python后端面试被问到的一些问题
一、python相关的问题
1、问:python2和python3有什么差异?
编码:
Python2 的默认编码是 asscii,这也是导致 Python2 中经常遇到编码问题的原因之一,至于是为什么会使用 asscii 作为默认编码,原因在于 Python这门语言诞生的时候还没出现 Unicode。Python 3 默认采用了 UTF-8 作为默认编码,因此你不再需要在文件顶部写 # coding=utf-8 了。
print:
在进行程序调试时用得最多的语句可能就是 print,在 Python 2 中,print 是一条语句,而 Python3 中作为函数存在。
字符串:
字符串是最大的变化之一,这个变化使得编码问题降到了最低可能。在 Python2 中,字符串有两个类型,一个是 unicode,一个是 str,前者表示文本字符串,后者表示字节序列,不过两者并没有明显的界限,开发者也感觉很混乱,不明白编码错误的原因,不过在 Python3 中两者做了严格区分,分别用 str 表示字符串,byte 表示字节序列,任何需要写入文本或者网络传输的数据都只接收字节序列,这就从源头上阻止了编码错误的问题。
True和False:
True 和 False 在 Python2 中是两个全局变量(名字),在数值上分别对应 1 和 0
Python3 修正了这个缺陷,True 和 False 变为两个关键字,永远指向两个固定的对象,不允许再被重新赋值。
迭代器:
在 Python2 中很多返回列表对象的内置函数和方法在 Python 3 都改成了返回类似于迭代器的对象,因为迭代器的惰性加载特性使得操作大数据更有效率。Python2 中的 range 和 xrange 函数合并成了 range。
nonlocal:
我们都知道在Python2中可以在函数里面可以用关键字 global 声明某个变量为全局变量,但是在嵌套函数中,想要给一个变量声明为非局部变量是没法实现的,在Pyhon3,新增了关键字 nonlcoal,使得非局部变量成为可能。
转载:Python 2 和 Python 3 有哪些主要区别? - 知乎
类:
- 新式类都从object继承,经典类不需要。
- 新式类的MRO(method resolution order 基类搜索顺序)算法采用C3算法广度优先搜索,而旧式类的MRO算法是采用深度优先搜索
- 新式类相同父类只执行一次构造函数,经典类重复执行多次。
其中:
- 截止到python2.1,只存在旧式类。旧式类中,类名和type是无关的:如果x是一个旧式类,那么x.__class__定义了x的类名,但是type(x)总是返回
。这反映了所有的旧式类的实例是通过一个单一的叫做instance的内建类型来实现的,这是它和类不同的地方。 - 新式类是在python2.2为了统一类和实例引入的。一个新式类只能由用户自定义。如果x是一个新式类的实例,那么type(x)和x.__class__是一样的结果(尽管这不能得到保证,因为新式类的实例的__class__方法是允许被用户覆盖的)。
- Python 2.x中默认都是经典类,只有显式继承了object才是新式类
- Python 3.x中默认都是新式类,经典类被移除,不必显式的继承object
继承搜索的顺序:
经典类多继承搜索顺序(深度优先):
新式类多继承搜索顺序(广度优先)
class A():
def __init__(self):
pass
def save(self):
print "This is from A"
class B(A):
def __init__(self):
pass
class C(A):
def __init__(self):
pass
def save(self):
print "This is from C"
class D(B,C):
def __init__(self):
pass
fun = D()
fun.save()
经典类的答案: This is from A
新式类的答案: This is from C
2、问:__new__和__init__的区别
__new__ 负责对象的创建而 __init__ 负责对象的初始化。
__new__:创建对象时调用,会返回当前对象的一个实例
__init__:创建完对象后调用,对当前对象的一些实例初始化,无返回值
1. 在类中,如果__new__和__init__同时存在,会优先调用__new__
class ClsTest(object):
def __init__(self):
print("init")
def __new__(cls,*args, **kwargs):
print("new")
ClsTest()输出:
new2. 如果__new__返回一个对象的实例,会隐式调用__init__
class ClsTest(object):
def __init__(self):
print ("init")
def __new__(cls,*args, **kwargs):
print ("new %s"%cls)
return object.__new__(cls, *args, **kwargs)
ClsTest()输出:
new
