【Rust】001-基础语法:变量声明及数据类型
【Rust】001-基础语法:变量声明及数据类型
文章目录
- 【Rust】001-基础语法:变量声明及数据类型
- 一、概述
-
- 1、学习起源
- 2、依托课程
- 二、入门程序
-
- 1、Hello World
- 2、交互程序
-
- 代码演示
- 执行结果
- 3、继续上难度:访问链接并打印响应
-
- 依赖
- 代码
- 执行命令
- 三、数据类型
-
- 1、标量类型
-
- 整型标量类型
- 其它
- 2、复合类型
- 四、变量声明与使用
-
- 1、常量
-
- 代码演示
- 执行结果
- 2、变量
-
- 代码演示
- 执行结果
- 3、变量名复用
-
- 代码演示
- 执行结果
- 4、声明时指定变量类型
-
- 代码演示
- 执行结果
- 5、元组的使用
-
- 代码演示
- 执行结果
- 6、数组的使用
-
- 代码演示
- 执行结果
- 7、字符串
-
- 代码演示
- 执行结果
- 五、演示 `Ownership(所有权)`、`Borrowing(借用)` 和 `Lifetime(生命周期)` 的基本概念的示例
-
-
- 代码演示
- 执行结果
-
- 六、const 和 let 的区别
-
-
- 1. 可变性(Mutability)
- 2. 类型注解
- 3. 初始化表达式
- 4. 作用域和生命周期
- 5. 内联
-
一、概述
1、学习起源
“一切能用 Rust 重写的项目都将或者正在用 Rust 重写”
2、依托课程
Rust 入门与实践:https://juejin.cn/book/7269676791348854839?utm_source=course_list
二、入门程序
1、Hello World
fn main() {
// 打印字符串
println!("Hello, world!");
}
2、交互程序
代码演示
use std::io; // 使用标准库中的 io 这个模块
fn main() {
// 打印字符串
println!("Hello, world!");
// 打印字符串
println!("请输入一个数字: ");
// 在这里我们创建了一个新的 String,用来接收下面的输入
let mut input = String::new();
io::stdin()
.read_line(&mut input) // 读取一行
.expect("Failed to read input!"); // 比较粗暴的错误处理
// 打印输入的原始内容
println!("Your raw input is: {:?}.", input);
// trim 把前后的空格、换行符这些空白字符都去掉,parse 将输入的字符串解析为 i64 类型,如果解析失败就报错
let number: i64 = input.trim().parse().expect("Input is not a number!");
// 打印 parse 之后的 i64 数字
println!("Your input is: {}.", number);
}
执行结果
C:/Users/Administrator/.cargo/bin/cargo.exe run --color=always --package hello_rust --bin hello_rust
Finished dev [unoptimized + debuginfo] target(s) in 0.01s
Running `target\debug\hello_rust.exe`
Hello, world!
请输入一个数字:
100
Your raw input is: "100\n".
Your input is: 100.
进程已结束,退出代码为 0
3、继续上难度:访问链接并打印响应
依赖
Cargo.toxml
[package]
name = "hello_rust"
version = "0.1.0"
edition = "2021"
[dependencies]
clap = { version = "4", features = ["derive"] }
reqwest = { version = "0.11", features = ["blocking"] }
代码
// 使用 use 引入一个标准库的包,或者第三方的包
use std::error::Error;
// clap 是一个 Rust 社区开发的命令行参数解析库
use clap::Parser;
// reqwest 是一个 Rust 社区开发的 HTTP 客户端库
use reqwest::blocking::Client;
use reqwest::header::HeaderMap;
// 使用 derive 宏,用于自动生成 Parser 的实现
// 在高级特性章节中我们会学到宏的用法及原理
#[derive(Parser)]
#[command(
author,
version,
about = "Sends HTTP requests and prints detailed information"
)]
struct Cli {
// arg 宏用于标记命令行参数,这里标记了一个必须的 URL 参数
