1.硬件结构
1.CPU如何执行程序?
图灵机的工作方式
纸带:一个一个连续的格子存放数据;
读写头:读取纸带上格子字符,读写头上有一些部件,比如存储单元、控制单元及运算流程
1、存储单元用于存放数据; 2、控制单元用于识别字符是数据还是指令,以及控制程序的流程等; 3、运算单元用于执行运算指令。
冯诺依曼模型
冯诺依曼模型:运算器、控制器、存储器、输入设备、输出设备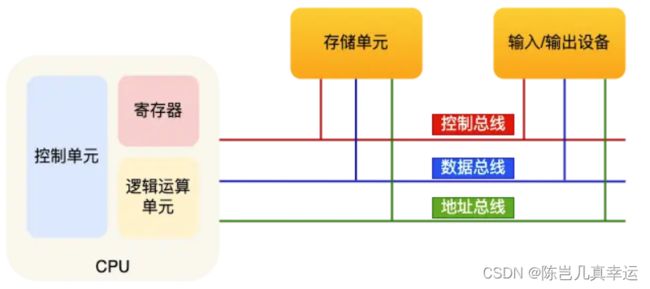
内存:
程序和数据存储在内存,存储的区域是线性的,存储数据的基本单位是字节byte,一字节等于8位,1byte=8bit
中央处理器:
CPU 32 位和 64 位,通常称为 CPU 的位宽,代表的是 CPU 一次可以计算(运算)的数据量。
- 32 位 CPU 一次可以计算 4 个字节;
- 64 位 CPU 一次可以计算 8 个字节;
CPU内部有寄存器、控制单元和逻辑单元,控制单元用于控制CPU工作,逻辑单元负责计算、寄存器可以分为多个种类,每种寄存器功能不同:
为什么需要寄存器,内存离CPU太远了,寄存器在CPU中,离控制单元逻辑单元近
- 通用寄存器,用来存放需要进行运算的数据,比如需要进行加和运算的两个数据。
- 程序计数器,用来存储 CPU 要执行下一条指令「所在的内存地址」,注意不是存储了下一条要执行的指令,此时指令还在内存中,程序计数器只是存储了下一条指令「的地址」。
- 指令寄存器,用来存放当前正在执行的指令,也就是指令本身,指令被执行完成之前,指令都存储在这里。
总线:
总线是用于CPU和内存以及其他设备之间的通信:
 输入、输出设备:
输入、输出设备:
输入设备向计算机输入数据,计算机经过计算后,把数据输出给输出设备。期间,如果输入设备是键盘,按下按键时是需要和 CPU 进行交互的,这时就需要用到控制总线了。
线路位宽与 CPU 位宽
数据是如何通过线路传输的呢?其实是通过操作电压,低电压表示 0,高压电压则表示 1。
为了避免低效率的串行传输的方式,线路的位宽最好一次就能访问到所有的内存地址。
如果计算的数额不超过 32 位数字的情况下,32 位和 64 位 CPU 之间没什么区别的,只有当计算超过 32 位数字的情况下,64 位的优势才能体现出来。
程序执行的基本过程

①:CPU读取【程序寄存器】的值(指令内存地址),【控制单元】操作【地址总线】找到对应程序内存地址,通知内存设备准备好数据,数据通过【数据总线】传给CPU,存入【指令寄存器】;
②:【程序寄存器】的值自增,表示指向下一条指令。自增大小由CPU位宽表示,32位增4字节。
③:CPU分析【指令寄存器】确定指令类型和数据,交给【逻辑运算单元】。
一个程序执行的时候,CPU 会根据程序计数器里的内存地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令
2.磁盘比内存慢几万倍?
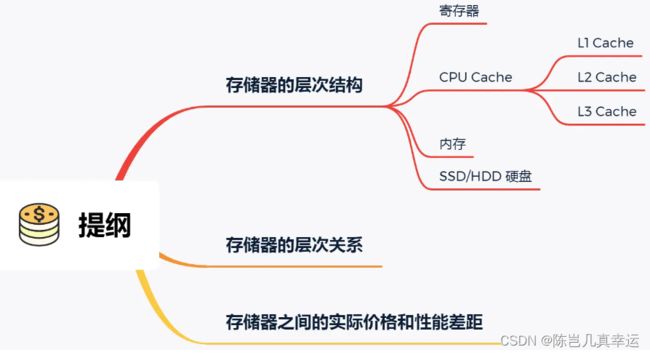
CPU中寄存器,处理速度是最快的,但是能存储的数据也是最少
CPU Cache称为CPU告诉缓存,通常会分为 L1、L2、L3 三层:
L1 Cache 通常分成「数据缓存」和「指令缓存」,L1离CPU最近,且最小
存储器的层次关系

3 如何写出让 CPU 跑得更快的代码?
