一个高光的时代,“算法+大数据”的方式,可以让模拟人类大脑的方式去思考,去帮助人类提效,这类新的技术也让机器完成了涅槃,拥有了生命,我们称之为“硅基生命”。
这么一看科技是可以促进创新、促进社会进步的,拥抱新的技术对我们来说显得尤为重要。因为要在这个生态环境下提供更好的服务是我们的初心,我们不但要拥抱新技术,还要反馈社会,促进科技创新,促进生态发展。那么回过头说说我们在云原生上是如何做“降本”和“提效”的。
未来,我们将在后续的规划里继续跟 OceanBase 合作,在降本和性能(涵盖 AP 场景)做更大的突破。高德在 Serverless 上已经取得了 100w/QPS+ 成绩,我们也会继续发挥这个优势,利用云原生+行业无关化架构提升开发效率,比如利用 Serverless,能大幅降低研发成本、提升人效并加快迭代速度,让业务更快,一起做好极致的用户体验。
[这里做一个云原生的概念回顾,因为可能读者会产生一个疑问,OceanBase 不是分布式数据库吗,什么时候变成云原生数据库了。]
云原生(Cloud Native)其实是一套架构体系,说到体系其实就会衍生出方法论。Cloud 的含义是应用和数据都不在机房或者 IDC 中,而在 N 多机器组合的云中.Native 设计之初就是以云架构为基础,提供资源池化、弹性和分布式服务等核心能力。
非原生到云原生的转化路径为:
1、DevOps 迭代与运维自动化,弹性伸缩、动态调度
2、微服务,Service Mesh、声明式 API
3、容器化
4、持续交付
OceanBase 提供了租户的概念,资源池+弹性+调度都是相互隔离的,数据非常安全。本身 OceanBase 的组件也都是服务化的基础服务,也可以跑到容器里。做到 Native 架构所要求的特性,而且 OceanBase 的资源都在云上。从这些来看 OceanBase 也可以说是一个云原生数据库了。
5.1 高德与 OceanBase 合作后续展望
上文也简单的介绍了 OceanBase 的技术内幕,我们直接说结论。DevOps 和持续交付这里不提,因为现在每款数据存储工具都会做,而且都会提供极致的用户体验,让运维变得更加简单。这里我们想说的是 OceanBase 的数据压缩技术, OceanBase 对数据压缩和路由上做了很多优化与创新,单说数据压缩,针对不同的列类型提供不同的压缩技术,尽量使得存储量变得小而不失查询效率。
这里是否会产生一个疑问?高德为什么这么在乎数据压缩和存储空间大小。其实可以先思考下这个问题,大家在使用高德地图的时候,体感只是当前使用的功能。为了更好的用户体验,我们做了很多数据和算法上的事来提升用户体验,这也导致高德数据体量非常大,所需要的成本会很高,可能都是指数的级别,从公司的角度来看,优化这块对我们来说收益很大,不但可以节省成本,还可以降低耗电量,保护环境。从另外一个角度来说做极致的优化也是我们的追求。
总结下,未来高德跟 OceanBase 合作的事项,以及详细规划。事项如下:
-
因高德数据体量很大,后续会持续落地OceanBase( 常规结构化和非结构化版本)
-
探索 OceanBase 的 AP 能力,替换 ADB 方案
-
探索 Serverless 版本

图 5.1 高德与 OceanBase 后续合作展望
一、海量数据项目 - 结构化数据
高德有许多结构化的数据存储在 Lindorm 中,Lindorm 本质是列存+多副本冗余架构本质上跟 OceanBase 一样高可用架构。列存的数据库对于大数据计算其实是很友好的,如果一个 Sum 的计算其实只要读一次列值然后计算就可以(这里是一个列,不涉及 IO 的计算) 。虽然结构化数据也支持,但是毕竟场景不是很合适因为我们有复杂的查询在里面,这里就比较适合迁移到 OceanBase 上,从另外一个角度来说 OceanBase 的多列类型压缩在成本上也有很大优势。
后续我们会持续把结构化数据场景的业务迁移到 OceanBase 上,比如高德足迹(结构化存储),目标降本 50% 以上。
当然迁移后,我们也可以享受 OceanBase 线性优化的收益,可以压缩数据的节点数量达到最小,当大促或者量大的时候自动进行弹性扩容,而且因 OceanBase 具备分布式的能力,我们也无需关注负载均衡的问题,完全实现了自动化透明扩容。

