Hive SQL 优化大全(参数配置、语法优化)
文章目录
-
- 参数配置优化
-
- yarn-site.xml 配置文件优化
- mapred-site.xml 配置文件优化
- 分组聚合优化 —— Map-Side
-
- 优化参数解析
- 优化案例
- Join 优化
-
- Map Join
服务器环境说明
| 机器名称 | 内网IP | 内存 | CPU | 承载服务 |
|---|---|---|---|---|
| master | 192.168.10.10 | 8 | 4 | NodeManager、DataNode、NameNode、JobHistoryServer、Hive、HiveServer2、MySQL |
| slave1 | 192.168.10.11 | 8 | 4 | NodeManager、DataNode、ResourceManager |
| slave2 | 192.168.10.12 | 8 | 4 | NodeManager、DataNode、SecondaryNameNode |
操作系统均为:CentOS 7.5
组件版本
jdk 1.8mysql 5.7hadoop 3.1.3hive 3.1.2
参数配置优化
下面以我的集群配置为例来进行优化,请按说明根据实际需求、节点情况进行灵活调整。
yarn-site.xml 配置文件优化
参数一
该参数指定了 NodeManager 可以分配给该节点上的 YARN 容器的最大内存量(以 MB 为单位),默认 8G。
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>6144value>
property>
我的每台服务器内存为 8 G,这里给 NodeManager 分配 6 G 内存,我们必须考虑给系统以及其它服务预留内存。
注意,该参数不能超过单台服务器的总内存。
参数二
该参数指定了 NodeManager 在 YARN 集群中的每个节点上可以分配给容器的虚拟 CPU 核心数量,默认值为: 8 。
增加它可以提高容器的并行性和性能,但也可能导致 CPU 资源过度分配。减小它可能会限制容器的性能,但可以确保更多的容器在集群上同时运行。
<property>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>6value>
property>
我的每台服务器物理 CPU 核数为 4 ,这里虚拟为 6 核,提高并发度。
参数三
该参数定义了 YARN 调度器允许的单个容器的最大内存分配。
这有助于确保在集群中合理分配内存资源,以防止某个应用程序或容器占用过多的内存,导致性能问题或资源争用。
该参数配置一般为 yarn.nodemanager.resource.memory-mb 的四分之一,结果最好能被 1024 整除。
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>2048value>
property>
上面设置 yarn.nodemanager.resource.memory-mb 的配置是 6G,6144 / 4 = 1536,显然 1536 无法被 1024 整除,所以这里直接设置为 2G,向上取整。
参数四
该参数定义了 YARN 调度器允许的单个容器的最小内存分配,默认为 1G。
<property>
<name>yarn.scheduler.minimum-allocation-mbname>
<value>512value>
property>
这里直接调为 512MB 就行了,如果内存很多,可以往上调。
参数五
分配给单个容器的最小与最大虚拟核心数量。
<property>
<name>yarn.scheduler.minimum-allocation-vcoresname>
<value>1value>
property>
<property>
<name>yarn.scheduler.maximum-allocation-vcoresname>
<value>2value>
property>
根据单节点虚拟总核心数来进行配置,最小设为 1 个,最大设置为虚拟总核心的四分之一,上面设置虚拟核心为 6 个,这里向上取整,所以最大设置为 2 个。
扩展配置1
设置 NodeManager 是否启用虚拟内存检查,默认值:true(启用虚拟内存检查)。
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>
当设置为 true 时(默认值),NodeManager 将启用虚拟内存检查。这意味着 YARN 应用程序的每个容器将受到虚拟内存限制的限制,一旦超过就会直接 kill 掉该容器。
当设置为 false 时,NodeManager 将禁用虚拟内存检查。这意味着容器将不会受到虚拟内存的限制,容器可以使用尽其所能的虚拟内存,但这可能会增加系统的风险,因为应用程序可以在不受约束的情况下使用虚拟内存,可能导致系统不稳定。
根据当前集群环境用途自行决断吧,学习阶段尽量设置为 false,不然可能会导致很多任务都跑不了,直接被 kill 掉。
扩展配置2
用于设置虚拟内存与物理内存之间的比率,默认为 2.1 倍。
这个参数的目的是限制应用程序可以使用的虚拟内存量,以避免某个应用程序无限制地占用虚拟内存资源,导致其他任务和应用程序受影响。
<property>
<name>yarn.nodemanager.vmem-pmem-rationame>
<value>2.1value>
property>
扩展配置应用场景
未关闭虚拟内存检查之前,由于虚拟内存不足,在运行任务时,你可能会看到如下所示的 Hive SQL 报错信息:
Execution Error,return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
在历史服务器中,查看详细报错信息如下:

[2023-09-01 20:39:05.542]Container [pid=64762,containerID=container_1693562800213_0002_01_000006] is running 324684288B beyond the ‘VIRTUAL’ memory limit. Current usage: 237.6 MB of 1 GB physical memory used; 2.4 GB of 2.1 GB virtual memory used. Killing container.
