python跑批模拟、深度遍历、echarts时序图
记一次跑批优化
目录
- 工作背景;
- 报表层表依赖关系梳理;
- 调度系统跑批模拟器;
- 理论上的最短耗时;
- echarts输出时序图;
1. 工作背景
因今年的项目需将原有报表工具上的一些报表迁移至新的报表平台,因此涉及到这些报表的取数脚本梳理。厂商在梳理过程中发现一张报表取数时,会涉及到多个中间表,且中间表也是经过层层加工出来,梳理工作进展缓慢。
因此考虑在厂商继续梳理的同时,我这边也研究下如何快速提取表之间的依赖关系。进而在与负责调度系统的同事沟通过程中,发现一些无效的作业依赖关系,并因此想到能否通过删除无效依赖关系,调整作业编号,从而缩短报表跑批耗时。随之便有了接下来的表依赖关系提取、调度跑批模拟器、深度优先遍历、echarts绘制调度时序图等工作。
2. 报表层表依赖关系梳理
基本概念
- 跑批调度系统里有多个跑批任务,本次仅针对报表层任务;
- 每个任务里包含多个作业;
- 每个作业有一个作业编号(命名为“作业类型_编号”,形如XXXX_0012);
- 作业的内容就是通过sh去调用一段perl脚本,脚本里包含sql语句,去执行数据跑批。
表间依赖关系整理
需梳理的目标脚本,为报表层脚本文件夹里的约560个perl脚本。perl文件的文件名即为目标表名,perl文件里的sql语句中的以IALDB、IBLDB、ICLDB、IDLDB、IELDB这五种库实例名开头的表,即为目标表依赖的表名。
存在问题:有些表没有写库实例名称,或者是库实例名称后边有空格的,这部分数量不多,后期手工梳理。 最终输出表间依赖关系2243条。
调度系统作业依赖关系导出
调度系统里的作业信息,以及作业依赖关系直接从数据库里导出。导出的数据进过汇总排序,按被依赖的数量做降序,Top10的截图如下:

其中XXXX_0145号作业被依赖达64条。
无效依赖关系筛查
作业的依赖关系,比如A作业依赖于B作业,即为A的perl脚本依赖于B的perl脚本,即为A表需要用到B表的数据。但根据之前梳理出的表间关系做初筛,并结合以下ssh语句做复核,发现有92条作业依赖关系是无效的。以XXXX_0145为例,实际就1个作业依赖于0145,而非64个。
# ssh下查找包含某表名的pl文件
find 某路径下 -name "*.pl" | xargs grep -i "某tablename "
剔除了无效依赖关系后,按被依赖的数量做降序,Top10的截图如下:

