prometheus使用 (五) 函数使用
常用的函数
为了方便查询,promQL内置了大量的函数,下面列举一些常用的
absent() #取布尔值
abs() #绝对值
sqrt() #平方根
ceil() #向上取整
floor() #向下取整
changes() #显示变更次数
round() #四舍五入取整
clamp_max() #当大于最大值时,则为最大值
clamp_min() #当小于最小值时,则为最小值
lable_join() #新增标签
lable_replace() #替换标签
predict_linear() #基于一段时间内的增长值来预测多久后会溢出
rate() #计算区间向量里的平均增长率
irate() #计算区间向量内最新和最后的瞬时向量的增长率
sort() #升序排序
sort_desc() #降序排序
delta() #计算区间向量里最大最小的差值
increase() #计算区间向量里最后一个值和第一个值的差值一. absent() 取布尔值
#先获取一个瞬时向量作为参数,然后判断这个瞬时向量是否有值
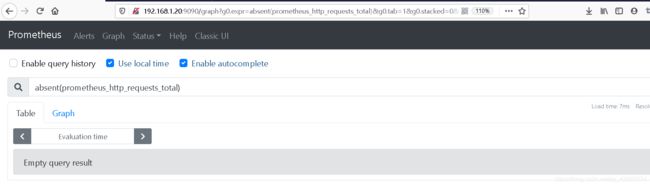
#如果该向量存在值,则返回空向量
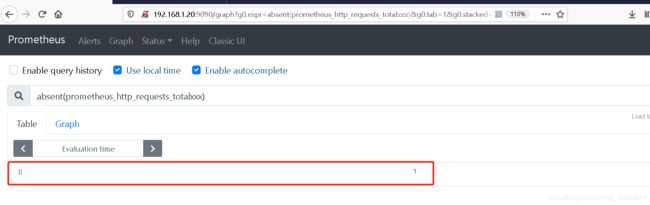
#如果该向量没有值,则返回不带标签名称的时间序列 并返回值为1
#存在值
absent(prometheus_http_requests_total)
#不存在值
absent(prometheus_http_requests_totalxxx)
#这对于在给定度量标准名称和标签组合不存在时间序列时发出警报非常有用。有效的
无效的
二. abs() 绝对值
返回绝对值,将负数变更为正数
#我们故意去整点负数
predict_linear(node_filesystem_free_bytes{mountpoint ="/",device!="rootfs"}[1h], 1111111111*3600) < 0
#返回值为负
{device="/dev/mapper/centos-root", fstype="xfs", instance="192.168.1.21:9100", job="node", mountpoint="/"} -177684705340231.84
#利用abs修改为绝对值
abs(predict_linear(node_filesystem_free_bytes{mountpoint ="/",device!="rootfs"}[1h], 1111111111*3600) < 0)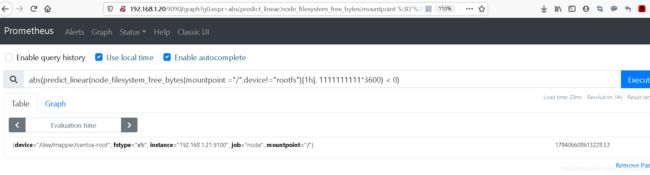
三. sqrt() 平方根
#取平方根
#如
http_request_total{handler="/", instance="192.168.1.20:3000", job="grafana", method="get", statuscode="200"}
#返回
http_request_total{handler="/", instance="192.168.1.20:3000", job="grafana", method="get", statuscode="200"} 20
#然后取平方根

四. ceil() 向上取整
ceil(node_filesystem_size_bytes{mountpoint = "/",device != "rootfs"} / 1024 / 1024 / 1024)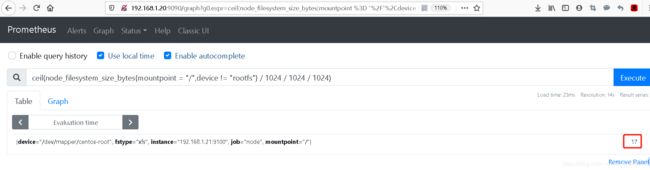
五. floor() 向下取证
#直接沿用上一个的语句
floor(node_filesystem_size_bytes{mountpoint = "/",device != "rootfs"} / 1024 / 1024 / 1024)
六.round 四舍五入取整
#继续沿用
round(node_filesystem_size_bytes{mountpoint = "/",device != "rootfs"} / 1024 / 1024 / 1024)
七. changes() 取变换次数
输入一个区间向量值,返回这个区间向量内每个样本数据值变化的次数
changes(node_filesystem_free_bytes{mountpoint = "/",device != "rootfs"}[2m])
#不是很明白什么地方会用到,难道要统计一段时间内写入的次数吗?八. clamp_max() 取最大值