提示,虚拟内存超出限制,当前容器正在使用 1G 物理内存中的 237.6MB 内存,正在使用 2.1G 虚拟内存中的 2.4G 虚拟内存,显然这超出了限制,那么为什么会出现这种情况呢?
这是因为我只给单个 Map 和 Reduce 任务分配了 1G 内存,所以这 1G 内存按照默认物理内存与虚拟内存转化率(yarn.nodemanager.vmem-pmem-ratio)来算,1024 * 2.1 = 2150.4,所以对应着虚拟内存最大为 2.1G,但是由于这个任务需要 2.4G 虚拟内存才可以运行,所以导致容器被直接 kill 掉。
这里不建议直接将虚拟内存比率调大,可以直接关闭虚拟内存检查来进行解决(实战别关,实战内存一般都很大,关了反而会影响系统稳定性)。
mapred-site.xml 配置文件优化
参数一
定义了单个 Map 与 Reduce 任务使用的最大内存分配量,以 MB 为单位,默认值都为 1024。
注意,这两项参数都不可以超过单个容器的最大内存分配量(yarn.scheduler.maximum-allocation-mb),避免单个 Mapper 或者 Reduce 任务使用超过 YARN 调度器允许的最大内存,导致任务运行异常。
<property>
<name>mapreduce.map.memory.mbname>
<value>1024value>
property>
<property>
<name>mapreduce.reduce.memory.mbname>
<value>1024value>
property>
前面我们设置单个容器的最大内存分配量为 2G,所以这里设置为默认值 1G 更合理,如果有条件,设置为 2G 更好。
其实,实际比例应该设置为 8:1(【单个容器最大内存分配量】 : 【单个 Map 与 Reduce 任务使用的最大内存分配量】)。但是说回来,没有绝对的比例,设置为 2G 也够用了,根据实际情况来吧。
参数二
定义了单个 Map 与 Reduce 任务使用的最大虚拟核心数,默认值都为 1。
注意,这两项参数都不可以超过单个容器的最大虚拟核心数(yarn.scheduler.maximum-allocation-vcores),避免单个 Mapper 或者 Reduce 任务使用超过 YARN 调度器允许的最大虚拟核心数,导致任务运行异常。
<property>
<name>mapreduce.map.cpu.vcoresname>
<value>1value>
property>
<property>
<name>mapreduce.reduce.cpu.vcoresname>
<value>1value>
property>
前面我们设置单个容器的最大虚拟核心数为 2,所以这里设置为默认值 1 更合理,根据实际条件向上调吧。
分组聚合优化 —— Map-Side
在 Hadoop MapReduce 中,Map-Side 聚合是一种优化技术,用于在 Map 任务阶段进行部分数据聚合,以减少数据传输到 Reducer 任务的量。
Map-Side 聚合是一种有效的性能优化技术,可以减少 MapReduce 作业中的数据传输和磁盘写入/读取,从而提高作业的执行速度。
优化参数解析
以下是在 Hive 中设置 Map-Side 聚合相关的关键参数,以及它们的详细解释:
1. hive.map.aggr
-
默认值:
true -
用于启用 Map-Side 聚合功能,默认开启。Hive 会尝试在 Map 任务中执行一些简单的聚合操作,例如 SUM、COUNT 等,以减少 Map 输出的数据量。这可以降低作业的整体负载,提高查询性能,特别是对于一些聚合型的查询。
这可能会降低 Reducer 的负载,但同时会增加 Map 任务的计算负担。如果查询需要更复杂的聚合操作或跨多个分组键的聚合,可能无法完全受益于 Map-Side 聚合。
2. hive.map.aggr.hash.min.reduction
-
默认值:
0.5 -
这个参数的值是一个浮点数,表示 Map-Side 聚合的最小减少量的阈值。阈值的范围是
0到1之间,0表示不启用 Map-Side 聚合,1表示始终启用 Map-Side 聚合。
如果设置为 0.5,表示只有当 Map 任务中的聚合操作可以减少至少 50% 的数据量时,才会启用 Map-Side 聚合。
如果设置为 1,表示无论聚合操作能否减少数据量,都始终启用 Map-Side 聚合。
如果设置为 0,表示禁用 Map-Side 聚合,不管聚合操作是否有助于减少数据传输到 Reducer 的数量。
要注意的是,过大的阈值可能导致 Map-Side 聚合不经常发生,从而减少其性能优势。过小的阈值可能导致频繁的 Map-Side 聚合,增加了 Map 任务的计算开销。因此,合适的阈值应该基于具体查询和数据集的特点进行调整和测试。
3. hive.groupby.mapaggr.checkinterval
-
默认值:
100000 -
控制 Map-Side 聚合的检查条数,用于验证任务是否满足聚合条件。
通俗来说就是,在开启 Map-Side 聚合操作后,当我们执行了聚合操作,在 Map 阶段系统会自动取前 100000 条数据取进行判断,此时,会出现下面两种情况:
-
如果其中的聚合键值大部分都一样,那么就会执行 Map-Side 聚合操作。
-
如果大部分聚合键值都不一样,那么就不会进行 Map-Side 聚合操作。
这个判断很容易会受到数据的分布影响,假设前 100000 行数据前面都不一样,只是因为数据量大,但其实后面有很多聚合键值都一样的数据,所以这就会造成判断不符合 Map-Side 聚合操作。
这种情况我们就需要根据实际情况进行判断了,如果聚合后数据量确实少了一半,我们可以强制开启 Map-Side 聚合操作。
4. hive.map.aggr.hash.force.flush.memory.threshold
-
默认值:
0.9 -
用于控制 Map-Side 聚合的内存阈值,指定 Map 任务在进行 Map-Side 聚合时,何时强制将内存中的数据写入磁盘以释放内存。
当 Map 任务的内存中数据占用达到或超过这个阈值时,Map 任务将强制将内存中的数据写入磁盘以释放内存,从而避免 OOM(内存溢出)错误。
优化案例
未开启 Map-Side 聚合执行
set hive.map.aggr = false;
