生成式 AI 已经成为各行业创意过程增强和加速的常用工具,包括娱乐、广告和平面设计。它可以为观众创造更个性化的体验,并提高最终产品的整体质量。
| 亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库! |
生成式 AI 的一个重要优势是为用户创建独特和个性化的体验。例如,生成式 AI 被流媒体服务用于为电影标题和视觉效果生成个性化的内容,以增加观众参与度,并根据用户的观看历史和偏好为标题构建视觉效果。 然后,系统会生成标题艺术品的数千个变体,并进行测试以确定哪个版本最能吸引用户的注意力。 在某些情况下,个性化的电视剧艺术品大大提高了点击率和观看率,与没有个性化艺术品的节目相比。
在本文中,我们演示了如何使用 Amazon SageMaker 中的 Stable Diffusion 2.1基础模型构建个性化头像解决方案,并通过多模型端点(MME)同时节省推理成本。 该解决方案演示了,通过上传10-12张自拍照,您可以微调一个个性化模型,然后基于任何文本提示生成头像,如下图所示。 尽管此示例生成了个性化头像,但您可以将该技术应用于通过微调特定对象或风格的任何创意艺术生成。

解决方案概览
下图概述了我们头像生成器的端到端解决方案体系结构。

本文和我们提供的 GitHub 代码示例的范围仅集中在模型训练和推理编排上(上图中的绿色部分)。您可以参考完整的解决方案架构,并基于我们提供的示例进行构建。
模型训练和推理可以分为四个步骤:
- 将图片上传到 Amazon Simple Storage Service (Amazon S3)。在此步骤中,我们要求您至少提供10张高分辨率的自拍照。图片越多结果越好,但训练时间就越长。
- 使用 SageMaker 异步推理微调 Stable Diffusion 2.1基础模型。我们在后文中解释了使用推理端点进行训练的原因。微调过程首先准备图片,包括人脸裁剪、背景变化和调整大小以适应模型。然后,我们使用适用于大型语言模型(LLM) 的高效微调技术 Low-Rank Adaptation(LoRA) 来微调模型。最后,在后处理中,我们将微调后的 LoRA 权重与推理脚本和配置文件 (tar.gz) 打包,并上传到 SageMaker MME 的 S3 存储桶位置。
- 使用 GPU 的 SageMaker MME 托管微调后的模型。 SageMaker 将根据每个模型的推理流量动态加载和缓存来自Amazon S3 位置的模型。
- 使用微调后的模型进行推理。 在 Amazon Simple Notification Service (Amazon SNS) 通知表明微调完成后,您可以立即通过在调用 MME 时提供target_model参数来使用该模型创建头像。
我们在下面的章节中更详细地解释每个步骤,并介绍一些示例代码片段。
准备图片
为了从微调 Stable Diffusion 获得最佳结果以生成自身的图像,您通常需要提供大量不同角度、不同表情以及不同背景的自拍照。但是,通过我们的实现,您现在只需要10张输入图像就可以获得高质量的结果。我们还增加了从每张照片中提取面部的自动预处理功能。您只需要从多个视角清楚地捕捉面部特征。包括正面照,每个侧面的侧面照,以及之间的不同角度的照片。您还应该包括不同面部表情的照片,如微笑、皱眉和中性表情。具有不同表情的组合将使模型能够更好地重现您独特的面部特征。输入图像决定了您可以生成头像的质量。为了确保正确完成此操作,我们建议使用直观的前端 UI 体验来指导用户完成图像捕获和上传过程。
以下是不同角度和不同面部表情的示例自拍照。

微调 Stable Diffusion 模型
在图片上传到 Amazon S3 后,我们可以调用 SageMaker 异步推理端点来启动训练过程。异步端点针对大型有效载荷(最高1 GB)和长时间处理(最高1小时)的推理用例。它还提供了对请求进行排队的内置机制,以及通过 Amazon SNS 的任务完成通知机制,此外还具有 SageMaker 托管的其他本机功能,例如自动扩展。
尽管微调不是推理用例,但我们选择在此利用它而不是 SageMaker 训练作业,是由于其内置的排队和通知机制以及托管自动扩展功能,包括在服务不使用时将实例扩展到0的能力。这使我们可以轻松地针对大量并发用户扩展微调服务,并消除了实现和管理其他组件的需要。但是,它确实具有1 GB 有效负载和1小时最大处理时间的缺点。在我们的测试中,我们发现20分钟的时间在 ml.g5.2xlarge 实例上使用大约10张输入图像就足以获得合理良好的结果。但是,对于更大规模的微调作业,SageMaker 训练将是推荐方法。