输入一个"瞬时向量"和"最大值",如果瞬时向量的值大于最大值,则返回最大值
(如果小于最大值,则返回之前的值)
clamp_max(node_filesystem_free_bytes{mountpoint = "/",device != "rootfs"},1)
#我这里演示用的1,并不是只能为1 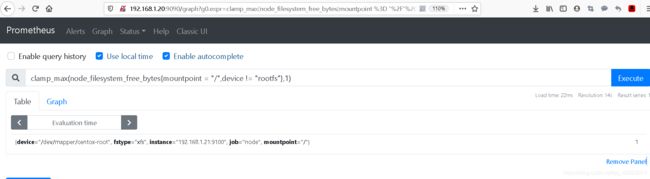
九.clamp_min() 取最小值
和clamp_max() 相反, 小于最小值则为最小值
(如果大于最大值,则返回之前的值)
#先查询一下
node_filesystem_free_bytes{mountpoint = "/",device != "rootfs"} / 1024 / 1024 /1024
#返回
{device="/dev/mapper/centos-root", fstype="xfs", instance="192.168.1.21:9100", job="node", mountpoint="/"} 9.193859100341797
#这里的值是9.193859100341797,小于10
#我们这里设置小于10的则值变更为10
clamp_min(node_filesystem_free_bytes{mountpoint = "/",device != "rootfs"} / 1024 / 1024 /1024 ,10)
十.lable_join() 新增标签
在原先标签的基础上,添加新的标签。 值来自于原先的标签的组合
在使用时需要提供一个瞬时向量,定义一个新标签名称,设置结果的连接分隔符,并建立要连接的标签
#先简单查询一下http请求状态码为200,模式为get的总量
http_request_total{handler="/login",method="get",statuscode="200"}
#返回
http_request_total{handler="/login", instance="192.168.1.20:3000", job="grafana", method="get", statuscode="200"} 2
#我们想要在他的后面添加一个新的标签,标名他的完整路径
label_join(http_request_total{handler="/login",method="get",statuscode="200"},"url","","instance","handler")
#含义
label_join() #新增标签
http_request_total{handler="/login",method="get",statuscode="200"} #度量值
"url" #新标签的名称
"" #新标签的值以什么进行分割
instance","handler" #该标签的值由 这个指标下的instance、handler这两个标签提供
#由""进行分隔
#返回结果
url="192.168.1.20:3000/login"
十一. lable_replace() 替换标签
和上面的lable_join()类似,他可以通过正则表达式来获取所选"源标签"的值
并将匹配的捕获组存储在目标标签中。 源和目标可以是同一个标签,有效的替换其的值
#先查询一下
http_request_total{handler="/login",method="get",statuscode="200",instance="192.168.1.20:3000"}
#返回
http_request_total{handler="/login", instance="192.168.1.20:3000", job="grafana", method="get", statuscode="200"} 2
#提供标签
label_replace(http_request_total{handler="/login",method="get",statuscode="200",instance="192.168.1.20:3000"}, "statuscode", "$1", "instance", ".*:(.*)")
#含义
label_replace() #替换标签操作
http_request_total{handler="/login",method="get",statuscode="200",instance="192.168.1.20:3000"} #度量值
"statuscode" #替换的标签,如果该指标下没有该标签,则改为新增标签
"$1" #匹配项,从0开始 第二部分 (也就是后面的3000)