init 3. __new__方法会返回所构造的对象,__init__则不会。__init__无返回值。
class ClsTest(object):
def __init__(cls):
cls.x = 2
print ("init")
return cls
ClsTest()输出:
init
Traceback (most recent call last):
File "", line 1, in
TypeError: __init__() should return None, not 'ClsTest' 4. 若__new__没有正确返回当前类cls的实例,那__init__是不会被调用的,即使是父类的实例也不行
class ClsTest1(object):
pass
class ClsTest2(ClsTest1):
def __init__(self):
print ("init")
def __new__(cls,*args, **kwargs):
print ("new %s"%cls)
return object.__new__(ClsTest1, *args, **kwargs)
b=ClsTest2()
print (type(b))输出:
new

转载:Python中__new__和__init__的区别与联系 - 技术颜良 - 博客园
3、问:关于python的时间/空间复杂度(重要)
因为这类问题出场率极高,应该会专门写一篇讲这个的,就想放些这类知识的博客链接
转载:Python(算法)-时间复杂度和空间复杂度 - Sch01aR# - 博客园
转载:Python上的时间复杂度 - 知乎
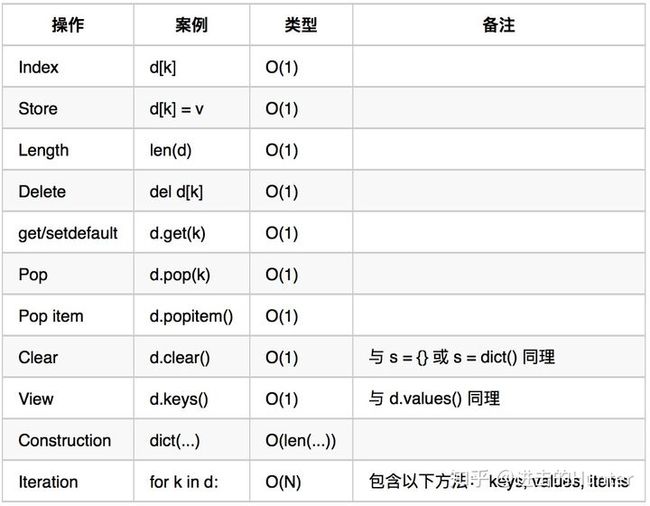
list

set

dict
二、Django相关的问题
1、问:怎么自定义ORM
import pymysql
'''
metaclass,直译为元类,简单的解释就是:
当我们定义了类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例。
但是如果我们想创建出类呢?那就必须根据metaclass创建出类,所以:先定义metaclass,然后创建类。
连接起来就是:先定义metaclass,就可以创建类,最后创建实例。
所以,metaclass允许你创建类或者修改类。换句话说,你可以把类看成是metaclass创建出来的“实例”。
当我们传入关键字参数metaclass时,魔术就生效了,它指示Python解释器在创建Student时,
要通过ModelMetaClass.__new__()来创建,在此,我们可以修改类的定义,比如,加上新的方法,然后,返回修改后的定义。
'''
class Field(object):#定义一个字段类
def __init__(self,name,column_type):
self.name = name#字段名
self.column_type = column_type#字段类型
def __str__(self):
return "<%s:%s>"%(self.name,self.column_type)
class StringField(Field):#字符串类型字段,继承Field
def __init__(self,name):
super(StringField,self).__init__(name,"varchar(100)")
# super(StringField, self).__init__(name,char(20))
class IntegerField(Field):#数字类型字段,继承Field
def __init__(self,name):
super(IntegerField,self).__init__(name,"int")
class ModelMetaClass(type):#定义一个元类
def __new__(cls, name,bases,attrs):
'''
:param name: 类的名称
:param bases: 类的继承
:param attrs: 类的属性
:return:
'''
if name == "Model":#如果传入的name:类名为Model则不进行操作,直接返回type类的相关参数
return type.__new__(cls,name,bases,attrs)
# return super(ModelMetaClass, self).__new__(cls,name,bases,attrs)
print('Found model: %s' % name) # 打印当前实例的类名称
mapping = dict() #空字典
for k,v in attrs.items(): #遍历属性
print('key:%s,value:%s' % (k, v))#打印遍历attrs的key和value
if isinstance(v,Field): #判断属性是否Field的实例
mapping[k] = v #添加到mapping当中
# print(mapping)
for k in mapping.keys(): #返回所有键
attrs.pop(k) #mapping里存在的内容从属性当中删除