要托管异步端点,我们必须完成几个步骤。首先是定义我们的模型服务器。对于本文,我们使用 Large Model Inference Container (LMI)。 LMI 由 DJL Serving 提供支持,这是一种高性能、与编程语言无关的模型服务解决方案。我们选择此选项是因为 SageMaker 托管推理容器已经具有我们需要的许多训练库,例如 Hugging Face Diffusers 和 Accelerate。这大大减少了自定义容器以进行微调作业所需的工作量。
下面的代码片段显示了我们在示例中使用的LMI容器的版本:
inference_image_uri = (
f"763104351884.dkr.ecr.{region}.amazonaws.com/djl-inference:0.21.0-deepspeed0.8.3-cu117"
)
print(f"Image going to be used is ---- > {inference_image_uri}")此外,我们需要一个serving.properties文件来配置服务属性,包括要使用的推理引擎、模型工件的位置以及动态批处理。最后,我们必须有一个model.py文件,用于将模型加载到推理引擎中,并准备模型的数据输入和输出。在我们的示例中,我们使用model.py文件来启动微调作业,我们将在后面的章节中对此进行更详细的解释。 serving.properties和model.py文件都在training_service文件夹中提供。
定义模型服务器之后的下一步是创建一个端点配置,该配置定义我们的异步推理的服务方式。对于我们的示例,我们只是定义了最大并发调用限制和输出 S3 位置。使用ml.g5.2xlarge实例,我们发现我们可以同时微调两个模型,而不会遇到内存不足 (OOM) 异常,因此我们将max_concurrent_invocations_per_instance设置为2。如果我们使用不同的一组调谐参数或较小的实例类型,则可能需要调整此数字。我们建议将其最初设置为1,并在 Amazon CloudWatch 中监控 GPU 内存利用率。
# create async endpoint configuration
async_config = AsyncInferenceConfig(
output_path=f"s3://{bucket}/{s3_prefix}/async_inference/output" , # Where our results will be stored
max_concurrent_invocations_per_instance=2,
notification_config={
"SuccessTopic": "...",
"ErrorTopic": "...",
}, # Notification configuration
)最后,我们创建一个 SageMaker 模型,该模型将容器信息、模型文件和 Amazon Identity and Access Management (IAM) 角色打包成一个对象。该模型使用我们之前定义的端点配置进行部署:
model = Model(
image_uri=image_uri,
model_data=model_data,
role=role,
env=env
)
model.deploy(
initial_instance_count=1,
instance_type=instance_type,
endpoint_name=endpoint_name,
async_inference_config=async_inference_config
)
predictor = sagemaker.Predictor(
endpoint_name=endpoint_name,
sagemaker_session=sagemaker_session
)当端点就绪时,我们使用以下示例代码调用异步端点并启动微调过程:
sm_runtime = boto3.client("sagemaker-runtime")
input_s3_loc = sess.upload_data("data/jw.tar.gz", bucket, s3_prefix)
