Rust 学习笔记之内存管理与生命周期
内存管理是理解低级语言(和硬件相关的)的基础概念。低级语言没有提供自动内存管理的解决方案,例如内置垃圾回收器。它要求程序员自己在程序中管理内存。理解内存何时何地被创建和释放可以使得程序员构建出一个高效、安全的软件。然而,低级语言的大量错误也正是因为程序员使用内存不当造成的。
C 和 C++ 因为容易出现大量的内存漏洞而一直被人们诟病,因此不少人选择使用 Java 这种自带垃圾回收的语言,既可以提高安全性,又省去内存管理的心智负担。不过,无论使用哪种垃圾回收方案,都无法避免世界暂停现象,垃圾回收器会使得程序中断,接着进行回收内存的操作。换句话说,这带来了性能的开销。
Rust 选择在编译阶段解决内存管理的问题,尽可能通过良好的编程实践,阻止程序员编写出糟糕的代码,通过编译器的指导程序员编写出安全、高效使用内存的软件。
内存安全
内存安全指的是程序不会碰到不该碰到的内存位置(例如越界),程序里的指针不能指向无效的内存(NULL),在整个代码中相关的内存都应该是有效的。换句话说,安全意味着程序指针始终是有效引用,进行指针操作的时候不会出现未定义的行为,例如访问未初始化的数组,编译器没有说明这种情况下会发生什么:
#include 编译执行这段代码,输出的都是随机值。这种情况最好是可以立即崩溃,像这样表面看起来很正常,很可能日后就成为一颗定时炸弹,在某些情况下导致错误的输出。
还有一种很常见的内存安全问题就是迭代器失效:
#include 能够正常编译这段代码,并且在某些情况下是能正常运行,但是某些情况下却会导致段错误。原因在于 push_back 有可能引发内存的重新分配(扩容),导致原有的迭代器失效(原本迭代器指向的内存已经被复制后删除了)。那么循环继续访问失效的内存,就会产生错误。
另外一种常见的内存安全问题就是数组越界:
int main()
{
char buf[3];
buf[0] = 'a';
buf[1] = 'b';
buf[2] = 'c';
buf[3] = 'd';
}
这种内存安全问题很容易导致缓冲区溢出攻击。现在的 gcc 版本中会使用 SIGABRT(中止)信号阻止程序。
还有另外一种内存问题就是内存泄漏。Rust 并不能完全解决这类问题。内存泄漏相对而言危害性不如上面几种,但如果需要一个长时间运行的系统,内存泄漏问题是值得关注的。内存日积月累的泄漏,长期运行下来,总会把内存占满,最终可能导致宕机。
所有权
所有者的概念不同语言有所不同。我们这里使用资源(resource)来统称堆或者栈上的任何变量,包括持有打开文件描述符、数据库连接、网络套接字等等。从他们存在到程序使用时,均占用一些内存。作为资源的所有者,一个重要指责就是在适当的时候释放掉内存。
像 Python 这样的动态语言中,可以有多个所有者或者别名指向类似 list 这样的对象。不需要关心和释放对象的问题,因为 GC 会处理这些问题。对于编译型语言,比如 C 或者 C++,由于没有清楚的界定所有权,很多时候内存该由库来释放还是由用户来释放是不清楚的,需要进一步的了解才能确定。C/C++ 语言允许多个指针指向同一个内存,这也是很多内存问题的根源,只要其中有一个释放掉内存,其余的指针就不能再使用了(当然,RAII 惯用法可以极大程度上解决这个问题)。
Rust 则希望给所有权定下明确的规则:
- 使用
let创建资源并分配给变量后,这个变量就是该资源的所有者; - 但该变量被重新绑定到另外一个变量后,所有权会转移到新的变量上,原有变量不能再访问;
- 变量会在作用域结束时被释放;
简而言之,Rust 规定了在同一时间里只能有一个所有者:
#[derive(Debug)]
struct Foo(u32);
fn main()
{
let foo = Foo(2048);
let bar = foo;
println!("Foo is {:?}", foo);
println!("Bar is {:?}", bar);
}
使用 rustc 编译这段代码,会发现报错:
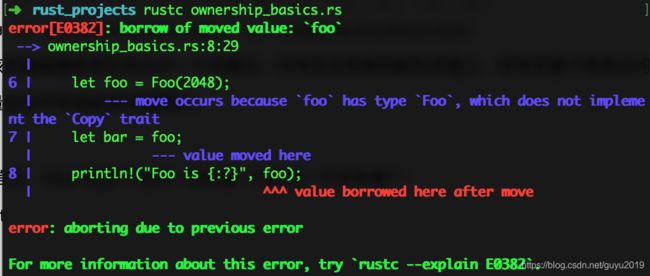
代码中,我们创建了两个变量,foo 和 bar。一开始 foo 拥有了 Foo 对象的所有权,随后重新绑定到了 bar 上,那么原来的 foo 变量就不再具有 Foo 资源的所有权了。也就是说,Rust 不允许在这个作用域内拥有两个可以修改资源的变量。
作用域
Rust 的作用域和大部分语言一样,同样支持 {} 建立块级作用域。作用域之间可以互相嵌套,但是内部作用域可以访问父作用域的环境变量,反之则不行。
fn main()
{
let level_0_str = String::from("foo");
{
let level_1_number = 9;
{
let mut level_2_vector = vec![1, 2, 3];
level_2_vector.push(level_1_number);
} // level_2_vector 作用域结束,被释放
level_2_vector.push(4); // 不存在了!!!