#[arg(short, long, help = "Target URL", required = true)]
url: String,
}
/// Rust 程序入口
fn main() -> Result<(), Box<dyn Error>> {
// 解析命令行参数
let cli = Cli::parse();
// 发起 HTTP 请求
// ? 是 Rust 中的错误传播语法糖,我们会在接下来的章节中学习
let response = send_request(&cli.url)?;
// 打印 HTTP 响应的详细信息
print_response_details(response)?;
Ok(())
}
/// 发起一个 HTTP 请求
/// 参数是目标 URL 的引用
/// 返回值是一个 Result,如果请求成功返回 Response,否则返回一个动态 Error
fn send_request(url: &str) -> Result<reqwest::blocking::Response, Box<dyn Error>> {
// 创建一个 HTTP 客户端
let client = Client::builder().build()?;
// 使用 GET 方法发起请求
let response = client.get(url).send()?;
Ok(response)
}
/// 打印出 HTTP 响应的详细信息
/// 参数是 Response 对象
/// 返回值是一个 Result,用于错误处理
fn print_response_details(response: reqwest::blocking::Response) -> Result<(), Box<dyn Error>> {
// 打印 HTTP 状态码
println!("Status: {}", response.status());
// 打印 HTTP 响应头
println!("Headers:");
print_headers(response.headers());
// 读取并打印 HTTP 响应体
let body = response.text()?;
println!("Body:\n{}", body);
Ok(())
}
/// 打印出 HTTP 响应头
/// 参数是 HeaderMap 的引用
fn print_headers(headers: &HeaderMap) {
for (key, value) in headers.iter() {
// 打印每个响应头的键和值
// 如果值不是 UTF-8 字符串,就打印 [unprintable]
println!(" {}: {}", key, value.to_str().unwrap_or("[unprintable]"));
}
}
执行命令
根目录执行
cargo run -- --url https://juejin.cn/
三、数据类型
1、标量类型
整型标量类型
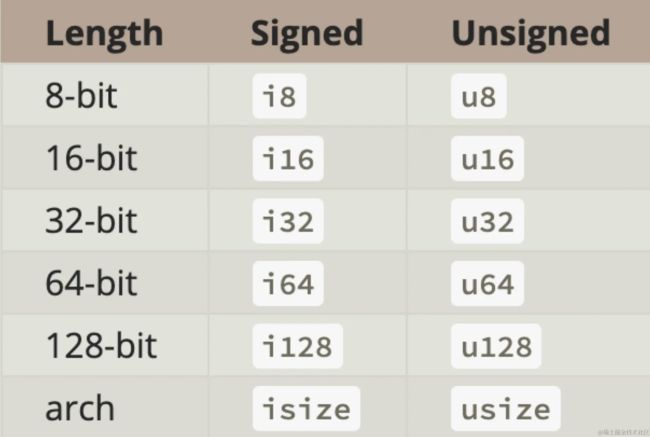
只要记得最低从 8 开始,到 128 结束(当然,正常情况下我们最多用到 64,128 在很多平台上需要软件模拟而不是硬件支持,不推荐大家用);在赋值的时候除了直接十进制数字赋值外,还支持以下语法(大家了解一下就好,不用死记硬背):
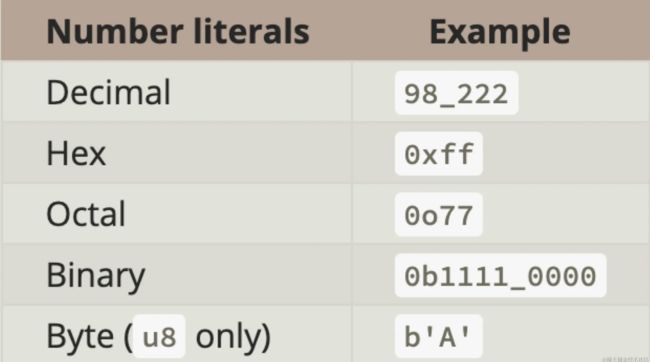
其它
- 浮点数:f32 / f64
- bool
- char:这个比较特殊,Rust 中一个 char 占 4 字节,存放的是一个 UTF-32,而不像 C/C++ 那样本质上是个 u8
2、复合类型
- 元组 tuple:let a = (1, 2); let (a, b) = (1, 2)
- 数组 array: let a = [1, 2, 3]; let a = [0; 5] // 这个声明中 0 是默认值,5 是长度,等价于 let a = [0, 0, 0, 0, 0]
四、变量声明与使用
1、常量
代码演示
fn main() {
// 声明常量,表示年龄
const AGE: u32 = 18;
// 声明常量,表示名字
let name = "张三";
// 打印名字和年龄
println!("{}的年龄是{}", name, AGE);
}
执行结果
张三的年龄是18
2、变量
代码演示
fn main() {
// 声明变量,表示年龄
let mut age = 18;
// 打印变量
println!("age = {}", age);
// 修改变量
age = 20;
// 打印变量
println!("age = {}", age);
}
执行结果
age = 18
age = 20
3、变量名复用
代码演示
fn main() {
// 声明常量,表示年龄
let age = 18;
// 打印年龄
println!("age = {}", age);
// 再次声明 age 变量,此时不会报错
let age = 20;
// 打印年龄
println!("age = {}", age);
}
执行结果
age = 18
age = 20
4、声明时指定变量类型
代码演示
fn main() {
// 声明常量,表示年龄
let age: i32 = 18;
// 打印年龄