attrs["__mapping__"] = mapping #设定__mapping__属性来保存字段
attrs["__table__"] = name #设定类名和表名一致(不区分大小写)
# print(attrs)
return type.__new__(cls,name,bases,attrs)#返回给类实例,这里为Student
class Model(dict,metaclass = ModelMetaClass):#创建一个实例类,设置其元类
def __init__(self,**kwargs):
self.db = pymysql.connect(#链接数据库
host = "localhost",
user = "root",
password = "123",
database = "test"
)
self.cursor = self.db.cursor()
super(Model,self).__init__(**kwargs)
def __getattr__(self, key):
return self[key]#返回对象的属性值
# print(self[key])
def __setattr__(self, key, value):
self[key] = value#设置对象的属性及其对应的值
def save(self):
fields = [] #空列表用来存储字段
args = [] #空列表用来存储字段的值
for k,v in self.__mapping__.items():
fields.append(v.name)#此时,v为field子类的实例,因此可以取出类属性name,作为字段名
# print(getattr(self, k, None))
args.append(getattr(self,k,None))#此时调用了self,则将传入的参数调用,此时再取变量的值,则为传入的实参
sql = "insert into %s(%s) values (%s)"%(
self.__table__,
",".join(fields),
",".join([repr(str(i)) for i in args]
)) #sql拼接
self.cursor.execute(sql)
print(sql)
def __del__(self):
'''
回收内存
'''
self.db.commit()
self.cursor.close()
self.db.close()
class Student(Model):#model实例类的子类
name = StringField("name")
# print(name)
room_id = IntegerField("room_id")
# print(room_id)
u = Student(name = "张3",room_id = 6)#实质是创建了一个字典的对象
u.save()#调用父类的save方法
2、问:你用过什么Django的第三方库
API开发:
- djangorestframework
- django-rest-multiple-models
- django-cors-headers
查询:
- django-filter
- django-haystack
- drf-haystack
后台界面:
- bootstrap_admin
- django-jet
- xadmin
- django-simpleui
- django-suit
- django-grappelli
调试:
- django-debug-toolbar
对象级权限:
- django-guardian
异步:
- celery
富文本编辑器:
- django-ckeditor
- django-tinymce
3、问:Django中的as_view做了什么?
django的类视图拥有自动查找指定方法的功能, 通过调用是通过as_view()方法实现
urls.py
from meduo_mall.demo import views
urlpatterns = [
url(r'register/$', views.Demo.as_view())
]views.py
from django.views.generic import View
class Demo(View):
def get(self, request):
return HttpResponse('get page')
def post(self, request):
return HttpResponse('post page')为什么as_view能自动匹配指定的方法,
先看源码
@classonlymethod
def as_view(cls, **initkwargs): # 实际上是一个闭包 返回 view函数
"""
Main entry point for a request-response process.
"""
for key in initkwargs:
if key in cls.http_method_names:
raise TypeError("You tried to pass in the %s method name as a "
"keyword argument to %s(). Don't do that."
