基于Yolov5的摄像头吸烟行为检测系统(pytoch)
目录
1.数据集介绍
1.1数据集划分
1.2 通过voc_label.py生成txt
1.3 小目标定义
2.基于Yolov5的吸烟行为检测性能提升
2.1采用多尺度提升小目标检测精度
2.2 多尺度训练结果分析
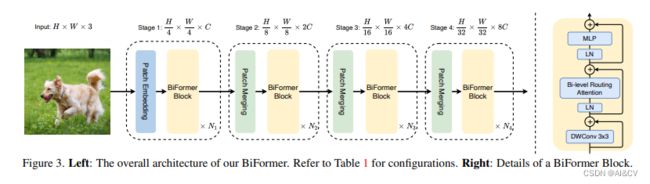
2.3基于多尺度基础上加入BiFormer: 基于动态稀疏注意力构建高效金字塔网络架构
2.3.1 BiFormer原理介绍
2.3.2实验结果分析
1.数据集介绍
通过摄像头采集吸烟行为,共采集1812张图片 进行标注,按照8:1:1进行训练集、验证集、测试集随机区分。
1.1数据集划分
通过split_train_val.py得到trainval.txt、val.txt、test.txt
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.9
train_percent = 0.8
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()1.2 通过voc_label.py生成txt
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val']
classes = ["smoke"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
#difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()通过图像判断属于小目标检测
1.3 小目标定义
1)以物体检测领域的通用数据集COCO物体定义为例,小目标是指小于32×32个像素点(中物体是指32*32-96*96,大物体是指大于96*96);
2)在实际应用场景中,通常更倾向于使用相对于原图的比例来定义:物体标注框的长宽乘积,除以整个图像的长宽乘积,再开根号,如果结果小于3%,就称之为小目标;
2.基于Yolov5的吸烟行为检测性能提升
2.1采用多尺度提升小目标检测精度
涨点技巧:基于Yolov5的微小目标检测,多头检测头提升小目标检测精度_yolov5 小目标检测_AI小怪兽的博客-CSDN博客