} // level_1_number 作用域结束
} // level_0_str 作用域结束
进行所有权推理的时候,作用域的范围是需要记住的重要属性。作用域结束的时候,会自动隐式调用 Drop 方法来释放内存。
Move 和 Copy 语义
Rust 中默认是是移动语义。C++ 默认则是 Copy语义,直到 C++ 11 才引入 Move 移义。复制语义意味着得到是值的副本,两个变量之间其实并没有联系。至于移动语义,并不进行拷贝,而是进行了所有权的转移。Rust 由于它的类型系统是仿射类型系统,默认具有移动语义。仿射类型系统的一个突出的特点就是值或者资源只能用一次。
如果 Rust 只有移动语义,有时就有一定的局限性。因此,Rust 提供了 Copy trait 来实现 Copy 语义。
#[derive(Copy, Clone, Debug)]
struct Dummy;
fn main() {
let a = Dummy;
let b = a;
println!("{:?}", a);
println!("{:?}", b);
}
对于简单的原生类型,例如 u32,Rust 默认实现了 Copy,但对于稍微复制的类型,一般都是移动语义,从而避免复制内存的开销。
Copy
Copy 通常用来实现完全由堆栈表示的类型,也就是在 C/C++ 中一般不用 malloc 和 new 的类型。换句话说,没有内存是在堆上的。如果类型是在堆上,Copy 一般就会是性能较差的操作,因为实现了 Copy 意味着从一个变量到另一个变量的赋值会隐式的复制数据,这个操作就很类似 C 语言中的 memcpy。
Rust 中,Vec、String,可变引用都默认没有实现 Copy。要复制这些值,我们需要更加明确的使用 Clone trait。
Clone
Clone trait 是用于显式复制的,它带有一个 clone 方法。Clone trait 的定义类似这样:
pub trait Clone {
fn clone(&self) -> Self;
}
可以看到它接收一个不可变的引用,并且返回一个相同类型的值。不像 Copy 可以隐式调用,使用 Clone 必须显式调用 clone 方法。
clone 方法是更加通用的复制机制,Copy 只是它的特例,Copy 总是按位复制。智能指针的类型也实现了 Clone trait,但它只需要复制指针和额外的元数据,例如引用计数。
#[derive(Clone, Debug)]
struct Dummy {
items: u32
}
fn main() {
let a = Dummy { items: 54 };
let b = a.clone();
println!("a: {:?}, b: {:?}", a, b);
}
正如前面所说的,Copy trait 只是 Clone trait 的特殊情况,因此要实现 Copy trait,就必须支持 Clone trait。
借用
借用的概念是为了规避所有权规则的限制。在借用下,并不会拥有值,而只会在需要的时候提供数据。
不可变借用
使用 & 操作符可以创建一个不可变借用。之前的例子可以用借用重写:
#[derive(Debug)]
struct Foo;
fn main()
{
let foo = Foo;
let bar = &foo;
println!("Foo is {:?}", foo);
println!("Bar is {:?}", bar);
}
可变借用
可变借用在 & 之前加上 mut,需要注意的是 Rust 默认是不可变的,因此要使用可变借用,前提是原来的资源就是可变的。
fn main()
{
let mut a = String::from("Owned string");
let a_ref = &mut a;
a_ref.push('!');
println!("{}", a);
println!("{}", a_ref);
}
编译这段代码,会报错:

Rust 规定了一旦值有了可变的借用,就不能再有其它的借用了,即使是不可变的借用。
借用规则
- 引用的生命周期不能长于它所引用的值。这个很显然,如果引用的值已经被释放了,引用就是非法的。
- 可变引用是排他性引用。也就是说,只要值存在可变引用,就不允许在作用域范围内存在对同一个值的引用,无论是可变还是不可变。
- 如果没有可变性引用,允许任意数量的不可变引用,即只读的引用可以有多个。
生命周期
借用的检查但单个作用域内是自动的,但是一旦跨作用域,有时候就需要我们手动标注生命周期参数。
struct SomeRef<T> {