% (key, cls.__name__))
if not hasattr(cls, key):
raise TypeError("%s() received an invalid keyword %r. as_view "
"only accepts arguments that are already "
"attributes of the class." % (cls.__name__, key))
def view(request, *args, **kwargs): # 作用:增加属性, 调用dispatch方法
self = cls(**initkwargs) # 创建一个 cls 的实例对象, cls 是调用这个方法的 类(Demo)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request # 为对象增加 request, args, kwargs 三个属性
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs) # 找到指定的请求方法, 并调用它
view.view_class = cls
view.view_initkwargs = initkwargs
# take name and docstring from class
update_wrapper(view, cls, updated=())
# and possible attributes set by decorators
# like csrf_exempt from dispatch
update_wrapper(view, cls.dispatch, assigned=())
return view
def dispatch(self, request, *args, **kwargs):
# Try to dispatch to the right method; if a method doesn't exist,
if request.method.lower() in self.http_method_names: # 判断请求的方法类视图是否拥有, http_method_names=['get', 'post']
handler = getattr(self, request.method.lower(), self.http_method_not_allowed) # 如果存在 取出该方法
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs) # 执行该方法
极简版
def as_view(): # 校验 + 返回view方法
# 一些校验
...
def view(): # 执行视图
# 增加 为对象request, args, kwargs 属性
...
return dispatch() # 调用指定的请求方法
return view
def dispatch(): # 真正的查找指定的方法, 并调用该方法
...
return handler()调用顺序: as_view --> view --> dispatch
-
可以看出
as_view实际上是一个闭包, 它的作用做一些校验工作, 再返回view方法. -
而
view方法的作用是给请求对象补充三个参数, 并调用dispatch方法处理 -
dispatch方法查找到指定的请求方法, 并执行
可以得出结论: 实际上真正实现查找的方法是 dispatch方法
4、问:http请求包括哪些部分?
http协议报文
1.请求报文
请求行 :具体的请求类别和请求内容
格式: GET / HTTP/1.1
请求类别 请求内容 协议版本
请求类别 : 表示请求的种类
GET 获取网络资源
POST 提交一定的附加信息,得到返回结果
HEAD 获取响应头
PUT 更新服务器资源
DELETE 删除服务器资源
CONNECT
TRACE 用于测试
OPTIONS 获取服务器性能信息
请求头(key value形式) :对请求内容的具体描述信息
User-Agent:产生请求的浏览器类型。
Accept:客户端可识别的内容类型列表。
Host:主机地址
空行
发送回车符和换行符,通知服务器以下不再有请求头
请求体 :请求参数或者是提交内容
post方法中,会把数据以key value形式发送请求
2.响应报文
响应行:反馈响应的情况
格式 : HTTP/1.1 200 OK
协议版本 响应码 附加信息
响应码 : 响应的具体情况
1xx : 提示信息,表示请求成功
2xx : 响应成功
3xx : 响应需要重定向
4xx : 客户端错误
5xx : 服务端错误
常见响应码 : 200 成功
404 请求内容不存在
401 没有访问权限
500 服务器发生未知错误
503 暂时无法执行
响应头:对响应内容的具体描述
空行
响应体:返回给请求端的具体内容
三、Mysql相关的问题
1、问:事务的四种隔离级别?
事务的并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
MySQL事务隔离级别
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
2、问:事务的操作?
- 开启事务: start transaction; begin;
- 回滚:rollback;
- 提交:commit;
例:
CREATE TABLE account (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
balance DOUBLE
);
-- 添加数据
INSERT INTO account (NAME, balance) VALUES ('zhangsan', 1000), ('lisi', 1000)
SELECT * FROM account;
-- 张三给李四转账 500 元
-- 0. 开启事务
START TRANSACTION;
-- 1. 张三账户 -500
UPDATE account SET balance = balance - 500 WHERE NAME = 'zhangsan';
-- 2. 李四账户 +500
-- 出错了...