执行如下 Hive SQL,数据量大约 1000w 行:
select
product_id,
count(1)
from order_detail
group by product_id;
执行计划:
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
""
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: order_detail
Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: product_id (type: string)
outputColumnNames: product_id
Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: product_id (type: string)
sort order: +
Map-reduce partition columns: product_id (type: string)
Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE
Execution mode: vectorized
Reduce Operator Tree:
Group By Operator
aggregations: count()
keys: KEY._col0 (type: string)
mode: complete
" outputColumnNames: _col0, _col1"
Statistics: Num rows: 6533388 Data size: 5880049219 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 6533388 Data size: 5880049219 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
""
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
从执行计划中可以看出,这段代码在 Map 阶段并没有进行聚合操作,在进行 Reduce 操作前,数据量并未发生任何变化。
执行结果,运行 43 秒:
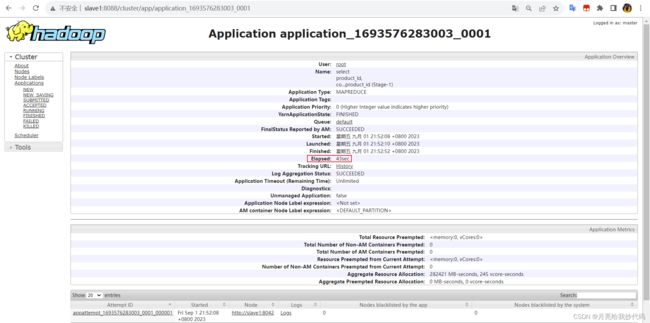
开启 Map-Side 聚合执行
set hive.map.aggr = true;
# 其余参数都保持默认
执行同上 Hive SQL:
select
product_id,
count(1)
from order_detail
group by product_id;
执行计划:
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
""
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: order_detail
Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: product_id (type: string)
outputColumnNames: product_id
Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE
Group By Operator
aggregations: count()
keys: product_id (type: string)
mode: hash
" outputColumnNames: _col0, _col1"
Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: _col0 (type: string)
sort order: +
Map-reduce partition columns: _col0 (type: string)
Statistics: Num rows: 13066777 Data size: 11760099340 Basic stats: COMPLETE Column stats: NONE
value expressions: _col1 (type: bigint)
Execution mode: vectorized
Reduce Operator Tree:
Group By Operator
aggregations: count(VALUE._col0)
keys: KEY._col0 (type: string)
mode: mergepartial
" outputColumnNames: _col0, _col1"
Statistics: Num rows: 6533388 Data size: 5880049219 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 6533388 Data size: 5880049219 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
""
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
从执行计划中可以看到,我们虽然已经开启了 Map-Side 聚合操作,在 Mape 阶段出现了 Group By 聚合操作,可是我们进入 Reduce 阶段前的数据量并没有变少,和之前一样。
这是因为在上面提到的数据分布影响造成的问题,因为 hive.groupby.mapaggr.checkinterval 默认只检查前 100000 行来验证是否进行 Map-Side 聚合操作,由于这里数据量比较大,导致前 100000 行的聚合键值大部分不相同(它觉得即使对这 100000 行数据进行了聚合操作,也达不到数据量减少 50% 的程度),所以它才没有进行 Map-Side 聚合操作,在这种情况下,需要强制开启 Map-Side 聚合操作。
set hive.map.aggr.hash.min.reduction = 1;
执行结果,运行 29 秒:

可见,速度的确得到大幅提升!