依赖关系可视化呈现
删除无效依赖,可降低跑批任务的维护难度,在neo4j上做关系图可视化如下: 删除无效依赖前:262条关系

删除无效依赖后:170条关系,干净了不少。

3. 调度系统跑批模拟器
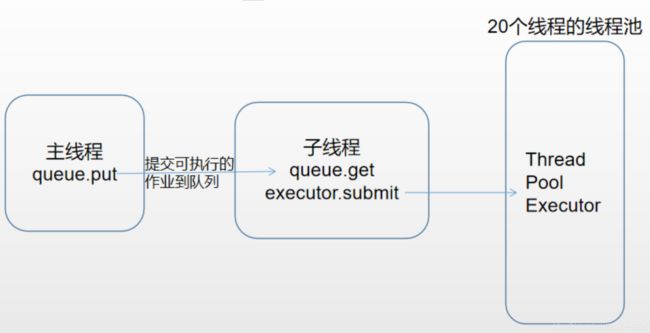
由于剔除了许多条依赖关系,不知该任务的跑批耗时是否有缩短,又不好在生产环境上进行验证,于是考虑在本地搞一个跑批的模拟器。
经与负责跑批调度系统的同事了解,调度系统的跑批规则如下:
- 20个线程同时跑;
- 按照作业编号order by的顺序取作业;
- 若取到的作业有依赖于其他作业,且其他作业尚未完成,则先跳过。
用python实现,设计如下:
代码如下:
# 数仓调度跑批模拟器
# %% import、文件路径
from concurrent.futures import ThreadPoolExecutor
import threading
import time
import datetime
import pandas as pd
import queue
import os
import webbrowser
from mylog import logc, dataf
jobInfo_filepath = u'./jobSrc/jobInfo_new.csv'
depInfo_filepath = u'./jobSrc/depInfo_new.csv'
dicjob = {}
executor = None
# 时间比例,缩小timescale倍
timescale = 100.0
dataf_template = "{{value:[{0},{1},{2},{3},types[{4}].name],itemStyle:{{normal:{{color:types[{5}].color}}}}}},"
# 显示x-range图开关
IS_OPEN_ECHARTS = True
# %%
###############
# timescale=100
###############
# 调试数据:20190908的调度数据---92min
# 原始作业编号,删除无效依赖,用时:
# 2019-09-24 17:21:07,292 - console[line:243] - INFO: used 65.566222s
# 修改24个作业编号后,用时:
# 2019-09-24 18:24:18,931 - console[line:251] - INFO: used 47.367517s
# 调试数据:20190913的调度数据---98m12s
# 原始作业编号,删除无效依赖,用时:
# 2019-09-24 17:23:12,103 - console[line:243] - INFO: used 68.279253s
# 修改24个作业编号后,用时:
# 2019-09-24 18:26:02,326 - console[line:253] - INFO: used 54.73252s
# 调试数据:20190922的调度数据---101m45s
# 原始作业编号,删除无效依赖,用时:
# 2019-09-24 17:24:56,260 - console[line:243] - INFO: used 68.034214s、
# 修改24个作业编号后,用时:
# 2019-09-24 18:27:53,594 - console[line:254] - INFO: used 54.080691s
# 2019-09-24 18:29:38,886 - console[line:255] - INFO: used 54.150868s
###############
# timescale=10
###############
# 调试数据:20190908的调度数据---92min
# 原始作业编号,删除无效依赖,用时:
# 2019-09-24 17:39:05,565 - console[line:235] - INFO: used 654.113571s
# 修改24个作业编号后,用时:
# 调试数据:20190913的调度数据---98m12s
# 原始作业编号,删除无效依赖,用时:
# 2019-09-24 17:51:41,276 - console[line:244] - INFO: used 685.985023s
# 修改24个作业编号后,用时:
# 调试数据:20190922的调度数据---101m45s
# 原始作业编号,删除无效依赖,用时:
# 2019-09-24 18:18:14,520 - console[line:246] - INFO: used 678.700894s
# 修改24个作业编号后,用时:
# %% 定义作业类
class BatJob(object):
def __init__(self, name, time, typeindex):
# 作业名称
self.__name = name
# 作业耗时
self.__time = time
# 作业依赖(list)
self.__deps = []
# 作业状态 S_WAIT,S_RUN,S_FINISH
self.__status = 'S_WAIT'
# 作业类别
# { name: '无父类有子类(起始节点)', color: '#75d874', typeindex:0 },
# { name: '无父类无子类(单节点)', color: '#7b9ce1', typeindex:1 },
# { name: '有父类无子类(末端节点)', color: '#000000', typeindex:2 },
# { name: '有父类有子类(中间节点)', color: '#bd6d6c', typeindex:3 }
self.__typeindex = typeindex
def addDep(self, dep):
self.__deps.append(dep)
def goPut(self):
self.__status = 'S_PUT'
def goRun(self):
self.__status = 'S_RUN'
# 作业完成时,修改状态
def goDone(self):
self.__status = 'S_FINISH'
def __str__(self):
return "\n".join(item for item in (
'【name】' + self.__name,
'【time】' + str(self.__time),
'【status】' + str(self.__status),
'【deps】' + str(self.__deps),
'【typeindex】' + str(self.__typeindex)
))
def getDeps(self):
return self.__deps