UPDATE account SET balance = balance + 500 WHERE NAME = 'lisi';
-- 发现执行没有问题,提交事务
COMMIT;
-- 发现出问题了,回滚事务
ROLLBACK;
3、问:讲一下联合索引
两个或更多个列上的索引被称作联合索引,联合索引又叫复合索引。对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 .当最左侧字段是常量引用时,索引就十分有效。
转载:mysql联合索引详解 - 云+社区 - 腾讯云
4、问:讲一下mysql中innoDB的聚簇索引
从物理存储角度 来分, 索引 可以 分为聚簇索引和非聚簇索引 , 区别主要看叶子节点存了什么数据 。
在InnoDB 里,索引 B+Tree 的叶子节点存储了整行数据的是主键索引,也被称之为聚簇索引。聚簇索引是对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的算法。特点是存储数据的顺序和索引顺序一致。一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引 , 因为 数据一旦存储,顺序只能有一种。找到了索引就找到了需要的数据,那么这个索引就是聚簇索引,所以主键就是聚簇索引,修改聚簇索引其实就是修改主键。
索引B+Tree 的叶子节点 只 存储了主键的值 和索引列 的是非主键索引,也被称之为非聚簇索引。一个表可以有多个非聚簇索引 。 非聚簇 索引的存储和数据的存储是分离的,也就是说 可能 找到了索引但没找到数据,需要根据索引上的值(主键)再次回表查询,非聚簇索引也叫做辅助索引。
聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
聚簇索引查询相对会更快一些,因为主键索引树的叶子节点直接就是我们要查询的整行数据了 , 而非主键索引的叶子节点是主键的值,查到主键的值以后,还需要再通过主键的值再进行一次查询(这个过程叫做回表 , 也就是查了2 个索引树)。
主键一定是聚簇索引, 如果开发 人员不手动设置 主键 , 那么MySQL 会 默认 使用 非空的 Unique 索引, 若 没有 非空的 Unique 索引,则会使用数据库内部的一个行的 id 来当作主键索引 , 其它普通索引需要区分SQL 场景,当 SQL 查询的列就是索引本身时,我们称这种场景下该普通索引也可以叫做聚簇索引, MyisAM 引擎没有聚簇索引。
转载:MySQL中的聚簇索引和非聚簇索引_ITPUB博客
B+tree相关知识 转载:BTree和B+Tree详解_御良私塾-CSDN博客_b+tree
四、Linux相关的问题
1、问:如何查看内存占用?
top命令
可以查看CPU、内存利用率,当然这些值都是平均利用率
其中,
PID - 进程标示号
USER - 进程所有者
PR - 进程优先级
NI - 进程优先级别数值
VIRT - 进程占用的虚拟内存值
RES - 进程占用的物理内存值
SHR - 进程使用的共享内存值
S - 进程的状态,其中S表示休眠,R表示正在运行,Z表示僵死
%CPU - 进程占用的CPU使用率
%MEM - 进程占用的物理内存百分比
TIME+ - 进程启动后占用的总的CPU时间
Command - 进程启动的启动命令名称
free命令
查看总内存、使用、空闲等情况
ps命令查看CPU状态
ps(process status)命令用来汇报处理器状态信息,示例用法:
ps ux
ps -H -eo user,pid,ppid,tid,time,%cpu,cmd --sort=%cpu
上述命令:第一条按默认方式查看状态,第二条命令指定显示列和排序方式,使用时任选其一。
2、问:如何查看端口是否被占用?
1. 可以通过"netstat -anp" 来查看哪些端口被打开。
(注:加参数'-n'会将应用程序转为端口显示,即数字格式的地址,如:nfs->2049, ftp->21,因此可以开启两个终端,一一对应一下程序所对应的端口号)
2. 然后可以通过"lsof -i:$PORT"查看应用该端口的程序($PORT指对应的端口号)。或者你也可以查看文件/etc/services,从里面可以找出端口所对应的服务。
(注:有些端口通过netstat查不出来,更可靠的方法是"sudo nmap -sT -O localhost")
3. 若要关闭某个端口,则可以:
1)通过iptables工具将该端口禁掉,如:
"sudo iptables -A INPUT -p tcp --dport $PORT -j DROP"
"sudo iptables -A OUTPUT -p tcp --dport $PORT -j DROP"
2)或者关掉对应的应用程序,则端口就自然关闭了,如:
"kill -9 PID" (PID:进程号)
如: 通过"netstat -anp | grep ssh"
有显示: tcp 0 127.0.0.1:2121 0.0.0.0:* LISTEN 7546/ssh
则: "kill -9 7546"
详细:Linux 查看端口占用情况 | 菜鸟教程