从历史服务器中查看执行该任务的一个 Map 中可以看出,在 Map 阶段的确发生了 Map-Side 聚合操作。
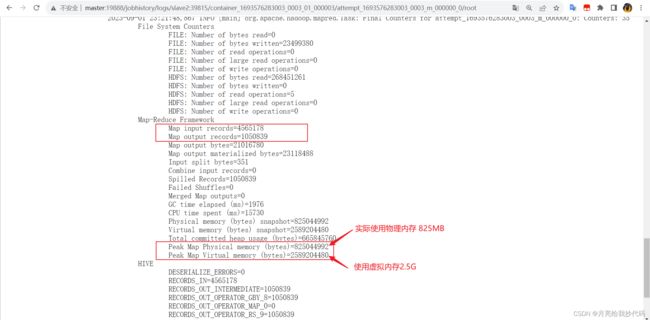
Map 阶段数据量前后对比少了很多,这就是 Map-Side 的玩法。
Join 优化
Map Join
Map Join 是 Hive 中的一种特殊类型的 Join,它用于处理大型维度表与较小事实表之间的连接操作,以提高查询性能。Map Join 利用了 Hive 中的 Map-Side Join 机制,将维度表加载到内存中,并在 Map 阶段执行连接操作,从而减少了数据的传输和磁盘读取,提高了查询性能。
相关参数
-
hive.auto.convert.join,默认值为true,以允许 Hive 自动将适合 Map Join 的连接转换为 Map Join。 -
hive.mapjoin.smalltable.filesize,默认值为25000000(以字节为单位,差不多25MB),用于指定哪些表被视为小表的文件大小阈值,如果表的大小低于此阈值,它将被认为是小表,可以用于 Map Join。 -
hive.mapjoin.bucket.cache.size,默认值为100(表示桶缓存中最多可以存储 100 个桶表),用于配置 Map Join 时的桶缓存大小,桶缓存用于缓存桶表以提高连接性能。 -
hive.auto.convert.join.noconditionaltask,默认值为true,在无条件限制的情况下,允许将 Join 转换为 Map Join。【当连接操作包含条件限制时,Hive 不会自动将其优化为 Map Join 或 Sort Merge Join。它会按照连接操作中指定的条件来执行连接,确保满足条件的行被正确连接,例如 Where 子句等】 -
hive.auto.convert.join.noconditionaltask.size,默认值为10000000(以字节为单位,差不多10MB),设置在没有条件限制的情况下自动将连接操作转换为 Map Join 或 Sort Merge Join 的大小阈值。这个参数的作用是定义了一个阈值,当连接操作中的中间表(即中间结果临时表)大小低于该阈值时,Hive 将自动尝试将连接操作转换为 Map Join 或 Sort Merge Join,以提高性能。
工作原理
-
Map Join 需要一个小的维度表(通常是维度表)和一个较大的事实表。
-
在执行查询之前,Hive 会将维度表加载到 Map 任务的内存中。
-
当执行 Join 操作时,Map 任务会将事实表的每一行与内存中的维度表进行连接。由于维度表已加载到内存中,连接操作非常快速。
-
Map 任务将连接后的结果发送给 Reducer 进行进一步的处理(如果需要的话)。
示例
假设有一个销售数据的事实表 sales 和一个产品维度表 products,我们想要获取每个销售记录的产品名称。products 表是较小的,可以加载到内存中。
-- 创建产品维度表
CREATE TABLE products (
product_id INT,
product_name STRING
);
-- 创建销售事实表
CREATE TABLE sales (
sale_id INT,
product_id INT,
sale_amount DOUBLE
);
-- 使用 Map Join 进行查询
SELECT
s.sale_id, p.product_name, s.sale_amount
FROM
sales s
JOIN
products p
ON
s.product_id = p.product_id;
Map Join 在处理小型维度表与大型事实表的连接时非常有用,但并不适用于所有情况。对于两个大型表之间的连接,Map Join 可能不是最佳选择,因为它可能导致内存不足的问题。因此,在使用 Map Join 时,应根据表的大小和系统资源来评估是否适合。