part: &T
}
fn main()
{
let a = SomeRef { part: &43 };
}
这段代码非常简单,但是编译的时候会发现报错:
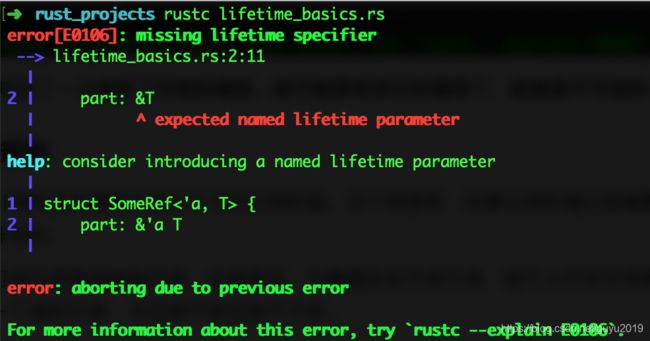
Rust 编译器也提供了一个参考的解决方案,我们按照编译器的提示,添加上生命周期参数:
#[allow(dead_code)]
struct SomeRef<'a, T> {
part: &'a T
}
fn main()
{
let _a = SomeRef { part: &43 };
}
需要注意的是,添加生命周期参数并不能改变变量的生命长度,仅仅是为了编译器进行借用检查。生命周期参数用 ' 表示,后面可以接任意的标识符,但是,按照惯例,基本都是使用 'a、'b 和 'c 作为生命周期参数。当然,如果你想使用更长的描述也是可以的,比如 ctx、reader、writer 等等。
Rust 还有一个静态的生命周期,使用 'static 表示,Rust 中所有的字符串文本都是具有 static 的生命周期长度,意味着在程序的整个时间内都持续有效。
生命周期规则
大多数时候,都不需要显式写生命周期参数,编译器会进行自动的推断和生成。例如下面的第二种写法等价与第一种:
fn func_one(x: &u8) -> &u8 { .. }
fn func_two<'a>(x: &'a u8) -> &'a u8 { .. }
当然,省略生命周期是有条件限制的。这里有两个概念:
- 输入生命周期:函数形参上的生命周期参数称为输入生命周期;
- 输出生命周期:函数返回值的生命周期称为输出生命周期;
省略的生命周期参数的规则如下:
- 只有一个输入生命周期参数,则分配给输出生命周期参数;
- 包含
&self和&mut self,则将&self的生命周期分配输出生命周期;
需要注意的是,如果函数有多个参数,则每个位置都会假定有不同的生命周期。在一些模棱两可的情况下,编译器是不会作出假定的:
fn foo(a: &str, b: &str) -> &str {
b
}
fn main()
{
let a = "Hello";
let b = "World";
let c = foo(a, b);
}
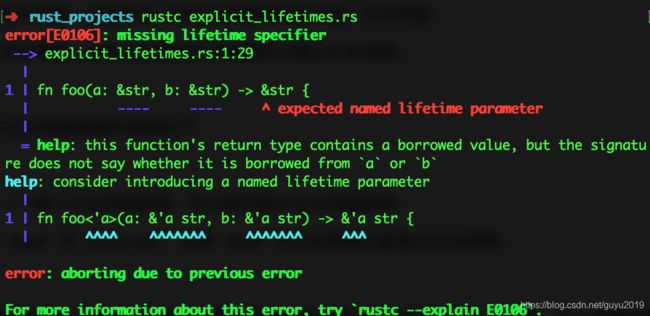
因为编译器会把 a 和 b 标为不同的生命周期,但两者之间的并不能直接推断出关系。我们当然可以手动将 a 和 b 标注一样的生命周期参数 'a,或者提供两者之间的生命周期关系:
fn foo<'b, 'a: 'b>(_a: &'a str, b: &'b str) -> &'b str {
b
}
fn main()
{
let a = "Hello";
let b = "World";
let _c = foo(a, b);
}
生命周期参数的位置和泛型是一样的,而 'a: 'b 则说明 'a 的生命周期长度包含 'b 的生命周期长度,即 'a 比 'b 的生命周期更长。
当然,也可以用 where 语法将两个生命周期参数之间的关系后置:
fn foo<'a, 'b>(_a: &'a str, b: &'b str) -> &'b str where 'a: 'b {
b
}
通常在下面三种情况下,需要手动标注生命周期参数:
- 函数形参
- 结构体及其字段;
impl
指针
如果不讨论指针,内存管理的故事是不完整的,因为指针是任何低级语言操作内存的主要方法。指针只是指向进程地址空间中内存位置的变量。在 Rust 中,我们处理三种类型的指针。
引用
引用比指针安全,它不会为空,总是指向变量的数据。使用 & 或者 &mut 操作符去创建一个引用。
&T:不可变的引用类型T。&T指针是一个Copy类型,意味着可以有多个不可变的引用指向值T。如果你绑定到其他的变量,会得到这个指针的拷贝。&mut T:指向类型T的可变指针。在同一个作用域内,不能有两个及以上的指向类型T的可变指针。也就是说,它并没有实现Copytrait,也不能被发送到线程上。
原生指针
原生指针带有一个 * 的符号,这个符号也是解引用的运算符。大部分时候用在 unsafe 块中。
*const T:指向类型T不可变的原生指针。类似&T,同样实现了Copy,只不过*const T有可能是null,而引用不会。*mut T:指向值T的原生可变指针,同样地,没有实现Copy。
引用可以转换成原生指针,就像下面这样:
let a = &56;
let a_raw_ptr = a as *const i32;
// or