图 5.2 OceanBase 弹性扩容设计
二、海量数据项目 - 非结构化数据
在高德的复杂场景里,我们处理结构化数据,还有许多非结构化存储场景,这里这的不是简单的 KV 模式,一个 Key 对应一个 Val。我们其实用的更加复杂,因为我们的非结构化的场景需要动态列 -Schemaless 能力,也会和固定表结构混用,这样就显得十分复杂。如果再加上一个多版本的数据保留,那么在查询上就会更加复杂。你们以为这就完了吗?我们还会加上一个列级的 TTL。这种复杂的组合真的很考验数据库的能力和性能。OceanBase 在收到我们的需求后,响应也是非常的及时,快速的开发出 NoSQL+多版数据版本来支持我们,目前已经满足了我们大部分场景。列级的 TTL 也已经开发的差不多了,近月就会提供出一个稳定版本让我们使用。
目前在非结构化数据场景,高德也一直和 OceanBase 在一起探索,目标把打车的特征平台(典型的KV场景)迁移到 OceanBase 上,预计降本目标 50%以上。
如果只是单独提出“多版本、动态列、列级TTL”组合能力,看着只是稍微复杂点,其实还好。 如果说我们每个应用的数据量级都是过百 T 的存储量,几百张表,读峰值在百万级/S,写峰值在十万级/S。 这么看是不是会体感更好点。所以针对这块降本还是很可观的具体降本在 30%-40%。
三、 探索 OceanBase 的 AP 能力,替换 ADB方案
OceanBase 目前的引擎能力已经支持了 AP 场景,但是因为 OceanBase 的目前的表现还是行,极少能吃到列存在 AP 上的表现。下半年 OceanBase 推出纯列存储引擎,在路由和数据模式上(冷热数据)也做了很多优化,性能会提升至少 3 倍数。我们也会在下半年把现有AP 场景切一个试点到OceanBase 上,目前预计降本 20%。
这里不是对 OceanBase 的 OLAP 场景的性能要求苛刻,我们还是本着降本提效的思路,要压榨出 OceanBase 极致的性能,因为我们在大数据分析场景,对数据分析的实时性要求很高,只要在快速的效果下才能提供极致的用户体验。而且同一个租户集群里,我们可以同时享受到 OLTP+OLAP 双引擎的优势和收益,降本收益还是很客观的。

图 5.3 OB的OLAP方案
当然我们也会把 OceanBase 引入到交易的场景里,在交易的复杂场景里, OceanBase 也会表现的非常好。

图 5.4 OceanBase 交易场景探索
四、Serverless 版本的探索
高德本身已经在 Serverless 上取得了很多成绩,百万级 QPS。我们有很多 Serverless 落地经验,也会跟 OceanBase 一起尝试落地 Serverless 版本的 OceanBase ,再次降本。
-
资源按需使用,规格动态升级
-
资源按需使用,底层存储空间扩容
因 OceanBase 是多副本模式+转存模式+多数派模式,扩容时可用。

图 5.5 OceanBase 在Serverless上的探索
5.2 极简架构建构云原生 Serverless 和组装式研发生态
说到组装式研发,这并不是一个新词,这种架构模式其实很早就存在了,只是每个公司实现的方式不同。高德针对组装式研发进行了调整,因为对我们来说数据流转就是 2 大属性,“Request和Response”。但是从业务组合的视角,我们其实只有“Input和Output”。从架构的视角就更加简单明了,也更加灵活了。
我们其实只要针对"输入和输出"进行加工,然后通过流水线的方式把流程编排起来,整个业务流程和数据流转就会非常清晰,我们也会根据公共特性进行封装变成通用组件进行复用,大大提供人效成本和降低后续维护成本。不再担心面对业务孵化和不敢改的局面,真正做到从人到机器再加上业务迭代上的一石三鸟的收益。(因辅助的工具比较多,这里不深入叙述,后续可以单独写一个专题)
组装式不单单可以用到应用上,还可以用到 Serverless 的 FaaS 里,其实我们现在好多服务已经进化成 Serverless 的 BaaS 模式。整个组装式已经深入到 Serverless 生态里面。我们也会继续建设Serverless生态,应对初心,促进科技发展,开源高德 Serverless FaaS 的 Runtime 脚手架到社区,让大家可以快速复刻高德的 Serverless 落地方案。我们已经在“交易、出行、广告、车生态”等多个场景里落地了,感兴趣的同学可以去搜索“高德云原生之 Serverless 体系建设&实践”。
整体抽象如下 3 点:
-
组装式研发,乐高组件,动态编排,快速迭代提升人效,降低维护成本,快速迭代业务。
-
Serverless 生态建设,更加丰富的脚手架和工具落地,快速降本。
-
存储层面支持 Serverless,一个函数通杀所有,端云一体,语言无关,降低研发门槛。

图 5.6 Serverless 端云引擎一体化探索设计
*本文参考:
[1] 阿里云. PolarDB-X技术架构[EB/OL]. 2023-07-18[2023-07]. https://help.aliyun.com/document_detail/316639.html
[2] PolarDB-X. PolarDB-X、OceanBase、CockroachDB、TiDB二级索引写入性能测评[EB/OL]. 2022[2023-07]. https://www.zhihu.com/org/polardb-x.
[3] Wu L, Yuan L, You J. Survey of large-scale data management systems for big data applications[J]. Journal of computer science and technology, 2015, 30(1): 163-183.
[4] https://glossary.cncf.io/serverless/
[5] https://developer.salesforce.com/docs