"instance" #匹配的值来自于instance标签(192.168.1.20:3000)
".*:(.*)" #正则匹配
十二. predict_linear() 预测
基于一段时间的资源增长速度来判断多久会到达峰值,上一章有用过
#首先查看一下可用磁盘的容量
node_filesystem_free_bytes{mountpoint ="/",device="/dev/mapper/centos-root"}
#返回
node_filesystem_free_bytes{device="/dev/mapper/centos-root", fstype="xfs", instance="192.168.1.21:9100", job="node", mountpoint="/"} 9871712256
#可用空间是9871712256字节
#基于10分钟的样本值,推测1个小时后 磁盘可用资源大小
predict_linear(node_filesystem_free_bytes{mountpoint ="/",device="/dev/mapper/centos-root"}[10m], 1*3600)
#得到的值是9871168760.553926,这个值看起来太费劲了,我们调整一下
#将预测的值取整,然后用瞬时查询的值减去预测的可用值,就得到我们真实增长的容量
#取证预测值
ceil(predict_linear(node_filesystem_free_bytes{mountpoint ="/",device="/dev/mapper/centos-root"}[10m], 1*3600))
#瞬时值减去预测的可用值
node_filesystem_free_bytes{mountpoint ="/",device="/dev/mapper/centos-root"} - ceil(predict_linear(node_filesystem_free_bytes{mountpoint ="/",device="/dev/mapper/centos-root"}[10m], 1*3600))
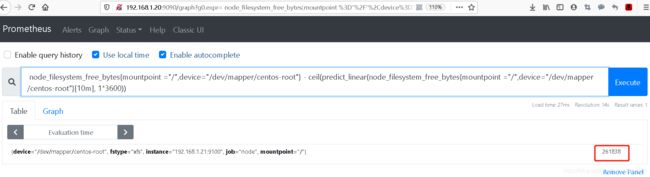
最后我们得知,如果正常运行的话。预测增长的值是261838字节的数据
十三. rate() 求区间增长率
直接通过"区间向量"计算请求访问的平均增长速率
该函数的返回结果不带有度量指标,只有标签列表
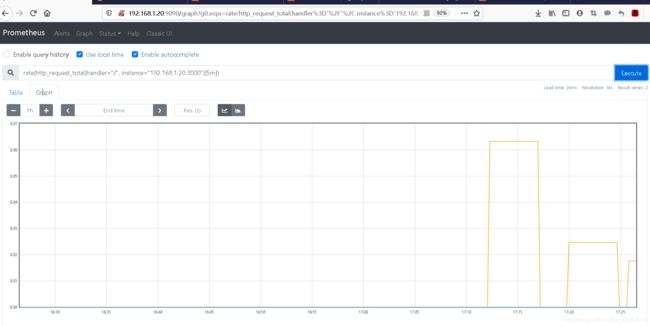
#查看区间向量中每个时间序列过去5分钟内 HTTP 请求数的每秒增长率
rate(http_request_total{handler="/", instance="192.168.1.20:3000"}[5m])
#如果都为0,可能是grafana太久没访问了,刷新几下再看看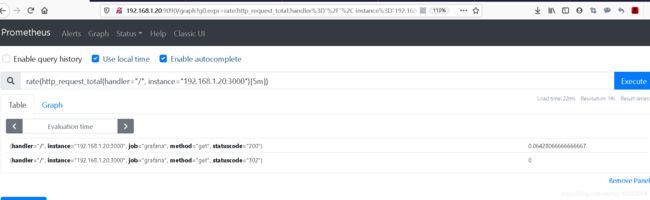
十四. irate() 求瞬时增长率
通rate类似,用于计算区间向量的增长率,但与rate不同的是他是用于计算"瞬时向量"的增长率
irate 函数是通过"区间向量"中"最后两个"样本数据来计算区间向量的增长速率的
#访问一下grafana,刷新几下
irate(http_request_total{handler="/", instance="192.168.1.20:3000"}[5m])
小知识
#irate 只能用于绘制快速变化的计数器,在长期趋势分析或者告警中更推荐使用 rate 函数。
#因为使用 irate 函数时,速率的简短变化会重置 FOR 语句,形成的图形有很多波峰,难以阅读。irate
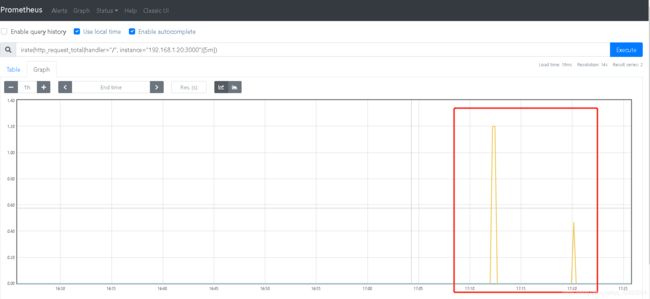
rate
十五. sort() 升序排序
sort(node_filesystem_free_bytes)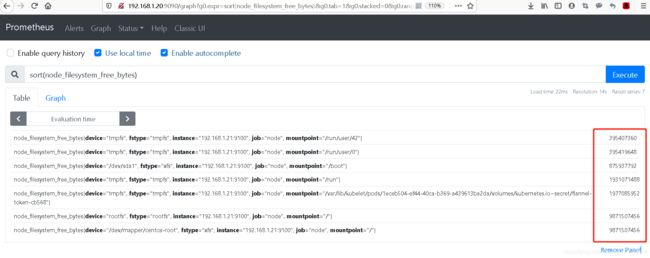
十六. sort_desc() 降序排序
sort_desc(node_filesystem_free_bytes)
十七. delta() 计算差值
# 计算内存在2分钟内的变换值
delta(node_memory_MemAvailable_bytes[2m])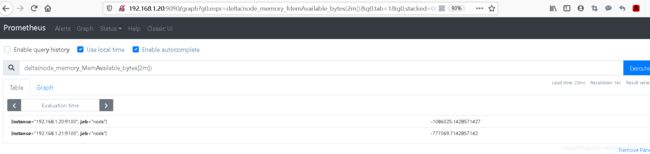

十八 increase()
#increase函数获取区间向量中的第⼀个和最后⼀个样本值并返回其增⻓量
increase(node_memory_MemAvailable_bytes[2m])