println!("age = {}", age);
}
执行结果
age = 18
age = 20
5、元组的使用
代码演示
fn main() {
// 声明一个包含三个元素的元组
let my_tuple = (1, "hello", 3.14);
// 使用索引访问元组中的元素
println!("第一个元素是:{}", my_tuple.0); // 输出 "第一个元素是:1"
println!("第二个元素是:{}", my_tuple.1); // 输出 "第二个元素是:hello"
println!("第三个元素是:{}", my_tuple.2); // 输出 "第三个元素是:3.14"
// 使用模式匹配解构元组
let (x, y, z) = my_tuple;
println!("解构后 x 的值是:{}", x); // 输出 "解构后 x 的值是:1"
println!("解构后 y 的值是:{}", y); // 输出 "解构后 y 的值是:hello"
println!("解构后 z 的值是:{}", z); // 输出 "解构后 z 的值是:3.14"
// 忽略元组中不需要的值
let (a, _, _) = my_tuple;
println!("只需要第一个元素:{}", a); // 输出 "只需要第一个元素:1"
// 嵌套元组
let nested_tuple = (1, (2, 3), 4);
let (_, (b, c), _) = nested_tuple;
println!("嵌套元组中 b 的值和 c 的值分别是:{} 和 {}", b, c); // 输出 "嵌套元组中 b 的值和 c 的值分别是:2 和 3"
}
执行结果
第一个元素是:1
第二个元素是:hello
第三个元素是:3.14
解构后 x 的值是:1
解构后 y 的值是:hello
解构后 z 的值是:3.14
只需要第一个元素:1
嵌套元组中 b 的值和 c 的值分别是:2 和 3
6、数组的使用
代码演示
fn main() {
// 声明一个包含5个元素的整数数组
let int_array = [1, 2, 3, 4, 5];
// 声明一个包含5个元素的浮点数数组,同时指定类型
let float_array: [f64; 5] = [1.0, 2.0, 3.0, 4.0, 5.0];
// 使用索引访问数组中的元素
println!("整数数组的第一个元素是:{}", int_array[0]); // 输出 "整数数组的第一个元素是:1"
println!("浮点数数组的第二个元素是:{}", float_array[1]); // 输出 "浮点数数组的第二个元素是:2.0"
// 使用循环遍历整数数组
println!("整数数组的所有元素:");
for num in int_array.iter() {
print!("{} ", num); // 输出 "1 2 3 4 5 "
}
println!();
// 使用循环遍历浮点数数组,并获取索引
println!("浮点数数组的所有元素和对应的索引:");
for (index, num) in float_array.iter().enumerate() {
println!("索引:{}, 元素:{}", index, num);
// 输出 "索引:0, 元素:1.0"
// 输出 "索引:1, 元素:2.0"
// ...
}
// 声明一个全部元素为0的数组
let zero_array: [i32; 5] = [0; 5];
println!("全为0的数组:{:?}", zero_array); // 输出 "全为0的数组:[0, 0, 0, 0, 0]"
}
执行结果
整数数组的第一个元素是:1
浮点数数组的第二个元素是:2
整数数组的所有元素:
1 2 3 4 5
浮点数数组的所有元素和对应的索引:
索引:0, 元素:1
索引:1, 元素:2
索引:2, 元素:3
索引:3, 元素:4
索引:4, 元素:5
全为0的数组:[0, 0, 0, 0, 0]
7、字符串
代码演示
fn main() {
// 使用字符串字面量声明一个不可变字符串
let hello_str = "Hello, world!";
println!("不可变字符串字面量:{}", hello_str); // 输出 "不可变字符串字面量:Hello, world!"
// 使用 String::from 创建一个可变字符串
let mut hello_string = String::from("Hello");
println!("可变字符串:{}", hello_string); // 输出 "可变字符串:Hello"
// 在可变字符串后追加字符串
hello_string.push_str(", world!");
println!("追加后的可变字符串:{}", hello_string); // 输出 "追加后的可变字符串:Hello, world!"
// 字符串拼接
let concat_str = [hello_str, " ", &hello_string].concat();
println!("拼接后的字符串:{}", concat_str); // 输出 "拼接后的字符串:Hello, world! Hello, world!"