原理介绍:为了实现上述微小目标同样可以达到较好的检测效果, YOLOv5模型上通过P2层特征引出了新的检测头. 结构如图2所示. P2层检测头分辨率为160×160像素, 相当于在主干网络中只进行了2次下采样操作, 含有目标更为丰富的底层特征信息. 颈部网络中自上而下和自下而上得到的两个P2层特征与主干网络中的同尺度特征通过concat形式进行特征融合, 输出的特征为3个输入特征的融合结果, 这样使得P2层检测头应对微小目标时, 能够快速有效的检测. P2层检测头加上原始的3个检测头, 可以有效缓解尺度方差所带来的负面影响. 增加的检测头是针对底层特征的, 是通过低水平、高分辨率的特征图生成的, 该检测头对微小目标更加敏感. 尽管添加这个检测头增加了模型的计算量和内存开销, 但是对于微小目标的检测能力有着不小的提升。
2.2 多尺度训练结果分析
confusion_matrix.png :列代表预测的类别,行代表实际的类别。其对角线上的值表示预测正确的数量比例,非对角线元素则是预测错误的部分。混淆矩阵的对角线值越高越好,这表明许多预测是正确的。
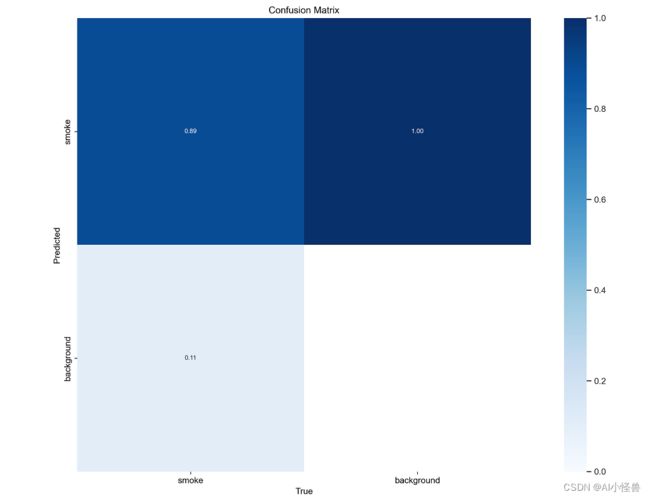
上图是吸烟检测检测训练,有图可以看出 ,分别是破损和background FP。该图在每列上进行归一化处理。则可以看出破损检测预测正确的概率为89%。
F1_curve.png:F1分数与置信度(x轴)之间的关系。F1分数是分类的一个衡量标准,是精确率和召回率的调和平均函数,介于0,1之间。越大越好。
TP:真实为真,预测为真;
FN:真实为真,预测为假;
FP:真实为假,预测为真;
TN:真实为假,预测为假;
精确率(precision)=TP/(TP+FP)
召回率(Recall)=TP/(TP+FN)
F1=2*(精确率*召回率)/(精确率+召回率)
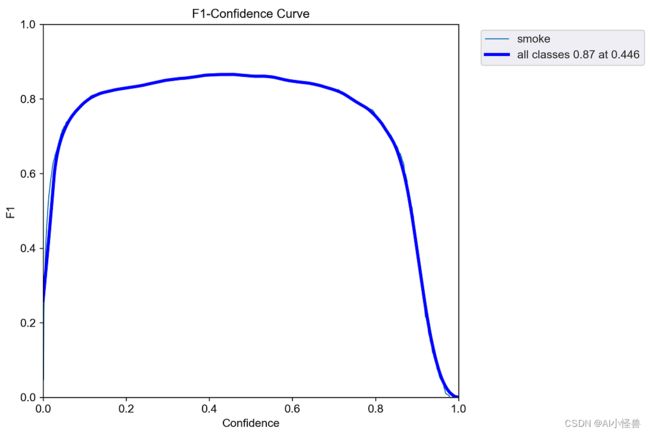
labels_correlogram.jpg :显示数据的每个轴与其他轴之间的对比。图像中的标签位于 xywh 空间。
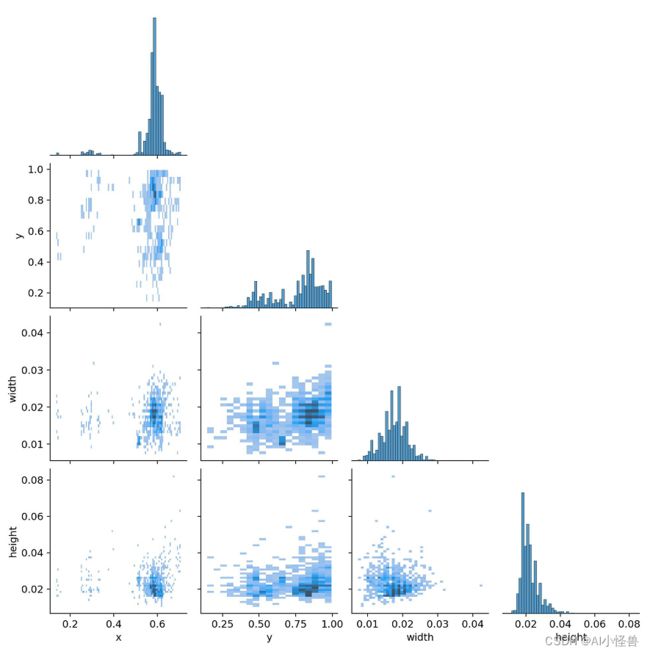
labels.jpg :
(1,1)表示每个类别的数据量
(1,2)真实标注的 bounding_box
(2,1) 真实标注的中心点坐标
(2,2)真实标注的矩阵宽高
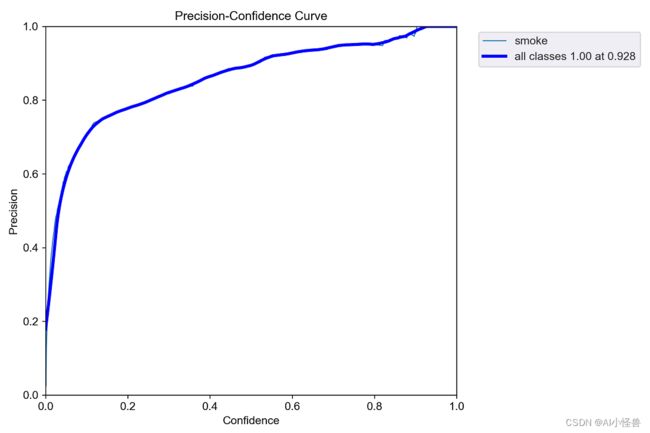
P_curve.png:表示准确率与置信度的关系图线,横坐标置信度。由下图可以看出置信度越高,准确率越高。
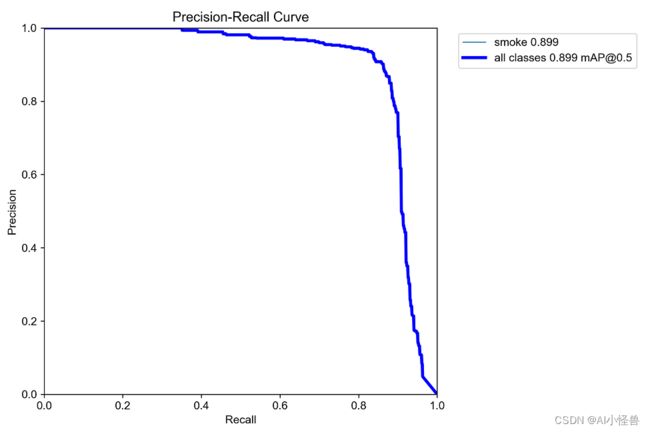
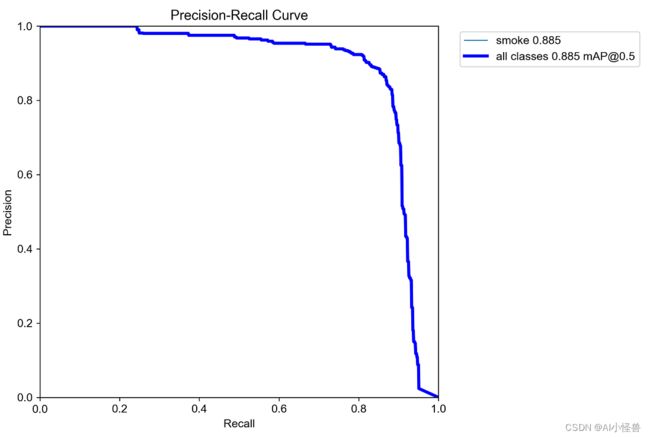