let b = &mut 5634.3;
let b_mut_ptr = b as *mut f64;
注意,不能把不可变引用 &T 转化成可变引用 &mut T,这样违反前面的借用规则。再重复一遍,一旦有了可变借用,就不能再有其他的借用了,即使是不可变的借用。
智能指针
使用原生指针非常不安全,需要小心翼翼才能避免很多细节问题,不然就可能出现内存泄漏、空悬指针、双重释放等问题。为了减少这种问题,可以使用由 C++ 推广的智能指针。
Rust 有很多种智能指针,之所以说他们智能,因为他们包含有元数据和代码。这些元数据和代码在创建和销毁的时候被执行。可以自动释放底层资源是使用智能指针的主要原因之一。智能指针的大部分“智能”来演于 Drop trait 和 Deref trait。
Drop
Drop 方法类似 C++ 中析构函数。对象超出作用域自动调用该函数来清理资源:
struct Character {
name: String,
}
impl Drop for Character {
fn drop(&mut self) {
println!("{} went away", self.name)
}
}
fn main()
{
let _steve = Character {
name: "Steve".into(),
};
let _john = Character {
name: "John".into(),
};
}
Deref 和 DerefMut
为了提供类和普通指针指针相似的行为,也就是能够进行解引用。智能指针类型通常实现了 Deref trait,这样就可以使用 * 进行解引用操作。
pub trait Deref {
type Target: ?Sized;
fn deref(&self) -> &Self::Target;
}
Deref 只有一个方法,返回一个不可变引用。
智能指针的类型
标准库提供了下列的一些智能指针:
Box:提供了最简单的队分配。Box类型拥有它内部的值。因此可以用它来持有结构体的值或者从函数中返回它;Rc:使用引用计数的指针指针。每当获取它的引用的时候,会自动增加计数。每当释放引用,就会减少计数值。一旦计数值为0,就自动清理资源。Arc:同样也是引用计数,只不过用原子引用计数来保证多线程安全。Cell:提供了内部可变性,对外提供类似get/set的组合来修改内部的值,不过限制了类型必须实现Copytrait。因为通过get/set进行控制,那么它允许获得多个可变引用。RefCell:同样也是提供了内部可变性,但它没有Copytrait 但限制。它使用运行锁(会带来一定的开销)来提供安全。
Box
Box 提供来一种最简单的在堆上分配内存。如果熟悉 Java,可以理解 Box 类似 Java 中的装箱,Box 包装整数,可以理解为 Integer。Box 类型的所有权语义取决于所包装类型,如果基础类型为 Copy 语义,则 Box 是 Copy,否则就是默认移动。
fn box_ref<T>(b: T) -> Box<T> {
let a = b;
Box::new(a)
}
struct Foo;
fn main() {
let boxed_one = Box::new(Foo);
let unboxed_one = *boxed_one;
box_ref(unboxed_one);
}
Box 类型可以用在需要创建递归类型中,比如链表结点,如果直接使用 Option 定义结点,是会出现递归问题的:
struct Node {
data: u32,
next: Option<Node>
}
fn main() {
let a = Node { data: 33, next: None};
}
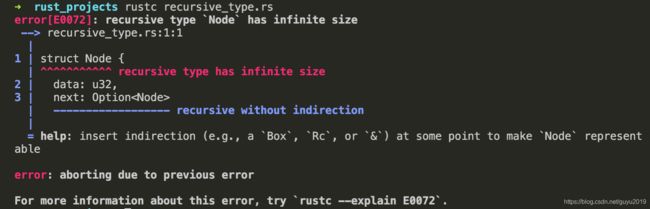
因为这样会不断地展开,直到超出堆栈内存。因此应该改成指针,因为 Node 结点大小已经知道了(指针的大小也是固定的):
struct Node {
data: u32,
next: Option<Box<Node>>
}
引用计数的智能指针
Box 主要针对单一所有权的,意味着不分享。每次分享,都只是复制一份新的。引用计数则会维护一个计数器,从而获得目前使用这个对象的情况。如果没有其他对象在使用了,计数器会减到0,从而自动释放。
Rc
Rc 最常用的是两个方法:
Rc::new:增加新的引用计数容器;clone:增加强引用计数并且获取Rc;
Rc 增加的引用可以是强引用或者弱引用,后者并不会增加计数。使用 clone() 增加的是强引用,而使用 downgrade 则增加弱引用计数。弱引用典型的实现是在观察者模式中,而在双向链表中,也需要使用弱引用计数避免循环计数从而造成内存泄漏。