def getStatus(self):
return self.__status
def getTime(self):
return self.__time/timescale
def getTypeindex(self):
return self.__typeindex
# %% 导入作业信息、依赖信息
def loadInfo():
jobInfo = pd.read_csv(jobInfo_filepath)
depInfo = pd.read_csv(depInfo_filepath)
dic = {}
jobnameList = []
for i in range(len(jobInfo)):
jobname = jobInfo.jobname[i]
jobtime = 1 if jobInfo.jobtime_s[i] == 0 else jobInfo.jobtime_s[i]
typeindex = jobInfo.typeindex[i]
dic[jobname] = BatJob(jobname, jobtime, typeindex)
jobnameList.append(jobname)
for i in range(len(depInfo)):
jobname = depInfo.jobname[i]
if(jobname in dic):
dic[jobname].addDep(depInfo.depjobname[i])
else:
logc.error('{}不在dic中'.format(jobname))
jobnameList.sort()
return dic, jobnameList
# %% 定时器回调
def jobSleep(args):
jobname = args[0]
thNum = args[1]
qTh = args[2]
starttime = args[3]
times = dicjob[jobname].getTime()
typeindex = dicjob[jobname].getTypeindex()
# 输出作业相关信息以便画甘特图
# 作业名称、开始时间戳-ms、耗时-ms、线程号
# dataf_template = "{{value:[{0},{1},{2},{3},types[{4}].name],itemStyle:{{normal:{{color:types[{5}].color}}}}}},"
if(IS_OPEN_ECHARTS is True):
dataf.info(dataf_template.format(thNum,
round(time.time()*1000) - starttime,
times*1000,
"'"+jobname+"'", typeindex, typeindex))
dicjob[jobname].goRun()
logc.info('{} run {}'.format(thNum, jobname))
time.sleep(times)
dicjob[jobname].goDone()
logc.info('{} finish {}'.format(thNum, jobname))
qTh.put(thNum, block=True)
return
# %%
def threadGetjob(q, qTh, batch_count):
starttime = round(time.time()*1000)
while batch_count > 0:
jobname = q.get(block=True)
thNum = qTh.get(block=True)
global executor
batch_count -= 1
logc.info('submit {} ,剩余作业{}个'.format(jobname, batch_count))
executor.submit(jobSleep, (jobname, thNum, qTh, starttime))
while qTh.full() is False:
pass
return
# %%
def main():
# 同时运行的作业数
batch_max = 20
global executor
executor = ThreadPoolExecutor(max_workers=batch_max)
que = queue.Queue(maxsize=10)
queTh = queue.Queue(maxsize=batch_max)
for i in range(1, batch_max+1):
queTh.put(str(i), block=True)
global dicjob
dicjob, jlist = loadInfo()
batch_count = len(jlist)
tic = datetime.datetime.now()
t = threading.Thread(target=threadGetjob, args=(que, queTh, batch_count))
t.start()
while(batch_count > 0):
for i in range(len(jlist)):
jobname = jlist[i]
if(dicjob[jobname].getStatus() != 'S_WAIT'):
continue
deps = dicjob[jobname].getDeps()
isReady = True
for dep in deps:
if (dicjob[dep].getStatus() != 'S_FINISH'):
isReady = False
break
if(isReady):
que.put(jobname, block=True)
jlist.pop(i)
batch_count -= 1
logc.info('put {} ,剩余作业{}个'.format(jobname, batch_count))
break
t.join()
logc.info('threadGetjon已结束')
executor.shutdown()
toc = datetime.datetime.now()
return toc-tic
# %%
if __name__ == "__main__":
if(IS_OPEN_ECHARTS is True):
dataf.info('var data = [')
how_many_time = main()
dataf.info('];')
webbrowser.open(os.getcwd()+'/'+'custome_profile.html')
else:
how_many_time = main()
logc.info('used {}s'.format(how_many_time.total_seconds()))
经模拟,发现无效依赖剔除后,耗时并没有缩短:

初步判断是因为有耗时较长的作业,已经覆盖住了无效依赖造成的等待时间。
4. 理论上的最短耗时
跑批模拟用的是20190908的数据,调度系统上显示是92min。假如系统硬件性能足够、线程数足够,那么该任务的跑批最短耗时应该是多少?也就是仅从依赖关系及作业编号上做优化,极限耗时是多短?

以上图的一段依赖关系为例,仅考虑作业1到5。 作业1不依赖于其他作业,顺着箭头方向为执行顺序方向,执行到节点5,有两条执行路径,分别为1245、1345。那么两条路径中的最大耗时,即为系统执行完作业5的最大耗时。
因此,对调度系统的作业做深度优先遍历,从不依赖于其他作业的作业开始往下遍历,找到最大耗时的路径,即为报表层跑批任务的最大耗时。
代码如下:
# %% import、文件路径
import time
import copy
import pandas as pd
import logging as log
log.basicConfig(
level=log.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
jobInfo_filepath = u'./jobSrc/jobInfo.csv'
depInfo_filepath = u'./jobSrc/depInfo_valid.csv'
# %% 定义作业类
class BatJob(object):
def __init__(self, name, time):
# 作业名称
self.__name = name
# 作业耗时
self.__time = time
# 作业依赖(list)
self.__childs = []
def addChild(self, child):
self.__childs.append(child)
def __str__(self):
return "\n".join(item for item in (
'【name】' + self.__name,
'【time】' + str(self.__time),
'【childs】' + str(self.__childs)
))
def getChilds(self):
return self.__childs
def popChild(self):
if(len(self.__childs) > 0):
return self.__childs.pop()
else:
return None
def getTime(self):
return self.__time
# %% 导入作业信息、依赖信息
def loadInfo():
jobInfo = pd.read_csv(jobInfo_filepath)
depInfo = pd.read_csv(depInfo_filepath)
dic = {}
jlist_all = set()
for i in range(len(jobInfo)):
jobname = jobInfo.jobname[i]
jobtime = 1 if jobInfo.jobtime_s[i] == 0 else jobInfo.jobtime_s[i]
dic[jobname] = BatJob(jobname, jobtime)
jlist_all.add(jobname)
jlist_child = set()
jlist_parent = set()
for i in range(len(depInfo)):
jlist_child.add(depInfo.jobname[i])
jlist_parent.add(depInfo.depjobname[i])
depjobname = depInfo.depjobname[i]
if(depjobname in dic):
dic[depjobname].addChild(depInfo.jobname[i])
else:
log.error('{}不在dic中'.format(depjobname))
# 无父类的作业list,即起始作业
noParentJlist = list(jlist_all.difference(jlist_child))
# 无子类的作业list,即末端
noChildJlist = list(jlist_all.difference(jlist_parent))
return dic, noParentJlist, noChildJlist
# %%
def sumTims(dic, stack):
res = 0
for i in range(len(stack)):
res += dic[stack[i]].getTime()
return res
def dfs(dic, startJobname, ncJlist):
maxtime = 0
stack = [startJobname]
res = set()
maxpath = ''
dicjobs = copy.deepcopy(dic)
while(len(stack) > 0):
stack_top = stack[-1]
child = dicjobs[stack_top].popChild()
if(child is not None):
stack.append(child)
else:
if(stack_top in ncJlist):
length = len(stack)
sumtime = sumTims(dic, stack)
maxtime = max(maxtime, sumtime)
res_str = '【len={},time={}】{}'.format(
length, str(sumtime), str(stack))
if(maxtime == sumtime):
maxpath = res_str
res.add(res_str)
stack.pop()
return res, maxtime, maxpath
# %%
dic, npJlist, ncJlist = loadInfo()
# output_filepath = u'./dfsRes/dfsRes_' + \
# time.strftime('%Y%m%d%H%M%S', time.localtime())+'.txt'
output_filepath = u'./dfsRes/dfsRes_' + \
time.strftime('%Y%m%d%H%M%S', time.localtime())+'.txt'
with open(output_filepath, 'w', encoding='utf8') as f:
for i in range(len(npJlist)):
startJobname = npJlist[i]
res, maxtime, maxpath = dfs(dic, startJobname, ncJlist)
print('{}【{}】'.format(i, startJobname))
f.write('##jobname={} maxtime={} maxpath={}\n'.format(
startJobname, maxtime, maxpath))
f.write('\n'.join(res))
f.write('\n')
跑完得到结果如下:

可看到作业XXXX_0273耗时3632s,即60.5分钟。即在系统性能、线程最优的情况下,报表层任务应在60分钟内完成。
但同时发现,该作业不依赖于其他作业,却编号为0273,排在了任务的尾巴才执行,使得整个报表层任务的作业耗时大大增加。
5. echarts输出时序图
经过深度优先遍历的分析,优化的思路为:将不依赖其他作业,且耗时较长的作业提到前边去执行。
由于跑批模拟器输出的文本结构,无法直观找到该调整哪些作业。因此考虑画一个作业执行的时序图。
一开始就想到是甘特图的形式,但网上找了半天,没找到合适的代码。有一个比较简便的,但是画出来的东西也就是看看而已,没有更多的用处了。代码如下:
# 画甘特图测试
# %%
import matplotlib.pyplot as plt
import pandas as pd
import logging as log
log.basicConfig(
level=log.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
csv_filepath = u'/log_20190920191138.csv'
ax = plt.gca()
[ax.spines[i].set_visible(False) for i in ["top", "right"]]
def gatt(data):
"""甘特图
m机器集
t时间集
"""
for i in range(len(data)):
# plt.barh(y, width, x)
# y为线程号,width为耗时,x为开始时间点
# plt.text(x, y, s, fontdict=None, withdash=False, **kwargs)
plt.barh(data.thNum[i], data.times[i], left=data.starttime[i])
plt.text(data.starttime[i], data.thNum[i],
data.jobname[i], color="white", size=8)
plt.yticks(range(max(data.thNum)+1), range(max(data.thNum)+1))
# %%
data = pd.read_csv(csv_filepath)
gatt(data)
plt.show()
参考链接:实用代码Python(七)甘特图画法
之后还是去翻了echarts的实例库,终于看到能用的。
参考链接:echarts example --Profile
html代码改造为:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>ECharts</title>
<!-- 引入 echarts.js -->
<script src="echarts.min.js"></script>
<script src="config.js"></script>
<script src="data.js"></script>
</head>
<body>
<!-- 为ECharts准备一个具备大小(宽高)的Dom -->
<div id="main" style="width: 2048px;height:1200px;"></div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
function renderItem(params, api) {
var thNum = api.value(0)-1;
var start = api.coord([api.value(1), thNum]);
var end = api.coord([api.value(2) + api.value(1), thNum]);
var height = api.size([0, 1])[1] * 0.6;
var rectShape = echarts.graphic.clipRectByRect({
x: start[0],
y: start[1] - height / 2,
width: end[0] - start[0],
height: height
}, {
x: params.coordSys.x,
y: params.coordSys.y,
width: params.coordSys.width,
height: params.coordSys.height
});
return rectShape && {
type: 'rect',
shape: rectShape,
style: api.style()
};
}
option = {
tooltip: {
formatter: function (params) {
return params.marker + params.value[3] + '_' + params.value[4] + ': ' + params.value[2] + ' ms';
}
},
// 图表标题
title: {
text: '作业运行耗时x-range图',
left: 'center'
},
dataZoom: [{
type: 'slider',
filterMode: 'weakFilter',
showDataShadow: false,
top: 700,
height: 10,
borderColor: 'transparent',
backgroundColor: '#e2e2e2',
handleIcon: 'M10.7,11.9H9.3c-4.9,0.3-8.8,4.4-8.8,9.4c0,5,3.9,9.1,8.8,9.4h1.3c4.9-0.3,8.8-4.4,8.8-9.4C19.5,16.3,15.6,12.2,10.7,11.9z M13.3,24.4H6.7v-1.2h6.6z M13.3,22H6.7v-1.2h6.6z M13.3,19.6H6.7v-1.2h6.6z', // jshint ignore:line
handleSize: 20,
handleStyle: {
shadowBlur: 6,
shadowOffsetX: 1,
shadowOffsetY: 2,
shadowColor: '#aaa'
},
labelFormatter: ''
}, {
type: 'inside',
filterMode: 'weakFilter'
}],
grid: {
height: 600
},
xAxis: {
min: 0,
scale: true,
axisLabel: {
formatter: function (val) {
return Math.max(0, val) + ' ms';
}
}
},
yAxis: {
data: thNums,
min: 0
},
series: [{
type: 'custom',
renderItem: renderItem,
itemStyle: {
normal: {
opacity: 0.8
}
},
encode: {
x: [1, 2],
y: 0
},
data: data
}]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</body>
</html>
结合一个config.js文件:
// 最大线程数
var maxThCounts = 20;
// 线程号
var thNums = [];
for (var i = 1; i < maxThCounts+1; i++) {
thNums.push(String(i))
}
var types = [
// 无父类有子类(起始节点)——绿色
// 无父类无子类(单节点)——紫色
// 有父类无子类(末端节点)——黑色
// 有父类有子类(中间节点)——红色
{ name: '无父类有子类(起始节点)', color: '#75d874', typeindex:0 },
{ name: '无父类无子类(单节点)', color: '#7b9ce1', typeindex:1 },
{ name: '有父类无子类(末端节点)', color: '#000000', typeindex:2 },
{ name: '有父类有子类(中间节点)', color: '#bd6d6c', typeindex:3 }
];
// data模板
// data.push({
// value: [
// thNum,
// starttime,
// duration,
// jobname,
// typename
// ],
// itemStyle: {
// normal: {
// color: types[typeIndex]
// }
// }
// })
跑完模拟,得到时序图如下:

图中:
- 无父类有子类(起始节点)——绿色
- 无父类无子类(单节点)——紫色
- 有父类无子类(末端节点)——黑色
- 有父类有子类(中间节点)——红色
有很多无父类无子类的单节点作业(紫色),以及无父类有子类(绿色),增加了整体任务的耗时,应当将耗时较长的绿色和紫色任务优先执行。
综上,修改了相关作业编号24个,涉及依赖4条。调整作业编号好,模拟跑批输出的时序图如下:

用20190908的数据,在时间比例为100的情况下,模拟跑批耗时从65.56秒,缩短为47.36秒。 另外使用20190913、20190922的数据进行测试,跑批缩短时长比例差不多都是72%-79%。 若生产跑批耗时95min,则调整作业编号上,预计缩短为68-75min,即减少了19-26min。
其他参考材料:
- Python中的logging模块就这么用
- pyecharts A Python Echarts Plotting Library.