一个内存的访问地址,包括组标记、CPU Cache Line 索引、偏移量这三种信息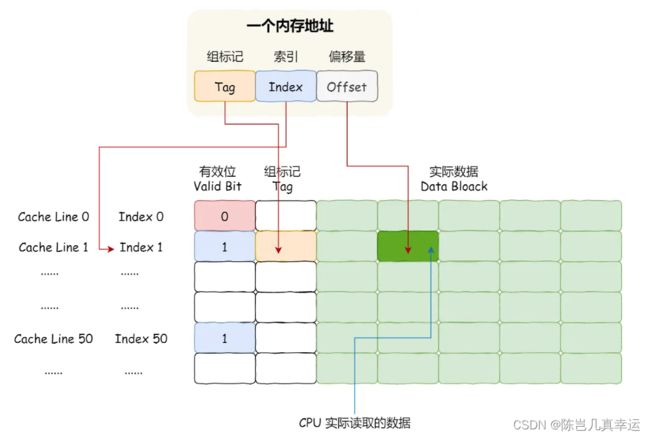
如何提升数据缓存的命中率?
形式一用 array[i][j] 访问数组元素,形式二的 array[j][i] 来访问,形式一更快
按照内存布局顺序访问,将可以有效的利用 CPU Cache 带来的好处,这样我们代码的性能就会得到很大的提升。
如何提升指令缓存的命中率?
如果分支预测可以预测到接下来要执行 if 里的指令,还是 else 指令的话,就可以「提前」把这些指令放在指令缓存中,这样 CPU 可以直接从 Cache 读取到指令,于是执行速度就会很快。
如何提升多核 CPU 的缓存命中率?
如果一个线程在不同核心来回切换,各个核心的缓存命中率就会受到影响,
当有多个同时执行「计算密集型」的线程,为了防止因为切换到不同的核心,而导致缓存命中率下降的问题,我们可以把线程绑定在某一个 CPU 核心上,这样性能可以得到非常可观的提升。
总结:
CPU Cache 作为内存与 CPU 之间的缓存层,CPU访问数据先从 CPU Cache 中找,如果缓存命中直接返回数据。如果 CPU Cache 里面没有,要从内存中每一读取一块的数据放到 CPU Cache 中。内存映射到 CPU Cache :把内存地址拆分成 [索引+组标记+偏移量]的方式。
4.CPU 缓存一致性
CPU Cache不仅需要读取数据,修改后还要同步数据,就是把cache数据同步到内存
写直达
把数据同时写入内存和 Cache 中,这种方法称为写直达,每次写操作都会把数据写回到内存,而导致影响性能
写回
当发生写操作时,新的数据仅仅被写入 Cache Block 里,只有当修改过的 Cache Block「被替换」时才需要写到内存中,
在把数据写入到 Cache 的时候,只有在缓存不命中,同时数据对应的 Cache 中的 Cache Block 为脏标记的情况下,才会将数据写到内存中,而在缓存命中的情况下,则在写入后 Cache 后,只需把该数据对应的 Cache Block 标记为脏即可,而不用写到内存里。
缓存一致性问题
由于 L1/L2 Cache 是多个核心各自独有的,那么会带来多核心的缓存一致性(Cache Coherence) 的问题
- 第一点,某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache,这个称为写传播(Write Propagation);
- 第二点,某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的,这个称为事务的串行化(Transaction Serialization)。
串行化需要保证核心C和D都能看到相同顺序的数据变化,这里就要使用锁了。
写传播的原则就是当某个 CPU 核心更新了 Cache 中的数据,要把该事件广播通知到其他核心。最常见实现的方式是总线嗅探(Bus Snooping)。
MESI 协议
总线嗅探:保证某个 CPU 核心的 Cache 更新数据这个事件能被其他 CPU 核心知道。
MESI协议:基于总线嗅探机制实现了事务串行化,也用状态机机制降低了总线带宽压力,这个协议就是 MESI 协议,这个协议就做到了 CPU 缓存一致性。
整个 MSI 状态的变更,则是根据来自本地 CPU 核心的请求,或者来自其他 CPU 核心通过总线传输过来的请求,从而构成一个流动的状态机。另外,对于在「已修改」或者「独占」状态的 Cache Line,修改更新其数据不需要发送广播给其他 CPU 核心。
5.CPU 是如何执行任务的?
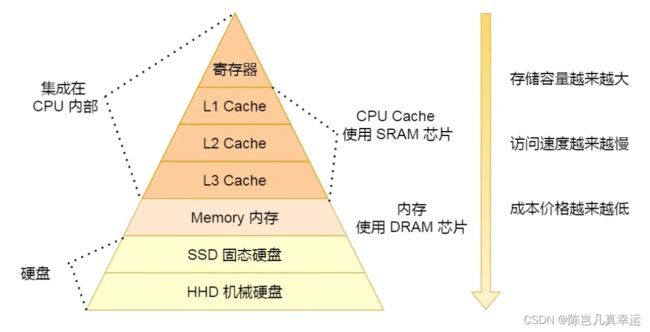
CPU Cache Line 是 CPU 从内存读取数据到 Cache 的单位。 L1 Cache 一次载入数据的大小是 64 字节。