下面是基于 Rc 实现的单链表结构:
use std::rc::Rc;
#[derive(Debug)]
struct LinkedList<T> {
head: Option<Rc<Node<T>>>
}
#[derive(Debug)]
struct Node<T> {
next: Option<Rc<Node<T>>>,
data: T
}
impl<T> LinkedList<T> {
fn new() -> Self {
LinkedList { head: None }
}
fn append(&self, data: T) -> Self {
LinkedList {
head: Some(Rc::new(Node {
data: data,
next: self.head.clone()
}))
}
}
}
fn main() {
let list_of_nums = LinkedList::new().append(1).append(2);
println!("nums: {:?}", list_of_nums);
let list_of_strs = LinkedList::new().append("foo").append("bar");
println!("strs: {:?}", list_of_strs);
}

单链表的指针单向向后,强引用计数没有什么问题。但如果要实现双向链表,是不能直接再反过来强引用的。这样的话就有一种类似死锁的引用循环。这个时候就应该使用 Weak:
use std::rc::Rc;
use std::rc::Weak;
#[derive(Debug)]
struct LinkedList<T> {
head: Option<Rc<LinkedListNode<T>>>
}
#[derive(Debug)]
struct LinkedListNode<T> {
next: Option<Rc<LinkedListNode<T>>>,
prev: Option<Weak<LinkedListNode<T>>>,
data: T
}
impl<T> LinkedList<T> {
fn new() -> Self {
LinkedList { head: None }
}
fn append(&self, data: T) -> Self {
let new_node = Rc::new(LinkedListNode {
data: data,
next: self.head.clone(),
prev: None
});
match self.head.clone() {
Some(node) => {
node.prev = Some(Rc::downgrade(&new_node));
},
None => {
}
}
LinkedList {
head: Some(new_node)
}
}
}
fn main() {
let list_of_nums = LinkedList::new().append(1).append(2).append(3);
println!("nums: {:?}", list_of_nums);
}
编译这段代码会报错:
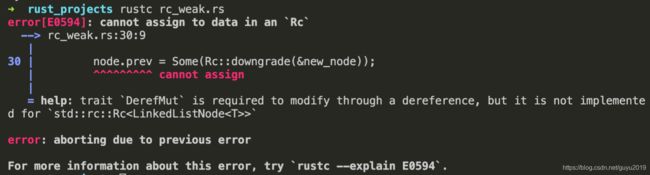
Rust 默认是不可变的,结构体的没有声明 mut,那么这个结构体内的每个字段都是不可变的。这也就是为什么 node.prev 是不能重新进行赋值的原因。为了实现这种赋值,可以使用 RefCell 实现一种内部可变性:
#[derive(Debug)]
struct LinkedListNode<T> {
next: Option<Rc<LinkedListNode<T>>>,
prev: RefCell<Option<Weak<LinkedListNode<T>>>>,
data: T
}
使用 append 创建一个新的 RefCell 和更新前向的引用:
fn append(&self, data: T) -> Self {
let new_node = Rc::new(LinkedListNode {
data: data,
next: self.head.clone(),
prev: RefCell::new(None)
});
match self.head.clone() {
Some(node) => {
let mut prev = node.prev.borrow_mut();