response = sm_runtime.invoke_endpoint_async(
EndpointName=sd_tuning.endpoint_name,
InputLocation=input_s3_loc)有关 SageMaker 上的LMI的更多详细信息,请参阅使用 DJLServing 和 DeepSpeed 模型并行推理在 Amazon SageMaker 上部署大型模型。
调用后,异步端点开始对我们的微调作业进行排队。每个作业都会执行以下步骤:准备图像,执行 Dreambooth 和 LoRA 微调,以及准备模型工件。让我们深入探讨微调过程。
准备图片
如前所述,输入图像的质量直接影响微调模型的质量。对于头像用例,我们希望模型专注于面部特征。我们实施了一个预处理步骤,使用计算机视觉技术来减轻这种负担,而不是要求用户提供精心策划的特定大小和内容的图像。在预处理步骤中,我们首先使用人脸检测模型隔离每张图像中的最大面部。然后,我们裁剪并填充图像以获得模型所需的512 x 512像素大小。最后,我们从背景中分割面部并添加随机背景变化。这有助于突出面部特征,从而使我们的模型可以从面部本身而不是背景中学习。下面的图像说明了此过程中的三个步骤。

Step 1: Face detection using computer vision
Step 2: Crop and pad the image to 512 x 512 pixels
Step 3 (Optional): Segment and add background variation
Dreambooth 和 LoRA 微调
对于微调,我们结合了 Dreambooth 和 LoRA 的技术。Dreambooth 允许您使用唯一标识符和扩展模型的语言视觉词典,将主体嵌入模型的输出域中。它使用一种称为先验保持的方法来保留模型对主体类别(在本例中为人)的语义知识,并使用其他对象类中的对象来改进最终图像输出。这就是 Dreambooth 如何能够仅使用少量主体输入图像就能够实现高质量结果的原因。
下面的代码片段显示了我们头像解决方案的trainer.py类的输入。请注意,我们选择了<
status = trn.run(base_model="stabilityai/stable-diffusion-2-1-base",
resolution=512,
n_steps=1000,
concept_prompt="photo of <>", # << unique identifier of the subject
learning_rate=1e-4,
gradient_accumulation=1,
fp16=True,
use_8bit_adam=True,
gradient_checkpointing=True,
train_text_encoder=True,
with_prior_preservation=True,
prior_loss_weight=1.0,
class_prompt="a photo of person", # << subject class
num_class_images=50,
class_data_dir=class_data_dir,
lora_r=128,
lora_alpha=1,
lora_bias="none",
lora_dropout=0.05,
lora_text_encoder_r=64,
lora_text_encoder_alpha=1,
lora_text_encoder_bias="none",
lora_text_encoder_dropout=0.05
) 启用了许多内存节省选项,包括fp16、use_8bit_adam和梯度累积。这将内存占用减少到12 GB以下,从而允许在ml.g5.2xlarge实例上同时微调多达两个模型。
LoRA 是一种高效的 LLM 微调技术,它冻结了大部分权重,并在预训练 LLM 的特定层附加了一个小的适配器网络,从而实现更快的训练和优化的存储。对于 Stable Diffusion,适配器连接到推理流水线的文本编码器和 U-Net 组件。文本编码器将输入提示转换为 U-Net 模型可以理解的潜在空间,然后 U-Net 模型使用潜在含义在随后的扩散过程中生成图像。微调的输出仅为text_encoder和 U-Net 适配器权重。在推理时,可以重新连接这些权重到基础 Stable Diffusion 模型以重现微调结果。
