k8s 启动和删除pod
k8s创建pod
pod的启动流程
流程图
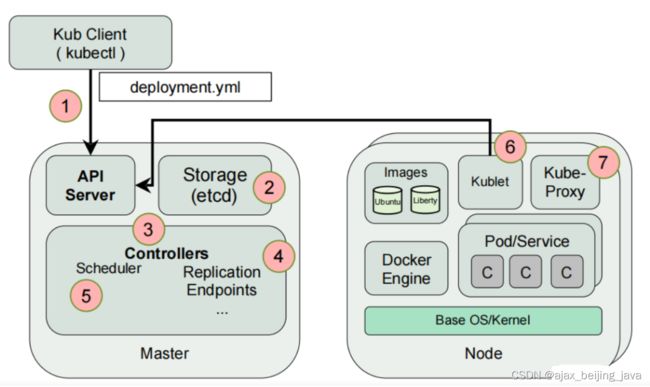
运维人员向kube-apiserver发出指令(我想干什么,我期望事情是什么状态)
api响应命令,通过一系列认证授权,把pod数据存储到etcd,创建deployment资源并初始化。(期望状态)
controller通过list-watch机制,监听api server读取etcd,发现新的deployment,将该资源加入到内部工作队列,发现该资源没有关联的pod和replicaset,启用deployment controller创建replicaset资源,再启用replicaset controller创建pod。所有controller被创建完成后.将deployment,replicaset,pod资源更新存储到etcd。
scheduler通过list-watch机制,监听api server读取etcd,发现新的pod,经过主机过滤、主机打分规则,将pod绑定(binding)到合适的主机,并将绑定结果存储到etcd。
kubelet每隔 20s(可以自定义)向apiserver获取自身Node上所要运行的pod清单.通过与自己的内部缓存进行比较,用容器运行时软件(docker或containerd)拉取镜像创建pod。
kube-proxy为新创建的pod注册动态DNS到CoreOS。给pod的service添加iptables/ipvs规则,用于服务发现和负载均衡。
controller通过control loop(控制循环)将当前pod状态与用户所期望的状态做对比,如果当前状态与用户期望状态不同,则controller会将pod修改为用户期望状态,实在不行会将此pod删掉,然后重新创建pod。
实践案例:控制器的方式创建nginx的pod
流程图

1.使用kubectl创建nginx的pod
[root@k8s-master ~]# kubectl create deployment k8s-nginx --image=nginx -r 3
相当于docker run去启动容器,背后一样要去拉取镜像
- create deployment,创建部署控制器
- k8s-nginx,命名部署控制器
- –image,指定使用的镜像
- -r 3,建立三个副本,删除后也会自动补充
2.查看部署控制器
[root@k8s-master ~]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
k8s-nginx 3/3 3 3 14m
3.查看副本控制器
[root@k8s-master ~]# kubectl get replicaset
NAME DESIRED CURRENT READY AGE
k8s-nginx-75f95db655 3 3 3 15m
4.查看pod的详细信息
[root@k8s-master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k8s-nginx-75f95db655-24mfb 1/1 Running 0 17m 10.244.140.73 k8s-node-2
k8s-nginx-75f95db655-fl5cc 1/1 Running 0 17m 10.244.109.81 k8s-node-1
k8s-nginx-75f95db655-txf25 1/1 Running 0 17m 10.244.109.80 k8s-node-1
参数的含义
status
- Running,正常运行
- Terminating,正在终止
- Container Created,正在创建容器
pod的命名规则
k8s-nginx-75f95db655-24mfb
- 部署控制器名+副本控制器名+pod名
5.进入pod容器
[root@k8s-master ~]# kubectl exec -it k8s-nginx-75f95db655-24mfb -- bash
root@k8s-nginx-75f95db655-24mfb:/#
- kubectl exec 进入pod容器
- -it 交互式进入容器
- – bash指定解释器
6.删除pod容器
[root@k8s-master ~]# kubectl delete pod k9s-nginx-68df494c64-529qk
- delete,删除指定pod
删除一个pod后,因为副本控制器指定为3,尽管删除一个后,也会自动补充一个pod
7.删除部署控制器
[root@k8s-master ~]# kubectl delete ployment k8s-nginx-75f95db655
删除部署控制器后,就会彻底删除所有的副本控制器以及pod
二、删除pod
在日常的k8s运维过程中,避免不了会对某些pod进行剔除,那么如何才能正确的剔除不需要的pod呢?
首先,需要查出想要删除的pod
# 可通过任意方式进行查询
kubectl get pods -A |grep
kubectl get pods -n
kubectl get pods --all-namespaces |grep
kubectl 删除pod命令
kubectl delete pod
例如:kubectl delete pod nginx-web-460776586-f6nf0 -n yundoc
可是这里你会发现,在进行删除delete pod后,并不会直接删除。该pod会自动重新构建(可以理解为重启、重构),原因是k8s误认为我们要删除的pod异常挂了,会启用容灾机制,导致重新再拉起一个新的pod。
我们想要正常且彻底的删除一个pod,必须要先破坏掉他的容灾机制,即删除deployment机制。
查看deployment信息
#可理解是调度管理pod的
kubectl get deployment --all-namespaces
kubectl get deployment -n kube-system
删除deployment配置
kubectl delete deployment
例如:kubectl delete deployment nginx-web -n yundoc
删除deployment,pod会随之删除。
可通过再次查看pod状态,然后进行删除pod命令即可,通常情况下删除deployment后,再次查询pod发现,pod已经开始自行删除了(这步可酌情处理)。
当然,也可以导出yaml文件,进行修改重启策略,重新启动pod , 我在之前的文章中也提到了。
然后再去删除pod 也是可以的。这个场景使用再测试环境或者生产环境都有可能。