目录扫描+JS文件中提取URL和子域+403状态绕过+指纹识别(dirsearch_bypass403)
dirsearch_bypass403
在安全测试时,安全测试人员信息收集中时可使用它进行目录枚举,目录进行指纹识别,枚举出来的403状态目录可尝试进行绕过,绕过403有可能获取管理员权限。不影响dirsearch原本功能使用
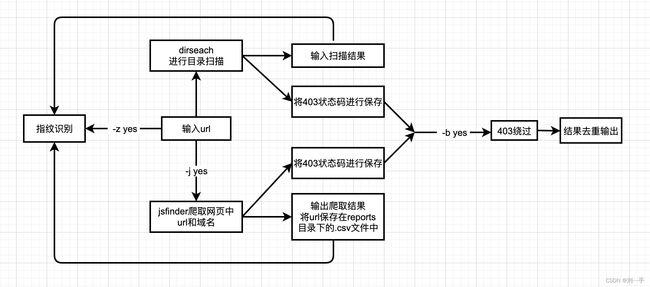
运行流程
dirsearch进行目录扫描—>将所有403状态的目录进行保存–>是否进行jsfind–>是(进行js爬取url和域名,将爬取到的url进行状态码识别如果是403状态则进行保存)–>进行403绕过–>目录进行指纹识别
使用说明
默认不启用jsfind和403bypass
403bypass : -b yes
python dirsearch.py -u "http://www.xxx.com/" -b yes
jsfind :-j yes
python dirsearch.py -u "http://www.xxx.com/" -j yes
jsfind和403bypass : -b yes -j yes
python dirsearch.py -u "http://www.xxx.com/" -j yes -b yes
单独对指定目录进行bypass
python single_403pass.py -u "http://www.xxx.com/" -p "/index.php" # -p 指定路径
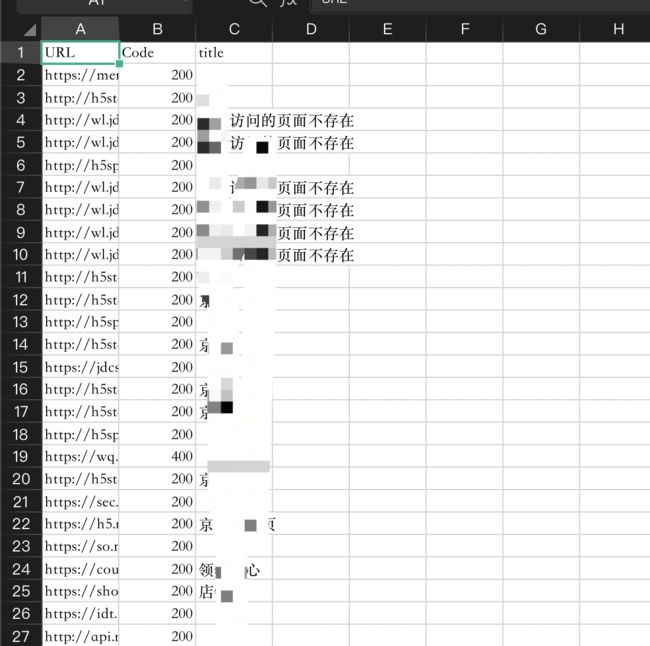
对扫描出来的目录进行指纹识别(结果会自动保存在reports目录下的.josn文件中)
python dirsearch.py -u "http://www.xxx.com/" -z yes
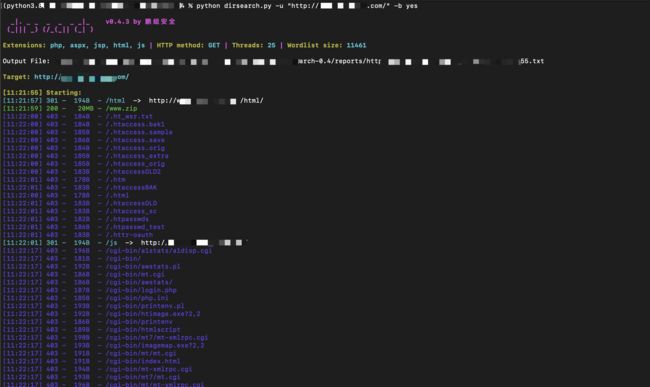
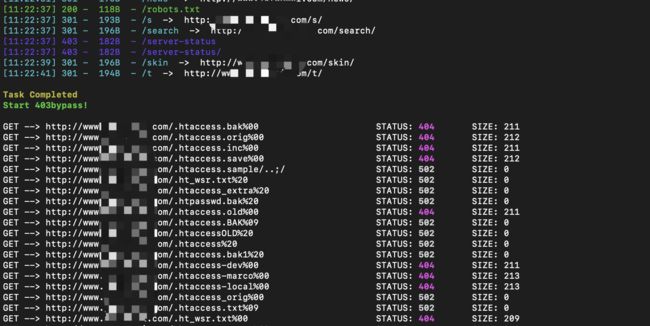
使用截图
更新日志
2023.5.7