下面的图表是原作者提供的 LoRA 微调详细图:Cheng-Han Chiang, Yung-Sung Chuang, Hung-yi Lee, “AACL_2022_tutorial_PLMs,” 2022
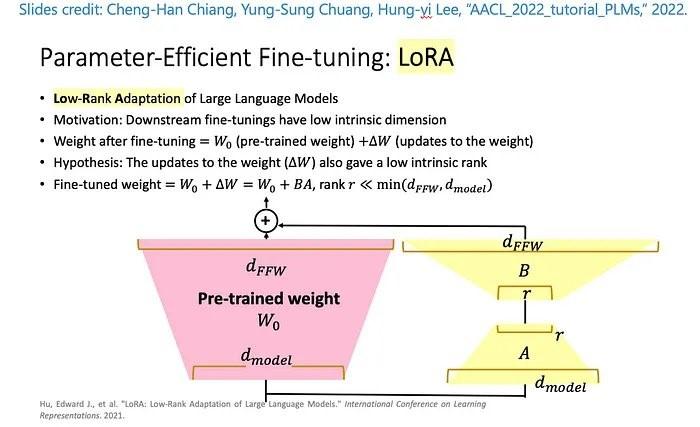
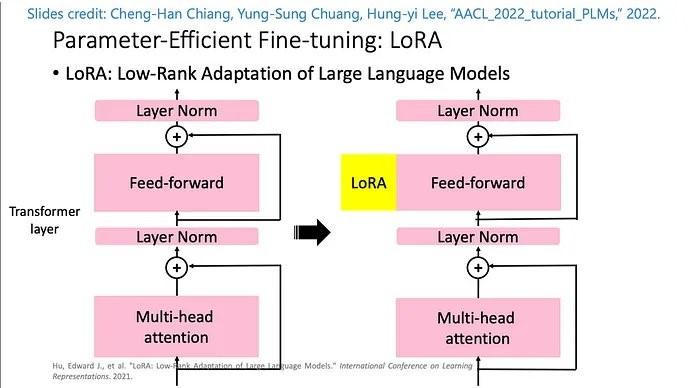
通过结合两种方法,我们能够在调谐数量级更少的参数的同时生成个性化模型。这大大缩短了训练时间和GPU利用率。此外,由于适配器权重仅为70 MB,而完整的 Stable Diffusion 模型为6 GB,存储量减少了99%。
准备模型工件
微调完成后,后处理步骤将使用 LoRA 权重和 NVIDIA Triton 的其余模型服务文件创建 TAR 文件。我们使用 Python 后端,这意味着需要 Triton 配置文件和用于推理的 Python 脚本。请注意,Python 脚本必须命名为model.py。最终的模型TAR文件应具有以下文件结构:
|--sd_lora
|--config.pbtxt
|--1\
|--model.py
|--output #LoRA weights
|--text_encoder\
|--unet\
|--train.sh使用 GPU 的 SageMaker MME 托管微调后的模型
在对模型进行微调后,我们使用 SageMaker MME 托管个性化的 Stable Diffusion 模型。SageMaker MME 是一个强大的部署功能,允许在单个容器后面通过单个端点托管多个模型。它会自动管理流量和路由到您的模型,以优化资源利用率、节省成本和最小化管理数千个端点的运营负担。在我们的示例中,我们在 GPU 实例上运行,SageMaker MME 通过Triton Server 支持 GPU。这允许您在单个 GPU 设备上运行多个模型,并利用加速计算。有关如何在 SageMaker MME 上托管 Stable Diffusion 的更多详细信息,请参阅使用 Amazon SageMaker Stable Diffusion 模型创建高质量图像并以高效低成本地部署。
对于我们的示例,我们进行了额外的优化,以在冷启动情况下更快地加载微调模型。这是 LoRA 适配器设计使之成为可能的。由于所有微调模型的基本模型权重和 Conda 环境都是相同的,我们可以通过将这些公共资源预先加载到托管容器上来共享它们。这只剩下需要从 Amazon S3 动态加载的 Triton 配置文件、Python 后端(model.py)和 LoRA 适配器权重。下图提供了横向比较。

这将模型TAR文件大小从约6GB显着减小到70MB,因此加载和解包速度更快。在我们的示例中,我们在models/model_setup中创建了一个实用的Python后端模型。该脚本简单地将基础 Stable Diffusion 模型和 Conda 环境从 Amazon S3 复制到公共位置,以在所有微调模型之间共享。以下是执行该任务的代码片段:
def initialize(self, args):
#conda env setup
self.conda_pack_path = Path(args['model_repository']) / "sd_env.tar.gz"
self.conda_target_path = Path("/tmp/conda")
self.conda_env_path = self.conda_target_path / "sd_env.tar.gz"
if not self.conda_env_path.exists():
self.conda_env_path.parent.mkdir(parents=True, exist_ok=True)
shutil.copy(self.conda_pack_path, self.conda_env_path)
#base diffusion model setup
self.base_model_path = Path(args['model_repository']) / "stable_diff.tar.gz"
try:
with tarfile.open(self.base_model_path) as tar:
tar.extractall('/tmp')
self.response_message = "Model env setup successful."