// 使用索引获取字符串中的字符(注意:这种方式不推荐,因为会导致错误或崩溃)
// let first_char = hello_str[0]; // 这样是错误的
// Rust 的字符串是 UTF-8 编码的,直接索引可能会导致字符被截断。
// 使用 chars 方法遍历字符串中的字符
println!("使用 chars 方法遍历字符串:");
for ch in hello_str.chars() {
print!("{} ", ch); // 输出 "H e l l o , w o r l d ! "
}
println!();
// 使用 bytes 方法遍历字符串中的字节
println!("使用 bytes 方法遍历字符串字节:");
for byte in hello_str.bytes() {
print!("{} ", byte); // 输出对应的 ASCII 或 UTF-8 编码的字节值
}
println!();
// 获取字符串长度
println!("字符串 '{}' 的长度是:{}", hello_str, hello_str.len()); // 输出 "字符串 'Hello, world!' 的长度是:13"
}
执行结果
不可变字符串字面量:Hello, world!
可变字符串:Hello
追加后的可变字符串:Hello, world!
拼接后的字符串:Hello, world! Hello, world!
使用 chars 方法遍历字符串:
H e l l o , w o r l d !
使用 bytes 方法遍历字符串字节:
72 101 108 108 111 44 32 119 111 114 108 100 33
字符串 'Hello, world!' 的长度是:13
五、演示 Ownership(所有权)、Borrowing(借用) 和 Lifetime(生命周期) 的基本概念的示例
代码演示
// 定义一个函数,演示所有权的转移
fn takes_ownership(some_string: String) {
println!("函数内部:{}", some_string);
} // 这里 some_string 离开作用域,所有权也随之释放
// 定义一个函数,演示借用(不可变)
fn borrows_immutable(s: &String) {
println!("函数内部(不可变借用):{}", s);
}
// 定义一个函数,演示借用(可变)
fn borrows_mutable(s: &mut String) {
s.push_str(", world!"); // 修改字符串
println!("函数内部(可变借用):{}", s);
}
// 定义一个函数,演示生命周期
// 注:'a 是生命周期标注,表明 x 和 y 的生命周期相同,并且与返回值的生命周期也相同
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
fn main() {
// 所有权(Ownership)
let s1 = String::from("hello"); // s1 获取了字符串 "hello" 的所有权
takes_ownership(s1); // 所有权转移到函数 takes_ownership
// println!("main 函数:{}", s1); // 错误!因为 s1 的所有权已经被转移
// 借用(Borrowing)
let s2 = String::from("hello"); // s2 获取了字符串 "hello" 的所有权
borrows_immutable(&s2); // 不可变借用,所有权仍在 s2
println!("main 函数(不可变借用后):{}", s2);
let mut s3 = String::from("hello"); // s3 获取了字符串 "hello" 的所有权,并且是可变的
borrows_mutable(&mut s3); // 可变借用,所有权仍在 s3,但内容已经被修改
println!("main 函数(可变借用后):{}", s3);
// 生命周期(Lifetime)
let str1 = "Rust";
let str2 = "Programming";
let result = longest(str1, str2);
println!("更长的字符串是:{}", result); // 输出 "更长的字符串是:Programming"
}
执行结果
函数内部:hello
函数内部(不可变借用):hello
main 函数(不可变借用后):hello
函数内部(可变借用):hello, world!
main 函数(可变借用后):hello, world!
更长的字符串是:Programming
六、const 和 let 的区别
1. 可变性(Mutability)
-
let: 默认情况下,使用let声明的变量是不可变的,但您可以使用mut关键字来使其可变。let x = 5; // 不可变 let mut y = 6; // 可变 -
const: 使用const声明的常量始终是不可变的,并且不能使用mut。const X: i32 = 5; // 始终不可变
2. 类型注解
-
let: 可以选择是否添加类型注解。let x = 5; // 类型推断为 i32 let y: i64 = 6; // 显示类型注解 -
const: 必须添加类型注解。const X: i32 = 5; // 必须提供类型
3. 初始化表达式
-
let: 可以使用任何类型的表达式进行初始化。let x = 5 + 5; // 算术表达式 -
const: 只能使用常量表达式进行初始化。const X: i32 = 5 + 5; // 常量表达式,但不能是函数调用、运行时计算等
4. 作用域和生命周期
let: 局部变量,作用范围仅限于声明它的代码块。const: 可以在模块级别使用,生命周期可跨越整个程序。
5. 内联
const: 在编译时,常量的值会被直接内联到使用它的表达式中。let: 取决于编译器优化。
总体来说,const 主要用于那些在编译时就能确定并且永远不会改变的值,而 let 则用于运行时可能会改变的值。希望这能帮助您更好地理解这两者之间的区别!