*prev = Some(Rc::downgrade(&new_node));
},
None => {
}
}
LinkedList {
head: Some(new_node)
}
}
这样就有一个比较好的链表实现了。
Cell
在下面代码中,试图有两个可变的引用,但正如上面所说的,只要有了可变引用,就不能再有其他的引用,不可变的引用也不行,因此下面的代码会报错:
use std::cell::Cell;
#[derive(Debug)]
struct Bag {
item: Box<u32>
}
fn main() {
let mut bag = Cell::new(Bag { item: Box::new(1) });
let hand1 = &mut bag;
let hand2 = &mut bag;
*hand1 = Cell::new(Bag { item: Box::new(2) });
*hand2 = Cell::new(Bag { item: Box::new(2) });
}
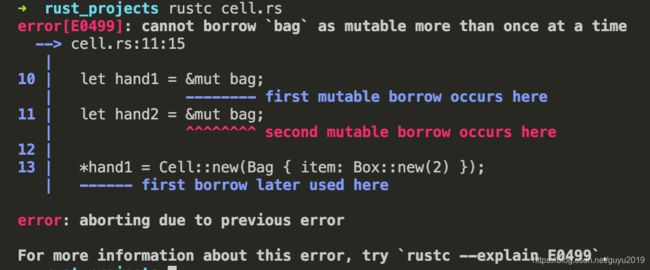
因此,可以使用 Cell 包裹这个类型,从而获得类似多个可变引用效果:
use std::cell::Cell;
#[derive(Debug)]
struct Bag {
item: Box<u32>
}
fn main() {
let bag = Cell::new(Bag { item: Box::new(1) });
let hand1 = &bag;
let hand2 = &bag;
hand1.set(Bag { item: Box::new(2) });
hand2.set(Bag { item: Box::new(3) });
}
Cell::new:创建新的实例;get:必须实现Copytrait;set:允许修改内部值,即便之前是不可变引用;
RefCell
如果需要非 Copy 的 Cell,就需要使用 RefCell。它会把借用检查从编译器变成运行时,但不是零成本。RefCell 提供对该值的引用,而不是 Cell 类型按那些值(副本)返回:
use std::cell::RefCell;
#[derive(Debug)]
struct Bag {
item: Box<u32>
}
fn main() {
let bag = RefCell::new(Bag { item: Box::new(1) });
let hand1 = &bag;
let hand2 = &bag;
*hand1.borrow_mut() = Bag { item: Box::new(2) };
*hand2.borrow_mut() = Bag { item: Box::new(3) };
let borrowed = hand1.borrow();
println!("{:?}", borrowed);
}
内部可变性
Cell 和 RefCell 提供了一种表面不可变的特点。将 struct 或 enum 要么是可变的要么是不可变的,而它的可变性会影响到它的所有字段。Cell 和 RefCell 提供了一个表面不可变,而内部可变的包裹。
use std::cell::Cell;
struct Point {
x: u8,
y: u8,
cached_sum: Cell<Option<u8>>
}
impl Point {
fn sum(&self) -> u8 {
match self.cached_sum.get() {
Some(sum) => {
println!("Got from cache: {}", sum);
sum
},
None => {
let new_sum = self.x + self.y;
self.cached_sum.set(Some(new_sum));
println!("Set cache: {}", new_sum);
new_sum
}
}
}
}
fn main() {
let p = Point { x: 8, y: 9, cached_sum: Cell::new(None) };
println!("Summed result: {}", p.sum());
println!("Summed result: {}", p.sum());
}
小结
Rust 采用了一种低层次的系统编程方法进行内存管理,可以达到 C/C++ 的性能,不需要垃圾回收器。相对而言,这块掌握的难度会比较大,但是掌握之后,对于编写更加安全的 C++ 代码也是大有裨益的。