except Exception as e:
# print the exception message
print(f"Caught an exception: {e}")
self.response_message = f"Caught an exception: {e}"然后每个微调模型将指向容器上的共享位置。Conda 环境在config.pbtxt中引用。
name: "pipeline_0"
backend: "python"
max_batch_size: 1
...
parameters: {
key: "EXECUTION_ENV_PATH",
value: {string_value: "/tmp/conda/sd_env.tar.gz"}
}在每个model.py文件的initialize()函数中,从 Stable Diffusion 基本模型加载。然后我们将个性化的 LoRA权重应用于 unet 和text_encoder模型以重现每个微调模型:
...
class TritonPythonModel:
def initialize(self, args):
self.output_dtype = pb_utils.triton_string_to_numpy(
pb_utils.get_output_config_by_name(json.loads(args["model_config"]),
"generated_image")["data_type"])
self.model_dir = args['model_repository']
device='cuda'
self.pipe = StableDiffusionPipeline.from_pretrained('/tmp/stable_diff',
torch_dtype=torch.float16,
revision="fp16").to(device)
# Load the LoRA weights
self.pipe.unet = PeftModel.from_pretrained(self.pipe.unet, unet_sub_dir)
if os.path.exists(text_encoder_sub_dir):
self.pipe.text_encoder = PeftModel.from_pretrained(self.pipe.text_encoder, text_encoder_sub_dir)使用微调后的模型进行推理
现在我们可以尝试微调后的模型,方法是调用 MME 端点。我们在示例中公开的输入参数包括prompt、negative_prompt和gen_args,如下面的代码片段所示。我们在字典中为每个输入项设置了数据类型和形状,并将其转换为 JSON 字符串。最后,有效负载字符串和TargetModel被传递到请求中以生成头像图片。
import random
prompt = """<> epic portrait, zoomed out, blurred background cityscape, bokeh,
perfect symmetry, by artgem, artstation ,concept art,cinematic lighting, highly
detailed, octane, concept art, sharp focus, rockstar games, post processing,
picture of the day, ambient lighting, epic composition"""
negative_prompt = """
beard, goatee, ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, blurry, bad anatomy, blurred,
watermark, grainy, signature, cut off, draft, amateur, multiple, gross, weird, uneven, furnishing, decorating, decoration, furniture, text, poor, low, basic, worst, juvenile,
unprofessional, failure, crayon, oil, label, thousand hands
"""
seed = random.randint(1, 1000000000)
gen_args = json.dumps(dict(num_inference_steps=50, guidance_scale=7, seed=seed))
inputs = dict(prompt = prompt,
negative_prompt = negative_prompt,
gen_args = gen_args)
payload = {
"inputs":
[{"name": name, "shape": [1,1], "datatype": "BYTES", "data": [data]} for name, data in inputs.items()]
}
response = sm_runtime.invoke_endpoint(
EndpointName=endpoint_name,
ContentType="application/octet-stream",
Body=json.dumps(payload),
TargetModel="sd_lora.tar.gz",
)
output = json.loads(response["Body"].read().decode("utf8"))["outputs"]
original_image = decode_image(output[0]["data"][0])
original_image 清理
按照 notebook 中的清理部分的说明删除作为本文一部分预配的资源,以避免不必要的费用。有关推理实例成本的详细信息,请参阅 Amazon SageMaker 定价。
结论
在本文中,我们演示了如何使用 SageMaker 上的 Stable Diffusion 创建个性化头像解决方案。通过仅使用少量图像微调预训练模型,我们可以生成反映每个用户个性和人格的头像。这只是我们如何使用生成式 AI 为用户创建定制化和独特体验的众多示例之一。可能性是无限的,我们鼓励您尝试这项技术并探索其增强创意过程的潜力。我们希望本文信息丰富且鼓舞人心。我们鼓励您尝试该示例,并通过社交平台上的 #sagemaker #mme #genai 标签与我们分享您的创作。我们很想知道您创作的作品。
除了 Stable Diffusion,还有许多其他生成式AI模型可在 Amazon SageMaker JumpStart 上获得。参阅开始使用 Amazon SageMaker JumpStart 来探索他们的功能。
文章来源:https://dev.amazoncloud.cn/column/article/64e5ffc984d23218430...