增加页面长度一样的无效结果进行过滤输出
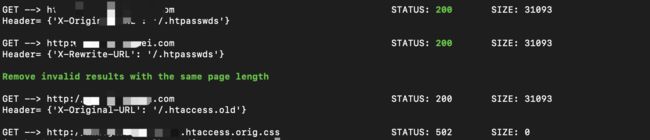
2023.5.9
是否进行jsfind查找js中的url,在网站的js文件中提取URl,排除(如png、gif)的URL,将403状态码的url进行403bypass
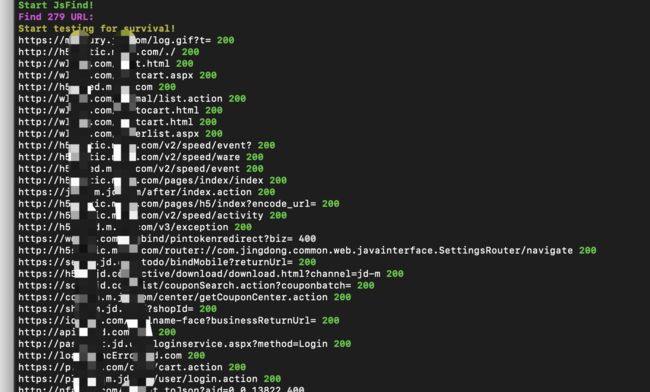
2023.5.11
优化原版403bypasser,单独对某一指定路径进行403bypass
昨天同事在使用时遇到问题:发现一个403页面,如果运行dirsearch则会目录扫描后再403bypass
single_403pass.py 单独对一个url指定路径进行403bypass
python single_403pass.py -u "http://www.xxx.com/" -p "/index.php" # -p 指定路径
2023.5.12
对目录进行指纹识别(结果会自动保存在reports目录下的.josn文件中)
python dirsearch.py -u "http://www.xxx.com/" -z yes
2023.5.22
对404状态码和0B数据进行过滤不进行指纹识别
2023.9.1
优化403bypass:与首页大小进行判断 如果size相同则表示绕过失败
增加了一点403bypass绕过方式
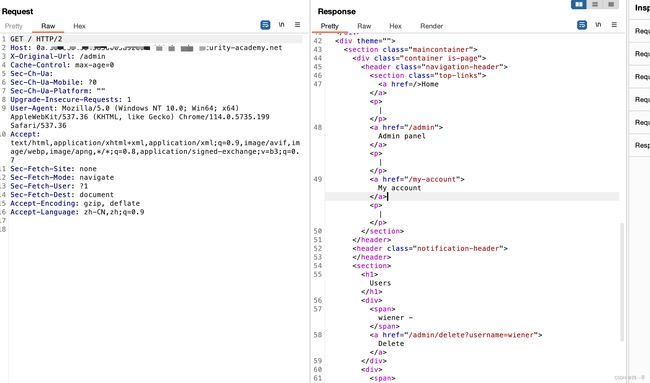
获取链接
https://github.com/lemonlove7/dirsearch_bypass403
参考优秀项目
dirsearch:https://github.com/maurosoria/dirsearch
403bypasser:https://github.com/yunemse48/403bypasser
JSFinder:https://github.com/Threezh1/JSFinder
EHole:https://github.com/EdgeSecurityTeam/EHole