PR_curve.png :PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系。
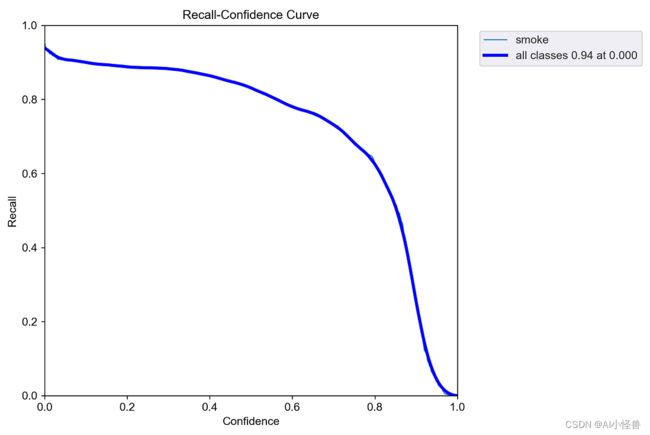
R_curve.png :召回率与置信度之间关系
results.png
mAP_0.5:0.95表示从0.5到0.95以0.05的步长上的平均mAP.
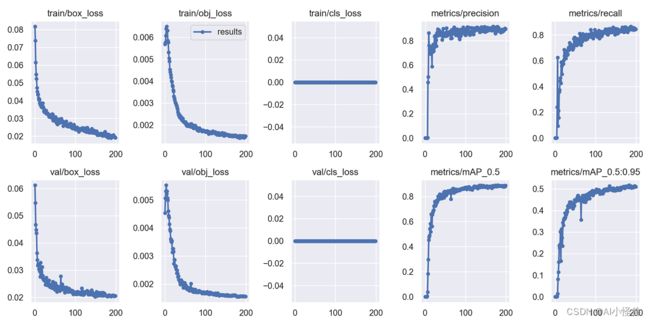
预测结果:
2.3基于多尺度基础上加入BiFormer: 基于动态稀疏注意力构建高效金字塔网络架构
Yolov5/Yolov7 引入CVPR 2023 BiFormer: 基于动态稀疏注意力构建高效金字塔网络架构,对小目标涨点明显_AI小怪兽的博客-CSDN博客
2.3.1 BiFormer原理介绍

论文:https://arxiv.org/pdf/2303.08810.pdf
背景:注意力机制是Vision Transformer的核心构建模块之一,可以捕捉长程依赖关系。然而,由于需要计算所有空间位置之间的成对令牌交互,这种强大的功能会带来巨大的计算负担和内存开销。为了减轻这个问题,一系列工作尝试通过引入手工制作和内容无关的稀疏性到关注力中来解决这个问题,如限制关注操作在局部窗口、轴向条纹或扩张窗口内。
本文方法:本文提出一种动态稀疏注意力的双层路由方法。对于一个查询,首先在粗略的区域级别上过滤掉不相关的键值对,然后在剩余候选区域(即路由区域)的并集中应用细粒度的令牌对令牌关注力。所提出的双层路由注意力具有简单而有效的实现方式,利用稀疏性来节省计算和内存,只涉及GPU友好的密集矩阵乘法。在此基础上构建了一种新的通用Vision Transformer,称为BiFormer。

其中图(a)是原始的注意力实现,其直接在全局范围内操作,导致高计算复杂性和大量内存占用;而对于图(b)-(d),这些方法通过引入具有不同手工模式的稀疏注意力来减轻复杂性,例如局部窗口、轴向条纹和扩张窗口等;而图(e)则是基于可变形注意力通过不规则网格来实现图像自适应稀疏性;作者认为以上这些方法大都是通过将 手工制作 和 与内容无关 的稀疏性引入到注意力机制来试图缓解这个问题。因此,本文通过双层路由(bi-level routing)提出了一种新颖的动态稀疏注意力(dynamic sparse attention ),以实现更灵活的计算分配和内容感知,使其具备动态的查询感知稀疏性,如图(f)所示。
2.3.2实验结果分析
map进一步提升至0.899